当前位置:网站首页>Tidb backup and recovery introduction
Tidb backup and recovery introduction
2022-07-06 08:02:00 【Tianxiang shop】
This document describes how to Kubernetes Upper TiDB The cluster performs data backup and data recovery . The tools used in backup and recovery are Dumpling、TiDB Lightning and BR.
Dumpling Is a data export tool , The tool can store in TiDB/MySQL The data in is exported as SQL perhaps CSV Format , It can be used to complete logical full backup or export .
TiDB Lightning Is a data import tool , This tool can put Dumpling or CSV Data in output format can be quickly imported into TiDB in , It can be used to complete logical full recovery or import .
BR yes TiDB Command line tools for distributed backup and recovery , Used to deal with TiDB Cluster for data backup and recovery . comparison Dumpling and Mydumper,BR It is more suitable for scenarios with a large amount of data ,BR Only support TiDB v3.1 And above . If you need incremental backups that are not sensitive to latency , see also BR. If you need real-time incremental backup , see also TiCDC.
Use scenarios
The data backup
If you have the following requirements for data backup , Consider using BR Yes TiDB Data backup :
- The amount of data backed up is large ( Greater than 1 TB), And it requires faster backup
- Directly backup data SST file ( Key value pair )
- Delay insensitive incremental backup
BR Relevant use documents can be referred to :
- Use BR Backup TiDB Cluster to compatible S3 The storage
- Use BR Backup TiDB Cluster to GCS
- Use BR Backup TiDB Cluster to Azure Blob Storage
- Use BR Backup TiDB Cluster to persistent volume
If you have the following requirements for data backup , Consider using Dumpling Yes TiDB Data backup :
- export SQL or CSV Formatted data
- For single SQL Limit the memory of the statement
- export TiDB Snapshot of historical data
Dumpling Relevant use documents can be referred to :
- Use Dumpling Backup TiDB Cluster data to compatible S3 The storage
- Use Dumpling Backup TiDB Cluster data to GCS
Data recovery
If you need from BR Backed up SST File pair TiDB Data recovery , You should use BR. Relevant use documents can be referred to :
- Use BR Restore compatibility S3 Backup data on storage
- Use BR recovery GCS Backup data on
- Use BR recovery Azure Blob Storage Backup data on
- Use BR Restore the backup data on the persistent volume
If you need from Dumpling Exported or other format compatible SQL or CSV File pair TiDB Data recovery , You should use TiDB Lightning. Relevant use documents can be referred to :
- Use TiDB Lightning Restore compatibility S3 Backup data on storage
- Use TiDB Lightning recovery GCS Backup data on
Backup and recovery process
In order to Kubernetes Upper TiDB Cluster data backup , Users need to create a custom Backup Custom Resource (CR) Object to describe a backup , Or create a custom BackupSchedule CR Object to describe a scheduled backup .
In order to Kubernetes Upper TiDB Cluster for data recovery , Users can create a customized Restore CR Object to describe a recovery .
After creating the corresponding CR After the object ,TiDB Operator The backup or recovery will be performed according to the corresponding configuration and select the corresponding tool .
Delete the backed up Backup CR
The user can delete the corresponding backup by the following statement CR Or regular full backup CR.
kubectl delete backup ${name} -n ${namespace} kubectl delete backupschedule ${name} -n ${namespace}
If you use v1.1.2 And previous versions , Or use v1.1.3 And later versions will spec.cleanPolicy Set to Delete when ,TiDB Operator In the delete CR The backup files will be cleaned up at the same time .
When the above conditions are met , If you need to delete namespace, It is suggested to delete all Backup/BackupSchedule CR, And then delete namespace.
If it is deleted directly Backup/BackupSchedule CR Of namespace,TiDB Operator Will continue to try to create Job Clean up the backed up data , But because namespace be in Terminating State and failed to create , Which leads to namespace Stuck in this state .
At this time, you need to delete finalizers:
kubectl patch -n ${namespace} backup ${name} --type merge -p '{"metadata":{"finalizers":[]}}'
Clean up backup files
TiDB Operator v1.2.3 And previous versions , The way to clean up backup files is : Delete backup files circularly , Delete one file at a time .
TiDB Operator v1.2.4 And later versions , The way to clean up backup files is : Delete backup files circularly , Delete multiple files in batch at a time . For the operation of deleting multiple files in batch each time , Depending on the type of back-end storage used for backup , There are different ways to delete .
- S3 Compatible back-end storage adopts concurrent batch deletion .TiDB Operator Start multiple Go coroutines , Every Go The interface is deleted in batches every time the coroutine calls "DeleteObjects" To delete multiple files .
- Other types of back-end storage adopt concurrent deletion .TiDB Operator Start multiple Go coroutines , Every Go The process Deletes one file at a time .
about TiDB Operator v1.2.4 And later versions , You can use Backup CR The following fields in control the cleanup behavior :
.spec.cleanOption.pageSize: Specify the number of files to be deleted in batch each time . The default value is 10000..spec.cleanOption.disableBatchConcurrency: When set to true when ,TiDB Operator Will disable concurrent batch deletion , Use concurrent deletion .If S3 Compatible backend storage does not support
DeleteObjectsInterface , The default concurrent batch deletion will fail , This field needs to be configured astrueTo use concurrent deletion ..spec.cleanOption.batchConcurrency: Specify the Go Number of trips . The default value is 10..spec.cleanOption.routineConcurrency: Specify the Go Number of trips . The default value is 100.
边栏推荐
- Pangolin Library: control panel, control components, shortcut key settings
- How to prevent Association in cross-border e-commerce multi account operations?
- Transformer principle and code elaboration
- "Designer universe": "benefit dimension" APEC public welfare + 2022 the latest slogan and the new platform will be launched soon | Asia Pacific Financial Media
- The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
- Qualitative risk analysis of Oracle project management system
- What are the ways to download network pictures with PHP
- C语言 - 位段
- Leetcode question brushing record | 203_ Remove linked list elements
- 【Redis】NoSQL数据库和redis简介
猜你喜欢
![[t31zl intelligent video application processor data]](/img/67/b77c1de990d9b8868f8df5e55b0227.png)
[t31zl intelligent video application processor data]
在 uniapp 中使用阿里图标
![08- [istio] istio gateway, virtual service and the relationship between them](/img/fb/09793f5fd12c2906b73cc42722165f.jpg)
08- [istio] istio gateway, virtual service and the relationship between them

Artcube information of "designer universe": Guangzhou implements the community designer system to achieve "great improvement" of urban quality | national economic and Information Center

How to prevent Association in cross-border e-commerce multi account operations?
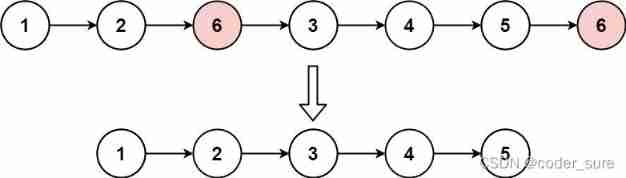
Leetcode question brushing record | 203_ Remove linked list elements
22. Empty the table
你想知道的ArrayList知识都在这
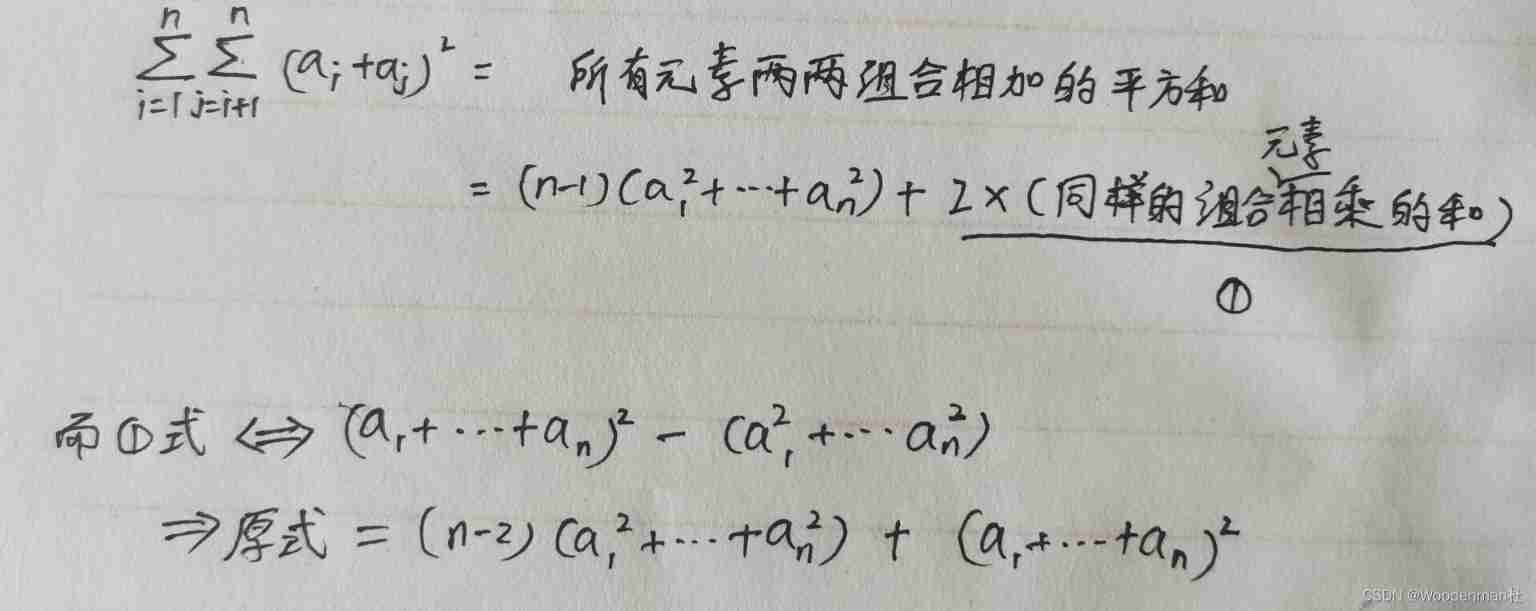
Codeforces Global Round 19(A~D)
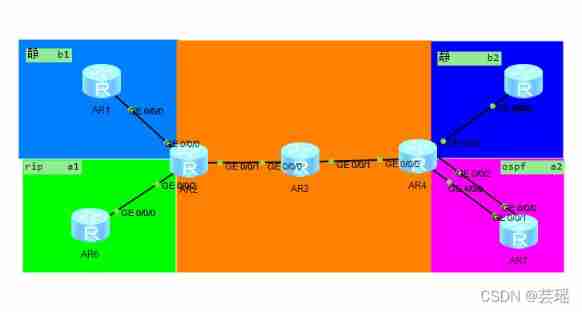
hcip--mpls
随机推荐
Interview Reply of Zhuhai Jinshan
珠海金山面试复盘
861. Score after flipping the matrix
649. Dota2 Senate
备份与恢复 CR 介绍
National economic information center "APEC industry +": economic data released at the night of the Spring Festival | observation of stable strategy industry fund
将 NFT 设置为 ENS 个人资料头像的分步指南
二叉树创建 & 遍历
Qualitative risk analysis of Oracle project management system
Chinese Remainder Theorem (Sun Tzu theorem) principle and template code
Mex related learning
Circuit breaker: use of hystrix
Introduction to number theory (greatest common divisor, prime sieve, inverse element)
使用 TiDB Lightning 恢复 S3 兼容存储上的备份数据
让学指针变得更简单(三)
Data governance: Data Governance under microservice architecture
Notes on software development
Analysis of Top1 accuracy and top5 accuracy examples
Transformer principle and code elaboration
Description of octomap averagenodecolor function