当前位置:网站首页>PACP学习笔记一:使用 PCAP 编程
PACP学习笔记一:使用 PCAP 编程
2022-07-07 11:00:00 【山鬼谣me】
pcap代码流程
- 我们首先确定要嗅探哪个接口。在 Linux 中这可能是 eth0,在 BSD 中可能是 xl1,等等。我们可以在字符串中定义这个设备,或者我们可以让 pcap 为我们提供一个接口的名称来完成这项工作。
- 初始化pcap。这其实是实际告诉pcap我们正在嗅探什么设备。如果我们愿意嗅探多个设备。我们如何区分它们呢?使用文件句柄。就行打开一个文件进行读取和写入一样,我们必须将我们的嗅探命名为“会话”,以便我们可以将它与其他此类会话区分开来。
- 如果我们只想嗅探特定流量(例如:仅 TCP/IP 数据包,仅发送到端口 23 的数据包等),我们必须创建一个规则集,“编译”并应用它。这是一个三个阶段的过程,所有这些都是密切相关的。规则集保存在一个字符串中,并转换为 pcap 可以读取的格式(因此对其进行编译)。编译实际上只是通过在我们的程序中调用一个函数来完成的;它不涉及使用外部应用程序。然后我们告诉 pcap 将它应用于我们希望它过滤的任何会话。
- 最后,我们告诉 pcap 进入它的主要执行循环。在这种状态下,pcap 会一直等待,直到它接收到我们希望它接收到的任何数据包。每次它收到一个新数据包时,它都会调用我们已经定义的另一个函数。它调用的函数可以做任何我们想做的事情;它可以剖析数据包并将其打印给用户,它可以将其保存在一个文件中,或者它什么也不做。
- 在满足我们的嗅探需求后,我们关闭会话并完成。
这实际上是一个非常简单的过程。总共五个步骤,其中一个是可选的(步骤 3,如果您想知道的话)。让我们看一下每个步骤以及如何实现它们。
设置设备
这非常简单。有两种技术可以设置我们希望嗅探的设备。
首先是我们可以简单地让用户告诉我们。考虑以下程序:
#include <stdio.h>
#include <pcap.h>
int main(int argc, char *argv[])
{
char *dev = argv[1];
printf("Device: %s\n", dev);
return(0);
}
用户通过将设备名称作为第一个参数传递给程序来指定设备。现在字符串 dev 以 pcap 可以理解的格式保存我们将嗅探的接口名称(当然,假设用户给了我们一个真实的接口)。
另一种技术同样简单。看看这个程序:
#include <stdio.h>
#include <pcap.h>
int main(int argc, char *argv[])
{
char *dev, errbuf[PCAP_ERRBUF_SIZE];
dev = pcap_lookupdev(errbuf);
if (dev == NULL) {
fprintf(stderr, "Couldn't find default device: %s\n", errbuf);
return(2);
}
printf("Device: %s\n", dev);
return(0);
}
在这种情况下,pcap 只是自行设置设备。 “但是等等, “errbuf 字符串是怎么回事?”,大多数 pcap 命令允许我们将字符串作为参数传递给它们。这个字符串的目的是什么?如果命令失败,它将使用错误描述填充字符串。在这种情况下,如果 pcap_lookupdev(3PCAP) 失败,它将在 errbuf 中存储错误消息。这就是我们设置设备的方式。
打开设备进行嗅探
创建嗅探会话的任务非常简单。为此,我们使用 pcap_open_live(3PCAP)。这个函数的原型如下:
pcap_t *pcap_open_live(char *device, int snaplen, int promisc, int to_ms,
char *ebuf)
| 参数字段 | 说明 |
|---|---|
| 第一个参数 | 第一个参数是我们在上一节中指定的设备。 |
| 第二个参数 | snaplen 是一个整数,它定义了 pcap 捕获的最大字节数。 |
| 第三个参数 | promisc,当设置为 true 时,使接口进入混杂模式(然而,即使它设置为 false,在特定情况下,接口也可能处于混杂模式,无论如何)。 |
| 第四个参数 | to_ms 是以毫秒为单位的读取超时时间(值 0 表示没有超时;至少在某些平台上,这意味着您可能要等到足够数量的数据包到达才能看到任何数据包,因此您应该使用非零暂停) |
| 第五个参数 | ebuf 是一个字符串,我们可以在其中存储任何错误消息(就像我们在上面使用 errbuf 所做的那样)。 |
| 返回值 | 该函数返回我们的会话处理程序 |
为了演示,请考虑以下代码片段:
#include <pcap.h>
...
pcap_t *handle;
handle = pcap_open_live(dev, BUFSIZ, 1, 1000, errbuf);
if (handle == NULL) {
fprintf(stderr, "Couldn't open device %s: %s\n", dev, errbuf);
return(2);
}
此代码片段打开存储在字符串 dev 中的设备,告诉它读取在 BUFSIZ 中指定的许多字节(通常通过 pcap.h 在 /usr/include/stdio.h 中定义)。我们告诉它让设备进入混杂模式,嗅探直到发生错误,如果有错误,将其存储在字符串 errbuf 中;它使用该字符串来打印错误消息。
关于混杂与非混杂嗅探的说明:这两种技术在风格上非常不同。在标准的非混杂嗅探中,主机仅嗅探与其直接相关的流量。嗅探器只会获取到、来自或路由通过主机的流量。另一方面,混杂模式会嗅探线路上的所有流量。在非交换环境中,这可能是所有网络流量。这样做的明显优势是它提供了更多用于嗅探的数据包,这可能会或可能不会有帮助,具体取决于您嗅探网络的原因。然而,也有倒退。混杂模式嗅探是可检测的;一个主机可以通过测试来确定另一个主机是否在进行混杂嗅探。其次,它仅适用于非交换环境(例如集线器,或被 ARP 泛洪的交换机)。第三,在高流量网络上,主机可能会占用大量系统资源。
并非所有设备都在您读取的数据包中提供相同类型的链路层标头。以太网设备和一些非以太网设备可能提供以太网标头,但其他设备类型,例如 BSD 和 OS X 中的环回设备、PPP 接口和在监控模式下捕获时的 Wi-Fi 接口,则不提供。
您需要确定设备提供的链路层标头的类型,并在处理数据包内容时使用该类型。 pcap_datalink(3PCAP) 例程返回一个值,指示链路层标头的类型;请参阅链路层标头类型值列表。它返回的值是该列表中的 DLT_ 值。
如果你的程序不支持设备提供的链路层头类型,就不得不放弃;这将通过代码完成,例如:
if (pcap_datalink(handle) != DLT_EN10MB) {
fprintf(stderr, "Device %s doesn't provide Ethernet headers - not supported\n", dev);
return(2);
}
如果设备不提供以太网标头,则会失败。这适用于下面的代码,因为它假定以太网标头。
过滤流量
很多时候,我们的嗅探器可能只对特定流量感兴趣。例如,有时我们想要的只是嗅探端口 23 (telnet) 以搜索密码。或者我们可能想要劫持通过端口 21 (FTP) 发送的文件。也许我们只想要 DNS 流量(端口 53 UDP)。无论如何,我们很少只想盲目地嗅探所有网络流量。这是就要用到两个方法: pcap_compile(3PCAP) 和 pcap_setfilter(3PCAP)。
这个过程很简单。在我们已经调用 pcap_open_live() 并且有一个工作嗅探会话之后,我们可以应用我们的过滤器。为什么不直接使用我们自己的 if/else if 语句呢?两个原因。首先,pcap 的过滤器效率更高,因为它直接与 BPF 过滤器一起使用;我们通过让 BPF 驱动程序直接执行来消除许多步骤。其次,这要容易得多:)
BPF 伯克利包过滤器。 是在linux 平台下的一个包过滤器。使用此过滤器可以在socket编程时非常方便的实现各种过滤规则。
在应用我们的过滤器之前,我们必须“编译”它。过滤器表达式保存在常规字符串(char 数组)中。语法在 pcap-filter(7) 中有很好的记录;我让你自己阅读。但是,我们将使用简单的测试表达式,所以也许您足够敏锐,可以从我的示例中弄清楚。
为了编译程序,我们调用 pcap_compile()。原型将其定义为:
int pcap_compile(pcap_t *p, struct bpf_program *fp, char *str, int optimize,
bpf_u_int32 netmask)
| 参数字段说明 | 描述 |
|---|---|
| 第一个参数 | 第一个参数是我们的会话句柄(pcap_t *handle 在我们之前的例子中)。 |
| 第二个参数 | 我们将存储 过滤器编译版本的位置引用。 |
| 第三个参数 | 表达式本身;格式:常规字符串 |
| 第四个参数 | 是一个整数,它决定表达式是否应该“优化”(0 为假,1 为真——标准内容)。 |
| 第五个参数 | 我们必须指定过滤器应用到的网络的网络掩码。 |
| 返回值 | 失败返回-1,其他值都是成功 |
表达式编译完成后,就可以应用它了。接着是 pcap_setfilter()。按照我们解释 pcap 的格式,我们来看看原型:
int pcap_setfilter(pcap_t *p, struct bpf_program *fp)
| 参数说明 | 描述 |
|---|---|
| 第一个参数 | 我们的会话处理程序 |
| 第二个参数 | 是对表达式的编译版本的引用(可能与 pcap_compile() 的第二个参数相同的变量) |
也许另一个代码示例将有助于更好地理解:
#include <pcap.h>
...
pcap_t *handle; /* Session handle 会话句柄 */
char dev[] = "rl0"; /* Device to sniff on 要嗅探的设备 */
char errbuf[PCAP_ERRBUF_SIZE]; /* Error string 记录错误信息的字符串 */
struct bpf_program fp; /* The compiled filter expression 编译后的过滤表达式 */
char filter_exp[] = "port 23"; /* The filter expression 过滤表达式 */
bpf_u_int32 mask; /* The netmask of our sniffing device 我们的嗅探设备的网络掩码 */
bpf_u_int32 net; /* The IP of our sniffing device 我们的嗅探设备的IP */
if (pcap_lookupnet(dev, &net, &mask, errbuf) == -1) {
fprintf(stderr, "Can't get netmask for device %s\n", dev);
net = 0;
mask = 0;
}
handle = pcap_open_live(dev, BUFSIZ, 1, 1000, errbuf);
if (handle == NULL) {
fprintf(stderr, "Couldn't open device %s: %s\n", dev, errbuf);
return(2);
}
if (pcap_compile(handle, &fp, filter_exp, 0, net) == -1) {
fprintf(stderr, "Couldn't parse filter %s: %s\n", filter_exp, pcap_geterr(handle));
return(2);
}
if (pcap_setfilter(handle, &fp) == -1) {
fprintf(stderr, "Couldn't install filter %s: %s\n", filter_exp, pcap_geterr(handle));
return(2);
}
该程序是嗅探器准备在设备rl0上以混杂模式嗅探来自或流向端口 23 的所有流量。
您可能会注意到前面的示例包含一个我们尚未讨论的函数。 pcap_lookupnet(3PCAP) 是一个函数,在给定设备名称的情况下,返回其 IPv4 网络号和相应的网络掩码(网络号是 IPv4 地址与网络掩码的与,因此它仅包含设备的网络部分地址)。这是必不可少的,因为我们需要知道网络掩码才能应用过滤器。此功能在文档末尾的其他部分中进行了描述。
根据我的经验,此过滤器不适用于所有操作系统。在我的测试环境中,我发现带有默认内核的 OpenBSD 2.9 确实支持这种类型的过滤器,但带有默认内核的 FreeBSD 4.3 不支持。
实际嗅探
至此,我们已经学会了如何定义一个设备,为嗅探做准备,并应用过滤器来判断我们应该和不应该嗅探什么。现在是时候实际捕获一些数据包了。
捕获数据包有两种主要技术。我们可以一次捕获一个数据包,也可以进入一个循环,等待 n 个数据包在完成之前被嗅探。我们将从查看如何捕获单个数据包开始,然后查看使用循环的方法。为此,我们使用 pcap_next(3PCAP)。
原型相当简单:
u_char *pcap_next(pcap_t *p, struct pcap_pkthdr *h)
| 参数具体说明 | 说明 |
|---|---|
| 第一个参数 | session handler |
| 第二个参数 | 是一个指向结构的指针,该结构包含有关数据包的一般信息,特别是它被嗅探的时间、该数据包的长度以及该特定部分的长度(例如,如果它被分段)。 |
| 返回值 | 返回指向此结构描述的数据包的 u_char 指针 |
这是使用 pcap_next() 嗅探数据包的简单演示。
#include <pcap.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
pcap_t *handle; /* Session handle 会话句柄 */
char *dev; /* The device to sniff on 要嗅探设备 */
char errbuf[PCAP_ERRBUF_SIZE]; /* Error string 记录错误的字符串 */
struct bpf_program fp; /* The compiled filter 编译后的过滤器 */
char filter_exp[] = "port 23"; /* The filter expression 过滤表达式 */
bpf_u_int32 mask; /* Our netmask 我们的网络掩码 */
bpf_u_int32 net; /* Our IP 我们的IP */
struct pcap_pkthdr header; /* The header that pcap gives us 给我们的标头 */
const u_char *packet; /* The actual packet 实际数据包 */
/* Define the device 定义设备 */
dev = pcap_lookupdev(errbuf);
if (dev == NULL) {
fprintf(stderr, "Couldn't find default device: %s\n", errbuf);
return(2);
}
/* Find the properties for the device 查找设备的属性 */
if (pcap_lookupnet(dev, &net, &mask, errbuf) == -1) {
fprintf(stderr, "Couldn't get netmask for device %s: %s\n", dev, errbuf);
net = 0;
mask = 0;
}
/* Open the session in promiscuous mode 以混杂模式打开会话 */
handle = pcap_open_live(dev, BUFSIZ, 1, 1000, errbuf);
if (handle == NULL) {
fprintf(stderr, "Couldn't open device %s: %s\n", dev, errbuf);
return(2);
}
/* Compile and apply the filter 编译并应用过滤器 */
if (pcap_compile(handle, &fp, filter_exp, 0, net) == -1) {
fprintf(stderr, "Couldn't parse filter %s: %s\n", filter_exp, pcap_geterr(handle));
return(2);
}
if (pcap_setfilter(handle, &fp) == -1) {
fprintf(stderr, "Couldn't install filter %s: %s\n", filter_exp, pcap_geterr(handle));
return(2);
}
/* Grab a packet 抓取到一个数据包 */
packet = pcap_next(handle, &header);
/* Print its length */
printf("Jacked a packet with length of [%d]\n", header.len);
/* And close the session 关闭一个会话 */
pcap_close(handle);
return(0);
}
此应用程序通过将 pcap_lookupdev() 返回的任何设备置于混杂模式来嗅探它。它找到第一个通过端口 23 (telnet) 的数据包,并告诉用户数据包的大小(以字节为单位)。同样,这个程序包括一个新的调用,pcap_close(3PCAP),我们稍后会讨论它(尽管它确实很容易解释)。
我们可以使用的另一种技术更复杂,而且可能更有用。很少有嗅探器(如果有的话)实际使用 pcap_next()。他们通常使用 pcap_loop(3PCAP) 或 pcap_dispatch(3PCAP)(然后它们自己使用 pcap_loop())。要了解这两个函数的使用,就必须了解回调函数的思想。
回调函数并不是什么新鲜事物,在许多 API 中都很常见。回调函数背后的概念相当简单。假设我有一个程序正在等待某种事件。出于本示例的目的,假设我的程序希望用户按下键盘上的某个键。每次他们按下一个键时,我都想调用一个函数,然后该函数将确定要执行的操作。我正在使用的函数是一个回调函数。每次用户按键时,我的程序都会调用回调函数。回调在 pcap 中使用,但不是在用户按键时调用,而是在 pcap 嗅探数据包时调用。可以用来定义其回调的两个函数是 pcap_loop() 和 pcap_dispatch(),它们在回调的用法上非常相似。每次嗅探到满足我们过滤器要求的数据包时,它们都会调用一个回调函数(当然,如果存在任何过滤器。如果不存在,则将所有嗅探到的数据包都发送到回调。)
pcap_loop() 的原型如下:
int pcap_loop(pcap_t *p, int cnt, pcap_handler callback, u_char *user)
| 参数具体说明 | 说明 |
|---|---|
| 第一个参数 | 第一个参数是我们会话句柄 |
| 第二个参数 | 是一个整数,它告诉 pcap_loop() 在返回之前它应该嗅探多少数据包(负值意味着它应该嗅探直到发生错误) |
| 第三个参数 | 是回调函数的名称(只是它的标识符,没有括号) |
| 第四个参数 | 最后一个参数在某些应用程序中很有用,但很多时候只是简单地设置为 NULL。假设除了 pcap_loop() 发送的参数之外,我们还有自己希望发送给回调函数的参数 |
在提供使用 pcap_loop() 的示例之前,我们必须检查回调函数的格式。我们不能随意定义回调的原型;否则, pcap_loop() 将不知道如何使用该函数。所以我们使用这种格式作为我们回调函数的原型。 — 这段来做英文翻译
首先,您会注意到该函数具有 void 返回类型。这是合乎逻辑的,因为 pcap_loop() 无论如何都不知道如何处理返回值。
void got_packet(u_char *args, const struct pcap_pkthdr *header, const u_char *packet);
| 参数具体说明 | 说明 |
|---|---|
| 第一个参数 | 第一个参数对应于 pcap_loop() 的最后一个参数。每次调用函数时,作为 pcap_loop() 的最后一个参数传递的任何值都会传递给回调函数的第一个参数。 |
| 第二个参数 | 第二个参数是 pcap 标头(header),它包含有关何时嗅探数据包、数据包大小等信息。 |
| 第三个参数 | 它是另一个指向 u_char 的指针,它指向包含整个数据包的数据块的第一个字节. |
第二个参数类型:
struct pcap_pkthdr {
struct timeval ts; /* time stamp 时间戳 */
bpf_u_int32 caplen; /* length of portion present 当前部分的长度 */
bpf_u_int32 len; /* length this packet (off wire) 这个数据包的长度 */
};
第三个参数是普通 pcap 新手程序员最困惑的参数,它是另一个指向 u_char 的指针,它指向包含整个数据包的数据块的第一个字节,由 pcap_loop() 嗅探。但是如何使用这个变量(在我们的原型中命名为 packet)?一个数据包包含许多属性,所以你可以想象,它实际上并不是一个字符串,而是一个结构的集合(例如,一个 TCP/IP 数据包将有一个以太网标头、一个 IP 标头、一个 TCP 标头,最后,数据包的有效载荷)。这个 u_char 指针指向这些结构的序列化版本。要使用它,我们必须进行一些有趣的类型转换。(标头:就是header)
首先,我们必须先定义实际的结构,然后才能对它们进行类型转换。以下是我用来描述以太网上的 TCP/IP 数据包的结构定义。
/* Ethernet addresses are 6 bytes */
/* 以太网地址为6个字节 */
#define ETHER_ADDR_LEN 6
/* Ethernet header */
/* 以太网 header */
struct sniff_ethernet {
u_char ether_dhost[ETHER_ADDR_LEN]; /* Destination host address */
u_char ether_shost[ETHER_ADDR_LEN]; /* Source host address */
u_short ether_type; /* IP? ARP? RARP? etc */
};
/* IP header */
struct sniff_ip {
u_char ip_vhl; /* version << 4 | header length >> 2 */
u_char ip_tos; /* type of service */
u_short ip_len; /* total length */
u_short ip_id; /* identification */
u_short ip_off; /* fragment offset field 片段偏移字段 */
#define IP_RF 0x8000 /* reserved fragment flag 保留分段标志 */
#define IP_DF 0x4000 /* don't fragment flag 不保留分段标志 */
#define IP_MF 0x2000 /* more fragments flag 更多片段标志 */
#define IP_OFFMASK 0x1fff /* mask for fragmenting bits 分段掩码 */
u_char ip_ttl; /* time to live 生存时间 */
u_char ip_p; /* protocol 协议 */
u_short ip_sum; /* checksum 校验和 */
struct in_addr ip_src,ip_dst; /* source and dest address 源地址和目标地址 */
};
#define IP_HL(ip) (((ip)->ip_vhl) & 0x0f)
#define IP_V(ip) (((ip)->ip_vhl) >> 4)
/* TCP header */
typedef u_int tcp_seq;
struct sniff_tcp {
u_short th_sport; /* source port 源端口 */
u_short th_dport; /* destination port 目标端口 */
tcp_seq th_seq; /* sequence number 序列号 */
tcp_seq th_ack; /* acknowledgement number 确认号 */
u_char th_offx2; /* data offset, rsvd 数据偏移量 */
#define TH_OFF(th) (((th)->th_offx2 & 0xf0) > 4)
u_char th_flags;
#define TH_FIN 0x01
#define TH_SYN 0x02
#define TH_RST 0x04
#define TH_PUSH 0x08
#define TH_ACK 0x10
#define TH_URG 0x20
#define TH_ECE 0x40
#define TH_CWR 0x80
#define TH_FLAGS (TH_FIN|TH_SYN|TH_RST|TH_ACK|TH_URG|TH_ECE|TH_CWR)
u_short th_win; /* window 窗口 */
u_short th_sum; /* checksum 校验和 */
u_short th_urp; /* urgent pointer 紧急指针 */
};
上面的这些与 pcap 和我们神秘的 u_char 指针有什么关系呢?好吧,这些结构定义了出现在数据包数据中的标头。那么我们怎么才能把它分开呢?
我们将假设我们正在处理以太网上的 TCP/IP 数据包。同样的技术适用于任何数据包;唯一的区别是您实际使用的结构类型。因此,让我们从定义解构数据包数据所需的变量和编译时定义开始。
/* ethernet headers are always exactly 14 bytes */
#define SIZE_ETHERNET 14
const struct sniff_ethernet *ethernet; /* The ethernet header 以太网header */
const struct sniff_ip *ip; /* The IP header */
const struct sniff_tcp *tcp; /* The TCP header */
const char *payload; /* Packet payload 报文的有效荷载 */
u_int size_ip;
u_int size_tcp;
现在,我们开始神奇的转换:
ethernet = (struct sniff_ethernet*)(packet);
ip = (struct sniff_ip*)(packet + SIZE_ETHERNET);
size_ip = IP_HL(ip)*4;
if (size_ip < 20) {
printf(" * Invalid IP header length: %u bytes\n", size_ip);
return;
}
tcp = (struct sniff_tcp*)(packet + SIZE_ETHERNET + size_ip);
size_tcp = TH_OFF(tcp)*4;
if (size_tcp < 20) {
printf(" * Invalid TCP header length: %u bytes\n", size_tcp);
return;
}
payload = (u_char *)(packet + SIZE_ETHERNET + size_ip + size_tcp);
这是如何运转的呢?考虑在内存中数据包的布局。 u_char 指针实际上只是一个包含内存地址的变量。这就是指针。它指向内存中的一个位置。

为了简单起见,我们会说这个指针设置的地址是值 X。好吧,如果我们的三个结构只是排成一行,它们中的第一个 (sniff_ethernet) 位于内存中的地址 X ,那么我们可以很容易地找到它后面的结构体的地址;该地址是 X 加上以太网报头的长度,即 14。
IP头与以太网头不同,它没有固定的长度;它的长度由 IP 标头的标头长度字段以 4 字节字数的形式给出。由于它是 4 字节字的计数,因此必须将其乘以 4 才能给出以字节为单位的大小。该标头的最小长度为 20 个字节。
TCP头也有可变长度;它的长度由 TCP 头的“数据偏移”字段给出,作为 4 字节字的数量,它的最小长度也是 20 字节。
所以让我们做一个图表:
| 变量 | 位置(以字节为单位) |
|---|---|
| sniff_ethernet | X |
| sniff_ip | X + SIZE_ETHERNET |
| sniff_tcp | X + SIZE_ETHERNET + {IP header length} |
| payload | X + SIZE_ETHERNET + {IP header length} + {TCP header length} |
说明:
- 第一行是以太网的位置 X
- sniff_ip,紧跟在 sniff_ethernet 之后,在位置 X,加上以太网报头消耗的空间(14 字节,或 SIZE_ETHERNET)
- sniff_tcp 在 sniff_ip 和 sniff_ethernet 之后,因此它位于 X 处的位置加上以太网和 IP 标头的大小(分别为 14 字节和 IP 标头长度的 4 倍)。
- 最后,有效载荷(没有与之对应的单一结构,因为它的内容取决于
TCP上使用的协议)位于所有这些之后。
至此,我们知道了如何设置回调函数,调用它,并找出已经嗅探到的数据包的属性。
总结
关键点就是下面这张表,根据偏移量解析下面的报文数据,数据就出来啦。
| 变量 | 位置(以字节为单位) |
|---|---|
| sniff_ethernet | X |
| sniff_ip | X + SIZE_ETHERNET |
| sniff_tcp | X + SIZE_ETHERNET + {IP header length} |
| payload | X + SIZE_ETHERNET + {IP header length} + {TCP header length} |
参考地址:
边栏推荐
- Sed of three swordsmen in text processing
- Unity 构建错误:当前上下文中不存在名称“EditorUtility”
- Visual stdio 2017 about the environment configuration of opencv4.1
- How does MySQL create, delete, and view indexes?
- PHP调用纯真IP数据库返回具体地址
- ORACLE进阶(五)SCHEMA解惑
- Day26 IP query items
- Master formula. (used to calculate the time complexity of recursion.)
- “新红旗杯”桌面应用创意大赛2022
- Leetcode skimming: binary tree 21 (verifying binary search tree)
猜你喜欢
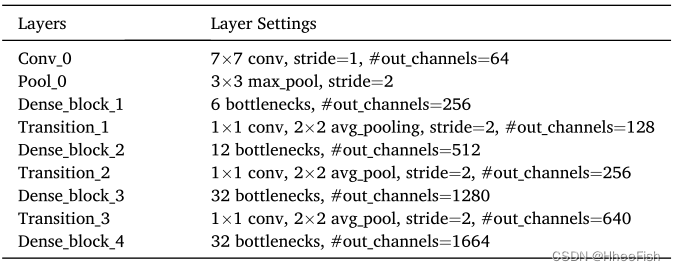
ISPRS2021/遥感影像云检测:一种地理信息驱动的方法和一种新的大规模遥感云/雪检测数据集
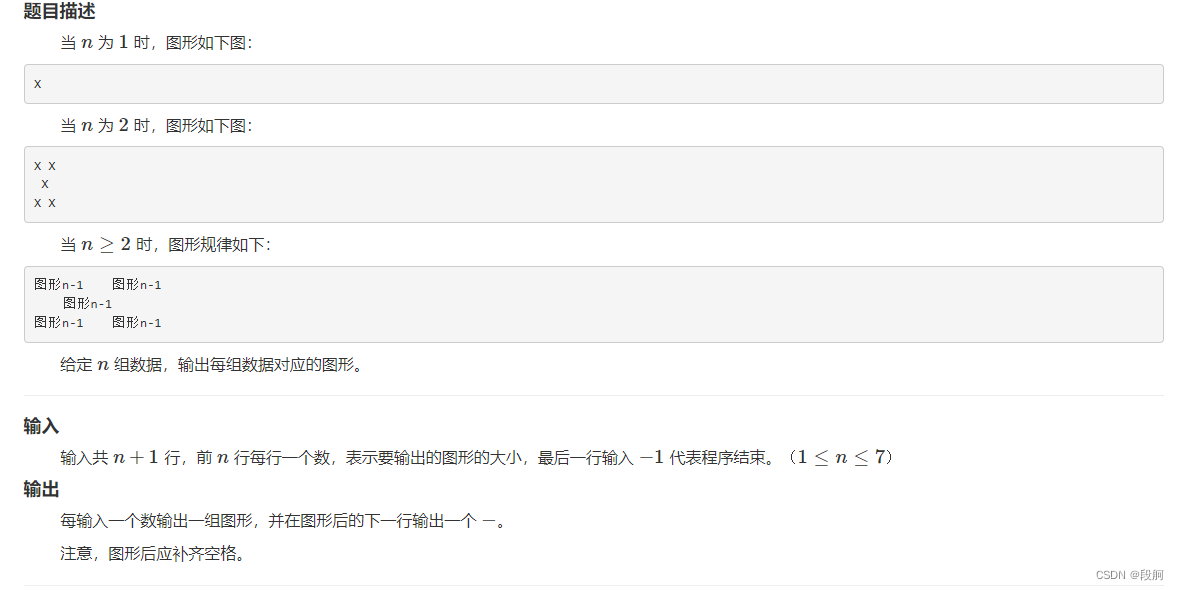
HZOJ #240. Graphic printing IV
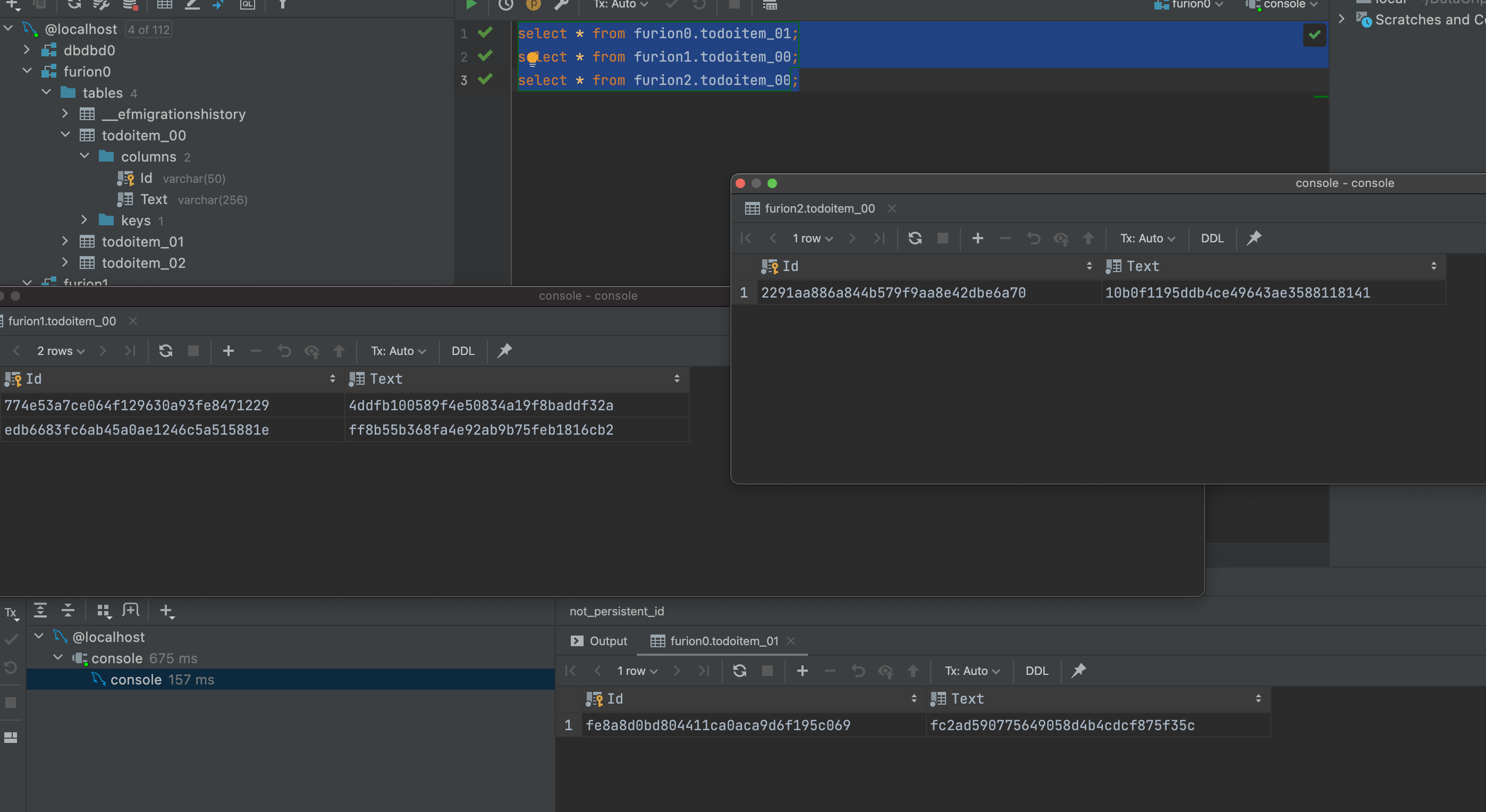
- Oui. Migration entièrement automatisée de la Sous - base de données des tableaux d'effets sous net

Polymorphism, final, etc
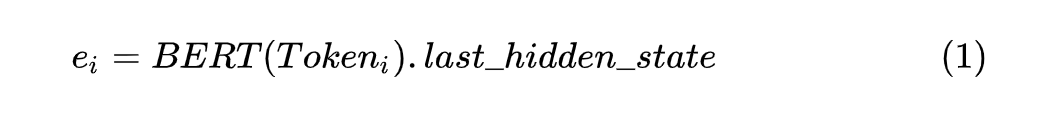
ACL 2022 | 序列标注的小样本NER:融合标签语义的双塔BERT模型

3D content generation based on nerf
Leetcode brush question: binary tree 24 (the nearest common ancestor of binary tree)
Importance of database security

Per capita Swiss number series, Swiss number 4 generation JS reverse analysis
Leetcode skimming: binary tree 21 (verifying binary search tree)
随机推荐
智云健康上市:市值150亿港元 SIG经纬与京新基金是股东
Day-24 UDP, regular expression
Polymorphism, final, etc
Analysis of DHCP dynamic host setting protocol
Lingyunguang of Dachen and Xiaomi investment is listed: the market value is 15.3 billion, and the machine is implanted into the eyes and brain
Day-16 set
Cookie
基于鲲鹏原生安全,打造安全可信的计算平台
ip2long与long2IP 分析
Enterprise custom form engine solution (XII) -- experience code directory structure
《ASP.NET Core 6框架揭秘》样章[200页/5章]
Image pixel read / write operation
MySQL导入SQL文件及常用命令
红杉中国完成新一期90亿美元基金募集
[learn wechat from 0] [00] Course Overview
[binary tree] delete points to form a forest
Leetcode question brushing: binary tree 26 (insertion operation in binary search tree)
Awk of three swordsmen in text processing
The difference between cache and buffer
How does MySQL create, delete, and view indexes?