当前位置:网站首页>9.新闻分类:多分类问题
9.新闻分类:多分类问题
2022-08-03 04:05:00 【好名字能更容易让朋友记住】
新闻分类:多分类问题
本次会构建一个网络,将路透社新闻划分为46个互斥的主题。因为有多个类别,这是多分类问题的一个例子。因为每个数据点只能划分到一个类别,所以更具体地说,这是单标签、多分类问题的一个例子。如果每个数据点可以划分到多个类别(主题),那它就是一个多标签、多分类的问题。
路透社数据集reuters
该数据集包含46个不同的主题:某些主题的样本更多,但训练集中每个主题都有至少10个样本。
from keras.datasets import reuters
(train_data, tarin_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
与IMDB相同,每个样本都是一个整数列表(表示单词索引)
将索引解码为新闻文本的方法
word_index = reuters.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decoded_newswrie = ' '.join([reverse_word_index.get(i - 3,'?') for i in train_data[0]])
# 索引减去3是因为0、1、2分别为“padding(填充)”、“start of sequence(序列开始)”、”unknown(未知词)“分别保留的索引。
样本对应的标签是一个0至45范围内的整数,即话题索引编号。
准备数据
使用以下方法将数据向量化
import numpy as np
def vectorize_sequences(sequense, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequenses):
retults[i, sequence] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
也可以使用 one-hot 编码,one-hot 编码是分类数据广泛使用的一种格式,也叫分类编码。在这个例子中,标签的 one-hot 编码就是将每个标签表示为全零向量,只有标签索引对应的元素为1。
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
one_hot_train_labels = to_one_hot(train_labels)
one_hot_test_labels = to_one_hot(test_labels)
Keras 内置方法可以实现这个操作
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
构建网络
这个问题与二分类问题类似,但是他有一个新的约束条件:输出类别和数量从2个变为64个。
对于Dense层的堆叠,每层只能访问上一层输出的信息。如果某一层丢失了与分类问题相关的一些信息,那么这些信息无法被后面的层找回,也就是说,每一层都有可能成为信息瓶颈。如果Dense层的维度过小,可能会造成信息瓶颈,永久的丢失信息。所以此次使用64个单元的维度。
form kears import models
form keras import layers
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
关于这个架构,需要注意:
- 网格最后的一层是大小为46的Dense层。这意味着,对于每个输入样本,网络都会输出一个46维的向量。这个向量的每个元素(即每个维度)代表不同的输出类别。
- 最后一层使用了softmax激活。网格将输出在46个不同输出类别上的概率分布——对于每一个输入样本,网络都会输出一个46维向量,其中 output[i] 是属于第 i 个类别的概率。46个概率的总和为1。
对于这个例子,最好的损失函数是 categorical_crossentropy(分类交叉熵)。它用于衡量两个概率分布之间的距离,这里两个概率分布分别是网络输出的概率分布和标签的真实分布。通过将这两个分布的距离最小化,训练网络可使输出结果尽可能接近真实标签。
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics='accuracy')
验证你的方法
首先在训练数据中留出1000个样本作为验证集
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_test_labels[1000:]
现在开始训练网络,共20个轮次
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
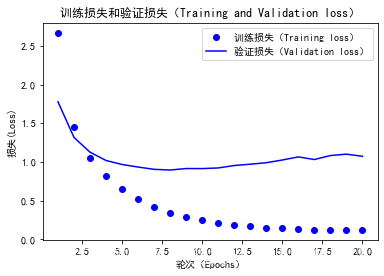
绘制训练损失和验证损失的图像
import matplotlib.pyplot as plt
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='训练损失(Training loss)')
plt.plot(epochs, loss, 'b', label='验证损失(Validation loss)')
plt.title('训练损失和验证损失(Training and Validation loss)')
plt.xlabel('轮次(Epochs)')
plt.ylabel('损失(loss)')
plt.legend()
plt.show()
绘制训练精度和验证精度图像
import matplotlib.pyplot as plt
plt.clf()
acc = history.history['acc']
val_acc = history.history['val_acc']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='训练精度(Training acc)')
plt.plot(epochs, val_acc, 'b', label='验证精度(Validation acc)')
plt.title('训练精度和验证精度(Training and Validation acc)')
plt.xlabel('训练精度(Training acc)')
plt.ylabel('验证精度(Validation acc)')
plt.legend()
plt.show()
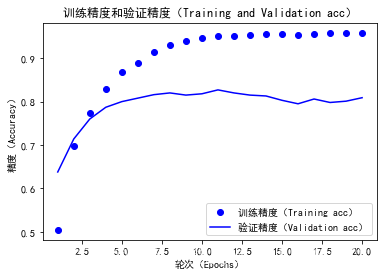
由以上两个图可以发现,网络在训练9轮时开始过拟合,我们可以重新训练一个网络,共九个轮次尝试。
import keras.models
import keras.layers
model = models.Sequential()
model.add(layers.Dense(61, activation='relu', input_shape(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=9,
batch_size=512,
validation_data=(x_val, y_val))
results = models.evaluate(x_test, one)
>>>results
[0.9760603904724121, 0.7862867116928101]
这种方法可以得到将近80%的精度。对于平衡的二分类问题,完全随机的分类器能够获得到50%的精度。对于这个例子,完全随机的精度约为19%。
>>>import copy
>>>test_labels_copy = copy.copy(test_labels)
>>>np.random.shuffle(tgest_labels_copy)
>>>hits_array = np.array(test_labels) == np.array(test_labels_copy)
>>>float(np.sum(hits_array)) / len(test_labels)
0.18477292965271594
在新数据上生成预测结果
模型实例的 predict 方法返回了在46个主题上的概率分布。我们对所有测试数据生成主题预测。
>>> predictions = model.predict(x_test)
>>> predictions[0].shape
(46,)
>>> np.sum(predictions[0])
1.0
>>> np.argmax(predictions[0])
3
处理标签和损失的另一种方法
前面提到了另一种编码标签的方法,就是将其转换为整数张量,如下所示
y_train = np.array(train_labels)
y_test = np.array(test_labels)
对于这种编码方法,需要改变的是损失函数的选择,对于以上使用的损失函数 categorical_crossentropy ,标签应该遵循分类编码。对于整数标签,你应该使用 sparse_categorical_crossentropy。
model.compile(optimizer='rmsporp',
loss='sparse_categorical_crossentropy',
metrics=['acc'])
这个新的损失函数在数学上与categorical_crossentropy完全相同,只是接口不同。
中间层维度足够大的重要性
对于这个例子,最终输出是46维的,因此中间层的隐藏单元个数是不应该比46小太多。如果中间层的维度远远小于46,就会发生信息瓶颈。
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(4, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=128,
validation_data=(x_val, y_val))
现在网络的验证精度最大约为71%,比前面下降了8%。导致这一下降的主要原因在于,试图将大量信息(这些信息足够恢复46个类别的分割超平面)压缩到维度很小的中间空间。网络能够将大部分必要信息塞入这个四维表示中,但并不是全部信息。
小结
- 如果要对N个类别的数据点进行分类,网络的最后一层应该是大小为N的Dense层。
- 对于单标签、多分类问题,网络的最后一层应该是哟个softmax激活,这样可以输出在N个输出类别上的概率分布。
- 这种问题的损失函数几乎总是应该使用分类交叉熵。他将网络输出的概率分布与目标的真实分布之间的距离最小化。
- 处理多分类问题的标签有两种方法
- 通过分类编码(也叫
ont-hot编码)对标签进行编码,然后使用categorical_crossentropy作为损失函数。 - 将标签编码为整数,然后使用
sparse_categorical_crossentropy损失函数。
- 通过分类编码(也叫
- 如果你需要将数据划分到许多类别中,应该避免使用太小的中间层,以免在网路中造成信息瓶颈。
N个输出类别上的概率分布。
- 这种问题的损失函数几乎总是应该使用分类交叉熵。他将网络输出的概率分布与目标的真实分布之间的距离最小化。
- 处理多分类问题的标签有两种方法
- 通过分类编码(也叫
ont-hot编码)对标签进行编码,然后使用categorical_crossentropy作为损失函数。 - 将标签编码为整数,然后使用
sparse_categorical_crossentropy损失函数。
- 通过分类编码(也叫
- 如果你需要将数据划分到许多类别中,应该避免使用太小的中间层,以免在网路中造成信息瓶颈。
边栏推荐
- path development介绍
- 中原银行实时风控体系建设实践
- Chapter 8 Character Input Output and Input Validation
- 高等代数_证明_矩阵乘以自身的转置的特征值不小于0
- 浏览器监听标签页关闭
- shell之条件语句(条件测试、if语句,case语句)
- 深圳线下报名|StarRocks on AWS:如何对实时数仓进行极速统一分析
- urlencode 和rawurlencode的区别
- Jincang Database OCCI Migration Guide (5. Program Development Example)
- 中非合作论坛非洲产品电商推广季启动 外交部:推动中非合作转型升级
猜你喜欢
自考六级雅思托福备战之路
软件测试个人求职简历该怎么写,模板在这里

工程水文学试题库

Can Oracle EMCC be installed independently?Or does it have to be installed on the database server?
【笔记】混淆矩阵和ROC曲线

高等代数_笔记_配方法标准化二次型

MySQL【约束】
Chapter 8 Character Input Output and Input Validation
Problems that need to be solved for interrupting the system

t条件判断语句与if循环

随机推荐
基于WPF重复造轮子,写一款数据库文档管理工具(一)
DC-6靶场下载及渗透实战详细过程(DC靶场系列)
voliate关键字
stdio.h(本机代码)
2022 the first of the new league henan (4) : zhengzhou university of light industry G - maze
Auto. Js scripts run time calculated Pro
C# WPF设备监控软件(经典)-上篇
(2022杭电多校五)1010-Bragging Dice (思维)
工程水文学试题库
【翻译】开发与生产中的Kubernetes修复成本对比
测开:项目管理模块-项目curd开发
软件测试个人求职简历该怎么写,模板在这里
Domino服务器SSL证书安装指南
【uni-APP搭建项目】
富瑞宣布战略交易,以简化运营,持续专注于打造领先的独立全服务型全球投行公司
阿里面试官:聊聊如何格式化Instant
Senior ClickHouse -
v-text指令:设置标签内容
2022河南萌新联赛第(四)场:郑州轻工业大学 E - 睡大觉
找不到符号@SuperBuilder,你以为真的是Lombok的问题?