当前位置:网站首页>Chained hash table
Chained hash table
2022-06-12 09:40:00 【Rookie ~~】
One 、 Defects of linear hash table
- When a hash conflict occurs , It is necessary to constantly look for the free location from the current conflict location , This process will slowly reduce the time complexity from O(1) become O(n), It's storage 、 The deletion and query process is slower . The more serious a hash conflict occurs, the closer it gets O(n) Complexity , Can this process be optimized ? Because it is a linear table , It's an array , Loop traversal is required , Tend to be O(n), Press one position to find , The more you look for , The time complexity is close to O(n). There is no way to optimize this process , Because there is only such an array structure . Of course, it can be optimized in the chain hash table .
- In the age when multi-core is very popular , Multi core is very convenient to use concurrent programs , That is, multiprocess multithreaded programs . There is a thread safety problem in the environment of multithreading , Can multiple threads be added to an array 、 Delete and query , Definitely not ! Like us C++ All containers in are not thread safe , To be used in multithreading, the mutex operation of threads must be used ( The mutex 、 Read write lock or spin lock ), To perform a thread mutually exclusive operation on the modified queries of these containers in a multi-threaded environment , Ensure that the operations of these containers in a multithreaded environment are all atomic operations . similarly ,vector The bottom layer is arrays , Arrays cannot be modified at the same time , Obviously, neither modification nor query is an atomic operation , Too many steps !** The hash table based on array used for linear detection , Only global tables can be mutexed to ensure the atomic operation of hash tables , Ensure thread safety !** Because linear detection has only one array , You have to lock the whole array , in other words , You are a thread , I'm a thread , If we all need to operate this thread at the same time , And we are not in the same position , In theory, it can be executed concurrently , But in fact, we can't let it execute without lock control , Because there may be hash conflicts , You need to find the next free location backwards , If we find the same free location , So no matter which of us put the elements first , In the end, the later ones cover the earlier ones . So we lock the entire hash table , Either you operate first , Or I'll do it first .
But chained hash tables can use segmented locks , This ensures thread safety , There is a certain amount of concurrency , Improved efficiency . Currently, the unordered associated containers in our library do not implement thread safety in multithreading , I didn't lock it , But that doesn't stop us when we really want to implement thread safety , The unordered Association container based on hash table can be directly used in multi-threaded environment , We can implement it in code by using segment lock .
Two 、 The principle of chain hash table
increase
Put the following set of data into the linked hash table .
The hash function uses the division and remainder method ( To reduce hash conflicts , The result of mapping should not conflict , The number of arrays should be a prime number , It's out 1 And yourself, but not divisible by other numbers , In this way, we try to reduce the conflict of the remainder .), The way to resolve hash conflicts is the chain address method .
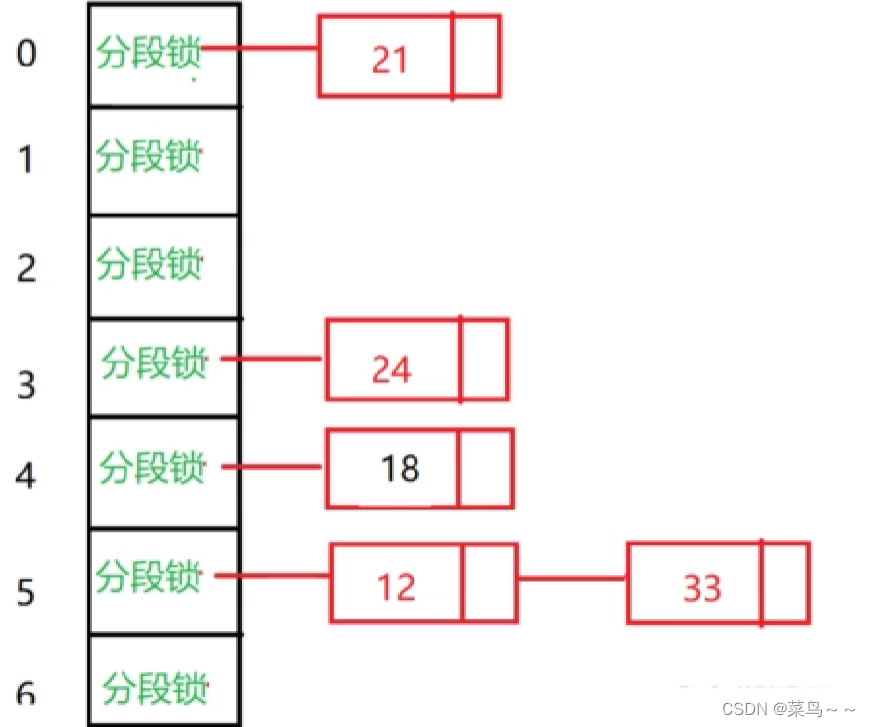
When a chain hash table has a conflict, it will not continue to probe backward like linear detection , Instead, a data structure is generated in the bucket ( Linked list ), We no longer need the state in the linked hash table , Each bucket has a linked list , Put all the elements with hash conflicts in a bucket , That is, the elements with hash conflicts are all connected to a linked list .
Why is it called a chained hash table ? First of all, its one-dimensional array is unchanged , Each element represents a hash bucket , But the bucket is no longer ordinary data , Put a linked list . Associate from the code :vector<list<int>> table.
Search for 
This 0 The linked list of bucket No. 1 has only one node, so it can be checked quickly . But when the linked list in each bucket of the linked hash table is relatively long , Linked list search takes more time , May approach O(n). So whether it is a chained hash table or a linear probe, it has a load factor , If the number of occupied barrels reaches... Of the total number of barrels 75%, The hash table is about to be expanded .
Delete
Deletion and search are very similar , To search first , Search it and delete it .
If the linked hash table is one of the bucket linked lists, it is very long , Many other barrels are empty , It means that the hash function is not selected well , There is no way to scatter the original data through a hash function . The hash function we need is to make the hash result as uniform as possible , Can be evenly distributed in the hash table , Improve the efficiency of the overall hash table .
Therefore, the time complexity of adding, deleting and checking hash tables can indeed reach O(1), But in most cases, there is no way to achieve O(1), Can only be infinitely close to O(1), Because of hash conflicts !
Two defects of linear hash table. What are the optimization methods when implementing in chain hash table ?
- When the length of the linked list is greater than a specified number , Turn the linked list in the bucket into a red black tree , The addition and deletion of red and black trees are O(logn), Obviously better than O(n) Linear complexity is much better .
- In the linked hash table , We only need to add a lock to each bucket to ensure thread safety . Therefore, the linked hash table must be in which bucket it first calculates , Just add a new node in the bucket . The linked list in each bucket cannot be operated concurrently , But the linked lists in different buckets can be operated concurrently .

3、 ... and 、 Chain hash table code implementation
swap Exchange elements of two containers , Will it be inefficient ?swap What is the underlying implementation ?
swap It's actually very efficient , It just swaps the member variables of the two containers , There is no exchange of data in the table , No re opening of memory 、 Re copy and so on .swap Exchange diagrams :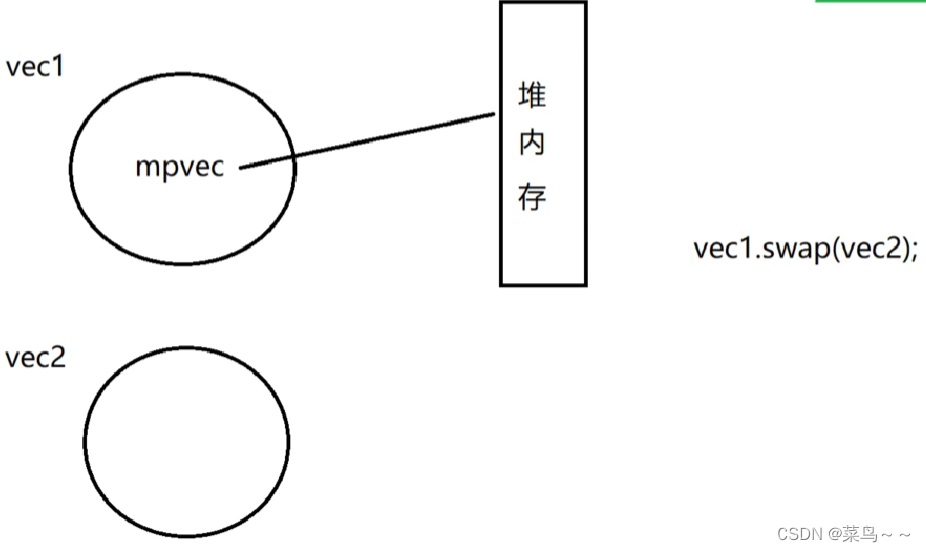

If two containers use different space configurators , For example, a container is managed by taking it out of the memory pool , A container is a common way to free memory free Method , So you can't simply exchange member variables .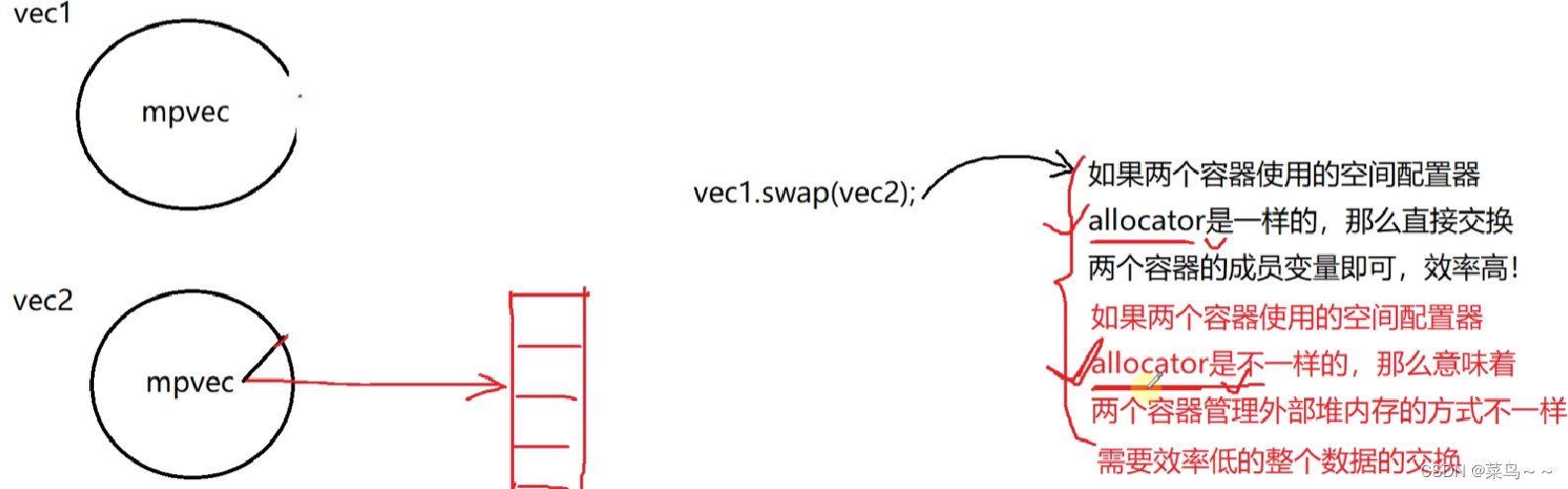
#include<iostream>
#include<vector>
#include<list>
#include<algorithm>
using namespace std;
class HashTable
{
private:
vector<list<int>> _table;
int _useBucketNum;
double _loadFactor;
static const int _primeSize = 10;
static int _primes[_primeSize];
int _primeIdx;
void expand()
{
++_primeIdx;
if (_primeIdx == _primeSize)
throw "hashtable is too large,can not expand anymore";
vector<list<int>> oldTable;
_table.swap(oldTable);
_table.resize(_primes[_primeIdx]);
for (auto list : oldTable)
{
for (auto key : list)
{
int idx = key % _primes[_primeIdx];
if (_table[idx].empty())
{
_useBucketNum++;
}
_table[idx].emplace_front(key);
}
}
}
public:
HashTable(int size = _primes[0], double loadFactor = 0.75)
:_useBucketNum(0), _loadFactor(loadFactor), _primeIdx(0)
{
if (size != _primes[0])
{
for (; _primeIdx < _primeSize; ++_primeIdx)
{
if (_primes[_primeIdx] > size)
{
break;
}
}
if (_primeIdx == _primeSize)
{
_primeIdx--;
}
}
_table.resize(_primes[_primeIdx]);
}
void insert(int key)
{
double factor = _useBucketNum * 1.0 / _table.size();
cout << factor << endl;
if (factor > 0.75)
{
expand();
}
int idx = key % _table.size();
if (_table[idx].empty())//O(1)
{
_useBucketNum++;
_table[idx].emplace_front(key);
}
else
{
auto it = ::find(_table[idx].begin(), _table[idx].end(), key);//O(n)
if (it == _table[idx].end())
{
//key non-existent
_table[idx].emplace_front(key);
}
}
}
void erase(int key)
{
int idx = key % _table.size();//O(1)
// If the linked list node is too long , If the hash function is concentrated ,( Problem with hash function !)
// If the hash is discrete , The length of the linked list is generally not too long , Because there is a loading factor
auto it = ::find(_table[idx].begin(), _table[idx].end(), key);//O(n)
if (it != _table[idx].end())
{
_table[idx].erase(it);
if (_table[idx].empty())
{
_useBucketNum--;
}
}
}
bool find(int key)
{
int idx = key % _table.size();//O(1)
auto it = ::find(_table[idx].begin(), _table[idx].end(), key);//O(n)
return it != _table[idx].end();
}
};
int HashTable::_primes[_primeSize] = {
3,7,23,47,97,251,443,911,1471,42773 };
int main()
{
HashTable htable;
htable.insert(12);
htable.insert(24);
htable.insert(38);
htable.insert(15);
htable.insert(14);
htable.insert(40);
htable.insert(93);
cout << htable.find(12) << endl;
htable.erase(12);
cout << htable.find(12) << endl;
}
Four 、 Hash table summary
Interview introduction hash table : A keyword , Mapping through hash function , Get its storage location in the table , In line with this key And its mapping relationship to get the storage location in the table , Such a table is called a hash table or hash table . Then we can explain the problem of hash conflict , Then explain the linear detection hash table and chain hash table to solve hash conflict .
Advantages and disadvantages :
Hash function :
Hash conflict handling :
Second detection : Like inserting 78, A hash conflict was found , Just look for it on the right , Then look on the left , Then look on the right , Then look on the left … Is the optimization of linear detection .
边栏推荐
猜你喜欢
What are the software testing requirements analysis methods? Let's have a look
Cas d'essai et spécification de description des bogues référence
功能测试面试常见的技术问题,总结好了你不看?

List、Set、Map的区别

MySQL优化之慢日志查询

Combat tactics based on CEPH object storage

In 2026, the capacity of China's software defined storage market will be close to US $4.51 billion
004:AWS数据湖解决方案

TAP 系列文章3 | Tanzu Application Platform 部署参考架构介绍

I Regular expression to finite state automata: regular expression to NFA



随机推荐
Combat tactics based on CEPH object storage
Selenium面试题分享
IV Transforming regular expressions into finite state automata: DFA minimization
Cas d'essai et spécification de description des bogues référence
Distributed task scheduling
Auto.js学习笔记7:js文件调用另一个js文件里的函数和变量,解决调用失败的各种问题
卖疯了的临期产品:超低价、大混战与新希望
Golandidea 2020.01 cracked version
【极术公开课预告】Arm最强MCU内核Cortex-M85处理器,全方位助力物联网创新(有抽奖)
Common technical questions in functional test interview. Would you like to summarize them?
JVM garbage collection
II Transforming regular expressions into finite state automata: NFA state machine recognizes input strings
哈希表的线性探测法代码实现
传输层协议 ——— TCP协议
Difference between MySQL unreal reading and non repeatable reading
How to write test cases?
软件测试工作经验分享,一定有你想知道的
5 most common CEPH failure scenarios
Summary of APP test interview questions, which must be taken in the interview
Microservice gateway