当前位置:网站首页>Redis's memory elimination mechanism, read this article is enough.
Redis's memory elimination mechanism, read this article is enough.
2022-07-05 12:17:00 【Xujunsheng】
Cache data elimination mechanism
Why should there be an elimination mechanism
Redis Cache uses memory to store data , It avoids the system reading data directly from the background database , Improved response speed . Due to the limited cache capacity , When the cache capacity reaches the upper limit , You need to delete some data to make room , So that new data can be added .Redis Defined 「 Elimination mechanism 」 Used to solve the problem of memory being full .
Cache elimination mechanism , Also called cache replacement mechanism , It needs to solve two problems :
- Decide which data to eliminate ;
- How to deal with obsolete data .
Now let's start to discuss Redis Memory elimination strategy in .
This article has a lot of dry goods , I hope you can read it patiently .
Redis Memory obsolescence strategy
This paper is based on Redis 4.0.9 Version analysis .
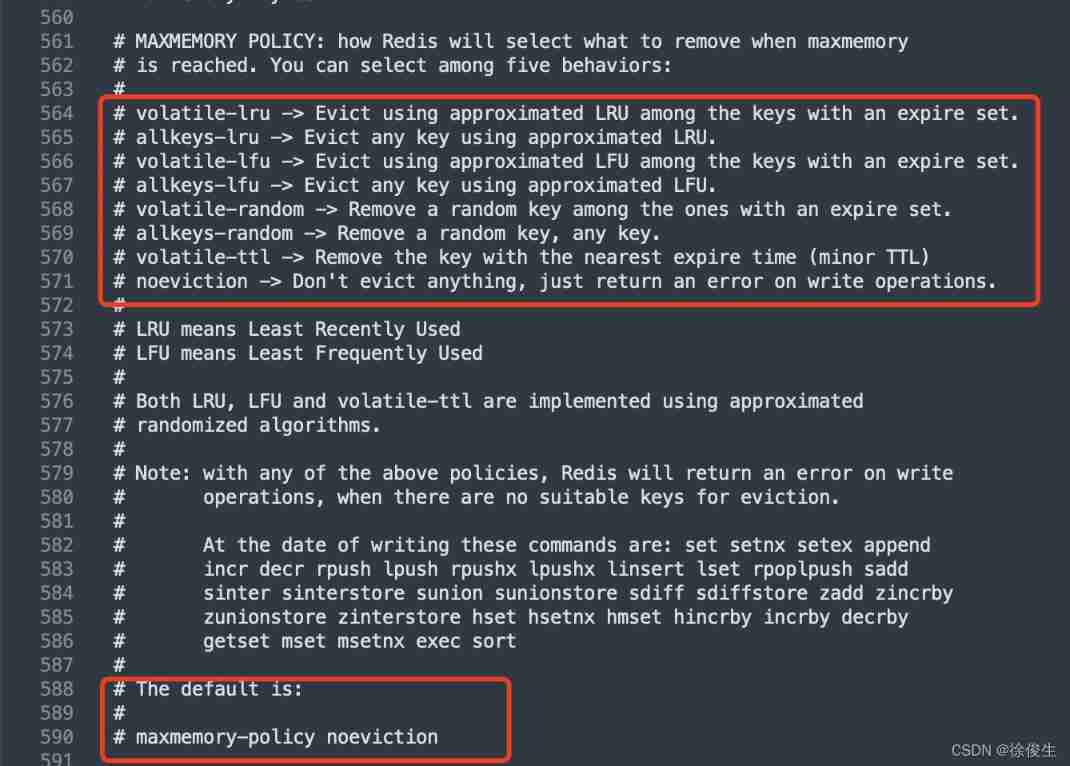
Redis 4.0 It's been realized before 6 Memory elimination strategy , stay 4.0 after , added 2 Strategies . So far ,Redis Defined 「8 Memory elimination strategy 」 Used for processing redis The memory is full :
noeviction: No data will be eliminated , When the memory space used exceedsmaxmemoryWhen the value of , Returns an error ;volatile-ttl: Filter key value pairs with expiration time , The earlier the expiration date, the earlier it is deleted ;volatile-random: Filter key value pairs with expiration time , Random delete ;volatile-lru: UseLRUThe algorithm filters key value pairs with expiration time set ;volatile-lfu: UseLFUThe algorithm selects the key value pair with expiration time set ;allkeys-random: In all key value pairs , Randomly select and delete data ;allkeys-lru: UseLRUThe algorithm filters through all the data ;allkeys-lfu:, UseLFUThe algorithm filters through all the data .
It's on it Out of memory Of 「 Elimination strategy 」, Another is the deletion strategy of expired keys , The two are different , Don't confuse .
Let's explain the meaning of each strategy .
1)、noeviction Strategy , It's also Redis Default policy , It requires Redis The memory space in use exceeds maxmemory When the value of , No data elimination . Once the cache is full , Another time to write a request ,Redis It will directly return an error .
In our actual project , This strategy is generally not used . Because our business data volume usually exceeds the cache capacity , This strategy does not eliminate data , As a result, some hot data cannot be saved in the cache , Lost the original intention of using cache .
2)、 Let's analyze volatile-random、volatile-ttl、volatile-lru、volatile-lfu These four elimination strategies . When they eliminate data , Only the key value pairs with expiration time will be filtered .
such as , We use EXPIRE The command sets the expiration time for a batch of key value pairs , Then there are two situations in which these data will be cleaned up :
- One is that the expiration time has expired , Will be deleted ;
- One is Redis The amount of memory used reaches
maxmemorythreshold ,Redis Will be based onvolatile-random、volatile-ttl、volatile-lru、volatile-lfuThese four elimination strategies , Specific rules for elimination ; That means , If a key value pair is selected by the delete policy , Even if it doesn't expire yet , It also needs to be deleted .
3)、allkeys-random,allkeys-lru,allkeys-lfu The difference between these three strategies and the above four strategies is : The data range of data filtering during elimination is all key value pairs .
We will decide whether to eliminate the data , And summarize according to the screening scope of the obsolete data set , Here's the picture :
Through our analysis above ,volatile-random、volatile-ttl as well as allkeys-random The filtering rules of are relatively simple , and volatile-lru,volatile-lfu,allkeys-lru,allkeys-lfu We used LRU and LFU Algorithm , We continue to analyze .
LRU Algorithm
LRU Algorithm full name Least Recently Used, A common page replacement algorithm . according to 「 Recently at least use 」 To filter data , Filter out the least commonly used data , Data that has been used frequently recently will remain in the cache .
LRU Filter logic for
LRU Will organize all the data into a linked list , The head and tail of a linked list represent MRU End sum LRU End , Represent the 「 Most often used recently 」 The data and 「 Not often these days 」 The data of .
Here's the picture :
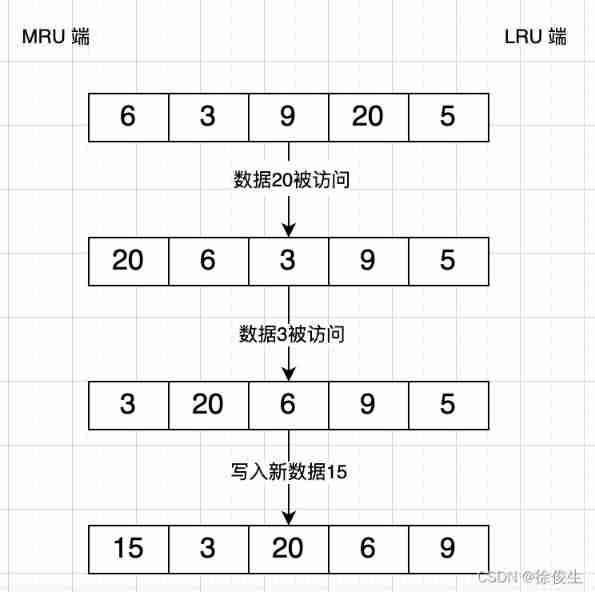
We have data now 6、3、9、20、5.
data 20 and 3 He was interviewed successively , They all move from the existing linked list position to MRU End , The data before them in the linked list moves back one bit accordingly .
because ,LRU When the algorithm chooses to delete data , from LRU End start , So move the data that has just been accessed to MRU End , You can keep them in the cache as much as possible .
If there's a new data 15 To be written to the cache , But there's no more cache space , That is, the list has no spare place , that ,LRU The algorithm does two things :
- Because of the data 15 It's just been interviewed , So it's going to be put in
MRUEnd ; - The algorithm puts
LRUEnd data 5 Remove from cache , There is no data in the corresponding linked list 5 The record of .
Actually ,LRU The algorithm logic of is very simple : It thinks , Data just accessed , It will definitely be visited again , So I put it in MRU End ;LRU The data on the end is considered to be data that has not been accessed for a long time , When the cache is full , Delete it first .
We can understand it as the background application window of the mobile phone . It always puts the most recently used window at the front , And less commonly used application windows , It's arranged in the back , If you add it, you can only place N Limitations of application windows , Eliminate the least recently used application windows , That is a living
LRU了 .
however ,LRU In the actual implementation of the algorithm , Need to use 「 Linked list 」 Manage all cached data , This brings two questions :
- Extra space overhead ;
- When data is accessed , You need to move the data to MRU End , If there's a lot of data being accessed , Will bring a lot of linked list mobile operation , It's time consuming , And then reduce Redis Cache performance .
therefore , stay Redis in ,LRU The algorithm has been simplified ,「 To reduce the impact of data obsolescence on cache performance 」.
Redis Yes LRU Implementation of algorithm
Simply speaking ,Redis Each data will be recorded by default Timestamp of the last access ( By the key value of the data structure RedisObject Medium lru Field records ).
then ,Redis When deciding on the data to be eliminated , For the first time, they will be randomly selected N Data , Take them as a candidate set .
Next ,Redis I'll compare this N Data lru Field , hold lru The data with the smallest field value is eliminated from the cache .
Redis A configuration parameter is provided maxmemory-samples, This parameter is Redis The number of alternative data selected .
for example , We execute the following order , It can make Redis elect 100 Data as an alternative data set :
config set maxmemory-samples 100
When you need to Eliminate data again when ,Redis Need to select data to enter 「 The candidate set created during the first elimination 」.
The selection criteria are : Data that can enter the candidate set lru The field value must be less than 「 The smallest in the candidate set lru value 」.
When new data enters the alternative data set , If the number of data in the alternative data set reaches the set threshold .Redis Just gather the alternative data lru The data with the smallest field value is eliminated .
such ,Redis Cache does not need to maintain a large linked list for all data , You don't have to move linked list items every time you access data , Improved cache performance .
Make a summary :
- If business data 「 There is a clear distinction between hot and cold data 」, It is recommended to use
allkeys-lruStrategy . such , Can be fully utilized LRU Advantages of algorithm , Leave the most recently accessed data in the cache , Improve the access performance of the application . - If 「 The frequency of data access is similar 」, There is no clear distinction between hot and cold data , It is recommended to use
allkeys-randomStrategy , Randomly select the eliminated data . - If there is 「 Roof placement 」 The needs of , Like top news 、 Top video , that , have access to
volatile-lruStrategy , At the same time, we don't set the expiration time for the top data . thus , The top data will never be deleted , And other data will be based onLRURules .
Analysis finished Redis How to select obsolete data , We continue to analyze Redis How to deal with these data .
How to deal with obsolete data
Generally speaking , Once the obsolete data is selected , If this data is clean , Then we'll delete ; If the data is dirty , We need to write it back to the database .
The difference between clean data and dirty data is , Compared with the value originally read from the back-end database , Has it been modified .
Clean data has not been modified , So the data in the back-end database is also the latest value . When replacing , It can be deleted directly . Dirty data is the opposite .
however , about Redis Come on , After it determines the eliminated data , Will delete them directly . Even if the obsolete data is dirty data ,Redis They will not be written back to the database .
therefore , We are using Redis When caching , If the data is modified , You need to write the data back to the database when it is modified .
otherwise , When this dirty data is eliminated , Will be Redis Delete , And there is no latest data in the database .
Analysis finished LRU We continue to analyze LFU Algorithm . Before that, let's understand a problem : Cache pollution .
Cache pollution
In some scenarios , Some data is accessed very infrequently , Even once . When these data services complete the access request , If it's still in the cache , It will only take up memory space in vain . This situation , Namely 「 Cache pollution 」.
Once cache pollution becomes serious , There will be a lot of data that is no longer accessed in the cache . If these data occupy the cache space , When we write new data to the cache , You need to phase out these data from the cache first , This introduces additional memory consumption , In turn, it will affect the performance of the application .
How to solve the cache pollution problem
Solution , That is to filter out and eliminate the data that will no longer be accessed . So you don't have to wait until the cache is full , Then eliminate the old data one by one , To write new data .
As for which data should be eliminated , It is determined by the elimination strategy of the cache .
We analyzed above Redis Of 8 Kind of elimination strategy , Let's analyze one by one , These strategies are important to solve the problem of cache pollution , Are they all effective ?
volatile-random and allkeys-random
These two strategies , They are all random memory data to be eliminated . Since it's random , that Redis It won't be based on 「 Data access 」 To filter the data .
And if the obsolete data is accessed again , A cache miss occurs . The application needs to access these data in the back-end database , Reduce the request response speed of the application .
Pictured :
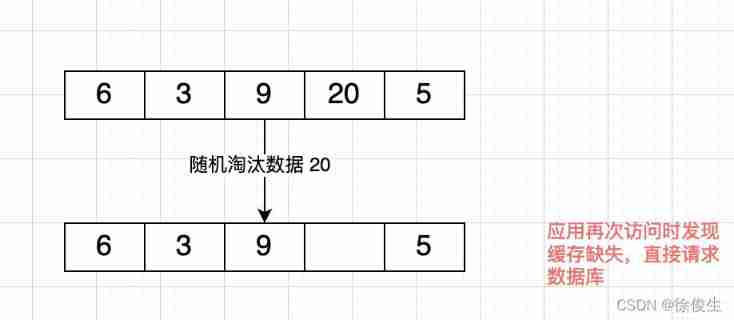
therefore ,volatile-random and allkeys-random Strategy , The effect on avoiding cache pollution is very limited .
volatile-ttl Strategy
volatile-ttl Data with expiration time set is filtered , Select and eliminate the data with the shortest remaining survival time .
although volatile-ttl The strategy is no longer random selection to eliminate data , however The remaining survival time cannot directly reflect the situation of data re access .
therefore , according to volatile-ttl Strategy obsolete data , Similar to eliminating data in a random way , It may also occur after the data is eliminated , Cache loss caused by being accessed again .
There is an exception : The business application sets the expiration time for the data , Know clearly that the data is accessed again , And set the expiration time according to the access situation .
here ,Redis Filter according to the remaining minimum survival time of the data , It can filter out data that will no longer be accessed , To avoid cache pollution .
Let's briefly summarize :
- Knowing clearly that the data is accessed again ,
volatile-ttlIt can effectively avoid cache pollution ; - In other cases ,
volatile-random、allkeys-random、volatile-ttlThese three strategies cannot deal with cache pollution .
Next , Let's analyze separately LRU Strategy , as well as Redis 4.0 Implemented after LFU Strategy .LRU The policy will be based on the timeliness of data access , To filter the data that will be eliminated , Very widely used .
LRU Strategy
LRU The core idea of strategy : If a data has just been accessed , So this data must be thermal data , Will be visited again .
Redis Medium LRU Strategy , It will be in the... Corresponding to each data RedisObject Set a... In the structure lru Field , Access time stamp used to record data .
During data obsolescence ,LRU The policy will be eliminated in the candidate data set lru The data with the smallest field value , That is, the data that has not been accessed for the longest time .
therefore , In business scenarios where data is frequently accessed ,LRU Policies can indeed effectively retain the data with the most recent access time . and , Because the retained data will be accessed again , So it can improve the access speed of the application .
however , It's also because of Just look at the access time of the data , Use LRU Strategy is dealing with 「 Scanning single query 」 In operation , Unable to resolve cache corruption .
So-called 「 Scanning single query operation 」, It means that the application reads a large amount of data at one time , Every data is read , And it will only be read once .
here , Because the queried data has just been accessed , therefore lru Field values are very large .
In the use of LRU When strategy knocks out data , This data will remain in the cache for a long time , Cause cache pollution .
If the amount of data queried is large , This data fills the cache space , But it won't serve new cache requests .
here , If there is new data to be written to the cache , We need to eliminate these old data first , This affects cache performance .
A simple example .
Here's the picture , data 6 After being interviewed , Written Redis cache . however , After that , data 6 Has not been visited again , This leads to data 6 Stuck in cache , Causing pollution .

therefore , For adopting LRU Strategic Redis Cache ,「 Scanning single query 」 Will cause cache pollution .
In order to deal with this kind of cache pollution ,Redis from 4.0 The version began to add LFU Elimination strategy .
And LRU Strategy compared to ,LFU The policy will filter and eliminate data from two dimensions :
- One is , Timeliness of data access ( How far is the access time from the current time );
- Two is , The number of times the data is accessed .
that Redis Of LFU How to implement the strategy , How to solve the cache pollution problem ? Let's keep looking .
LFU Strategy optimization
LFU The caching strategy is LRU On the basis of strategy , Add one for each data 「 Counter 」, To count the number of visits to this data .
LFU Filter rules for policies :
- When using LFU When policies filter out data , First, it will filter according to the number of times the data is accessed , Eliminate the least accessed data from the cache .
- If both data are accessed the same number of times ,LFU Strategy Then compare the access timeliness of these two data , Eliminate data that is older than the last access from the cache .
LFU The specific implementation of the strategy
We mentioned above , In order to avoid the overhead of operating the linked list ,Redis In the realization of LRU The strategy uses two approximate methods :
- Redis stay
RedisObjectIn the structurelruField , Access time stamp used to record data ; - Redis Not maintaining a global linked list for all data , But through 「 Random sampling 」 The way , Select a certain amount of data and put it into the alternative set , Then in the alternative set according to
lruFilter and delete the size of the field value .
On this basis ,Redis In the realization of LFU When it comes to strategy , Just put the original 24bit The size of lru Field , It is further divided into two parts :
- ldt value :lru First... Of the field 16bit, Represents the access timestamp of the data ;
- counter value :lru After the field 8bit, Represents the number of visits to data .
A simple example .
Suppose the first data A The cumulative number of visits is 256, The access timestamp is 202010010909, So it's counter The value is 255.
Redis Use only the 8bit Record the number of visits to the data , and 8bit The maximum value recorded is 255.
And the second data B The cumulative number of visits is 1024, The access timestamp is 202010010810.
If counter Values can only be recorded to 255, So the data B Of counter So is the value 255.
here , The cache is full ,Redis Use LFU Strategy for elimination .
Because of the data A and B Of counter Values are 255,LFU Strategies will continue to compare A and B Access timestamp for . Find data B Your last visit was earlier than A, It will B Eliminate .
But the data B The number of accesses is much greater than the number of data A, It is likely to be visited again . thus , Use LFU Strategy to eliminate data is not appropriate .
Redis This is also optimized : In the realization of LFU strategy ,Redis It doesn't take data every time it's accessed , Just give it to the corresponding counter It's worth adding 1 Counting rules for , Instead, a more optimized counting rule is adopted .
Redis Yes LFU Implementation of algorithm
Redis Realization LFU Counting rules for policies :
- Whenever data is accessed once , First use 「 The current value of the counter 」 multiply 「 Configuration item 」
lfu_log_factor, add 1; Take the reciprocal , Get one p value ; - then , Put this p Value and a value range in (0,1) Random number between r Value ratio size , Only p Greater than r When the value of , The counter is added 1.
Here is Redis Partial source code of , among ,baseval Is the current value of the counter . The initial value of the counter defaults to 5( By the LFU_INIT_VAL Constant settings ), instead of 0. This prevents data from being just written to the cache , It was eliminated immediately because of the few visits .
double r = (double)rand()/RAND_MAX;
...
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
After using this calculation rule , We can set different lfu_log_factor Configuration item , To control the speed at which the counter value increases , avoid counter The value will arrive soon 255 了 .
Redis A table provided on the official website , Go further LFU The effect of increasing the policy counter . It records when lfu_log_factor When taking different values , Under different actual visits , Change of counter value .
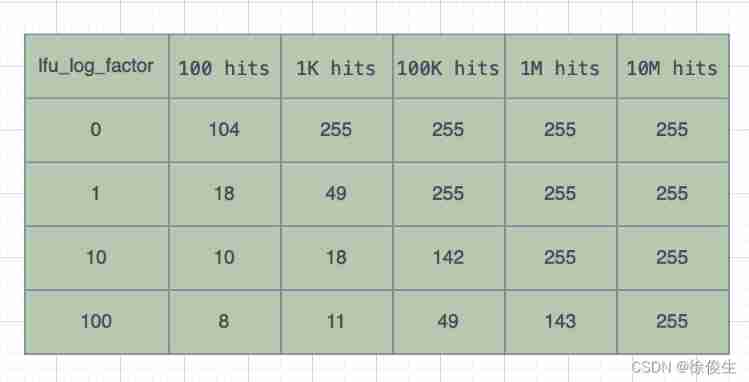
You can see , When lfu_log_factor The value is 1 when , The actual number of visits is 100K after ,counter The value reaches 255 了 , It is no longer possible to distinguish data with more actual accesses .
And when lfu_log_factor The value is 100 when , When the actual number of visits is 10M when ,counter The value reaches 255.
It is precisely because the counter method of nonlinear increment is used , Even if there are thousands of accesses to cached data ,LFU Policies can also effectively distinguish between different access times , So as to reasonably screen the data .
From the table just now , We can see , When lfu_log_factor The value is 10 when , hundred 、 thousand 、 The number of visits at 100000 levels corresponds to counter Values are clearly distinguished . therefore , We are applying LFU strategy , Generally, you can put lfu_log_factor The value is 10.
As we mentioned earlier , The application load is very complex . For example, some business scenarios , There's some data in 「 After a large number of visits in a short time, they will not be visited again 」.
Then filter according to the number of visits , This data will be kept in the cache , But it will not improve the cache hit rate .
So ,Redis In the realization of LFU strategy , And designed a 「 counter It's worth it Attenuation mechanism 」.
counter Value decay mechanism
Simply speaking ,LFU Strategy use 「 Attenuation factor configuration item 」 lfu_decay_time To control the attenuation of access times .
- LFU The strategy will calculate The difference between the current time and the last access time of the data , and Convert this difference into minutes .
- then ,LFU The strategy then divides this difference by
lfu_decay_timevalue , The result is data counter The value to attenuate .
Just a quick example , hypothesis lfu_decay_time The value is 1, If the data is in N Not visited in minutes , Then its number of visits will be reduced N.
If lfu_decay_time Larger value , Then the corresponding attenuation value will become smaller , The attenuation effect will also weaken . therefore , If there is short-term and high-frequency access data in the business application , Make a proposal to lfu_decay_time Value is set to 1,
thus ,LFU Policies after they are no longer accessed , Will decay their visits faster , Eliminate them from the cache as soon as possible , Avoid cache pollution .
Used LFU Will the policy ensure that the cache is not polluted ?
In some extreme cases ,LFU The counter used by the policy may reach a large value in a short time , And the counter 「 Attenuation configuration item 」 lfu_decay_time Set it up larger , Causes the counter value to decay very slowly , under these circumstances , The data may reside in the cache for a long time .
If you want to see more quality original articles , Welcome to my official account. 「ShawnBlog」.
边栏推荐
- Redis master-slave mode
- The survey shows that traditional data security tools cannot resist blackmail software attacks in 60% of cases
- Automated test lifecycle
- Mmclassification training custom data
- 投资理财适合女生吗?女生可以买哪些理财产品?
- 什么是数字化存在?数字化转型要先从数字化存在开始
- MySQL splits strings for conditional queries
- Matlab struct function (structure array)
- JS for循环 循环次数异常
- Seven polymorphisms
猜你喜欢
嵌入式软件架构设计-消息交互
MySQL storage engine
Yolov5 target detection neural network -- calculation principle of loss function
16 channel water lamp experiment based on Proteus (assembly language)
Course design of compilation principle --- formula calculator (a simple calculator with interface developed based on QT)
HiEngine:可媲美本地的云原生内存数据库引擎

Matlab superpixels function (2D super pixel over segmentation of image)
Embedded software architecture design - message interaction
Select drop-down box realizes three-level linkage of provinces and cities in China
Principle of redis cluster mode
随机推荐
PXE启动配置及原理
Redirection of redis cluster
How to recover the information server and how to recover the server data [easy to understand]
只是巧合?苹果 iOS16 的神秘技术竟然与中国企业 5 年前产品一致!
Reading notes of growth hacker
Pytorch linear regression
Matlab label2idx function (convert the label matrix into a cell array with linear index)
Learn memory management of JVM 01 - first memory
Codeforces Round #804 (Div. 2)
MVVM framework part I lifecycle
A guide to threaded and asynchronous UI development in the "quick start fluent Development Series tutorials"
[upsampling method opencv interpolation]
1 plug-in to handle advertisements in web pages
Matlab imoverlay function (burn binary mask into two-dimensional image)
[pytorch modifies the pre training model: there is little difference between the measured loading pre training model and the random initialization of the model]
July Huaqing learning-1
MySQL multi table operation
Codeworks 5 questions per day (1700 average) - day 5
Intern position selection and simplified career development planning in Internet companies
ABAP table lookup program