当前位置:网站首页>Principle of persistence mechanism of redis
Principle of persistence mechanism of redis
2022-07-05 11:44:00 【We've been on the road】
One 、redis Persistence of
Redis Support two ways of persistence , One is RDB The way 、 The other is AOF(append-only-file) The way , Two kinds of persistence
You can use one of them alone , You can also combine these two methods .
RDB: According to the specified rules “ timing ” Store the data in memory on the hard disk ,
AOF: Record the command itself after each command execution .
Two 、RDB
1. Configuration of snapshot generation
RDB The way to persist is through snapshots (snapshotting) Accomplished , It is Redis Default persistence method , The configuration is as follows .
# save 3600 1
# save 300 100
# save 60 10000
Redis Allows users to customize snapshot conditions , When the snapshot conditions are met ,Redis The snapshot operation will be performed automatically . The conditions of snapshots can be configured by the user in the configuration file . The configuration format is as follows
save <seconds> <changes>
The first parameter is the time window , The second is the number of keys , in other words , The number of keys changed within the configuration range of the first time parameter is greater than the following changes when , That is, it meets the snapshot conditions . When the trigger condition ,Redis It will automatically generate a copy of the data in memory and store it on disk , This process is called “ snapshot ”
Other parameter settings
| Parameters | explain |
|---|---|
| dir | rdb The file is in the boot directory by default ( Relative paths ) config get dir obtain |
| dbfilename | File name |
| rdbcompression | Turn on compression to save storage space , But it will consume some CPU Calculation time , Default on |
| rdbchecksum | Use CRC64 Algorithm to check data , But doing so will add about 10% Performance consumption of , If you want to get the maximum performance improvement , You can turn it off . |
If you need to close RDB Persistence mechanism of , You can refer to the following configuration , Turn on save , And annotate other rules
save ""
#save 900 1
#save 300 10
#save 60 10000
2. In addition to the above rules , There are also several ways to generate snapshots
2.1 User execution SAVE perhaps GBSAVE command
Except for Jean Redis Automatic snapshot , When we restart the service or migrate the server, we need to manually intervene in the backup .redis Two commands are provided to complete this task
6. save command
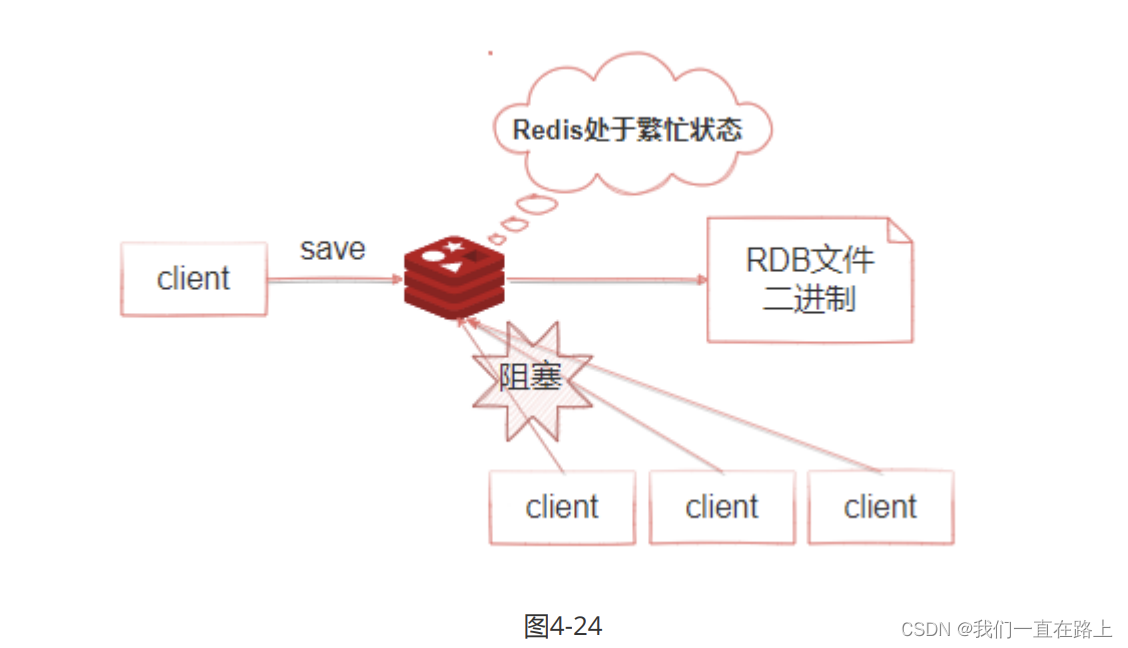
Pictured 4-24 Shown , When executed save On command ,Redis Synchronize snapshot operations , All requests from clients will be blocked during snapshot execution . When redis When there is more data in memory , Passing this command will result in Redis Long time non response . Therefore, it is not recommended to use this command in a production environment , It's recommended bgsave command
- bgsave command
As shown in the figure below ,bgsave The command can perform snapshot operations asynchronously in the background , While taking a snapshot, the server can continue to respond to requests from the client . perform BGSAVE after ,Redis Will return immediately ok Indicates that the snapshot operation is started , stay redis-cli terminal , You can obtain the time of the last successful snapshot execution through the following command ( With UNIX Time stamp format means ).
LASTSAVE
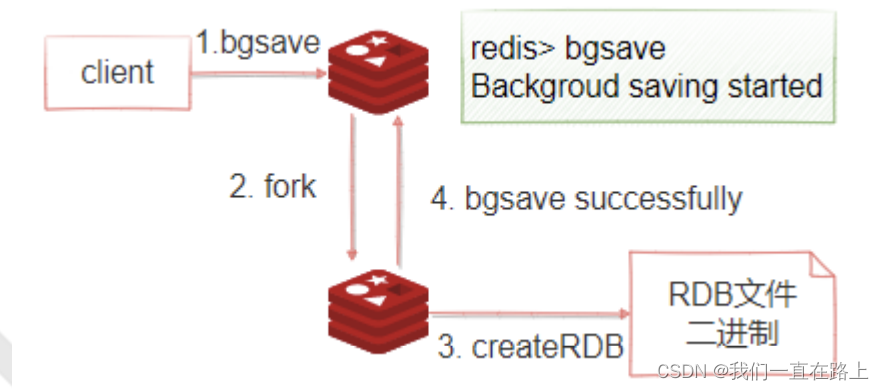
1:redis Use fork Function copies a copy of the current process ( Subprocesses )
2: The parent process continues to receive and process commands from the client , The subprocess begins to write the data in memory to temporary files in the hard disk
3: When the subprocess has finished writing all the data, it will replace the old one with the temporary one RDB file , thus , A snapshot operation is completed .
Be careful :redis It will not be modified during snapshot RDB file , Only after the end of the snapshot will the old file be replaced with the new , That is to say, any time RDB The documents are complete . This allows us to make regular backups RDB File to implement redis Backup of database , RDB Files are compressed binaries , It takes up less space than the data in memory , It's easier to transmit .bgsave The snapshot is executed asynchronously ,bgsave The data written is fork Process time redis Data status of , Once that is done fork, The data changes caused by the new client commands executed later will not be reflected in this snapshot Redis It will read RDB Snapshot file , And load the data from the hard disk into memory . Depending on the amount of data and server performance , The loading time is also different .
2.2. perform FLUSHALL command
The command was mentioned earlier , Will clear redis All data in memory . After executing the command , as long as redis The snapshot rule configured in is not empty , That is to say save The rules exist .redis A snapshot operation will be performed . No matter what the rules are, they will be implemented . If no snapshot rule is defined , The snapshot operation will not be performed .
2.3. Perform replication (replication) when
This operation is mainly in master-slave mode ,redis Automatic snapshot will be taken when replication is initialized . There are no automatic snapshot rules defined for instant , And there is no manual snapshot operation , It will still generate RDB Snapshot file .
3.RDB The strengths and weaknesses of the document
advantage
- RDB It's a very compact (compact) The file of , It has been saved. redis Data set at a certain point in time , This kind of document is very Suitable for backup and disaster recovery .
- Generate RDB When you file ,redis The main process will fork() A subprocess to handle all the saving work , The main process does not need to Any disk IO operation .
- RDB Speed ratio when recovering large data sets AOF It's faster to recover .
Inferiority
RDB Modal data cannot be persisted in real time / Second persistence . because bgsave Run every time fork Operational innovation Build a process , Frequent execution cost is too high
Make a backup at regular intervals , So if redis accident down If you drop it , After the last snapshot All modifications ( Data is missing ).
If the data is relatively important , Hope to minimize the loss , You can use AOF Way to persist .
3、 ... and 、AOF
AOF(Append Only File):Redis Not on by default .AOF Log every write operation , And add it to the file . After opening , Make changes Redis When data is ordered , Will write the command to AOF In file .Redis During the restart, the write instructions will be executed from the front to the back according to the contents of the log file to complete the data recovery .
AOF Configuration switch
# switch
appendonly no /yes
# file name
appendfilename "appendonly.aof"
problem 1: Is data persistent to disk in real time ?
Although every time a change is made Redis Operation of database content ,AOF Will record the command in AOF In file , But in fact , Because of the caching mechanism of the operating system , The data is not actually written to the hard disk , Instead, it enters the system's hard disk cache . By default, the system every 30 The synchronization operation will be performed once per second . So that the contents of the hard disk cache can really be written to the hard disk . Here 30 If the system exits abnormally during seconds, the data in the hard disk cache will be lost . Generally speaking, it can enable AOF The premise is that the business scenario cannot tolerate such data loss , This is the time Redis In the writing AOF After the file is, the system is actively required to synchronize the cached content to the hard disk . stay redis.conf The synchronization mechanism is set in the following configuration .
| project | Value |
|---|---|
| appendfsync everysec | AOF Persistence strategy ( Hard disk cache to disk ), Default everysec1 no Means not to execute fsync, Data synchronization to disk is guaranteed by the operating system , The fastest , But it's not safe ;2 always Indicates that every write is executed fsync, To ensure data synchronization to disk , Efficiency is very low ;3 everysec Represents one execution per second fsync, It could lead to the loss of this 1s data . Usually choose everysec , Both safety and efficiency . |
problem 2: The files are getting bigger , What do I do ?
because AOF Persistence is Redis Keep writing orders to AOF In file , With Redis Constantly running ,AOF It's going to get bigger and bigger , The bigger the file , The larger the server's memory and AOF The longer it takes to recover .
for example set gupao 666, perform 1000 Time , The result is gupao=666.
To solve this problem ,Redis New rewrite mechanism , When AOF When the file size exceeds the set threshold ,Redis Will start AOF The content of the file is compressed , Keep only the smallest instruction set that can recover data . You can use the following command to actively trigger rewriting
redis> bgrewriteaof
AOF File rewriting is not about rearranging the original file , Instead, read the existing key value pairs of the server directly , Then use one command to replace the previous commands recording this key value pair , Create a new file and replace the original one AOF file .
The rewriting trigger mechanism is as follows
| Parameters | explain |
|---|---|
| auto-aofrewritepercentage | The default value is 100. It means when the current AOF The file size is larger than that of the last rewrite AOF What percentage of the file size will be rewritten again , If it hasn't been rewritten before , At startup AOF File size is based on |
| auto-aofrewritemin-size | Default 64M. The representation limits the minimum number of overrides allowed AOF file size , Usually in AOF When the file is very small, even if there are many redundant commands, we don't care much |
When it starts ,Redis It will be executed one by one AOF File to load data from the hard disk into memory , The loading speed is relative to RDB It will be slower
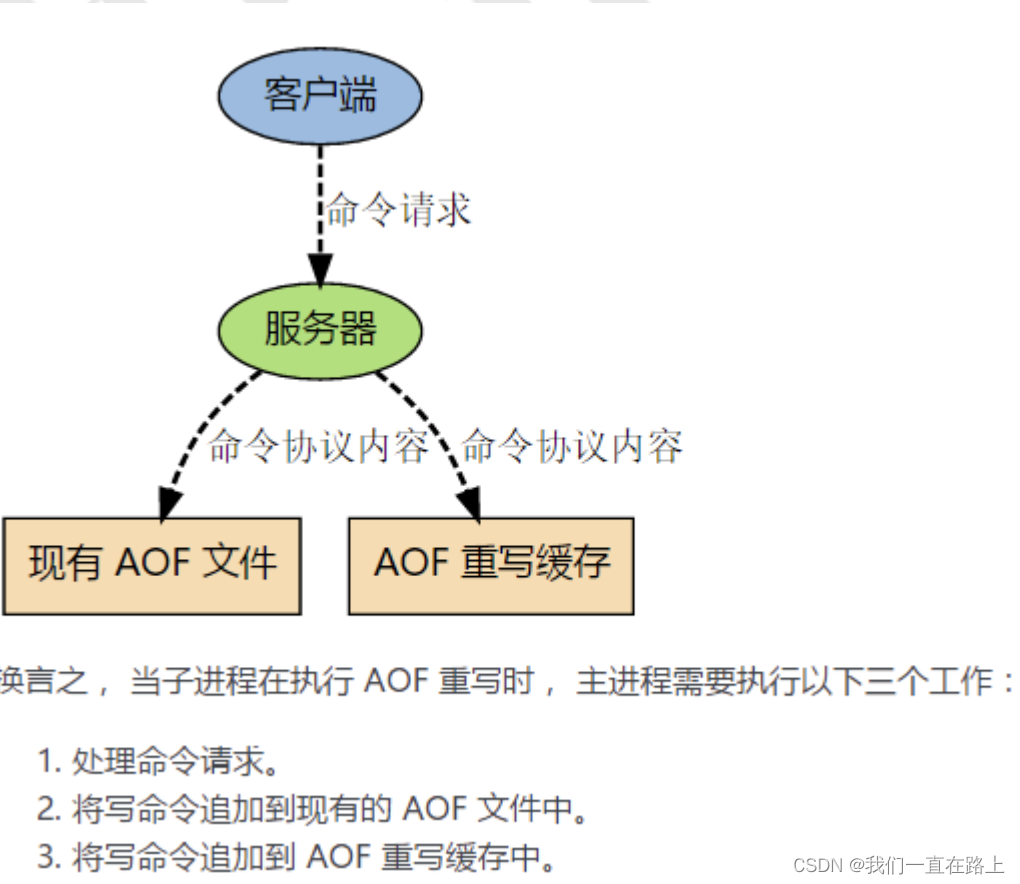
problem : In the process of rewriting ,AOF What to do if the document is changed ?
Redis Can be in AOF When the file size becomes too large , Automatically in the background AOF Rewrite : The rewritten new AOF The file contains the minimum set of commands required to recover the current dataset .
Process rewriting
- The main process will fork A sub process comes out and AOF rewrite , This rewriting process is not based on the original aof File to do , It's a bit like a snapshot , Full traversal of data in memory , Then sequence one by one to aof In file .
- stay fork Subprocesses in this process , The server can still provide external services , It was rewritten at this time aof Data and redis What if the memory data is inconsistent ? Never mind , In the process , Data update operation of the main process , Caches to aof_rewrite_buf in , That is to open up a separate cache to store commands received during rewriting , When the child process finishes rewriting, the data in the cache is appended to the new process aof file .
- When all the data is added to the new aof After in file , Put the new aof File rename official file name , After that, all operations will be written to the new aof file .
- If in rewrite Failure in the process , It won't affect the original aof Normal operation of documents , Only when rewrite The file will not be switched until it is finished . So the rewrite The process is more reliable .
Redis Allow simultaneous opening of AOF and RDB, It not only ensures the data security, but also makes the operation such as backup very easy . If it is turned on at the same time ,Redis Restart will use AOF File to recover data , because AOF Persistence of methods may lose less data .
Four 、AOF Advantages and disadvantages of
advantage :
1、AOF The persistence method provides a variety of synchronization frequencies , Even if you use the default synchronization frequency to synchronize once per second ,Redis At most, it's lost 1 Seconds of data .
shortcoming :
1、 For... With the same data Redis,AOF Documents are usually better than RDB Larger file size (RDB It's a snapshot of the data ).
2、 although AOF Provides a variety of synchronous frequencies , By default , The frequency of synchronization once per second also has high performance . In the case of high concurrency ,RDB Than AOF With good and better performance guarantee .
边栏推荐
- 全网最全的新型数据库、多维表格平台盘点 Notion、FlowUs、Airtable、SeaTable、维格表 Vika、飞书多维表格、黑帕云、织信 Informat、语雀
- 7 大主题、9 位技术大咖!龙蜥大讲堂7月硬核直播预告抢先看,明天见
- [configuration method of win11 multi-user simultaneous login remote desktop]
- Unity xlua monoproxy mono proxy class
- 【TFLite, ONNX, CoreML, TensorRT Export】
- How can China Africa diamond accessory stones be inlaid to be safe and beautiful?
- XML解析
- idea设置打开文件窗口个数
- CDGA|数据治理不得不坚持的六个原则
- 中非 钻石副石怎么镶嵌,才能既安全又好看?
猜你喜欢

![[upsampling method opencv interpolation]](/img/6b/5e8f3c2844f0cbbbf03022e0efd5f0.png)
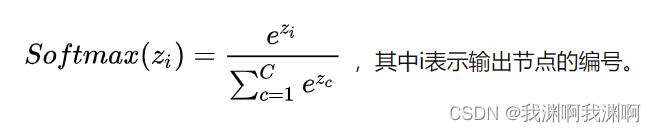
随机推荐
Advanced technology management - what is the physical, mental and mental strength of managers
Pytorch softmax regression
[crawler] Charles unknown error
yolov5目标检测神经网络——损失函数计算原理
871. Minimum Number of Refueling Stops
Crawler (9) - scrape framework (1) | scrape asynchronous web crawler framework
What about SSL certificate errors? Solutions to common SSL certificate errors in browsers
【PyTorch预训练模型修改、增删特定层】
idea设置打开文件窗口个数
Startup process of uboot:
XML parsing
[singleshotmultiboxdetector (SSD, single step multi frame target detection)]
ACID事务理论
如何通俗理解超级浏览器?可以用于哪些场景?有哪些品牌?
pytorch-线性回归
pytorch-权重衰退(weight decay)和丢弃法(dropout)
Web API configuration custom route
How did the situation that NFT trading market mainly uses eth standard for trading come into being?
How to get a token from tokenstream based on Lucene 3.5.0
SET XACT_ ABORT ON