当前位置:网站首页>卡尔曼滤波-1
卡尔曼滤波-1
2022-07-06 20:23:00 【wmzjzwlzs】
转自:卡尔曼滤波(kalman filter)和均值滤波有什么关系? - 知乎
看了一篇文章《傻瓜也能懂的卡尔曼滤波器(翻译自外网博客)》,发现评论里很多人说看不懂,决定写一篇真傻瓜也能懂的卡尔曼滤波。
文章先从简单的平均值开始,问题从简单到复杂,最后引入卡尔曼滤波。
一、平均值
举个例子:如下图,有一个滑块在一根杆上,杆一端有一个测距激光头,现在要测量滑块的位置。
[激光头]->_______[滑块]__________
三次测量值:1米、0.9米、1.2米
显然取平均值(1+0.9+1.2)/3=1.033米更准确。
二、加权平均值
假设有两个激光头:
[两激光头]=》________[滑块]_________
两个激光头同时测出:1.1米和1.5米
平均值1.3米更准确吗?不一定,如果两个激光头的测量精度一样,那平均值1.3米就是更准确的。
如果它们测量精度不一样,比如激光头1测量误差方差为0.01,激光头2误差方差为0.1,那么单独激光头1的测量值1.1米比平均值1.3米更准确,因为激光头2实在太差了,可以计算一下平均值的方差
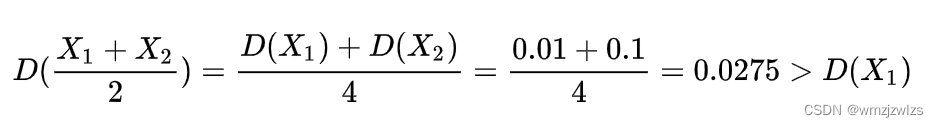
平均值的方差比激光头1的误差方差更大了,显然平均值不好。但是激光头2的测量值完全没用吗?可以换一种计算平均值的方法,叫做加权平均值
![]()
显然用0.9和0.1做加权平均,方差变小了,加权平均值比两个测量值都更准确。那加权平均值的两个权值取多少最好呢?可以假设 的权值为a,则 的权值为(1-a),代进去计算
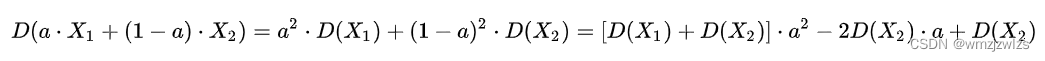
这是关于a的二次函数,![]() 时加权平均值方差取得最小值(高中数学的二次函数极值问题),也就是 的加权系数之比等于它们的方差之比的倒数。
时加权平均值方差取得最小值(高中数学的二次函数极值问题),也就是 的加权系数之比等于它们的方差之比的倒数。
三、卡尔曼滤波
现在滑块不是静止的了,是运动的,假设匀速运动,1米/秒,激光头每秒测量一次
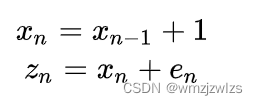
表示n时刻滑块位置, 表示n时刻激光头测量值, 表示测量误差。显然现在不能对激光头多次测量值求平均或者加权平均了,因为滑块是运动的。怎么办呢?最简单的办法就是直接将 ![]() 作为结果,也就是
作为结果,也就是 ![]() 的估计值 ,但是这不是最好的,因为滑块的运动方程没有用上。那就按最简单的求平均值的方式用上
的估计值 ,但是这不是最好的,因为滑块的运动方程没有用上。那就按最简单的求平均值的方式用上
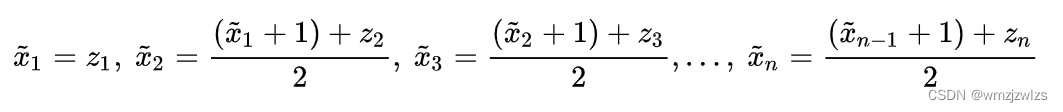
这样计算是不是比直接用测量值作为结果更好呢,可以计算一下他们的估计值方差
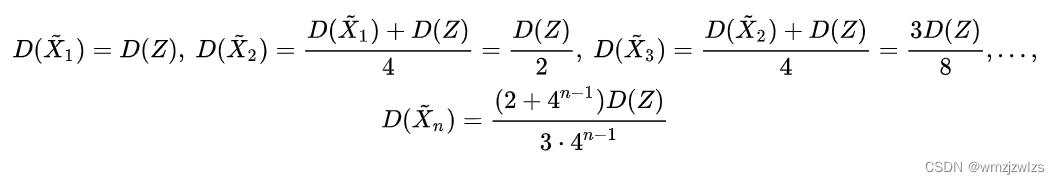
显然这种求平均值的方法估计值方差更小,当n趋于无穷大时 ![]() 。还可以改变一下估计值的初值,比如以0作为初值
。还可以改变一下估计值的初值,比如以0作为初值
![]()
同样计算一下可以发现,n趋于无穷大时,估计值方差 ![]() 还是
还是![]() ,也就是只要迭代次数足够,误差与初值无关,都收敛于同一个值。
,也就是只要迭代次数足够,误差与初值无关,都收敛于同一个值。
其实上面的平均值还不是最优的,你可以试一下计算每一步的加权平均值,两个权值之比同样是方差之比的倒数。同样你会发现,估计值方差会收敛,收敛值与初值选择无关。
到这里发现没有,上面的结果很像卡尔曼滤波了,其实这就是卡尔曼滤波了,只不过状态转移方程和测量方程特别简单。把状态方程和测量方程换成标准的方程,同样地像上面那样,每一步迭代用最佳加权系数计算加权平均值,你就会发现这就是标准的卡尔曼滤波了,只要记住最佳加权系数之比等于方差之比的倒数。也就是说,卡尔曼滤波其实就是选择了最佳加权系数的加权平均。
上面说的状态方程和测量方程都是一维的,如果它们都是多维的会怎样呢?多维的方程组就需要用最小二乘法求解。一维的最小二乘解就是平均值,多维的最小二乘解可以理解为多维的平均值,而加权最小二乘解就是加权平均值。所以对于多维的状态方程和测量方程,在每一步迭代用加权最小二乘法计算状态估计值就可以了。
结论:卡尔曼滤波本质就是选择了最佳加权系数的加权平均;加权最小二乘法就是求多维加权平均。
理解这样有什么用?我发现有很多人一看到滤波有关的问题,就想去折腾看上去很高级的卡尔曼滤波,其实没必要,如果用平均值或者加权平均值(多维对应最小二乘法或者加权最小二乘法)能把所有测量值都包含了,一般就没必要折腾卡尔曼滤波了,本质上都是一样的,除非用卡尔曼滤波能引入额外的比较准确的观测值。
边栏推荐
- 【基于 RT-Thread Studio的CPK-RA6M4 开发板环境搭建】
- sshd[12282]: fatal: matching cipher is not supported: aes256- [email protected] [preauth]
- Open3D 网格滤波
- SQL Tuning Advisor一个错误ORA-00600: internal error code, arguments: [kesqsMakeBindValue:obj]
- 22. (ArcGIS API for JS) ArcGIS API for JS Circle Collection (sketchviewmodel)
- [safe office and productivity application] Shanghai daoning provides you with onlyoffice download, trial and tutorial
- Jericho is in non Bluetooth mode. Do not jump back to Bluetooth mode when connecting the mobile phone [chapter]
- Jerry's broadcast has built-in flash prompt tone to control playback pause [chapter]
- RestClould ETL 社区版六月精选问答
- Sorting operation partition, argpartition, sort, argsort in numpy
猜你喜欢

树莓派设置静态ip

Can the applet run in its own app and realize live broadcast and connection?

19.(arcgis api for js篇)arcgis api for js线采集(SketchViewModel)

CVPR 2022 最佳论文候选 | PIP: 6个惯性传感器实现全身动捕和受力估计
About Confidence Intervals

The latest 2022 review of "small sample deep learning image recognition"

U.S. Air Force Research Laboratory, "exploring the vulnerability and robustness of deep learning systems", the latest 85 page technical report in 2022
![[tools] basic concept of database and MySQL installation](/img/9c/626e42097050517a13a2ce7cdab1bb.jpg)
[tools] basic concept of database and MySQL installation
Ubuntu20 installation redisjson record

Basic concepts of Huffman tree
随机推荐
HDU ACM 4578 Transformation-> Segment tree - interval change
CVPR 2022 最佳论文候选 | PIP: 6个惯性传感器实现全身动捕和受力估计
Principle of attention mechanism
About Tolerance Intervals
[cpk-ra6m4 development board environment construction based on RT thread studio]
Jerry's FM mode mono or stereo selection setting [chapter]
【安全的办公和生产力应用程序】上海道宁为您提供ONLYOFFICE下载、试用、教程
Jerry's ble exiting Bluetooth mode card machine [chapter]
Set WiFi automatic connection for raspberry pie
The version control of 2021 version is missing. Handling method
存储过程与函数(MySQL)
Lab1 configuration script
HMS Core 机器学习服务打造同传翻译新“声”态,AI让国际交流更顺畅
2022.6.28
qt-线程等01概念
数学归纳与递归
Lost in the lock world of MySQL
Create applet from 0
哈夫曼树基本概念
An error in SQL tuning advisor ora-00600: internal error code, arguments: [kesqsmakebindvalue:obj]