当前位置:网站首页>[deploy pytoch project through onnx using tensorrt]
[deploy pytoch project through onnx using tensorrt]
2022-07-05 11:42:00 【Network starry sky (LUOC)】
List of articles
1 Model scheme
TensorRT The installation of can be described according to the blog TensorRT Installation and usage guide and windows install tensorrt understand .
quote 【1】 title :TensorRT Installation and usage guide link :
https://blog.csdn.net/zong596568821xp/article/details/86077553
author :ZONG_XP
quote 【2】 title : windows install tensorrt link :
https://zhuanlan.zhihu.com/p/339753895
author : Know user 15Z1y4
1.1 Deployment process
be based on ONNX Route , call C++、Python Interface and hand it over to Builder, Finally, build the engine .
1.2 Export correctly onnx
I wrote a simple example :
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(in_channels=1,out_channels=1,kernel_size=3,stride=1,padding=1,bias=True)
self.conv.weight.data.fill_(1)
self.conv.bias.data.fill_(1)
def forward(self,x):
x = self.conv(x)
return x.view(-1,int(x.numel()//x.size(0)))
model = Model().eval()
x = torch.full((1,1,3,3),1.0)
y = model(x)
torch.onnx.export(
model,(x,),"test.onnx",verbose=True
)
use netron Import the generated onnx file , The network structure and parameters can be viewed online :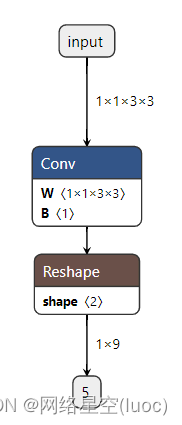
1.3 stay C++ Use in
First of all, will tensorRT The next path include Copy files in to cuda Corresponding include Under the folder ,lib In the folder lib Document and dll The files are copied to cuda Corresponding lib/x64 Under the folder and bin Under the folder .
To configure VS Environmental Science , Here is the list of required configurations :
├── VC++ Catalog
│├── Contains the directory
%OPENCV_PATH%\opencv\build\include
%OPENCV_PATH%\opencv\build\include\opencv2
│├── The library catalog
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3\lib\x64
%OPENCV_PATH%\opencv\build\x64\vc15\lib
├──C/C++
│├── routine
││├── Attach include directory
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3\include
├── The linker
│├── routine
││├── Additional Library Directory
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3\lib\x64
│├── Input
││├── Additional dependency
c10.lib
libprotobuf.lib
mkldnn.lib
torch.lib
torch_cpu.lib
nvinfer.lib
nvinfer_plugin.lib
nvonnxparser.lib
nvparsers.lib
cudnn.lib
cublas.lib
cudart.lib
nvrtc.lib
opencv_world3416.lib
according to TensorRT In the official developer's Guide C++ API example , The development process is as follows :
1.3.1 Construction phase
First create builder, First instantiation ILogger Interface to catch exceptions :
class Logger : public ILogger
{
void log(Severity severity, const char* msg) override
{
// suppress info-level messages
if (severity <= Severity::kWARNING)
std::cout << msg << std::endl;
}
} logger;
But writing according to official documents will report an error : The restrictive exception specification of overriding virtual functions is better than that of base class virtual member functions
I saw the official sample,logging.h In the writing 
So this is changed to :
class Logger : public ILogger
{
//void log(Severity severity, const char* msg) override
void log(Severity severity, const char* msg) noexcept override
{
// suppress info-level messages
if (severity <= Severity::kWARNING)
std::cout << msg << std::endl;
}
} logger;
Then instantiate builder:
IBuilder* builder = createInferBuilder(logger);
Instantiation builder after , The first step in optimizing the model is to create a network definition :
uint32_t flag = 1U <<static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH)
INetworkDefinition* network = builder->createNetworkV2(flag);
After defining the network , You can create ONNX Parser to populate the network :
IParser* parser = createParser(*network, logger);
then , Read the model file and handle any errors :
parser->parseFromFile(modelFile, ILogger::Severity::kWARNING);
for (int32_t i = 0; i < parser.getNbErrors(); ++i)
{
std::cout << parser->getError(i)->desc() << std::endl;
}
Then build engine, Create a build configuration , Appoint TensorRT How to optimize the model .
unsigned int maxBatchSize = 1;
builder->setMaxBatchSize(maxBatchSize);
IBuilderConfig* config = builder->createBuilderConfig();
This interface has many properties , You can set these properties to control TensorRT How to optimize the network . An important attribute is the maximum workspace size . Layer implementations usually require a temporary workspace , And this parameter limits the maximum size that can be used by any layer in the network . If the workspace provided is insufficient ,TensorRT The implementation of the layer may not be found .
config->setMaxWorkspaceSize(1U << 20);
Specify the configuration to build the engine , Serialization model , Namely the engine Convert to a storable format for later use . Inference time , Simply deserialize this engine It can be directly used for reasoning . Usually create a engine It takes a lot of time , You can use this serialization method to avoid every time you re create engine:
IHostMemory* serializedModel = builder->buildSerializedNetwork(*network, *config);
The serialization engine contains the necessary weight copies , Parser 、 Network definition 、 The builder configuration and builder are no longer required , Can be safely removed :
delete parser;
delete network;
delete config;
delete builder;
1.3.2 Deserialization model
Assume that you have serialized an optimization model and want to perform reasoning :
IRuntime* runtime = createInferRuntime(logger);
ICudaEngine* engine = runtime->deserializeCudaEngine(modelData, modelSize);
1.3.3 To carry out reasoning
IExecutionContext *context = engine->createExecutionContext();
int32_t inputIndex = engine->getBindingIndex(INPUT_NAME);
int32_t outputIndex = engine->getBindingIndex(OUTPUT_NAME);
void* buffers[2];
buffers[inputIndex] = inputBuffer;
buffers[outputIndex] = outputBuffer;
context->enqueueV2(buffers, stream, nullptr);
This is for asynchronous reasoning enqueueV2, If you want synchronous reasoning , have access to excuteV2
2 Use TensorRT Deploy YOLOv5
2.1 download YOLOv5 Source code
download https://github.com/ultralytics/yolov5master Branch .
2.2 export YOLOv5 onnx Model
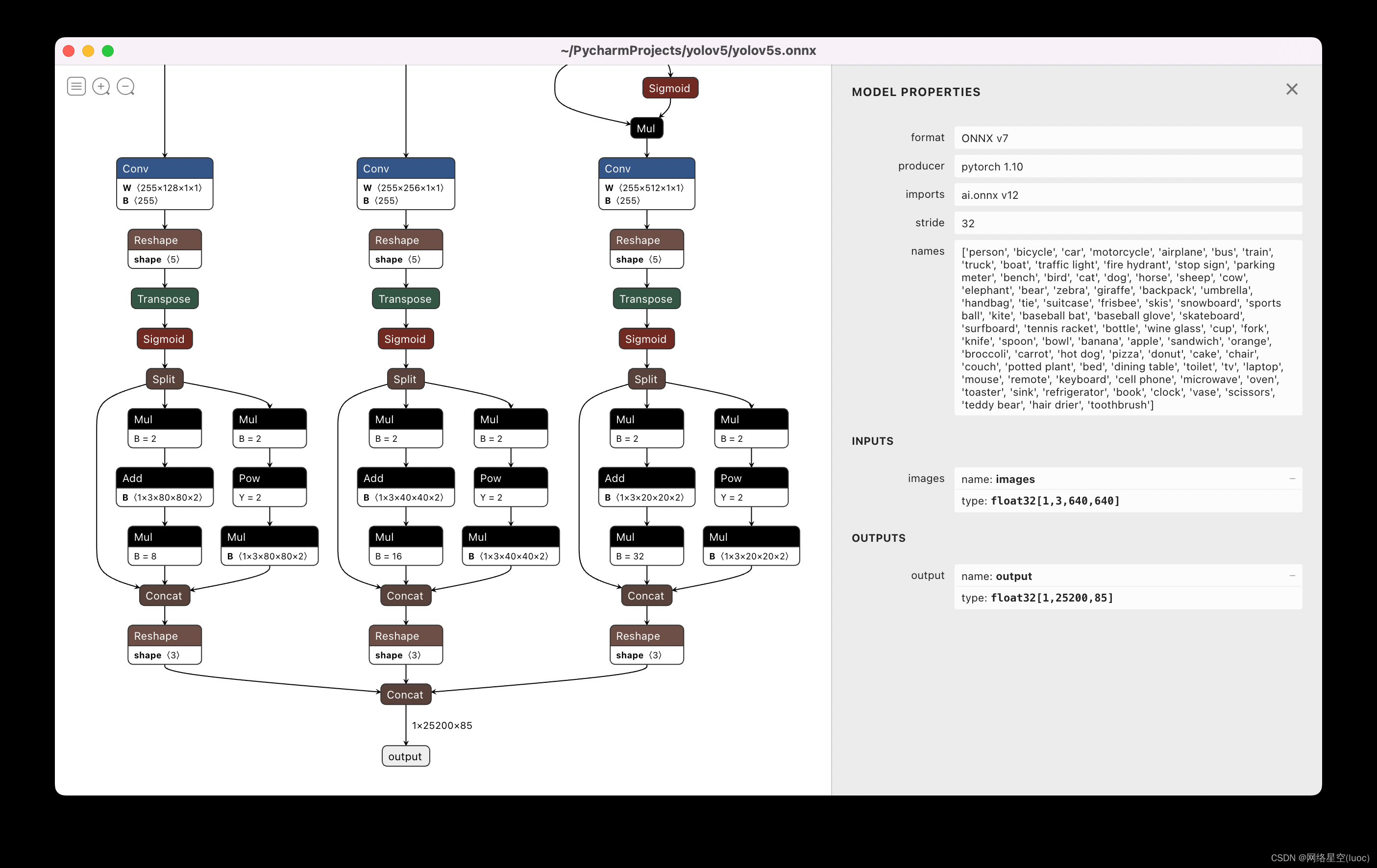
open export.py Files are generated after they are run directly yolov5s.onnx file , Open it as shown in the figure :

2.3 stay C++ Use in
Load exported yolov5s.onnx And reason ( The complete code of the project is in TensorRT Deploy yoloV5 Source code ):
#include <iostream>
#include "NvOnnxParser.h"
#include "NvInfer.h"
#include "opencv2/opencv.hpp"
#include <cuda_runtime_api.h>
using namespace cv;
using namespace nvinfer1;
using namespace nvonnxparser;
using namespace std;
class Logger : public ILogger
{
//void log(Severity severity, const char* msg) override
void log(Severity severity, nvinfer1::AsciiChar const* msg) noexcept override
{
// suppress info-level messages
if (severity <= Severity::kWARNING)
std::cout << msg << std::endl;
}
} gLogger;
int main() {
// Instantiation builder
IBuilder* builder = createInferBuilder(gLogger);
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH));
// load onnx file
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, gLogger);
const char* onnx_filename = "yolov5s.onnx";
parser->parseFromFile(onnx_filename, static_cast<int>(Logger::Severity::kWARNING));
for (int i = 0; i < parser->getNbErrors(); ++i)
{
std::cout << parser->getError(i)->desc() << std::endl;
}
std::cout << "successfully load the onnx model" << std::endl;
// Create the engine
unsigned int maxBatchSize = 1;
builder->setMaxBatchSize(maxBatchSize);
IBuilderConfig* config = builder->createBuilderConfig();
config->setMaxWorkspaceSize(1 << 20);
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
// serialize
IHostMemory* serializedModel = engine->serialize();
std::ofstream serialize_output_stream("./build/yolov5_engine_output.trt", std::ios_base::out | std::ios_base::binary);;
serialize_output_stream.write((char*)serializedModel->data(), serializedModel->size());
serialize_output_stream.close();
delete parser;
delete network;
delete config;
delete builder;
// Deserialization
IRuntime* runtime = createInferRuntime(gLogger);
std::string cached_path = "./build/yolov5_engine_output.trt";
std::ifstream trtModelFile(cached_path, std::ios_base::in | std::ios_base::binary);
trtModelFile.seekg(0, ios::end);
int size = trtModelFile.tellg();
trtModelFile.seekg(0, ios::beg);
char* buff = new char[size];
trtModelFile.read(buff, size);
trtModelFile.close();
ICudaEngine* re_engine = runtime->deserializeCudaEngine((void*)buff, size, NULL);
delete buff;
// establish context
// establish context
IExecutionContext* context = re_engine->createExecutionContext();
// The image processing
string img_path = "bus.jpg";
cv::Mat img = imread(img_path);
int h = img.rows;// Get the length of the picture
int w = img.cols;// Get the width of the picture
cvtColor(img, img, COLOR_BGR2YCrCb);// Convert the picture to YCrCb
vector<Mat> over;
split(img, over);
over[0].convertTo(over[0], CV_32F, 1 / 255.0); // take Y Channel normalization
// establish buffers Point to input / output stream
void* buffers[2];
int inputIndex;
int outputIndex;
for (int bi = 0; bi < re_engine->getNbBindings(); bi++)
{
if (re_engine->bindingIsInput(bi) == true)
inputIndex = bi;
else
outputIndex = bi;
}
// Distribute buffers Space
cudaMalloc(&buffers[inputIndex], h * w * sizeof(float));
cudaMalloc(&buffers[outputIndex], h * 2 * w * 2 * sizeof(float));// The size of the superscript
// establish cuda flow
cudaStream_t stream;
cudaStreamCreate(&stream);
// Copy picture data to GPU
cudaMemcpyAsync(&buffers[inputIndex], &over[0], h * w * sizeof(float), cudaMemcpyHostToDevice, stream);
// To carry out reasoning
context->enqueue(1, buffers, stream, nullptr);
// take 3 The size of each channel after being converted into a super division
for (int i = 0; i < 3; i++)
resize(over[i], over[i], Size(w * 2, h * 2), 0, 0, INTER_CUBIC);
// take GPU Copy data back to CPU
cudaMemcpy(&over[0], &buffers[outputIndex], h * 2 * w * 2 * sizeof(float), cudaMemcpyDeviceToHost);
// Anti normalization , Convert data type
over[0].convertTo(over[0], CV_8U, 1 * 255);
// Merge 3 passageway , write file
merge(over, img);
// take YCrCb Turn it back RGB(opencv Medium is BGR), write file ;
cvtColor(img, img, COLOR_YCrCb2BGR);
imwrite("bus_infer.jpg", img);
// Release resources
cudaStreamDestroy(stream);
context->destroy();
re_engine->destroy();
runtime->destroy();
cudaFree(buffers[inputIndex]);
return 0;
}
Running results :

If you make a mistake C4996:
‘XXXX’: This function or variable may be unsafe. Consider using localtime_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.
Add... To the error file :
#pragma warning(disable:4996)
If you make a mistake C2664:
“HMODULE LoadLibraryW(LPCWSTR)”: Unable to set parameter 1 from “const _Elem *” Convert to “LPCWSTR”
Right click solution -> attribute -> Configuration properties -> senior -> Character set
take " Use Unicode Character set " Change to " Using multibyte character sets "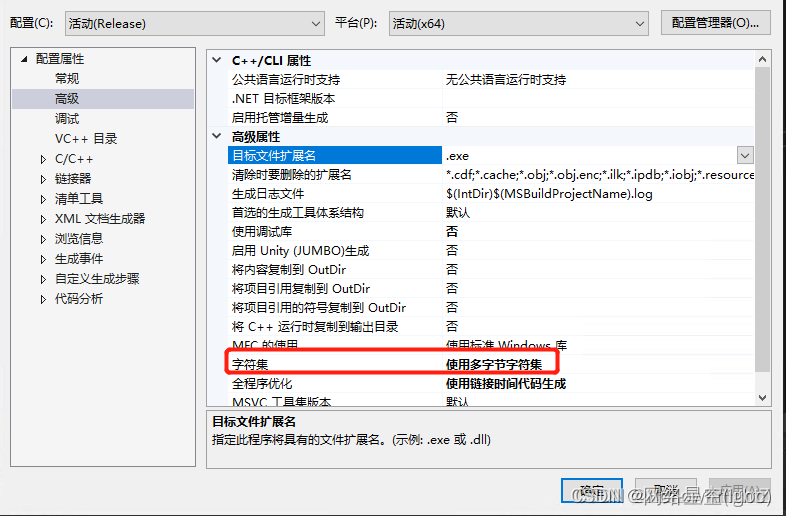
TensorRT Report errors :
TensorRT was linked against cuBLAS/cuBLAS LT 11.6.3 but loaded cuBLAS/cuBLAS LT 11.5.1
By checking the blog https://blog.csdn.net/qq_41151162/article/details/118735414 Found to be cuda Version of the problem .
TensorRT Report errors :
Parameter check failed at: ...
The reason for this is that the pre training model does not match the network structure , Regenerate the corresponding pre training model .
边栏推荐
- Error assembling WAR: webxml attribute is required (or pre-existing WEB-INF/web.xml if executing in
- View all processes of multiple machines
- C#实现WinForm DataGridView控件支持叠加数据绑定
- COMSOL--三维随便画--扫掠
- 1.php的laravel创建项目
- Advanced technology management - what is the physical, mental and mental strength of managers
- 【主流Nivida显卡深度学习/强化学习/AI算力汇总】
- POJ 3176-Cow Bowling(DP||记忆化搜索)
- 如何通俗理解超级浏览器?可以用于哪些场景?有哪些品牌?
- CDGA|数据治理不得不坚持的六个原则
猜你喜欢

无密码身份验证如何保障用户隐私安全?

Ziguang zhanrui's first 5g R17 IOT NTN satellite in the world has been measured on the Internet of things
【Win11 多用户同时登录远程桌面配置方法】
《增长黑客》阅读笔记
COMSOL--三维图形的建立
【TFLite, ONNX, CoreML, TensorRT Export】

11.(地图数据篇)OSM数据如何下载使用
【PyTorch预训练模型修改、增删特定层】
紫光展锐全球首个5G R17 IoT NTN卫星物联网上星实测完成

Is it difficult to apply for a job after graduation? "Hundreds of days and tens of millions" online recruitment activities to solve your problems
随机推荐
Pytorch training process was interrupted
Harbor镜像仓库搭建
pytorch-线性回归
The ninth Operation Committee meeting of dragon lizard community was successfully held
MySQL 巨坑:update 更新慎用影响行数做判断!!!
Ziguang zhanrui's first 5g R17 IOT NTN satellite in the world has been measured on the Internet of things
分类TAB商品流多目标排序模型的演进
Project summary notes series wstax kt session2 code analysis
Question and answer 45: application of performance probe monitoring principle node JS probe
Go language learning notes - analyze the first program
项目总结笔记系列 wsTax KT Session2 代码分析
MySQL statistical skills: on duplicate key update usage
Programmers are involved and maintain industry competitiveness
12. (map data) cesium city building map
How to understand super browser? What scenarios can it be used in? What brands are there?
2048游戏逻辑
查看多台机器所有进程
Dynamic SQL of ibatis
yolov5目标检测神经网络——损失函数计算原理
7.2 daily study 4