当前位置:网站首页>[information retrieval] experiment of classification and clustering
[information retrieval] experiment of classification and clustering
2022-07-04 14:29:00 【Alex_ SCY】
(1) use Java Language or other commonly used languages to realize teaching materials 《Introduction to Information Retrieval》 The first 13 The two feature selection methods introduced in the chapter :13.5.1 Based on mutual information described in section (Mutual Information) Feature selection method and 13.5.2 The described in section is based on X^2 Feature selection method of .
Please get it by yourself from the official document of the school 2021 News documents of ( Crawl or download manually ), Requirements include the following 150 News document :
“ Party and government offices ” The latest 30 News document ,
“ The Ministry of Education ” The latest 30 News document ,
“ Admissions office ” The latest 30 News document ,
“ graduate school ” The latest 30 News document ,
“ Ministry of science and technology ” The latest 30 News document .
take “ Party and government offices ”、“ The Ministry of Education ”、“ Admissions office ”、“ graduate school ” and “ Ministry of science and technology ” As 5 individual class, And through mutual information and X^2 For each class Choose the most relevant 15 Features ( Include the feature name and the corresponding value , After the decimal point 2 position ), And make a brief analysis of the results .
Code screenshot 、 Screenshots of running results and detailed text description :
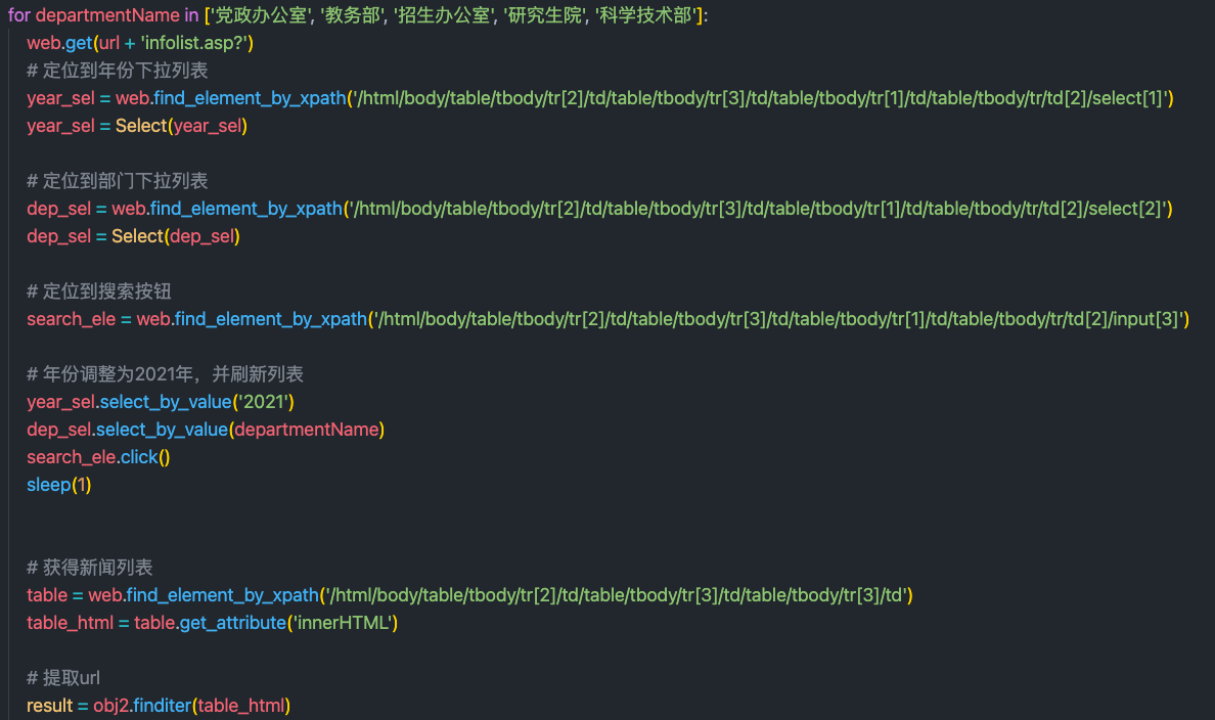
First step : Reptiles
Use python selenium Automatic tools crawl text from official documents , And extract the text and organize it into a file for storage . The specific implementation process is roughly using chrome The automation tool automatically switches to 2021 Interfaces of various departments in , Then before the crawler gets 30 Link to the news and use it to locate the corresponding div Read text . The specific implementation is as follows :
Automatic page switching :
Get text information :
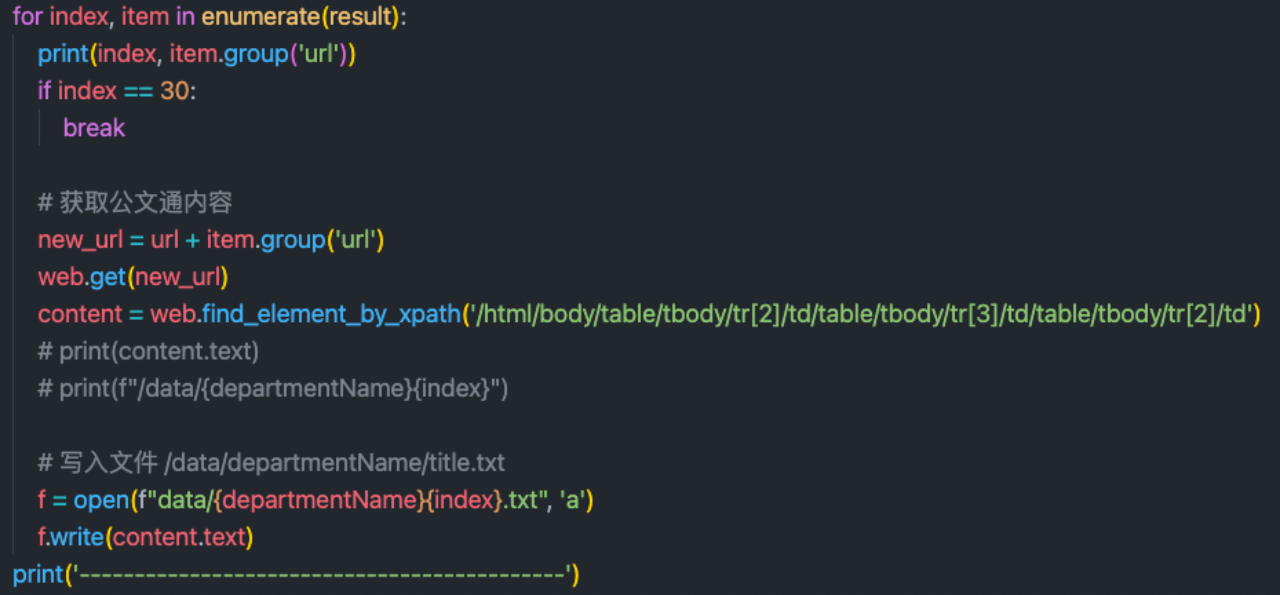
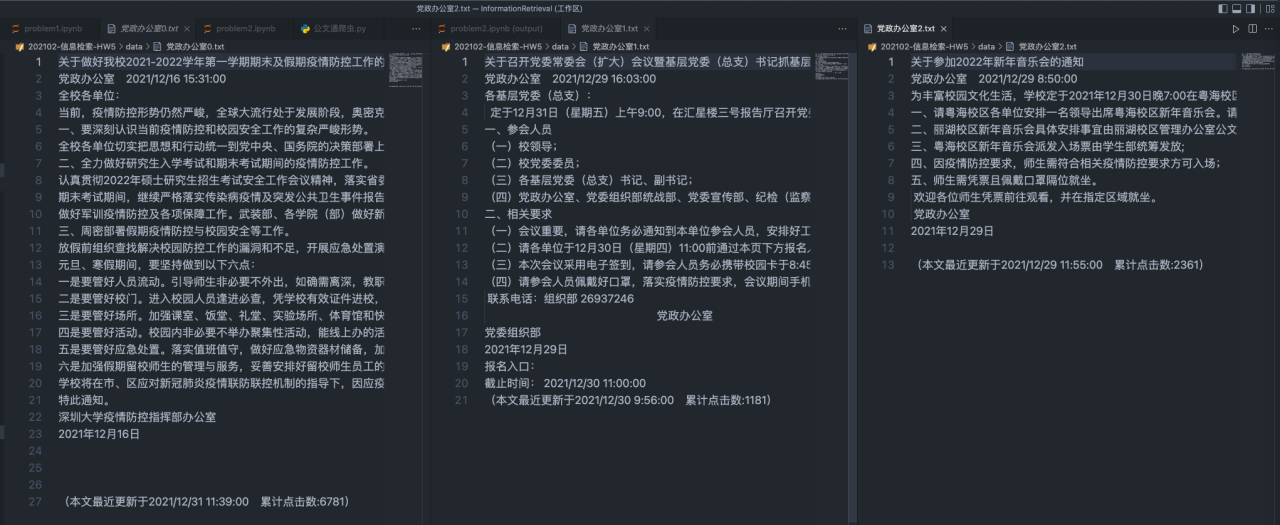
The second step is to process text information
1. Read document , Classify according to file name
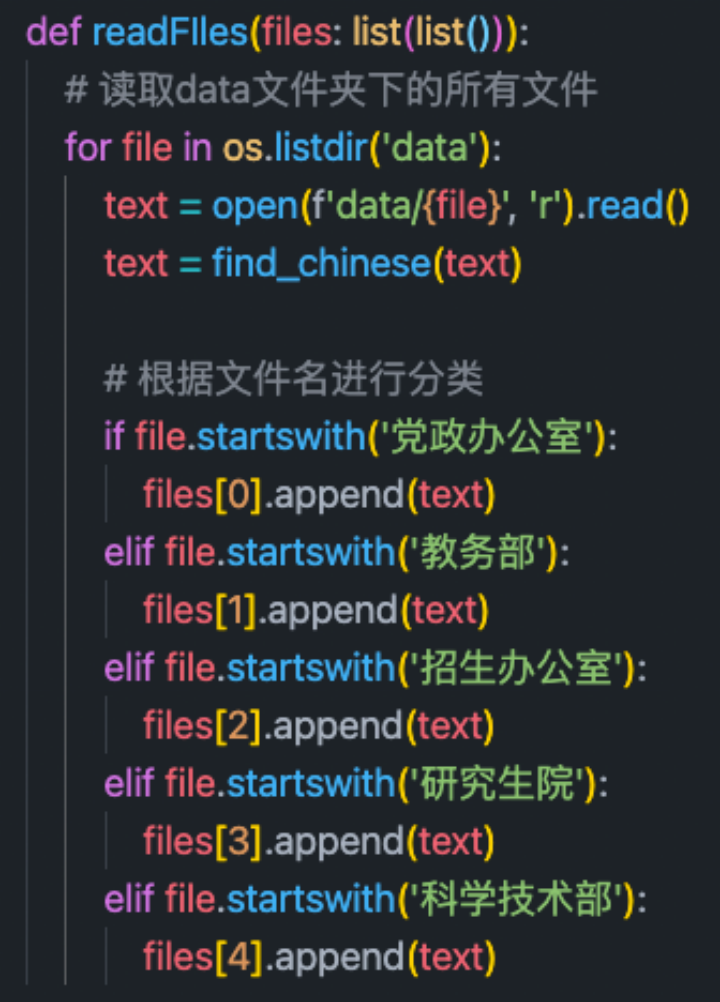
among file[0-5] There are five categories of articles in turn 
2. Use jieba Do word segmentation , And generate word bags .
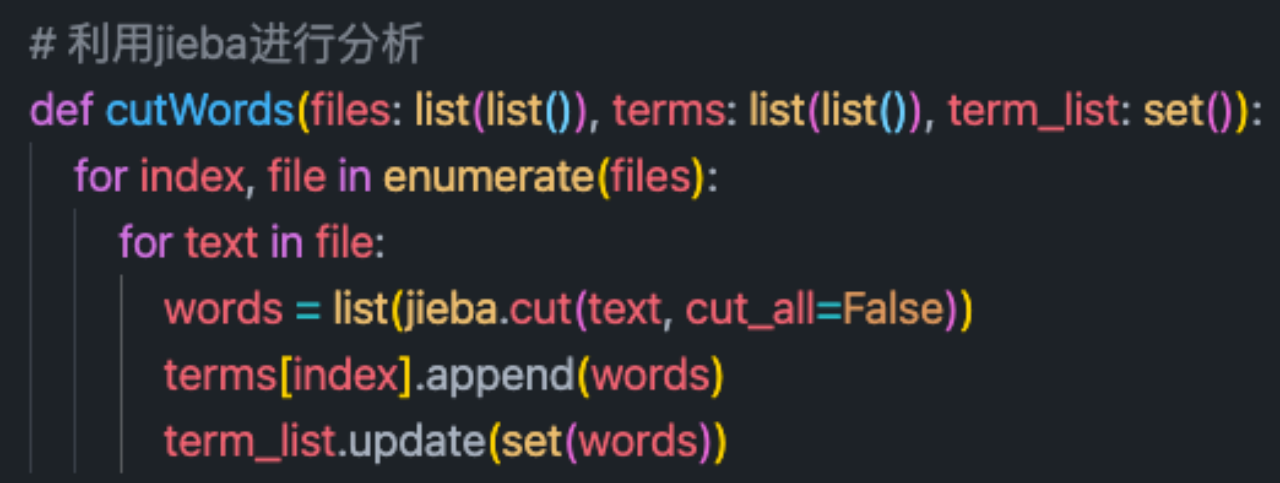
Segmentation result :
The word bag :
notes : Because the crawler down the article will have \u3000 Wait for extra characters , Therefore, additional treatment is required 
The third step is feature selection :
MI The formula is as follows :
So in order to reduce double counting , First of all, I made statistics on the occurrence of each word item in different categories . For each word , First of all, the statistics are in the form of the following table :
| Word / Category | Number of occurrences | No occurrences |
|---|---|---|
| Category 1 | 1 | 29 |
| Category 2 | 3 | 27 |
| Category 3 | 5 | 25 |
| Category 4 | 7 | 23 |
| Category 5 | 9 | 21 |

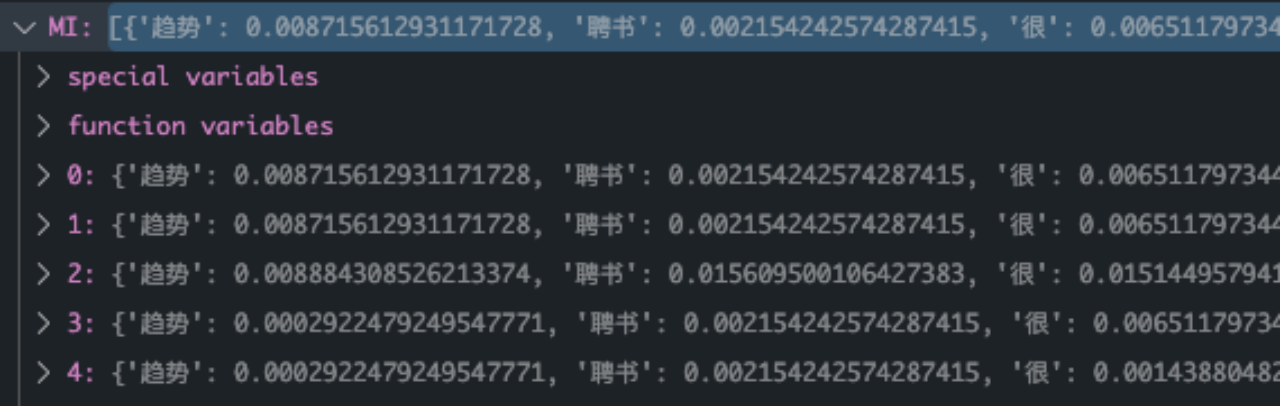
With the above table , You can quickly calculate each category N11,N10,N01,N00 Four values of , And according to MI,X^2 The corresponding results are obtained by the calculation formula of 


The final calculation results are as follows :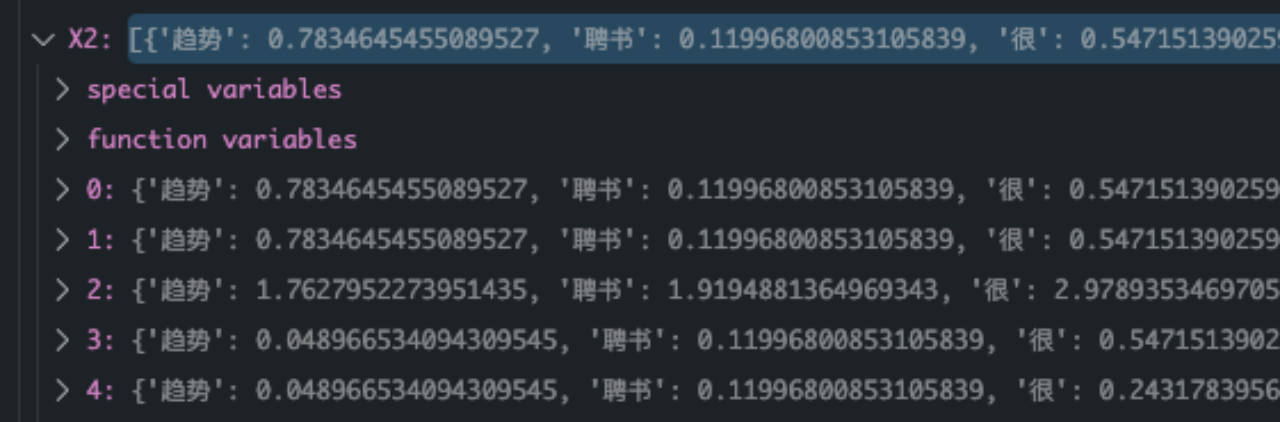
The fourth step is to sort .
Because the title only needs to be obtained before 15 Large eigenvalues , Therefore, the small top stack based TopK Algorithm :
First, write a small top heap reconstruction algorithm :
And then there was TopK Sorting algorithm : First, before using K Create a small top heap with three elements , If the subsequent element is larger than the heap top element , The replacement , And rebuild the small top pile . Finally, use the heap sorting algorithm , Yes K Elements to sort .
The result is as follows :
Make a brief introduction to the Chinese word segmentation tools used :
call jieba.cut Function for word segmentation
jieba participle 0.4 Versions above support four word segmentation modes :
1. Accurate model : Try to cut the sentence as precisely as possible , Suitable for text analysis ;
2. All model : Scan the sentences for all the words that can be made into words , Very fast , But it doesn't solve the ambiguity
3. Search engine model : On the basis of exact patterns , Again shred long words , Increase recall rate , Suitable for search engine segmentation
4.paddle Pattern : utilize PaddlePaddle Deep learning framework , Training sequence labeling ( two-way GRU) The network model realizes word segmentation . It also supports part of speech tagging .
It can be seen that , The coarsest pattern of words is , All words are returned . There are mainly the following questions :
1. Without context , Easily ambiguous : Collaborative filtering ----> synergy + The same thing + Filter
2. Don't know vocabulary : Robust ----> Lu + Great
Precise mode and search engine mode can be selected according to specific needs .
Through mutual information for each class Choose the most relevant 15 Features :
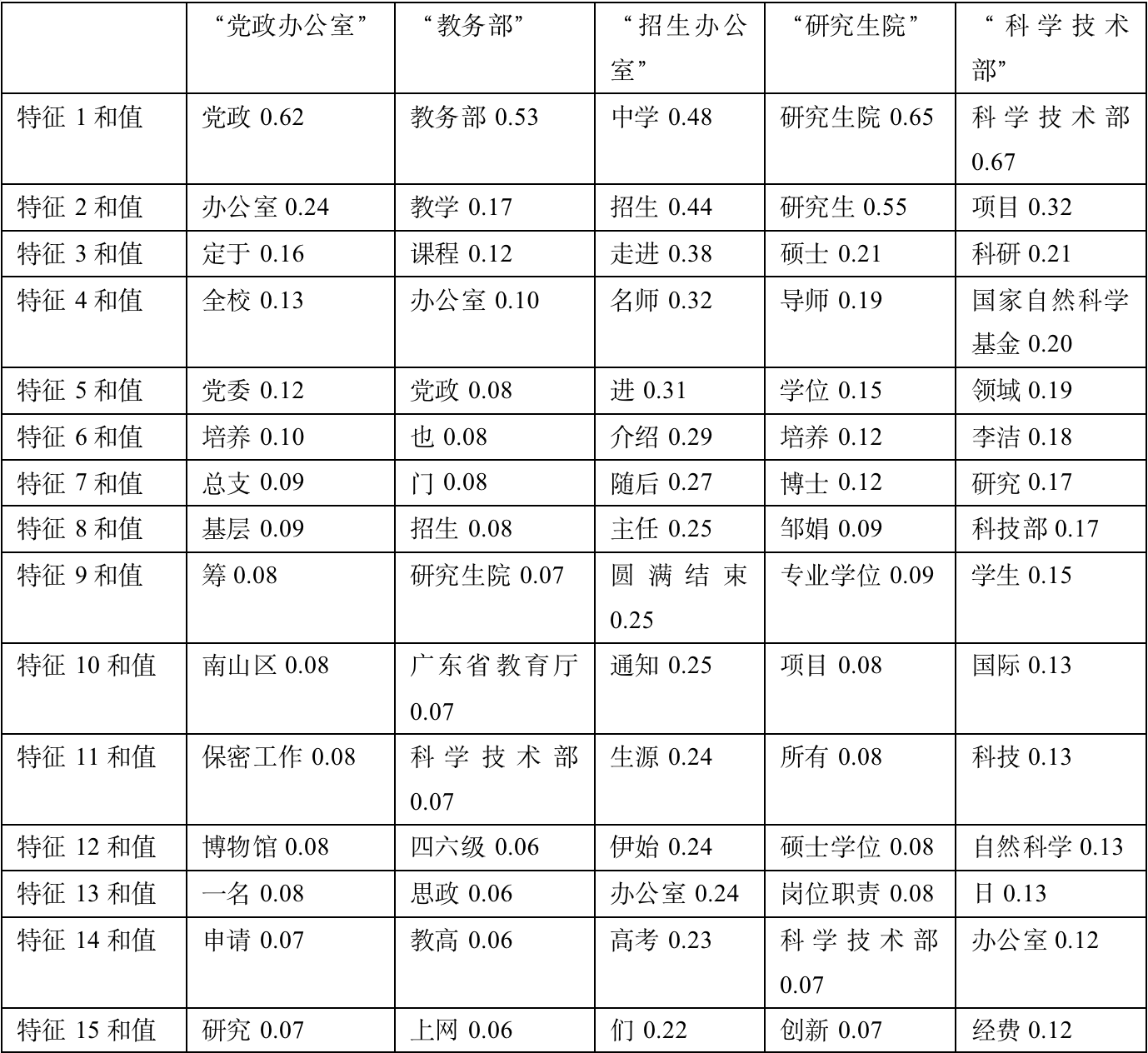
Through mutual information for each class Choose the most relevant 15 Make a brief analysis of the characteristics :
1、 Party and government offices : The filtered information is more in line with , party and government 、 Party Committee 、 Grassroots and other words are very consistent .
2、 The Ministry of Education : Most of the selected articles focus on 12 month , At that time, most of the articles were about summarizing the annual work . After comparison , It can roughly summarize the main work content of the month .
3、 Admissions office : More in line with . It is obvious that many consultations were released at that time to go into high school and promote deep education . verified , It is found that a large number of topics have been published for 《 Famous teachers go to middle school 》 A series of articles .
4、 graduate school : The filtered information is more in line with , master 、 mentor 、 Doctor and other words are very consistent .
5、 Ministry of science and technology : The filtered information is more in line with , NSFC 、 Natural science 、 Funds and other words are very consistent .
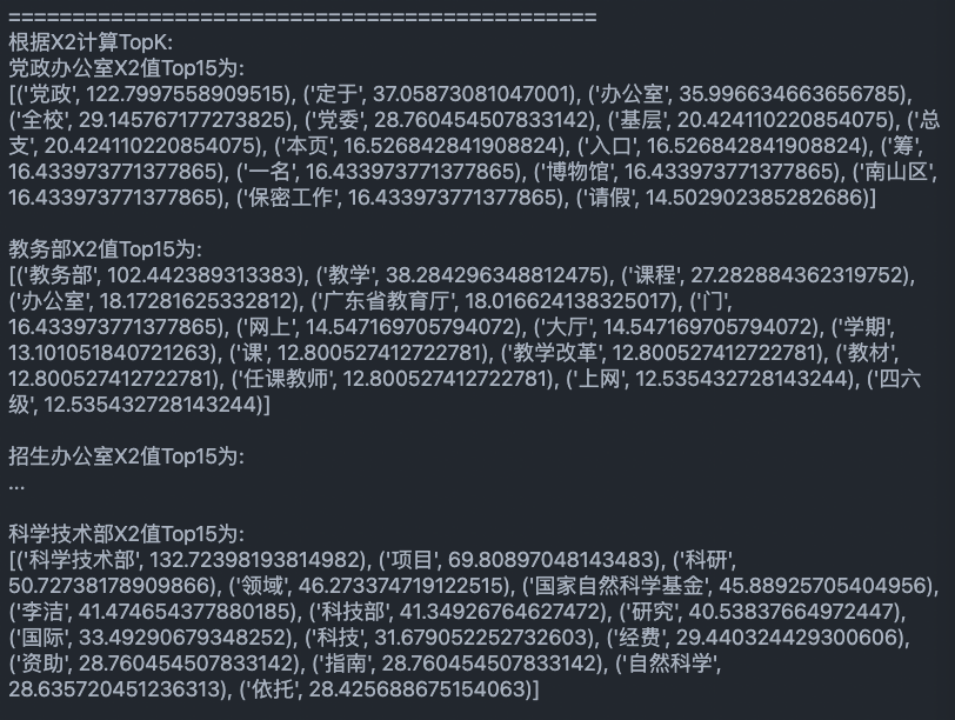
adopt X^2 For each class Choose the most relevant 15 Features :
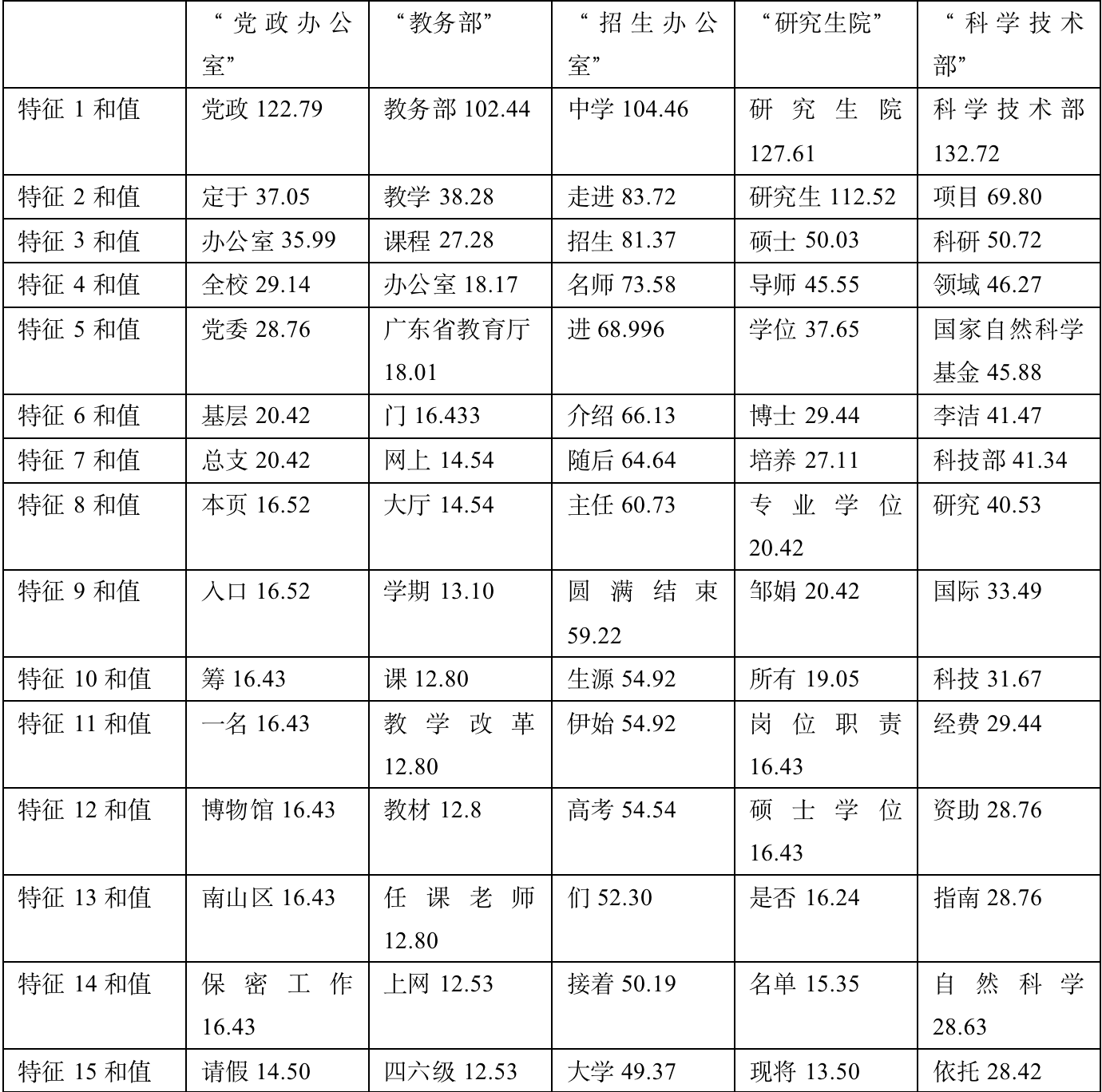
Yes X^2 For each class Choose the most relevant 15 Make a brief analysis of the characteristics :
1、 Party and government offices : The filtered information is more in line with , party and government 、 Party Committee 、 Grassroots and other words are very consistent .
2、 The Ministry of Education : Most of the selected articles focus on 12 month , At that time, most of the articles were about summarizing the annual work . After comparison , It can roughly summarize the main work content of the month .
3、 Admissions office : More in line with . It is obvious that many consultations were released at that time to go into high school and promote deep education . verified , It is found that a large number of topics have been published for 《 Famous teachers go to middle school 》 A series of articles .
4、 graduate school : The filtered information is more in line with , master 、 mentor 、 Doctor and other words are very consistent .
5、 Ministry of science and technology : The filtered information is more in line with , NSFC 、 Natural science 、 Funds and other words are very consistent .
Through mutual information and X^2 For each class Choose the most relevant 15 Make a brief comparative analysis of the three features :
Because of reptiles , In all articles, there will be similar ( This article was recently updated on 2021/12/29 19:05:00 Cumulative hits :877) The sentence of . But both algorithms can filter out this kind of information that repeats in all categories , The reason is that in this statement term Of N11 and N10 All very high , It can filter better .
The other two calculation methods , The selection and ranking of the first few features are relatively consistent . The latter features will have different emphasis , This is because X^2 Choose based on statistical significance , So he will be better than MI Select more rare items , These terms are not reliable for classification . Of course ,MI It is not necessarily possible to choose the words that maximize the classification accuracy of yes . So I think the better way is to increase the sample size .
(2) use Java Language or other commonly used languages to implement a naive Bayesian Classification Algorithm (Naive Bayes algorithm) Simple document classification system ( Judge whether the notice of a document communication is “ Party and government offices ”、“ The Ministry of Education ”、“ Admissions office ”、“ graduate school ” and “ Ministry of science and technology ” Information about , From 5 Select the most relevant category ).
The classification effects of using feature selection and not using feature selection should be compared and analyzed . Use questions (1) To train and test , In each category 20 Articles are used for training ,10 Articles are used for testing .
Please attach the overall design of the system in the report 、 Code screenshot ( Don't copy the source code , Please use screenshots )、 Screenshots of running results and detailed text description . The program should have detailed notes . Make a brief introduction to the Chinese word segmentation tools used .(20 branch )
Overall design of the system :
Integral design :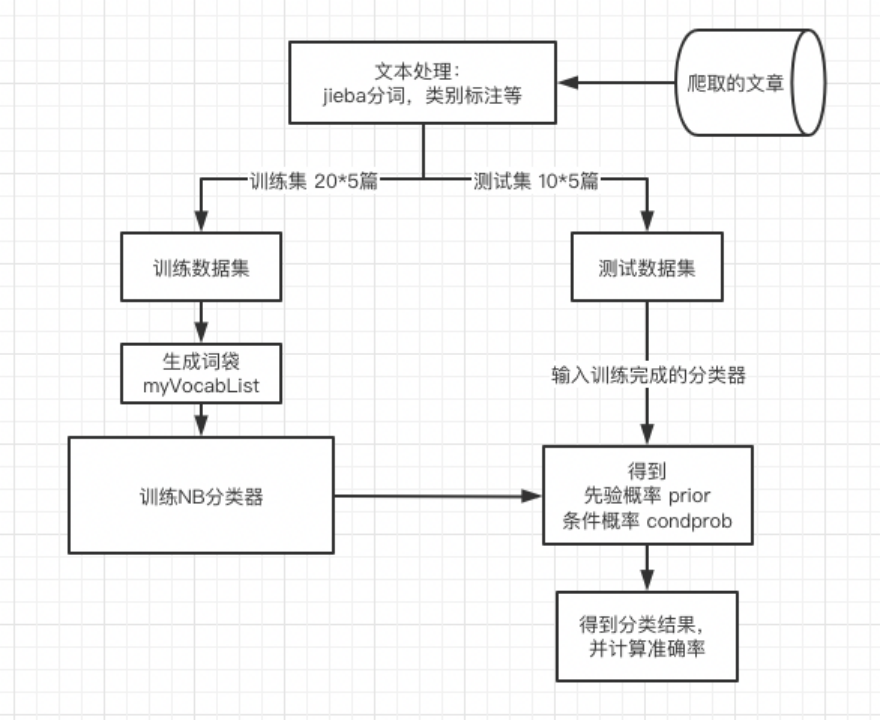
Code screenshot 、 Screenshots of running results and detailed text description :
First step : Read the article data set 
During reading , Need to read text for processing . Among them, there will be articles down due to crawlers \u3000 Wait for extra characters , Therefore, additional treatment is required . And then use it jieba Word segmentation generates a list of articles .postingList and classVec One-to-one correspondence , For the correct classification of text and markup .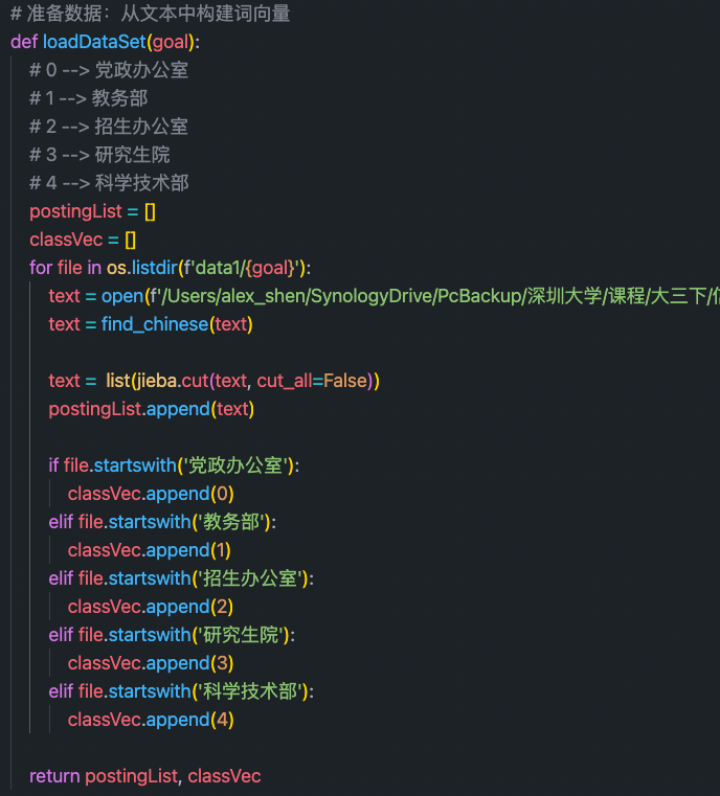
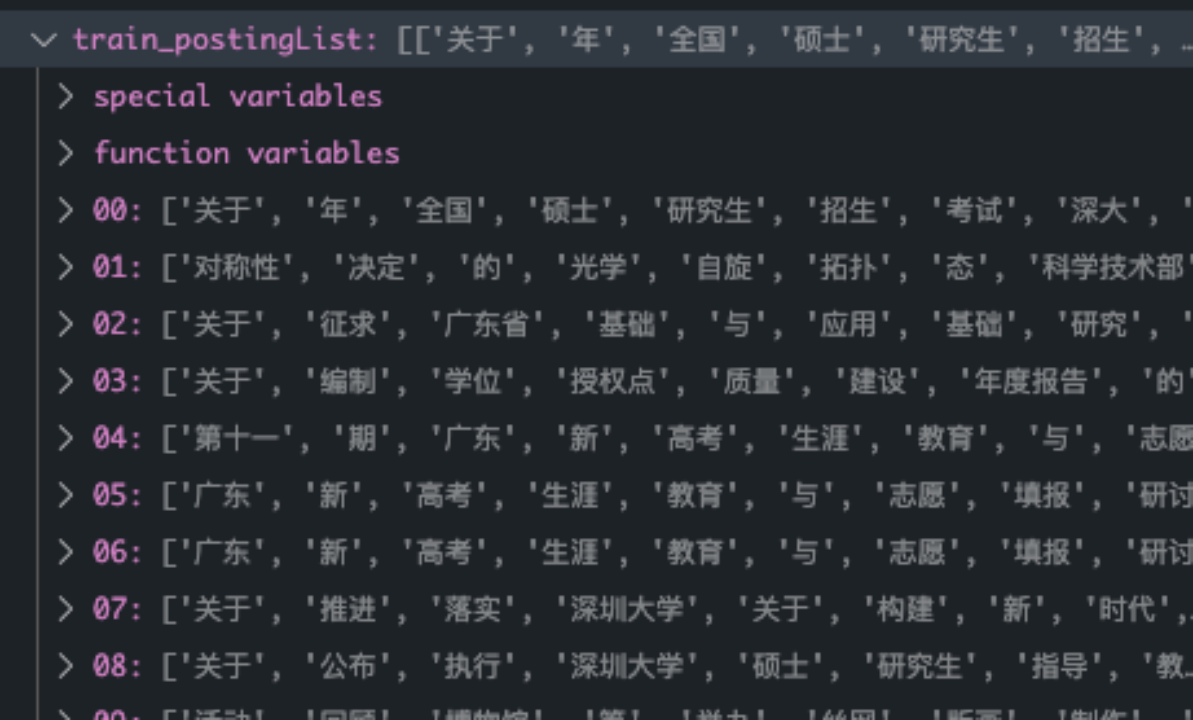
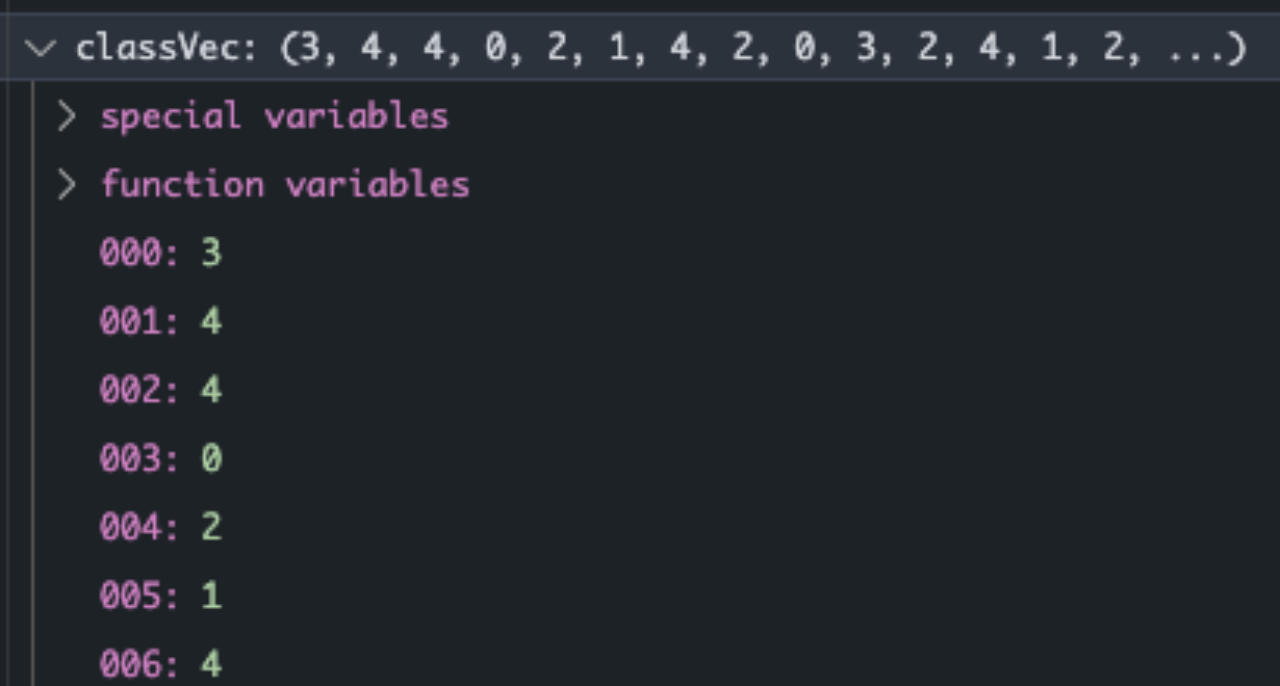
Generate word bag according to the article list 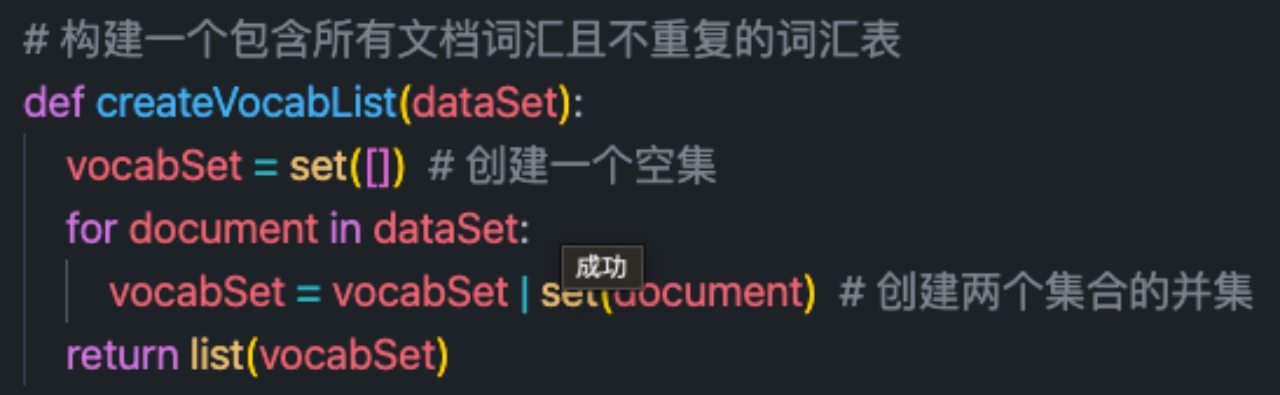
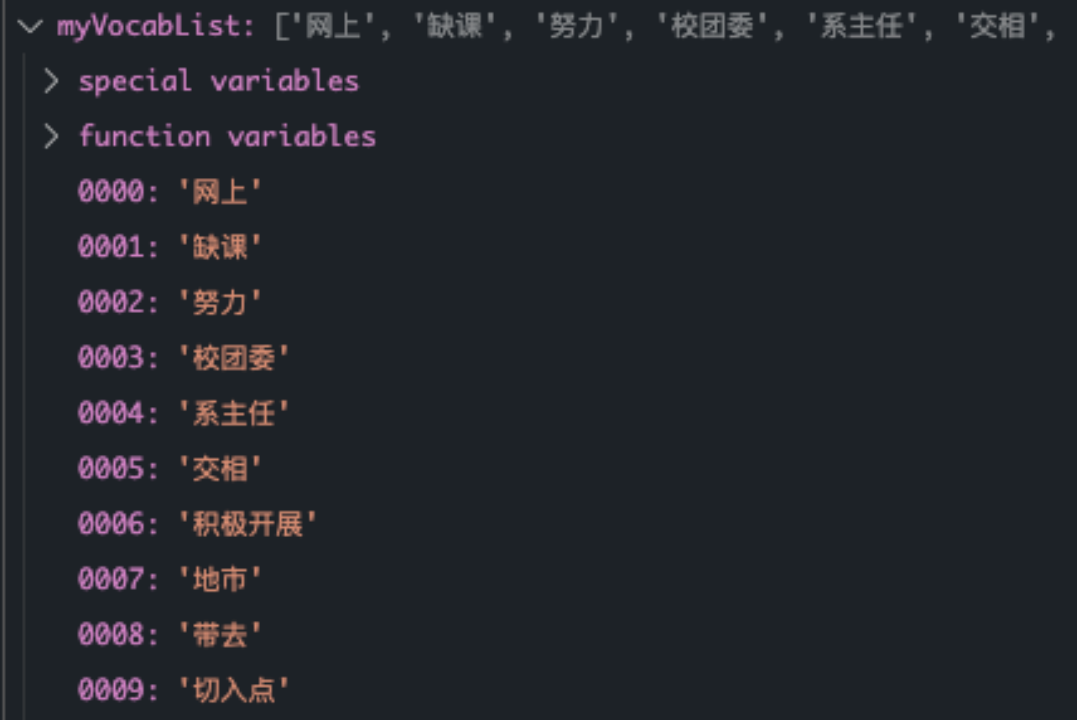
The next step is training NB The process of classifier

Naive Bayesian calculation formula is as follows :
Specifically, the following training pseudo code :
The specific implementation is as follows :
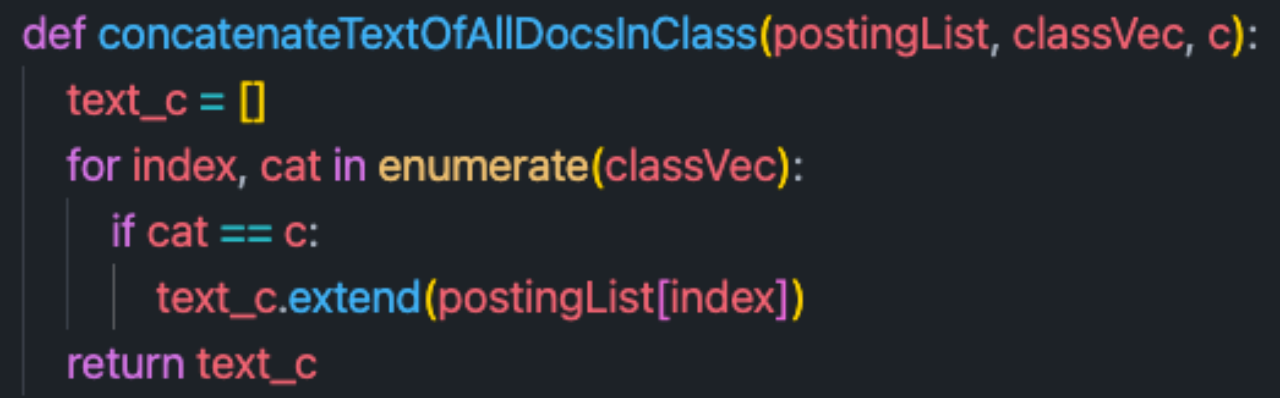
Finally, we can get the conditional probability of each word
condprob[term][c] representative term In Category c Conditional probabilities in 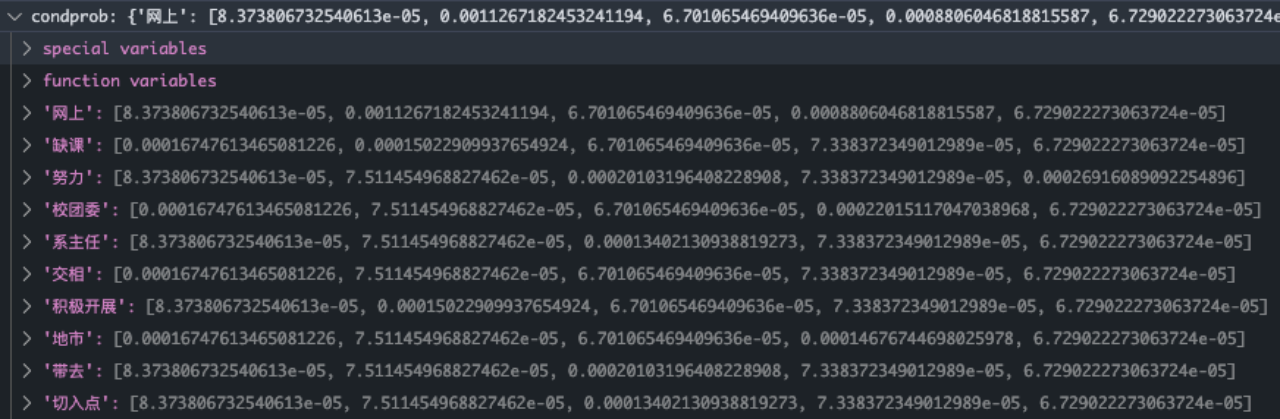
Application of naive Bayesian algorithm :
The formula is as follows : You can add log Function to solve the problem of decimal loss 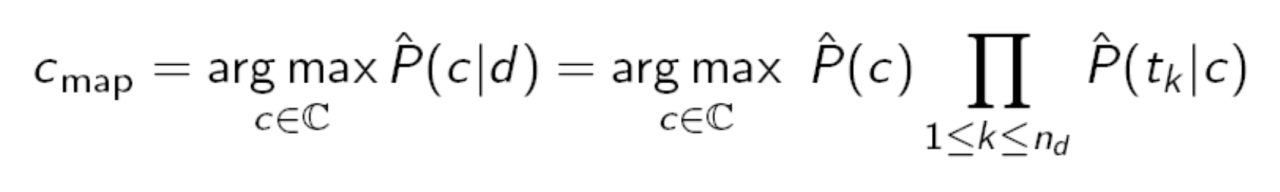
Specifically, the following training pseudo code :
applyMultinomialNB The document category with the highest probability will be returned .

Classification effect when using feature selection :
Overall accuracy 94%
Classification effect without feature selection :
Overall accuracy 86%
The classification effects of using feature selection and not using feature selection are compared and analyzed :
You can see , The classification effect is better after using feature selection . This is because after using feature selection , It can more accurately distinguish keywords from categories , In the unused process , There will be more redundant words to interfere .
Under the other two methods , The classification accuracy of the academic affairs department is not ideal . Combined with specific articles , I think the possible reason is that there are too many types of articles , The amount of data is too small to conform to the law . Therefore, it will lead to the decline of classification accuracy . I guess a feasible method is to increase the sample size , Enrich the corresponding words .
边栏推荐
- Leetcode T48: rotating images
- Leetcode t49: grouping of alphabetic words
- Data warehouse interview question preparation
- C # WPF realizes the real-time screen capture function of screen capture box
- R语言dplyr包summarise_if函数计算dataframe数据中所有数值数据列的均值和中位数、基于条件进行数据汇总分析(Summarize all Numeric Variables)
- R language ggplot2 visualization: gganimate package creates dynamic line graph animation (GIF) and uses transition_ The reveal function displays data step by step along a given dimension in the animat
- WT588F02B-8S(C006_03)单芯片语音ic方案为智能门铃设计降本增效赋能
- 關於miui12.5 紅米k20pro用au或者povo2出現問題的解决辦法
- 一种架构来完成所有任务—Transformer架构正在以一己之力统一AI江湖
- Ws2818m is packaged in cpc8. It is a special circuit for three channel LED drive control. External IC full-color double signal 5v32 lamp programmable LED lamp with outdoor engineering
猜你喜欢

Test evaluation of software testing

Digi XBee 3 rf: 4 protocols, 3 packages, 10 major functions
基于51单片机的超声波测距仪
The implementation of OSD on rk1126 platform supports color translucency and multi-channel support for Chinese
WT588F02B-8S(C006_03)单芯片语音ic方案为智能门铃设计降本增效赋能

测试流程整理(3)
gin集成支付宝支付
失败率高达80%,企业数字化转型路上有哪些挑战?
统计php程序运行时间及设置PHP最长运行时间
Leetcode T48:旋转图像
随机推荐
opencv3.2 和opencv2.4安装
Leetcode T49: 字母异位词分组
Oppo find N2 product form first exposure: supplement all short boards
Abnormal value detection using shap value
MySQL的触发器
The failure rate is as high as 80%. What are the challenges on the way of enterprise digital transformation?
What is the difference between Bi financial analysis in a narrow sense and financial analysis in a broad sense?
Why should Base64 encoding be used for image transmission
实时数据仓库
MySQL的存储过程练习题
递增的三元子序列[贪心训练]
92.(cesium篇)cesium楼栋分层
NowCoder 反转链表
codeforce:C. Sum of Substrings【边界处理 + 贡献思维 + 灵光一现】
【MySQL从入门到精通】【高级篇】(四)MySQL权限管理与控制
【云原生】我怎么会和这个数据库杠上了?
GCC [6] - 4 stages of compilation
leetcode:6109. Number of people who know the secret [definition of DP]
MySQL triggers
C# wpf 实现截屏框实时截屏功能