当前位置:网站首页>【全网首发】(大表小技巧)有时候 2 小时的 SQL 操作,可能只要 1 分钟
【全网首发】(大表小技巧)有时候 2 小时的 SQL 操作,可能只要 1 分钟
2022-07-05 10:39:00 【HeapDump性能社区】
大家好,我是yes。
上篇文章 关于一张 5 亿数据表之我与 DBA 的 battle 发了之后,有好几个小伙伴来问我 SQL 是怎么拆的。
这篇我们来简单盘下,其实拆 SQL 是因为涉及大表删除的问题。
比如,你现在需要删除一张一共有 5 亿数据的表里面的 2021 年数据,假设这张表叫 yes。
我相信你脑子在 1s 内肯定会蹦出这条 SQL :
delete from yes where create_date > "2020-12-31" and create_date < "2022-01-01";
如果直接执行这条 SQL 会发生什么问题呢?
长事务
我们需要关注到一个前提:这张表有 5 亿的数据,所以它是一张超大表,因此这个 where 条件可能涉及非常多的数据,所以我们可以从离线数仓或者备库查下数据量,然后我们发现这条 SQL 会删除 3 亿左右的数据。
那么一次性 delete 完的方案是不行的,因为这会涉及到长事务的问题。
长事务涉及到加锁,只会在事务执行完毕后才会释放锁,由于长事务锁了很多数据,如果期间有频繁的 DML 想要操作这些数据,那么就会造成阻塞。
连接都阻塞住了,业务线程自然就阻塞了,也就是说你的服务线程都在等待数据库的响应,然后可能还会影响到别的服务,可能产生雪崩,于是就 GG 了。
长事务可能会造成主从延迟,你想想主库执行了好久,才执行完给从库,从库又要重放好久,期间可能有很长一段时间数据是不同步的。
还有一种情况,业务都有个特殊停机窗口,你觉得你可以为所欲为,然后开始执行长事务了,然后执行了 5 小时之后,不知道啥情况抛错了,事务回滚了,于是浪费了 5 个小时,还得重新开始。
综上,我们需要避免长事务的发生。
那面对可能发生长事务的 SQL 我们怎么拆呢?
拆 SQL
我们就以上面这条 SQL 为例:
delete from yes where create_date > "2020-12-31" and create_date < "2022-01-01";
看到这条 SQL,如果要拆分,想必很多小伙伴会觉得很简单,按日期拆不就完事了?
delete from yes where create_date > "2020-12-31" and create_date < "2021-02-01";
delete from yes where create_date >= "2021-02-01" and create_date < "2021-03-01";
......
这当然可以,恭喜你,你已经拆分成功了,没错就这么简单。
但是,如果 create_date 没有索引怎么办?
没索引的话,上面这就全表扫描了啊?
影响不大,没有索引我们就给他创造索引条件,这个条件就是主键。
我们直接一个 select min(id)... 和 select max(id).... 得到这张表的主键最小值和最大值,假设答案是233333333 和 666666666。
然后我们就可以开始操作了:
delete from yes where (id >= 233333333 and id < 233433333) and create_date > "2020-12-31" and create_date < "2022-01-01";
delete from yes where (id >= 233433333 and id <233533333) and create_date > "2020-12-31" and create_date < "2022-01-01";
......
delete from yes where (id >= 666566666 and id <=666666666) and create_date > "2020-12-31" and create_date < "2022-01-01";
当然你也可以再精确些,通过日期筛选来得到 maxId,这影响不大(不满足条件的 SQL 执行很快,不会耗费很多时间)。
这样一来 SQL 就满足了分批的操作,且用得上索引。
如果哪条语句执行出错,只会回滚小部分数据,我们重新排查下就好了,影响不大。
而且拆分 SQL 之后还可以并行提高执行效率。
当然我之前的文章说过,并行可能有锁竞争的情况,导致个别语句等待超时。不过影响不大,只要机器状态好,执行的快,因为锁竞争导致的等待并不一定会超时,如果个别 SQL 超时的话,重新执行就好了。
有时候要转换思路
关于大表删除有时候要转换思路,把删除转成插入。
假设还是有一张 5 亿的数据表,此时你需要删除里面 4.8 亿的数据,那这时候就不要想着删除了,要想着插入。
道理很简单,删除 4.8 亿的数据,不如把要的 2000W 插入到新表中,我们后面业务直接用新表就好了。
这两个数据量对比,时间效率差异不言而喻了吧?
具体操作也简单:
创建一张新表,名为 yes_temp 将 yes 表的 2000W 数据 select into 到 yes_temp 中 将 yes 表 rename 成 yes_233 将 yes_temp 表 rename 成 yes
狸猫换太子,大功告成啦!
之前有个记录表我们就是这样操作的,就 select into 近一个月的数据到新表中,以前老数据就不管了,然后 rename 一下,执行的非常快,1 分钟内就搞定了。
这种类似的操作是有工具的,比如 pt-online-schema-change 等,不过我没用过,有兴趣的小伙伴可以自己去看看,道理是一样的,多了几个触发器,这里不多赘述了。
最后
咱们开发还是得多学一些数据库的操作和原理,因为好多数据库的操作都需要你亲力亲为,小公司没 DBA 的话就不说了,大公司的话咱也不知道 DBA 到底会关心到哪个程度,还是得靠自己靠谱。
我翻了翻我之前的文章,好像 MySQL 相关写的是最多的,有兴趣的可以看下这个合集:MySQL合集
不过应该有文章挺多没加到这个合集的,有空我再整理整理。
欢迎关注我的个人公众号:【yes的练级攻略】
看到这里的你,如果对于我写的内容很感兴趣,有任何疑问,欢迎在下面留言,会第一次时间给大家解答,谢谢!
我是yes,从一点点到亿点点我们下篇见~
边栏推荐
- 32:第三章:开发通行证服务:15:浏览器存储介质,简介;(cookie,Session Storage,Local Storage)
- Explanation of message passing in DGL
- A usage example that can be compatible with various database transactions
- [可能没有默认的字体]Warning: imagettfbbox() [function.imagettfbbox]: Invalid font filename……
- uniapp
- About the use of Vray 5.2 (self research notes)
- 基于昇腾AI丨以萨技术推出视频图像全目标结构化解决方案,达到业界领先水平
- 数据类型、
- 第五届 Polkadot Hackathon 创业大赛全程回顾,获胜项目揭秘!
- Use bat command to launch common browsers with one click
猜你喜欢
Bidirectional RNN and stacked bidirectional RNN
32:第三章:开发通行证服务:15:浏览器存储介质,简介;(cookie,Session Storage,Local Storage)

Go语言-1-开发环境配置
2022 t elevator repair operation certificate examination questions and answers
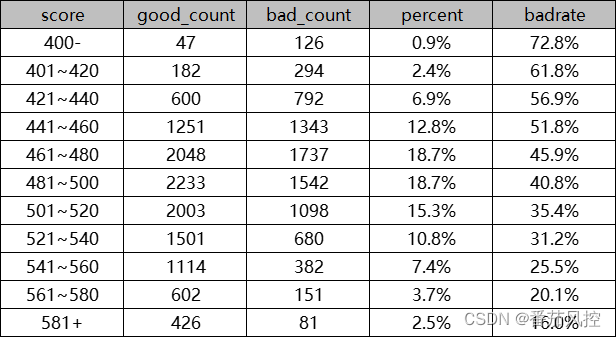
风控模型启用前的最后一道工序,80%的童鞋在这都踩坑
![C language QQ chat room small project [complete source code]](/img/4e/b3703ac864830d55c824e1b56c8f85.png)
C language QQ chat room small project [complete source code]

Operation of simulated examination platform of special operation certificate examination question bank for safety production management personnel of hazardous chemical production units in 2022

爬虫(9) - Scrapy框架(1) | Scrapy 异步网络爬虫框架
Ad20 make logo

2022 mobile crane driver examination question bank and simulation examination
随机推荐
2022鹏城杯web
How can non-technical departments participate in Devops?
About the use of Vray 5.2 (self research notes)
关于vray 5.2的使用(自研笔记)
风控模型启用前的最后一道工序,80%的童鞋在这都踩坑
Bidirectional RNN and stacked bidirectional RNN
Cross page communication
Node の MongoDB Driver
Web3 Foundation grant program empowers developers to review four successful projects
String
Process control
matlab cov函数详解
DGL中的消息传递相关内容的讲解
在C# 中实现上升沿,并模仿PLC环境验证 If 语句使用上升沿和不使用上升沿的不同
A mining of edu certificate station
跨页面通讯
关于 “原型” 的那些事你真的理解了吗?【上篇】
regular expression
PWA (Progressive Web App)
一次edu证书站的挖掘