当前位置:网站首页>[cloud lesson] EI lesson 47 Mrs offline data analysis - processing OBS data through Flink
[cloud lesson] EI lesson 47 Mrs offline data analysis - processing OBS data through Flink
2022-07-06 20:06:00 【Hua Weiyun】
MRS Support large data storage capacity 、 When computing resources need elastic expansion , Users store data in OBS In service , Use MRS The storage and calculation separation mode in which the cluster only performs data calculation and processing .
Flink It is a unified computing framework combining batch processing and stream processing , Its core is a stream data processing engine that provides data distribution and parallel computing . Its biggest highlight is stream processing , It is the top open source stream processing engine in the industry .
This article will show you how to MRS Running in cluster Flink Homework to deal with OBS Data stored in .


In this example , We use MRS Cluster built-in Flink WordCount Operation procedure , To analyze OBS Source data saved in the file system , Count the number of word occurrences in the source data .
Of course, you can also get MRS Service sample code project , Reference resources Flink Development of guidelines Develop others Flink Flow operation procedure .
The basic operation process of this case is as follows :

establish MRS colony
This article is based on the purchase MRS 3.1.0 Take the cluster of version , Cluster not turned on Kerberos authentication .
In this example , Because we have to analyze and deal with OBS Data in the file system , Therefore, the advanced configuration parameters of the cluster should be MRS Cluster binding IAM Authority delegation , Enable components in the cluster to dock OBS And have the operation permission of the corresponding file system directory .
You can directly select the system default “MRS_ECS_DEFAULT_AGENCY”, You can also create others with OBS Custom delegation of file system operation permissions .

For example, the client installation directory is “/opt/client”.
Prepare test data
Creating Flink Before data analysis , We need to prepare the test data to be analyzed in advance , And upload the data to OBS File system .
Create one locally “mrs_flink_test.txt” file , For example, the contents of the file are as follows :
This is a test demo for MRS Flink. Flink is a unified computing framework that supports both batch processing and stream processing. It provides a stream data processing engine that supports data distribution and parallel computing.Select “ Storage > Object storage service ”, Sign in OBS Administrative console .
single click “ Parallel file system ”, Create a parallel file system , And upload the test data file .

For example, the file system name created is “mrs-demo-data”, Click system name , stay “ file ” On the page , Create a new folder “flink”, Upload test data to this directory .
Then the complete path of the test data of this example is “obs://mrs-demo-data/flink/mrs_flink_test.txt”.
Upload data analysis application .
When submitting jobs directly using the management console interface , Will have developed Flink Applications jar Files can also be uploaded to OBS File system , perhaps MRS Within cluster HDFS File system .
In this example, we use MRS Cluster built-in Flink WordCount Sample program , Can be obtained from MRS Get from the client installation directory of the cluster , namely “/opt/client/Flink/flink/examples/batch/WordCount.jar”.
take “WordCount.jar” Uploaded to the “mrs-demo-data/program” Under the table of contents .


Create and run Flink Homework
The way 1: Submit your homework online in the console interface .
Sign in MRS Administrative console , single click MRS Cluster name , Enter the cluster details page .
On the cluster details page “ overview ” Tab , single click “IAM User synchronization ” On the right side of the “ Click sync ” Conduct IAM User synchronization .
- single click , Get into Tab .
- single click “ add to ”, Add one Flink Homework .
The type of assignment :Flink
Job name : Customize , for example flink_obs_test.
Execution path : This example uses Flink Client's WordCount Program, for example .
Run program parameters : Use the default value .
Execute program parameters : Set the input parameters of the application ,“input” For the test data to be analyzed ,“output” Output files for results .
For example, in this example , We set it to “--input obs://mrs-demo-data/flink/mrs_flink_test.txt --output obs://mrs-demo-data/flink/output”.
- Service configuration parameters : Use the default value , If you need to manually configure parameters related to the job , May refer to function Flink Homework .
- After confirming the job configuration information , single click “ determine ”, Complete the addition of the job , And wait for the run to complete .


The way 2: Submit jobs through the cluster client .
- Use root The user logs in to the cluster client node , Enter the client installation directory .
su - ommcd /opt/clientsource bigdata_env Execute the following command to verify whether the cluster can access OBS.
hdfs dfs -ls obs://mrs-demo-data/flinkSubmit Flink Homework , Specify source file data for consumption .
flink run -m yarn-cluster /opt/client/Flink/flink/examples/batch/WordCount.jar --input obs://mrs-demo-data/flink/mrs_flink_test.txt --output obs://mrs-demo/data/flink/output2The results after execution are similar to the following :
...Cluster started: Yarn cluster with application id application_1654672374562_0011Job has been submitted with JobID a89b561de5d0298cb2ba01fbc30338bcProgram execution finishedJob with JobID a89b561de5d0298cb2ba01fbc30338bc has finished.Job Runtime: 1200 ms
View job execution results
After the job is submitted successfully , Sign in MRS Clustered FusionInsight Manager Interface , choice “ colony > service > Yarn”.
single click “ResourceManager WebUI” Follow the link to Yarn Web UI Interface , stay Applications View the current page Yarn Detailed operation status and operation log of the job .
Wait for the job to complete , stay OBS The results of data analysis output can be viewed in the result output file specified in the file system .
download “output” File locally and open , You can view the output analysis results .
a 3and 2batch 1both 1computing 2data 2demo 1distribution 1engine 1flink 2for 1framework 1is 2it 1mrs 1parallel 1processing 3provides 1stream 2supports 2test 1that 2this 1unified 1When submitting a job using the cluster client command line , If you do not specify the output directory , You can also directly view the data analysis results in the job operation interface .
Job with JobID xxx has finished.Job Runtime: xxx msAccumulator Results:- e6209f96ffa423974f8c7043821814e9 (java.util.ArrayList) [31 elements](a,3)(and,2)(batch,1)(both,1)(computing,2)(data,2)(demo,1)(distribution,1)(engine,1)(flink,2)(for,1)(framework,1)(is,2)(it,1)(mrs,1)(parallel,1)(processing,3)(provides,1)(stream,2)(supports,2)(test,1)(that,2)(this,1)(unified,1)


边栏推荐
- 腾讯云数据库公有云市场稳居TOP 2!
- Example of applying fonts to flutter
- PowerPivot——DAX(初识)
- Chic Lang: attributeerror: partially initialized module 'CV2' has no attribute 'GAPI_ wip_ gst_ GStreamerPipe
- Technology sharing | packet capturing analysis TCP protocol
- Introduction to enterprise lean management system
- Vscode debug run fluent message: there is no extension for debugging yaml. Should we find yaml extensions in the market?
- 夏志刚介绍
- Blue Bridge Cup microbial proliferation C language
- 350. Intersection of two arrays II
猜你喜欢
A5000 vgpu display mode switching

22-07-05 七牛云存储图片、用户头像上传
Speech recognition (ASR) paper selection: talcs: an open source Mandarin English code switching corps and a speech

Standardized QCI characteristics
Teach you to learn JS prototype and prototype chain hand in hand, a tutorial that monkeys can understand
![[Yann Lecun likes the red stone neural network made by minecraft]](/img/95/c3af40c7ecbd371dd674aea19b272a.png)
[Yann Lecun likes the red stone neural network made by minecraft]
(3) Web security | penetration testing | basic knowledge of network security construction, IIS website construction, EXE backdoor generation tool quasar, basic use of

PowerPivot - DAX (first time)
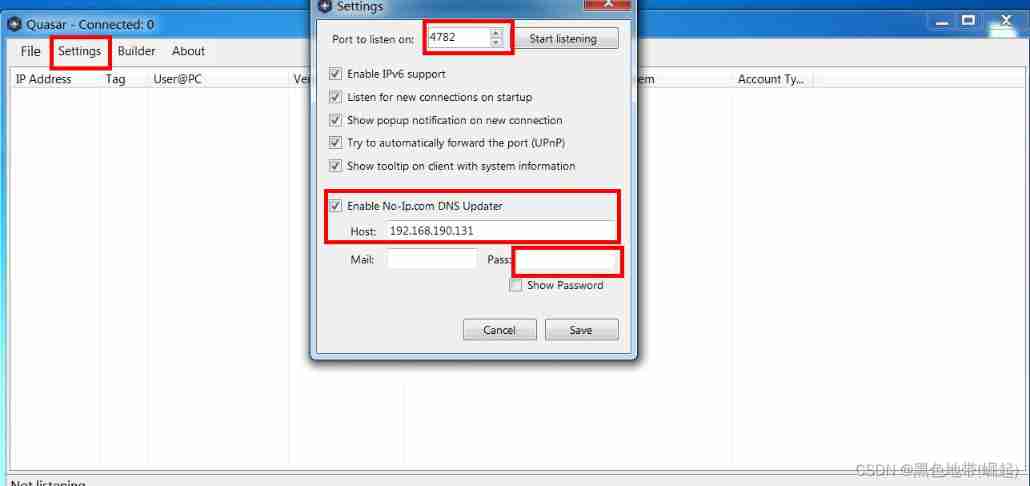
Configuration and simple usage of the EXE backdoor generation tool quasar

Introduction to enterprise lean management system
随机推荐
js实现力扣71题简化路径
Example of applying fonts to flutter
String length limit?
js获取浏览器系统语言
Cf960g - bandit Blues (type I Stirling number +ogf)
Groovy基础语法整理
Technology sharing | packet capturing analysis TCP protocol
In simple terms, interview surprise Edition
Alibaba data source Druid visual monitoring configuration
Poj1149 pigs [maximum flow]
PowerPivot——DAX(初识)
腾讯Android面试必问,10年Android开发经验
Understand yolov1 Part II non maximum suppression (NMS) in prediction stage
Speech recognition (ASR) paper selection: talcs: an open source Mandarin English code switching corps and a speech
golang的超时处理使用技巧
腾讯安卓开发面试,android开发的基础知识
Node. Js: express + MySQL realizes registration, login and identity authentication
POJ 3207 Ikki' s Story IV – Panda' s Trick (2-SAT)
Example of shutter text component
企业精益管理体系介绍