当前位置:网站首页>pytorch-线性回归
pytorch-线性回归
2022-07-05 11:34:00 【我渊啊我渊啊】
1、导入表格数据
filename = "./data.csv"
data = pd.read_csv(filename)
features = data.iloc[:,1:]
labels = data.iloc[:,0]
2、转成Tensor形式
''' DataFrame ----> Tensor '''
features = torch.tensor(features.values, dtype=torch.float32)
labels = torch.tensor(labels.values, dtype=torch.float32)
labels = torch.reshape(labels,(-1,1))
3、生成迭代器,分批次读取数据
from torch.utils import data
def load_array(data_arrays , batch_size , is_train = True):
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset , batch_size , shuffle = is_train)
batch_size = 10
data_iter = load_array((features,labels),batch_size)
next(iter(data_iter))
4、定义神经网络
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.layer1 = nn.Linear(2, 1)
def forward(self, x):
return self.layer1(x)
5、训练网络
model = LinearRegression()
gpu = torch.device('cuda')
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
Loss = []
epochs = 1000
def train():
for i in range(epochs):
for X , y in data_iter:
y_hat = model(X) # 计算模型输出结果
loss = mse_loss(y_hat, y) # 损失函数
loss_numpy = loss.detach().numpy()
Loss.append(loss_numpy)
optimizer.zero_grad() # 梯度清零
loss.backward() # 计算权值
optimizer.step() # 修改权值
print(i, loss.item(), sep='\t')
train() # 训练
for parameter in model.parameters():
print(parameter)
plt.plot(Loss)
6 整体代码
import matplotlib.pyplot as plt
import pandas as pd
import torch
from torch import nn, optim
from torch.utils import data
class LinearRegression (nn.Module):
def __init__(self, feature_nums):
super (LinearRegression, self).__init__ ()
self.layer1 = nn.Linear (feature_nums, 1)
def forward(self, x):
return self.layer1 (x)
def load_array(data_arrays, batch_size, is_train=True):
dataset = data.TensorDataset (*data_arrays)
return data.DataLoader (dataset, batch_size, shuffle=is_train)
def Linear_Regression_pytorch(filepath, feature_nums, batch_size, learning_rate, epochs):
filename = filepath
data = pd.read_csv (filename)
features = data.iloc[:, 1:]
labels = data.iloc[:, 0]
features = torch.tensor (features.values)
features = torch.tensor (features, dtype=torch.float32)
labels = torch.tensor (labels.values)
labels = torch.tensor (labels, dtype=torch.float32)
labels = torch.reshape (labels, (-1, 1))
batch_size = batch_size
data_iter = load_array ((features, labels), batch_size)
next (iter (data_iter))
model = LinearRegression (feature_nums)
gpu = torch.device ('cuda')
mse_loss = nn.MSELoss ()
optimizer = optim.Adam (model.parameters (), lr=learning_rate)
Loss = []
epochs = epochs
for i in range (epochs):
for X, y in data_iter:
y_hat = model (X) # 计算模型输出结果
loss = mse_loss (y_hat, y) # 损失函数
loss_numpy = loss.detach ().numpy ()
optimizer.zero_grad () # 梯度清零
loss.backward () # 计算权值
optimizer.step () # 修改权值
print (i, loss.item (), sep='\t')
Loss.append (loss.item ())
for parameter in model.parameters ():
print (parameter)
plt.plot (Loss)
plt.title("Loss")
plt.show ()
if __name__ == "__main__":
Linear_Regression_pytorch (filepath="data.csv",
feature_nums=2,
batch_size=10,
learning_rate=0.05,
epochs=1000
)
边栏推荐
- SET XACT_ABORT ON
- go语言学习笔记-初识Go语言
- Technology sharing | common interface protocol analysis
- MySQL 巨坑:update 更新慎用影响行数做判断!!!
- 如何通俗理解超级浏览器?可以用于哪些场景?有哪些品牌?
- Error assembling WAR: webxml attribute is required (or pre-existing WEB-INF/web.xml if executing in
- 爬虫(9) - Scrapy框架(1) | Scrapy 异步网络爬虫框架
- Shell script file traversal STR to array string splicing
- C operation XML file
- [SWT component] content scrolledcomposite
猜你喜欢
【Office】Excel中IF函数的8种用法
Evolution of multi-objective sorting model for classified tab commodity flow
COMSOL -- establishment of geometric model -- establishment of two-dimensional graphics
IPv6与IPv4的区别 网信办等三部推进IPv6规模部署
go语言学习笔记-分析第一个程序
Advanced technology management - what is the physical, mental and mental strength of managers

NFT 交易市场主要使用 ETH 本位进行交易的局面是如何形成的?
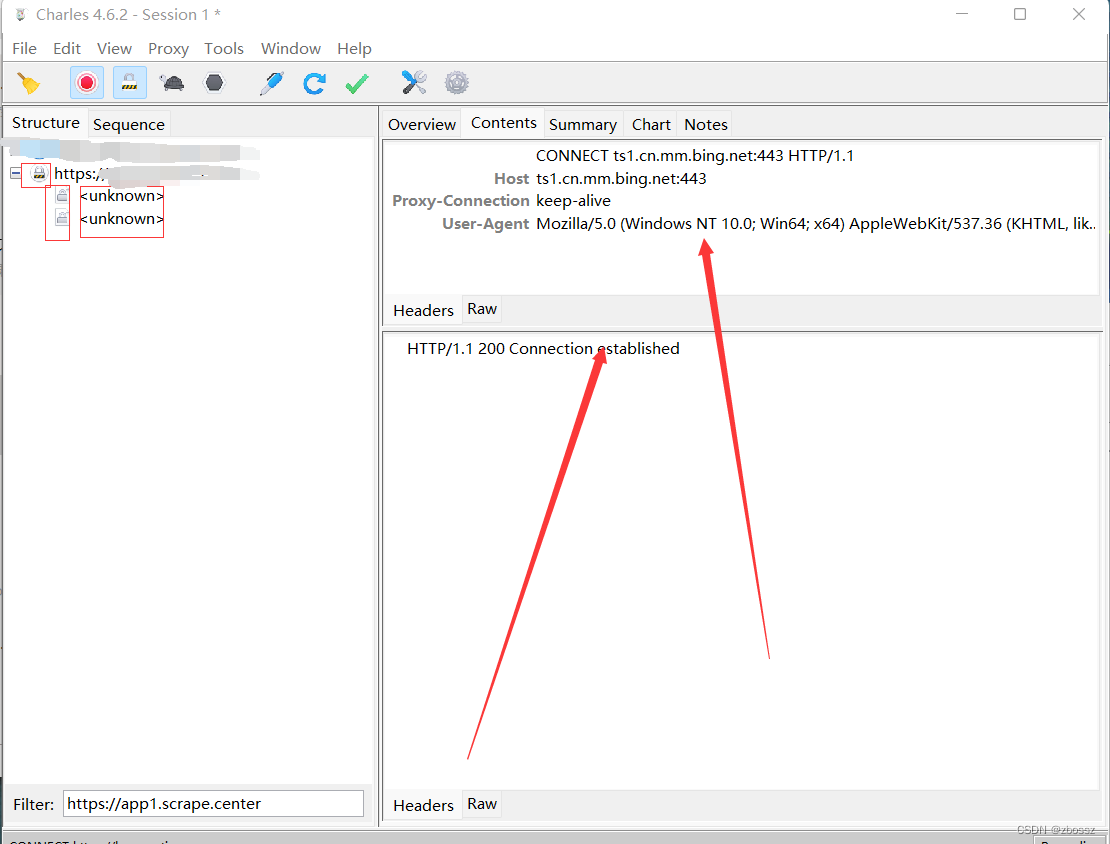
【爬虫】charles unknown错误
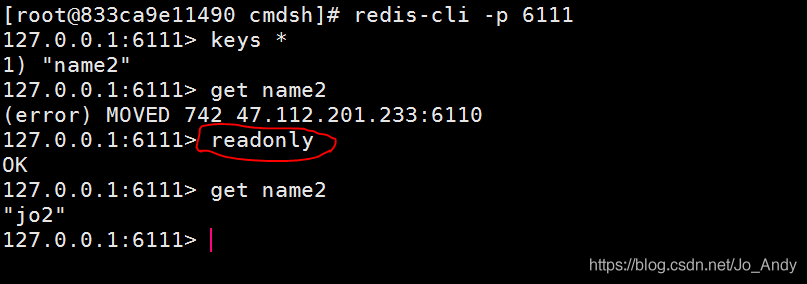
简单解决redis cluster中从节点读取不了数据(error) MOVED
AutoCAD -- mask command, how to use CAD to locally enlarge drawings
随机推荐
871. Minimum Number of Refueling Stops
AUTOCAD——遮罩命令、如何使用CAD对图纸进行局部放大
如何通俗理解超级浏览器?可以用于哪些场景?有哪些品牌?
871. Minimum Number of Refueling Stops
Summary of thread and thread synchronization under window
go语言学习笔记-初识Go语言
查看多台机器所有进程
idea设置打开文件窗口个数
spark调优(一):从hql转向代码
How did the situation that NFT trading market mainly uses eth standard for trading come into being?
C#实现WinForm DataGridView控件支持叠加数据绑定
How to get a token from tokenstream based on Lucene 3.5.0
石油化工企业安全生产智能化管控系统平台建设思考和建议
Go language learning notes - analyze the first program
shell脚本文件遍历 str转数组 字符串拼接
Risc-v-qemu-virt in FreeRTOS_ Scheduling opportunity of GCC
Crawler (9) - scrape framework (1) | scrape asynchronous web crawler framework
Evolution of multi-objective sorting model for classified tab commodity flow
百问百答第45期:应用性能探针监测原理-node JS 探针
13.(地图数据篇)百度坐标(BD09)、国测局坐标(火星坐标,GCJ02)、和WGS84坐标系之间的转换