当前位置:网站首页>Hudi vs Delta vs Iceberg
Hudi vs Delta vs Iceberg
2022-07-06 19:35:00 【April day 03】
What is? TPC-DS?
TPC-DS It is a benchmark of data warehouse , from Transaction Processing Performance Council(TPC) Definition .TPC It's a non-profit organization , By the database community in 20 century 80 Established in the late S , Its goal is to develop benchmarks that can be objectively used to test the performance of database systems by simulating real-world scenarios .TPC Has had a significant impact on the database industry .
" Help make decisions "(Decision Support) yes TPC-DS Medium "DS" What it stands for .TPC-DS contain 99 A query , From simple aggregation to advanced pattern analysis .
1. We have publicly shared our views on Delta Modification of benchmark framework [8], To support the passage of Spark Datasource or Spark SQL establish Hudi surface . This can be switched dynamically in the benchmark definition .
2. TPC-DS Loading does not involve updating .Hudi Loaded databeans The configuration uses an inappropriate write operation
upsert, And clearly record [9] 了 Hudibulk-insert[10] Is the recommended write operation for this use case . Besides , We adjusted Hudi parquet File size set to match Delta Lake The default value is .
CREATE TABLE ...
USING HUDI
OPTIONS (
type = 'cow',
primaryKey = '...',
precombineField = '',
'hoodie.datasource.write.hive_style_partitioning' = 'true',
-- Disable Hudi’s record-level metadata for updates, incremental processing, etc
'hoodie.populate.meta.fields' = 'false',
-- Use “bulk-insert” write-operation instead of default “upsert”
'hoodie.sql.insert.mode' = 'non-strict',
'hoodie.sql.bulk.insert.enable' = 'true',
-- Perform bulk-insert w/o sorting or automatic file-sizing
'hoodie.bulkinsert.sort.mode' = 'NONE',
-- Increasing the file-size to match Delta’s setting
'hoodie.parquet.max.file.size' = '141557760',
'hoodie.parquet.block.size' = '141557760',
'hoodie.parquet.compression.codec' = 'snappy',
– All TPC-DS tables are actually relatively small and don’t require the use of MT table (S3 file-listing is sufficient)
'hoodie.metadata.enable' = 'false',
'hoodie.parquet.writelegacyformat.enabled' = 'false'
)
LOCATION '...'Hudi The origin of [11] Rooted in incremental data processing , To turn all old batch jobs into increments [12]. therefore ,Hudi The default configuration of is for incremental update insertion and for incremental ETL Pipeline generates change flow , Treat the initial load as a rare one-time operation . Therefore, we need to pay more attention to the loading time in order to be consistent with Delta Comparable
4. Run benchmark
4.1 load

You can see it clearly ,Delta and Hudi stay 0.11.1 The error in the version is 6% within , At present Hudi Of master* The mean square error is 5% within ( We are also right Hudi Of master The branch has been benchmarked , Because we have been Parquet An error was found in the encoding configuration [13] It has been solved in time ). by Hudi In primitive Parquet The rich feature set provided above the table provides support , for example :
• Incremental processing [14]( Because in the timestamp t Submit )
• Record level index [15]( Support record level search 、 Update and delete ),
There are more ,Hudi A set of additional metadata and each called meta field are stored internally [16] The record of . because tpc-ds Mainly focus on snapshot query , In this particular experiment , These fields have been disabled ( And not calculated ),Hudi Leave them blank , In order to open them in the future without pattern evolution . Add five such fields as null , Although the cost is very low , But still can not be ignored .
4.2 Inquire about

As we can see ,Hudi 0.11.1 and Delta 1.2.0 There is little difference in performance , and Hudi current master Faster (~5%). You can go to Google Drive The original log was found in this directory on :
• Hudi 0.11: load [17]/ Inquire about [18]
• Hudi master: load [19]/ Inquire about [20]
• Delta 1.2.0: load [21]/ Inquire about [22]
• Delta 2.0.0 rc1: load [23]/ Inquire about [24]
To reproduce the above results , Please use our in Delta Benchmark repository [25] And follow the steps in the readme .
5. Conclusion
To make a long story short , We want to emphasize the importance of openness and repeatability in such sensitive and complex areas as performance benchmarking . As we have seen over and over again , Obtaining reliable and reliable benchmark results is tedious and challenging , Need dedication 、 Diligent and rigorous support . Looking forward to the future , We plan to release more internal benchmarks , highlight Hudi How the rich feature set achieves unparalleled performance levels in other common industry workloads . Stay tuned !
Environment building
In this benchmark , We used Delta 1.0 and Iceberg 0.13.0, The environment configuration is listed in the following table .

As mentioned earlier , We used Delta Oss The open source TPC-DS The benchmark [5], And it is extended to support Iceberg. We recorded Load performance , That is to remove data from Parquet Format loaded into Delta/Iceberg The time required in the table . then , We also recorded Query performance . Every TPC-DS The query is run three times , Use the average running time as the result .
test result
1. Overall performance
After completing the benchmark , We found that whether it was Load still Query, The overall performance is Delta better , Because it's better than Iceberg fast 3.5 times . Load data into Delta And implement TPC-DS The query needs 1.68 Hours , and Iceberg You need to 5.99 Hours .

2. Load performance
When from Parquet When the file loads data into two formats ,Delta The overall performance is better than Iceberg fast 1.3 times .

For further analysis Load Performance results , We delved into the detailed loading results of each table , And notice that when the size of the table becomes larger , The difference in loading time will become larger . for example , When loading customer Table time ,Delta and Iceberg The performance of is actually the same . On the other hand , In the load store_sales surface , That is to say TPC-DS One of the largest tables in the benchmark ,Delta Than Iceberg fast 1.5 times .
This shows that , When loading data ,Delta Than Iceberg faster 、 Better scalability .

3. Query performance
In execution TPC-DS When inquiring ,Delta The overall performance ratio of Iceberg fast 4.5 times . stay Delta Executing all queries on requires 1.14 Hours , And in the Iceberg Executing the same query on requires 5.27 Hours .

Iceberg and Delta stay query34、query41、query46 and query68 It shows basically the same performance . The difference in these queries is less than 1 second .
However , In other TPC-DS Querying ,Delta All ratio Iceberg fast , And the level of difference varies .
In some queries , Such as query72,Delta Than Iceberg fast 66 times .
In other queries ,Delta and Iceberg The difference between 1.1 times To 24 times Between , All are Delta faster .

summary
After running the benchmark ,Delta In terms of scalability and performance, it exceeds Iceberg, And the range is sometimes unexpectedly large . This benchmark provides a clear answer for us and our customers , Which solution should be selected when building the data Lake warehouse .
It should also be pointed out that ,Iceberg and Delta Are constantly improving , As they improve , We will continue to pay attention to their performance , And share our results in the wider community .
If you want to further analyze and refine your opinion from the benchmark results , You can download the complete benchmark report here [6].
Original address :
https://databeans-blogs.medium.com/delta-vs-iceberg-performance-as-a-decisive-criteria-add7bcdde03d
边栏推荐
- A popular explanation will help you get started
- Learn to explore - use pseudo elements to clear the high collapse caused by floating elements
- 三面蚂蚁金服成功拿到offer,Android开发社招面试经验
- Hudi vs Delta vs Iceberg
- 学习探索-无缝轮播图
- 在解决了 2961 个用户反馈后,我做出了这样的改变...
- First day of rhcsa study
- Interview assault 63: how to remove duplication in MySQL?
- DaGAN论文解读
- Don't miss this underestimated movie because of controversy!
猜你喜欢

Dark horse -- redis

PMP practice once a day | don't get lost in the exam -7.6
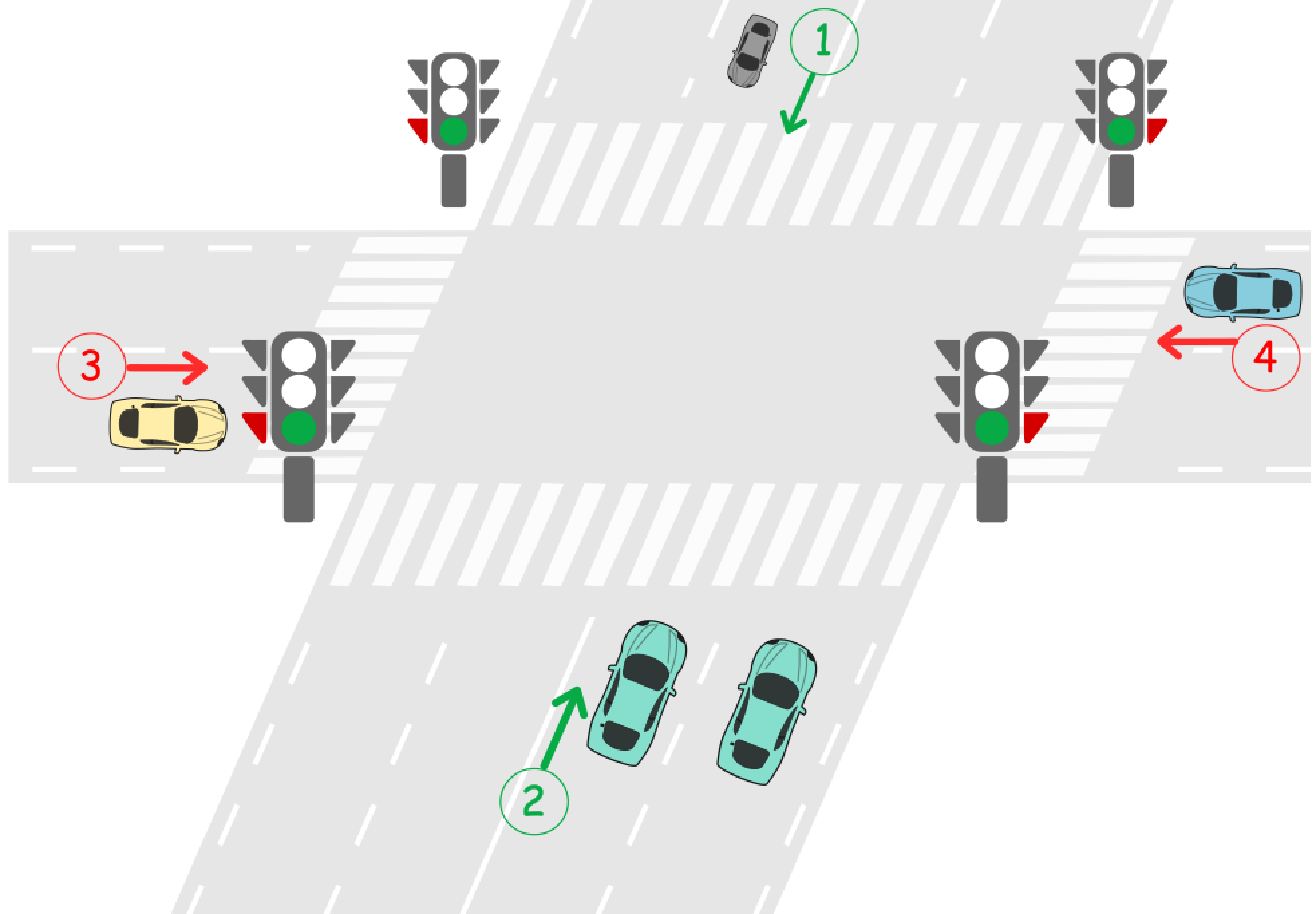
LeetCode-1279. 红绿灯路口

倒计时2天|腾讯云消息队列数据接入平台(Data Import Platform)直播预告

Mathematical knowledge -- code implementation of Gaussian elimination (elementary line transformation to solve equations)

思維導圖+源代碼+筆記+項目,字節跳動+京東+360+網易面試題整理
Countdown 2 days | live broadcast preview of Tencent cloud message queue data import platform
Zero foundation entry polardb-x: build a highly available system and link the big data screen
史上超级详细,想找工作的你还不看这份资料就晚了

Using clip path to draw irregular graphics
随机推荐
[translation] linkerd's adoption rate in Europe and North America exceeded istio, with an increase of 118% in 2021.
思维导图+源代码+笔记+项目,字节跳动+京东+360+网易面试题整理
倒计时2天|腾讯云消息队列数据接入平台(Data Import Platform)直播预告
zabbix 代理服务器 与 zabbix-snmp 监控
打家劫舍III[后序遍历与回溯+动态规划]
In depth analysis, Android interview real problem analysis is popular all over the network
Zero foundation entry polardb-x: build a highly available system and link the big data screen
安装Mysql报错:Could not create or access the registry key needed for the...
121. 买卖股票的最佳时机
Simple understanding of MySQL database
The list of people who passed the fifth phase of personal ability certification assessment was published
Solution of commercial supply chain management platform for packaging industry: layout smart supply system and digitally integrate the supply chain of packaging industry
MySQL information schema learning (II) -- InnoDB table
在解决了 2961 个用户反馈后,我做出了这样的改变...
Leetcode 30. 串联所有单词的子串
Excel 中VBA脚本的简单应用
Elastic search indexes are often deleted [closed] - elastic search indexes gets deleted frequently [closed]
Reflection and illegalaccessexception exception during application
Unbalance balance (dynamic programming, DP)
Take a look at how cabloyjs workflow engine implements activiti boundary events