当前位置:网站首页>Spark Tuning (I): from HQL to code
Spark Tuning (I): from HQL to code
2022-07-05 11:13:00 【InfoQ】
1. cause
SELECT id,name,
max(score1),
sum(score2),
avg(score3)
FROM table
GROUP BY id,name
snappy Compress , Raw data 500G
280 Billion data
First step Shuffle Write 800G
The next task is estimated to need 8 Run in an hour
2. Optimization starts
--conf spark.storage.memoryFraction=0.7
--conf spark.executor.heartbeatInterval=240
--conf spark.locality.wait=60
-XX:+UseG1GC
dataset.repartition(20000)
3. Problem solving
Dataset<Row> ds = spark.sql(sql);
dsTag0200.javaRDD().mapPartitionsToPair(
Transformation data
Group when key Make it tuple2
Here I cache some differences that need to be aggregated later
).reduceByKey(
Judge the maximum and minimum
sum The aggregation operation of uses difference to aggregate directly
You can directly output the final result once
)
4 summary
Conclusion
边栏推荐
- 9、 Disk management
- 数据库三大范式
- [there may be no default font]warning: imagettfbbox() [function.imagettfbbox]: invalid font filename
- About the use of Vray 5.2 (self research notes)
- 小红书自研KV存储架构如何实现万亿量级存储与跨云多活
- Wechat nucleic acid detection appointment applet system graduation design completion (7) Interim inspection report
- Detailed explanation of MATLAB cov function
- 四部门:从即日起至10月底开展燃气安全“百日行动”
- About the use of Vray 5.2 (self research notes)
- When using gbase 8C database, an error is reported: 80000502, cluster:%s is busy. What's going on?
猜你喜欢

关于vray 5.2的使用(自研笔记)
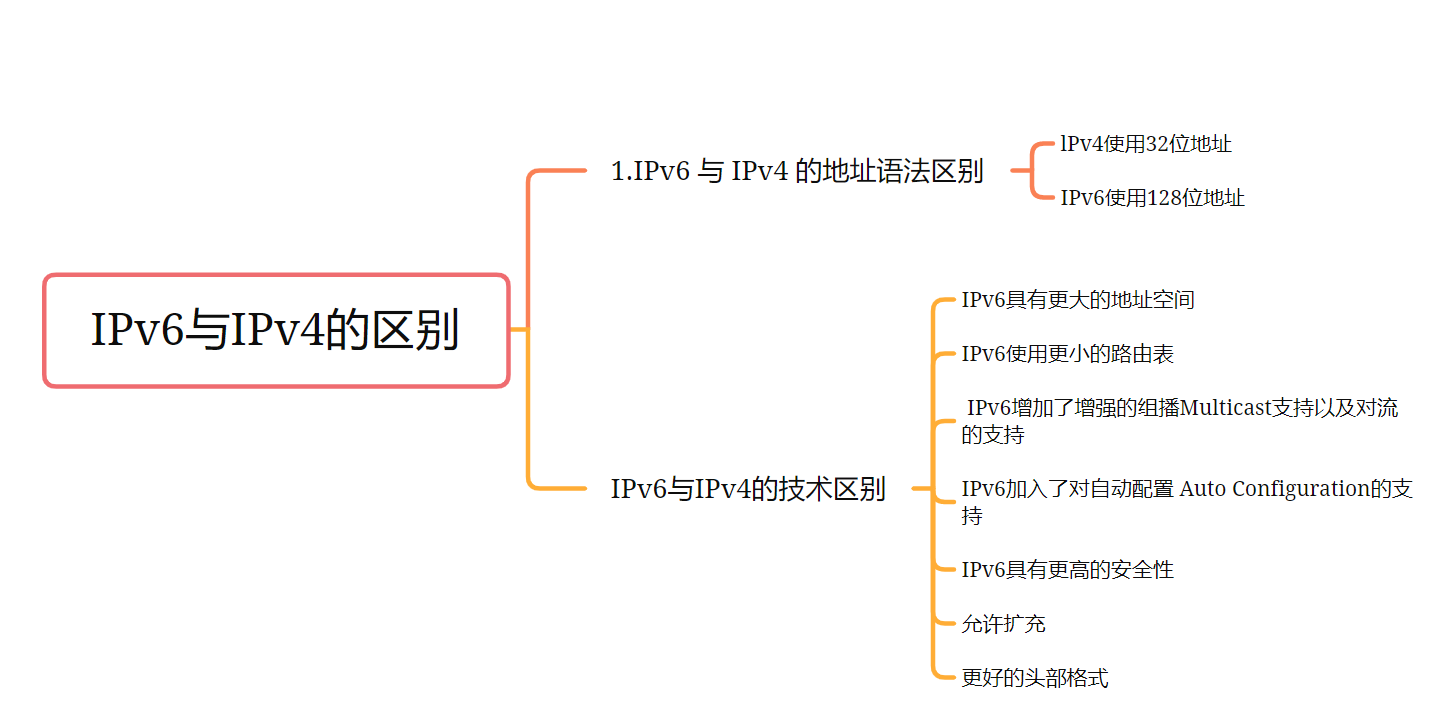
IPv6与IPv4的区别 网信办等三部推进IPv6规模部署
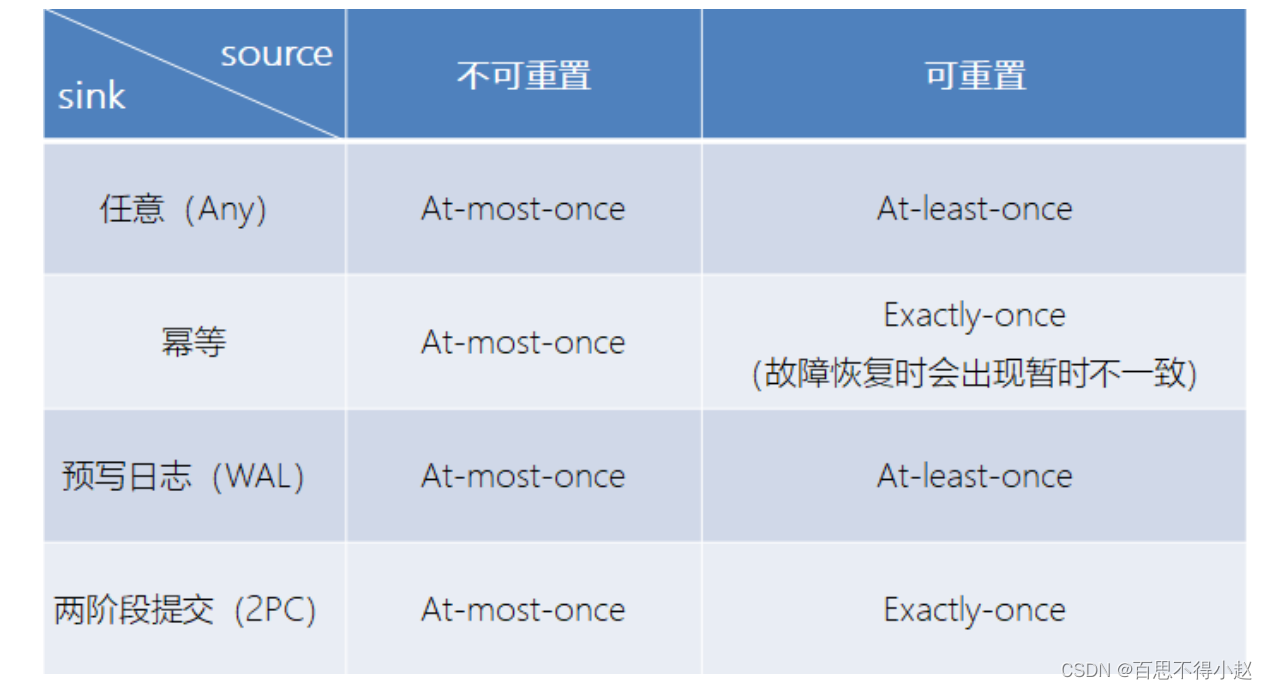
谈谈对Flink框架中容错机制及状态的一致性的理解

磨砺·聚变|知道创宇移动端官网焕新上线,开启数字安全之旅!
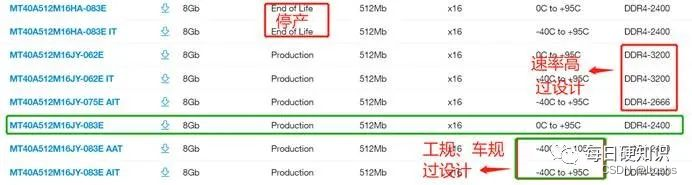
DDR4硬件原理图设计详解
磨礪·聚變|知道創宇移動端官網煥新上線,開啟數字安全之旅!
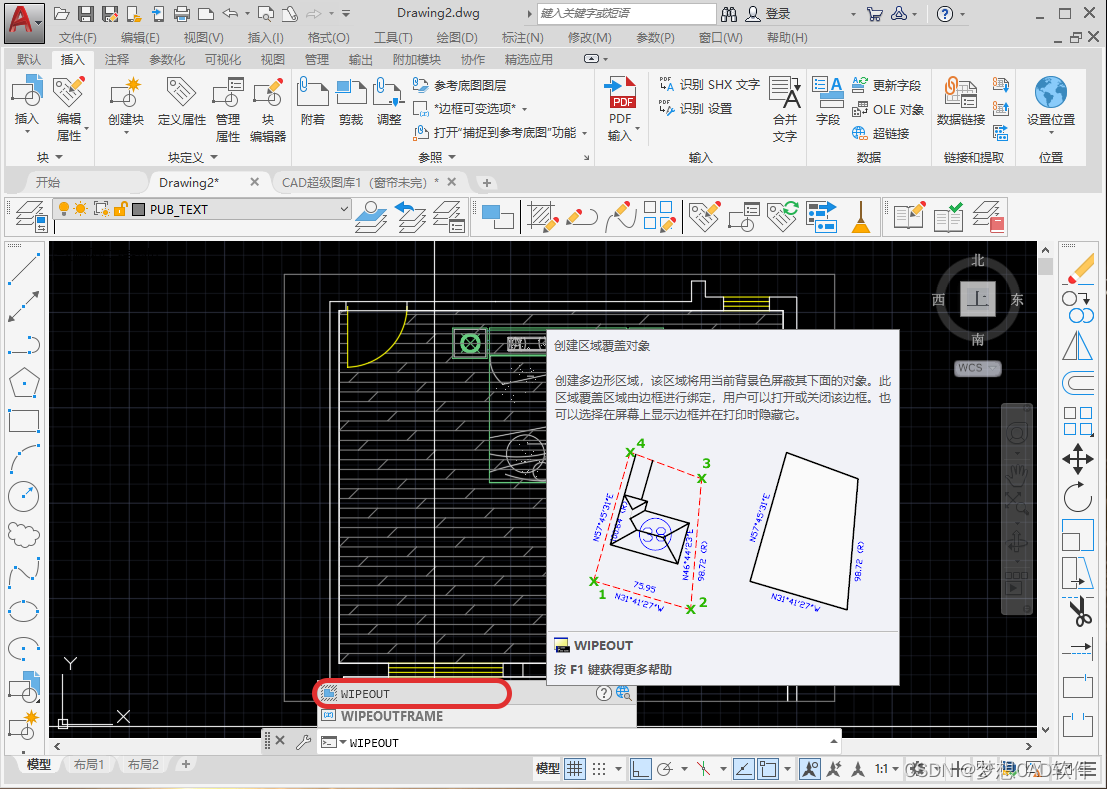
AUTOCAD——遮罩命令、如何使用CAD对图纸进行局部放大
基础篇——REST风格开发

Question bank and answers of special operation certificate examination for main principals of hazardous chemical business units in 2022

The first product of Sepp power battery was officially launched
随机推荐
Leetcode 185 All employees with the top three highest wages in the Department (July 4, 2022)
Three suggestions for purchasing small spacing LED display
[SWT component] content scrolledcomposite
Ddrx addressing principle
About the use of Vray 5.2 (self research notes)
基于昇腾AI丨爱笔智能推出银行网点数字化解决方案,实现从总部到网点的信息数字化全覆盖
Nuxt//
Sqlserver regularly backup database and regularly kill database deadlock solution
GBase 8c数据库如何查看登录用户的登录信息,如上一次登录认证通过的日期、时间和IP等信息?
The first product of Sepp power battery was officially launched
Do you really understand the things about "prototype"? [part I]
Basic part - basic project analysis
技术分享 | 常见接口协议解析
When using gbase 8C database, an error is reported: 80000502, cluster:%s is busy. What's going on?
matlab cov函数详解
Dspic33ep clock initialization program
About the use of Vray 5.2 (self research notes)
2022 Pengcheng cup Web
Deepfake tutorial
数据类型 ntext 和 varchar 在not equal to 运算符中不兼容 -九五小庞