当前位置:网站首页>Principle of attention mechanism
Principle of attention mechanism
2022-07-07 03:22:00 【Master Ma】
Attention Mechanisms have been used in images in recent years , Important breakthroughs have been made in natural language processing and other fields , It is proved to be beneficial to improve the performance of the model .Attention The mechanism itself is also in line with the perception mechanism of the human brain and human eyes , This time we mainly take the field of computer vision as an example , about Attention The principle of mechanism , Application and model development .
1 Attention Mechanism and saliency diagram
1.1 What is the Attention Mechanism
So-called Attention Mechanism , That is, the mechanism of focusing on local information , For example, an image area in an image . As the task changes , Areas of attention tend to change .
Facing the picture above , If you just look at it as a whole , I only saw a lot of heads , But you can't look closer one by one , All talented scientists .
In fact, all the information in the picture except the face is useless , Can't do anything ,Attention The mechanism is to find the most useful information , You can imagine that the simplest scene is to detect faces from photos .
1.2 be based on Attention Significant target detection
One task that accompanies attention mechanism is salient target detection , namely salient object detection. Its input is a graph , The output is a probability map , The greater the probability , The greater the probability that the representative is an important target in the image , That is, the focus of human eyes , A typical saliency diagram is as follows :

The right figure is the salient figure of the left figure , In the head position, the probability is the greatest , And the legs , The tail also has a high probability , This is the really useful information in the figure .
Significant target detection requires a data set , The collection of such data sets is obtained by tracking the attention direction of multiple experimenters' eyeballs in a certain period of time , Typical steps are as follows :
(1) Let the subject observe the diagram .
(2) use eye tracker Record the eye's attention position .
(3) Gaussian filtering is used to synthesize the attention positions of all testers .
(4) The result is 0~1 The probability of .
So you can get the following picture , The second line is the result of eye tracking , The third line is the probability diagram of significant target .
The above is all about the spatial attention mechanism , That is, focus on different spatial locations , And in the CNN In structure , There are different characteristic channels , Therefore, different characteristic channels have similar principles , Let's talk about .
2 Attention Model architecture
The essence of attention mechanism is to locate the information of interest , Suppress useless information , The results are usually displayed in the form of probability map or probability eigenvector , In principle , It is mainly divided into spatial attention model , Channel attention model , Three kinds of spatial and channel mixed attention models , There is no distinction between soft and hard attention.
2.1 Spatial attention model (spatial attention)
Not all areas in the image contribute equally to the task , Only task related areas need to be concerned , For example, the main body of the classification task , Spatial attention model is to find the most important part of the network for processing .
Here we introduce two representative models , The first one is Google DeepMind Proposed STN The Internet (Spatial Transformer Network[1]). It learns the deformation of input , So as to complete the preprocessing operation suitable for the task , It's a space-based Attention Model , The network structure is as follows :
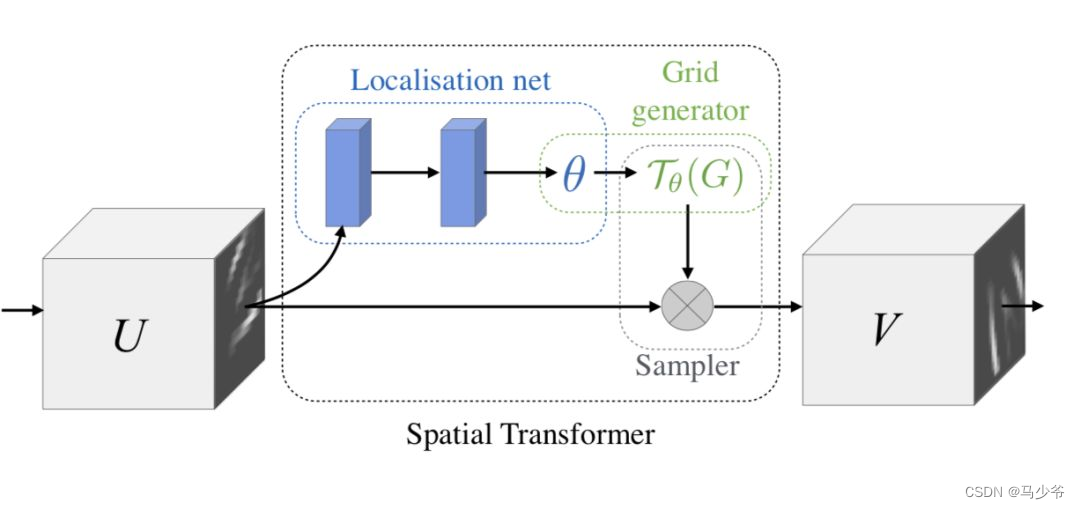
there Localization Net Used to generate affine transformation coefficients , Input is C×H×W The image of dimension , The output is a spatial transformation coefficient , Its size depends on the type of transformation to learn , If it's an affine transformation , It is a 6 Dimension vector .
The effect of such a network is shown in the figure below :
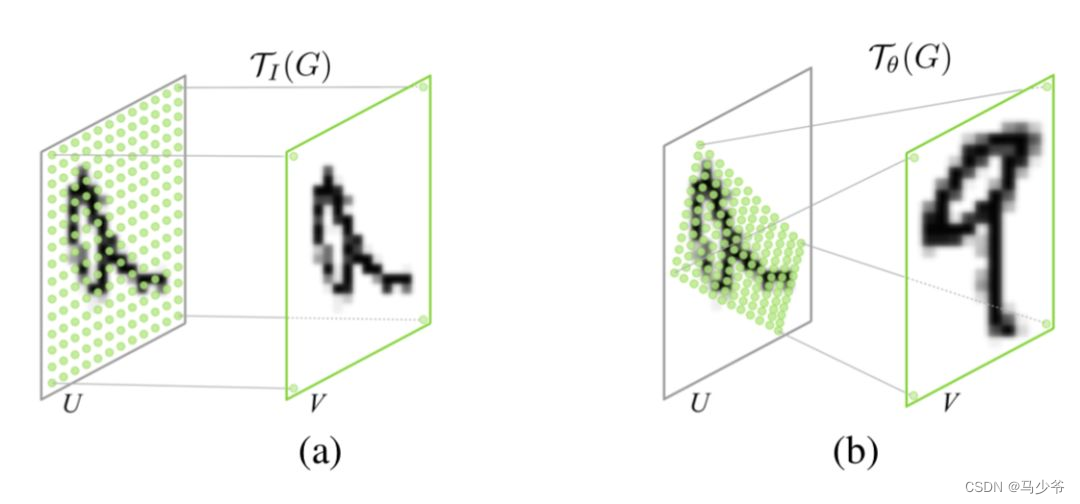
That is, locate the position of the target , Then perform operations such as rotation , Make the input sample easier to learn . This is a one-step adjustment solution , Of course, there are many iterative adjustment schemes
Compared with Spatial Transformer Networks One step to complete the target positioning and affine transformation adjustment ,Dynamic Capacity Networks[2] Two sub networks are used , They are low-performance subnetworks (coarse model) And high-performance subnetworks (fine model). Low performance subnetworks (coarse model) Used to process the whole picture , Locate the region of interest , As shown in the following figure fc. High performance subnetworks (fine model) Then the region of interest is refined , As shown in the following figure ff. Use both together , Lower computational cost and higher accuracy can be obtained .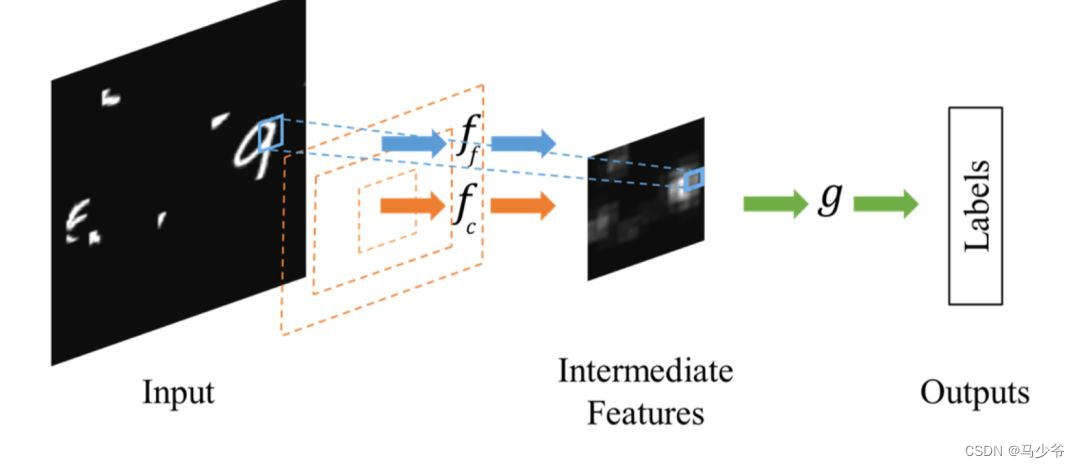
Because in most cases, the region of interest is only a small part of the image , Therefore, the essence of spatial attention is to locate the target and make some changes or obtain weights .
2.2 Channel attention mechanism
For input 2 Dimensional image of CNN Come on , One dimension is the scale space of the image , Length and width , Another dimension is the channel , Therefore, channel based Attention It is also a very common mechanism .
SENet(Sequeeze and Excitation Net)[3] yes 2017 the ImageNet The champion network of classification competition , It is essentially a channel based Attention Model , It models the importance of each feature channel , Then enhance or suppress different channels for different tasks , Schematic diagram is as follows .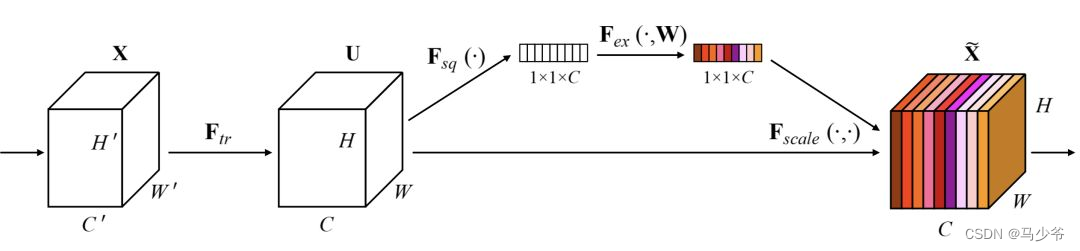
After normal convolution operation, a bypass branch is separated , First of all to Squeeze operation ( In the picture Fsq(·)), It compresses the spatial dimension , That is, each two-dimensional characteristic graph becomes a real number , It is equivalent to pooling operation with global receptive field , The number of characteristic channels remains unchanged .
And then there was Excitation operation ( That is... In the picture Fex(·)), It's through parameters w Generate weights for each feature channel ,w It is learned to explicitly model the correlation between feature channels . in an article , Used a 2 layer bottleneck structure ( First reduce the dimension and then increase the dimension ) The full connection layer of +Sigmoid Function to implement .
After getting the weight of each feature channel , This weight is applied to each original feature channel , Based on specific tasks , You can learn the importance of different channels .
The mechanism is applied to several benchmark models , With a small amount of calculation added , More significant performance improvement . As a general design idea , It can be used in any existing network , It has strong practical significance . Then SKNet[4] The idea of weighting such channels and Inception The multi branch network structure in is combined , It also improves the performance .
The essence of channel attention mechanism , Is to model the importance of each feature , For different tasks, the characteristics can be assigned according to the input , Simple and effective .
The foregoing Dynamic Capacity Network From the spatial dimension Attention,SENet From the channel dimension Attention, Naturally, space can also be used at the same time Attention And channel Attention Mechanism .
CBAM(Convolutional Block Attention Module)[5] Is one of the representative networks , The structure is as follows :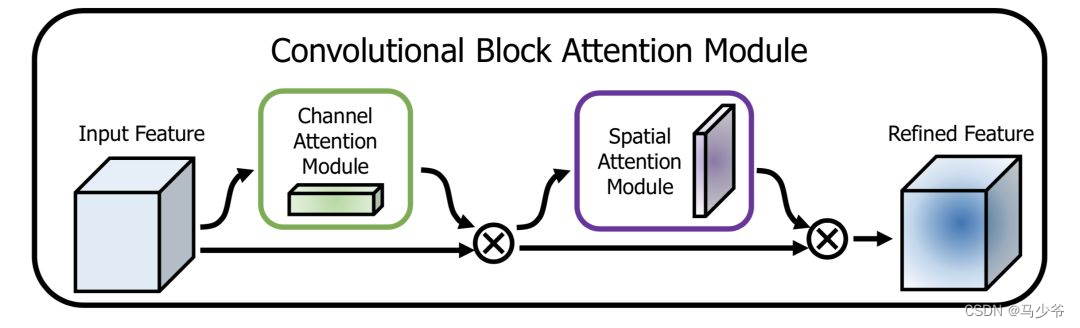
In the direction of the passage Attention Modeling is about the importance of features , The structure is as follows :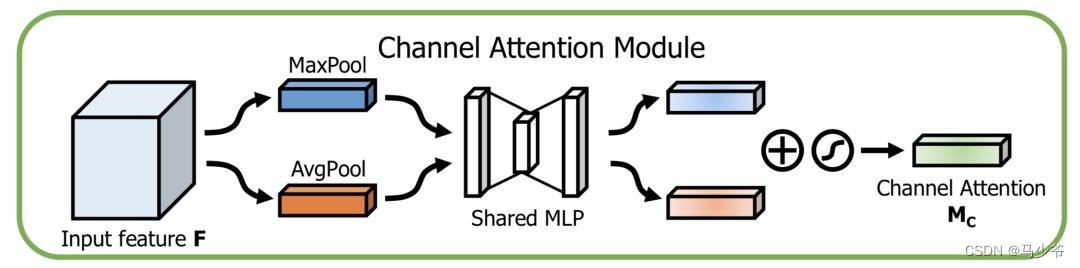
Use the maximum at the same time pooling Sum mean pooling Algorithm , Then after a few MLP Layer to obtain the transformation result , Finally, it is applied to two channels , Use sigmoid Function to get the of the channel attention result .
In the direction of space Attention Modeling is the importance of spatial location , The structure is as follows :
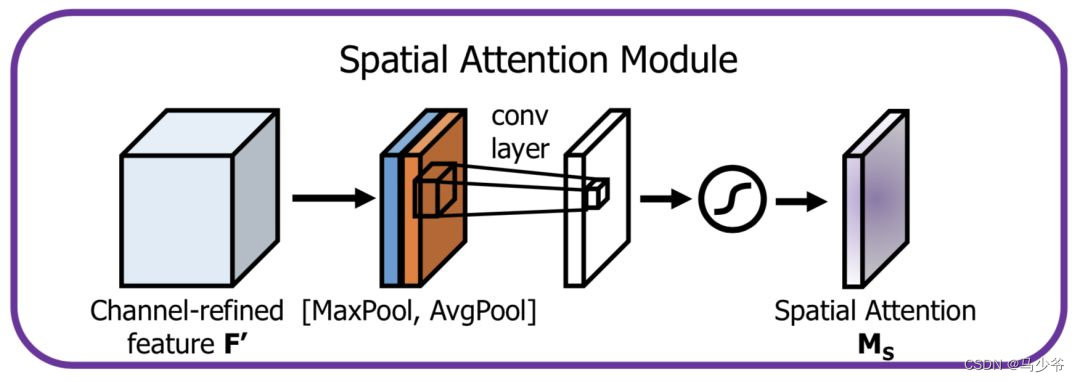
First, reduce the dimension of the channel itself , Obtain the maximum pooling and mean pooling results respectively , Then it is spliced into a feature map , Then use a convolution layer to learn .
These two mechanisms , The importance of channel and space are studied respectively , It can also be easily embedded into any known framework .
besides , There are also many studies related to the mechanism of attention , Such as residual attention mechanism , Multiscale attention mechanism , Recursive attention mechanism, etc .
3 Attention Typical application scenarios of mechanism
In principle , Attention mechanism can improve the performance of the model in all computer vision tasks , But there are two types of scenarios that benefit in particular .
3.1 Fine grained classification 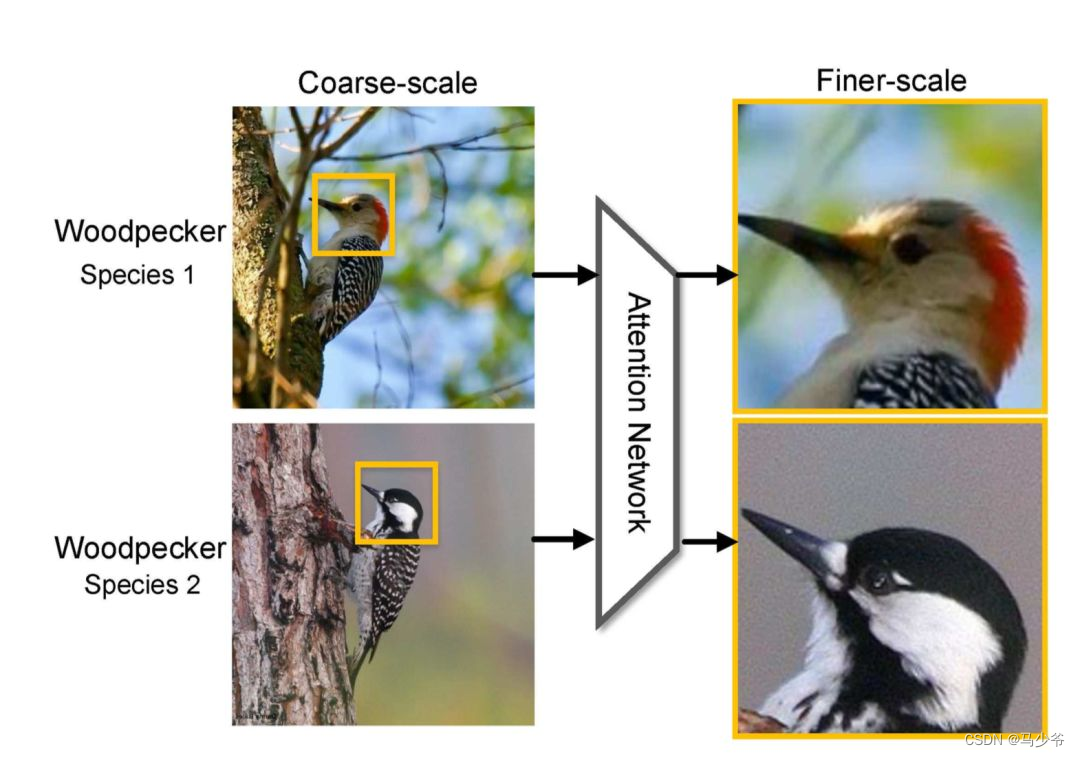
We know that the real problem in fine-grained classification tasks is how to locate local areas that are really useful for the task , The head of the bird in the above diagram .Attention The mechanism happens to be very suitable in principle , writing [1],[6] Attention mechanisms are used in , The improvement effect on the model is obvious .
3.2 Salient object detection / Thumbnail generation / Automatic composition
We're back to the beginning , you 're right ,Attention The essence of is important / Significant area positioning , So it is very useful in the field of target detection .


The above figure shows the results of several significant target detection , It can be seen that for graphs with significant goals , The probability map is very focused on the target subject , Add attention mechanism module to the network , The model of this kind of task can be further improved .
reference
[1] Jaderberg M, Simonyan K, Zisserman A. Spatial transformer networks[C]//Advances in neural information processing systems. 2015: 2017-2025.
[2] Almahairi A, Ballas N, Cooijmans T, et al. Dynamic capacity networks[C]//International Conference on Machine Learning. 2016: 2549-2558.
[3] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
[4] Li X, Wang W, Hu X, et al. Selective Kernel Networks[J]. 2019.
[5] Woo S, Park J, Lee J Y, et al. Cbam: Convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 3-19.
[6] Fu J, Zheng H, Mei T. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4438-4446.
reference :https://blog.csdn.net/qq_42722197/article/details/123039018
边栏推荐
- “去虚向实”大潮下,百度智能云向实而生
- 2022.6.28
- “零售为王”下的家电产业:什么是行业共识?
- Le tube MOS réalise le circuit de commutation automatique de l'alimentation principale et de l'alimentation auxiliaire, et la chute de tension "zéro", courant statique 20ua
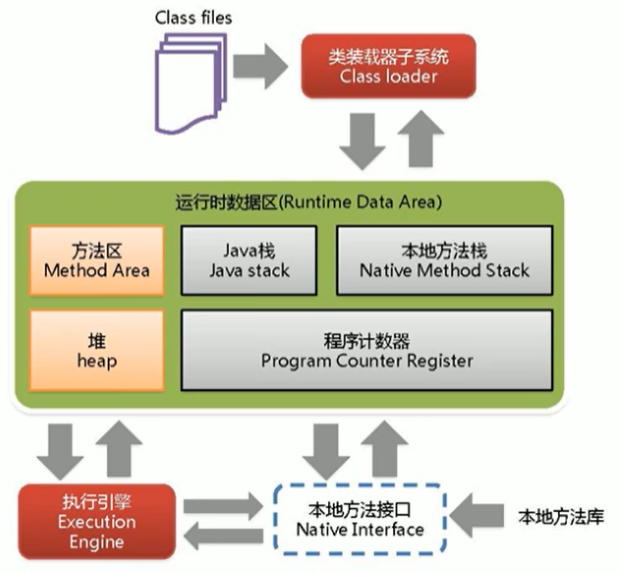
- Shangsilicon Valley JVM Chapter 1 class loading subsystem
- 知识图谱构建全流程
- 硬件之OC、OD、推挽解释
- CVPR 2022 best paper candidate | pip: six inertial sensors realize whole body dynamic capture and force estimation
- MOS transistor realizes the automatic switching circuit of main and auxiliary power supply, with "zero" voltage drop and static current of 20ua
- mos管实现主副电源自动切换电路,并且“零”压降,静态电流20uA
猜你喜欢


随机推荐
杰理之开启经典蓝牙 HID 手机的显示图标为键盘设置【篇】
[swift] learning notes (I) -- familiar with basic data types, coding styles, tuples, propositions
Shangsilicon Valley JVM Chapter 1 class loading subsystem
安装 torch 0.4.1
数学归纳与递归
杰理之开 BLE 退出蓝牙模式卡机问题【篇】
体会设计细节
Appx code signing Guide
2022.6.28
leetcode
VHDL实现任意大小矩阵加法运算
从 1.5 开始搭建一个微服务框架——日志追踪 traceId
腾讯云原生数据库TDSQL-C入选信通院《云原生产品目录》
Oracle connection pool is not used for a long time, and the connection fails
Construction of knowledge map of mall commodities
Leetcode-02 (linked list question)
Jerry's ble exiting Bluetooth mode card machine [chapter]
opencv环境的搭建,并打开一个本地PC摄像头。
QT Bluetooth: qbluetooth DeviceInfo
【基于 RT-Thread Studio的CPK-RA6M4 开发板环境搭建】