当前位置:网站首页>【CTR】《Towards Universal Sequence Representation Learning for Recommender Systems》 (KDD‘22)
【CTR】《Towards Universal Sequence Representation Learning for Recommender Systems》 (KDD‘22)
2022-07-25 13:09:00 【chad_ lee】
《Towards Universal Sequence Representation Learning for Recommender Systems》 (KDD‘22)
The sequence recommendation is based on what the user has clicked item Sequence , Learn a sequence representation , Then predict the next one according to the characterization item, The models of modeling and representation are RNN、CNN、GNN、Transformer、MLP etc. .
Existing methods rely on explicit commodities ID modeling , There are problems of poor mobility and cold start ( Even if the data format of each recommended scenario is exactly the same ). The article is inspired by the pre training language model , Hope to design a sequence representation learning method for sequence recommendation .
The core idea is to use : Product related text ( Such as product description 、 title 、 Brand, etc ) To learn can Cross domain migration Product representation and sequence representation .( The model can be in the same APP Fast adaptation on new scenes 、 new APP Fast adaptation on ).
The core technology mainly depends on MoE And dynamic routing .
Two problems to solve :1、 We need to adapt the semantic space of the text to the recommendation task .2、 Span domain Data of may conflict , Cause the seesaw phenomenon .
UnisRec Model
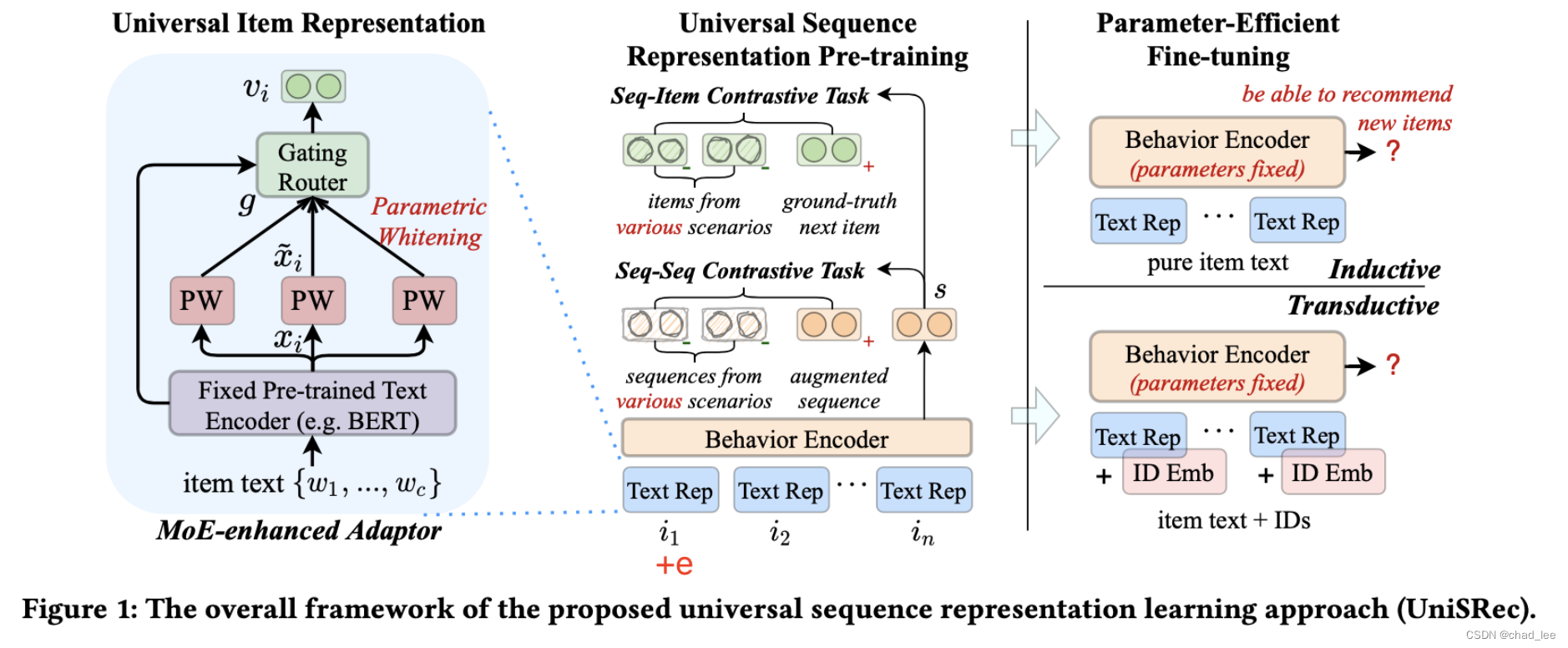
Input
What the user has clicked item In chronological order s = { i 1 , i 2 , … , i n } s=\left\{i_{1}, i_{2}, \ldots, i_{n}\right\} s={ i1,i2,…,in}, Each of these products i All correspond to a id And a descriptive text ( Such as product description 、 Title or brand ). goods i The description text of can be formalized as t i = { w 1 , w 2 , … , w c } t_{i}=\left\{w_{1}, w_{2}, \ldots, w_{c}\right\} ti={ w1,w2,…,wc}, among w j w_j wj Is a shared vocabulary , c Represents the longest length of the product text ( truncation ).
- The product sequence here is anonymous , Don't record user id
- One user on multiple platforms 、 Multiple domains will generate interaction sequences , Every domain The sequence of is recorded separately , Mixed together as sequence data
- goods ID Not as UniSRec The input of , Because Commodities ID Span domain It doesn't make sense .
- therefore UniSRec The purpose of can have Modeling generic sequence representation The ability of , In this way, we can realize the utilization Microblogging The sequence data of TaoBao recommend
General commodity text representation
Commodity text coding based on pre training language model
Enter the product text BERT, use [CLS] As a sequence representation :
x i = BERT ( [ [ C L S ] ; w 1 , … , w c ] ) \boldsymbol{x}_{i}=\operatorname{BERT}\left(\left[[\mathrm{CLS}] ; w_{1}, \ldots, w_{c}\right]\right) xi=BERT([[CLS];w1,…,wc])
x i ∈ R d W \boldsymbol{x}_{i} \in \mathbb{R}^{d_{W}} xi∈RdW yes [CLS] Output . Even though
Semantic Transformation via Parametric Whitening
stay NLP There are many studies in the field that BERT The generated representation space is non smooth and anisotropic , The specific performance is BERT The output vector has a poor effect in calculating the unsupervised similarity , One improvement measure is to put BERT The output vector of becomes Gaussian distribution , That is, let all vectors be converted to the mean value of 0 And the covariance is the vector of the identity matrix .
( It's easy to understand , stay BERT There is no explicit pairwise The optimization of the Alignment and Uniformity)
This article does not use the pre calculated mean and variance to whiten , In order to better generalize in the unknown field , Will be b and W Set as a learnable parameter :
x ~ i = ( x i − b ) ⋅ W 1 \widetilde{\boldsymbol{x}}_{i}=\left(\boldsymbol{x}_{i}-\boldsymbol{b}\right) \cdot \boldsymbol{W}_{1} xi=(xi−b)⋅W1
Is to project into another semantic space .
Domain Fusion and Adaptation via MoE-enhanced Adaptor
Because there is often a large semantic gap between different domains , Therefore, when learning the general commodity representation, we should consider how to migrate and integrate the information of different domains . for instance ,Food The high-frequency words of the domain are natural, sweet, fresh etc. , and Movies The domain is war, love, story etc. . If you directly connect multiple BERT The original output of is projected into the same semantic space , May exist bias, Unable to adapt to the new recommended scenario .
So use a hybrid expert architecture (mixture-of-expert, MoE) Learn the whitening representation of multiple parameters for each commodity , And adaptively integrate into a general commodity representation . introduce G Parameter whitening network as expert, And parameterized routing module :( There are experts, there are routes )
v i = ∑ k = 1 G g k ⋅ x ~ i ( k ) \boldsymbol{v}_{i}=\sum_{k=1}^{G} g_{k} \cdot \widetilde{\boldsymbol{x}}_{i}^{(k)} vi=k=1∑Ggk⋅xi(k)
among x ~ i ( k ) \widetilde{\boldsymbol{x}}_{i}^{(k)} xi(k) It's No k The output of a parameter whitening network , g k g_k gk It is the corresponding fusion weight generated by the gateway routing module , Specific calculation method :
g = Softmax ( x i ⋅ W 2 + δ ) δ = Norm ( ) ⋅ Softplus ( x i ⋅ W 3 ) \begin{aligned} &\boldsymbol{g}=\operatorname{Softmax}\left(\boldsymbol{x}_{i} \cdot \boldsymbol{W}_{2}+\boldsymbol{\delta}\right) \\ &\boldsymbol{\delta}=\operatorname{Norm}() \cdot \operatorname{Softplus}\left(\boldsymbol{x}_{i} \cdot \boldsymbol{W}_{3}\right) \end{aligned} g=Softmax(xi⋅W2+δ)δ=Norm()⋅Softplus(xi⋅W3)
Use BERT Raw output x i x_i xi As the input of the routing module ,W Are learnable parameters .Norm() Generate random Gaussian noise , in order to experts Load balancing between .
- The multi parameter whitening network is similar to MHA、 Multikernel convolution
- such MoE Architecture is conducive to domain adaptation and integration
- Inserting parameters here is conducive to subsequent fine-tuning
Universal sequence representation
Now I have got one embedding Make up the sequence , The design model architecture needs to consider that the same sequence model can be used to model commodities in different recommended scenarios . Considering the difference domain It usually corresponds to different user behavior patterns , Simple and direct pooling Methods may lead to seesaw phenomenon 、 Conflict .
Based on this motivation Two pre training tasks based on comparative learning are proposed .
First, go through multiple layers Transformer:
f j 0 = v i + p j F l + 1 = FFN ( MHAttn ( F l ) ) \begin{gathered} \boldsymbol{f}_{j}^{0}=\boldsymbol{v}_{i}+\boldsymbol{p}_{j} \\ \boldsymbol{F}^{l+1}=\operatorname{FFN}\left(\operatorname{MHAttn}\left(\boldsymbol{F}^{l}\right)\right) \end{gathered} fj0=vi+pjFl+1=FFN(MHAttn(Fl))
The output of the last position of the last layer is the representation of the whole sequence f n L f_{n}^{L} fnL, It is also the following s s s
Sequence - Commodity comparison task
Given sequence , Predict the next moment commodity ( Example ), The negative example is in-batch As a negative example , Enhance the fusion and adaptation of common representations of different domains :
ℓ S − I = − ∑ j = 1 B log exp ( s j ⋅ v j / τ ) ∑ j ′ = 1 B exp ( s j ⋅ v j ′ / τ ) \ell_{S-I}=-\sum_{j=1}^{B} \log \frac{\exp \left(\boldsymbol{s}_{j} \cdot \boldsymbol{v}_{j} / \tau\right)}{\sum_{j^{\prime}=1}^{B} \exp \left(\boldsymbol{s}_{j} \cdot \boldsymbol{v}_{j^{\prime}} / \tau\right)} ℓS−I=−j=1∑Blog∑j′=1Bexp(sj⋅vj′/τ)exp(sj⋅vj/τ)
Sequence - Sequence comparison task
For a product series , Random drop Words in the product or product text , Get a positive example of the sequence , Then the negative example is in-batch Other sequences of other domains of :
ℓ S − S = − ∑ j = 1 B log exp ( s j ⋅ s ~ j / τ ) ∑ j ′ = 1 B exp ( s j ⋅ s j ′ / τ ) \ell_{S-S}=-\sum_{j=1}^{B} \log \frac{\exp \left(\boldsymbol{s}_{j} \cdot \tilde{\boldsymbol{s}}_{j} / \tau\right)}{\sum_{j^{\prime}=1}^{B} \exp \left(\boldsymbol{s}_{j} \cdot \boldsymbol{s}_{j^{\prime}} / \tau\right)} ℓS−S=−j=1∑Blog∑j′=1Bexp(sj⋅sj′/τ)exp(sj⋅s~j/τ)
Two loss Pre training together :
L P T = ℓ S − I + λ ⋅ ℓ S − S \mathcal{L}_{\mathrm{PT}}=\ell_{S-I}+\lambda \cdot \ell_{S-S} LPT=ℓS−I+λ⋅ℓS−S
fine-tuning
When fine tuning, put all Transformer encoder fix(PLM Is originally fixed Of ), Just fine tune MoE The parameters of that piece , It is using MoE Let the pre training model quickly adapt to new fields 、 The fusion .
According to the products in the new recommendation scenario id Is it available , Set two fine tuning settings :
Inductive:
For the frequent emergence of new products , goods ID No dice , Or use the product text as the general expression of new products , Predict according to the following probability :
P I ( i t + 1 ∣ s ) = Softmax ( s ⋅ v i t + 1 ) P_{I}\left(i_{t+1} \mid s\right)=\operatorname{Softmax}\left(\boldsymbol{s} \cdot \boldsymbol{v}_{i_{t+1}}\right) PI(it+1∣s)=Softmax(s⋅vit+1)
Transductive:
For the scenario that almost all products appear in the training set ( No, OOV), We can also learn about commodities at the same time ID Express . General text representation can be simply combined with ID Indicates addition and prediction :
P T ( i t + 1 ∣ s ) = Softmax ( s ~ ⋅ ( v i t + 1 + e i t + 1 ) ) P_{T}\left(i_{t+1} \mid s\right)=\operatorname{Softmax}\left(\tilde{\boldsymbol{s}} \cdot\left(\boldsymbol{v}_{i_{t+1}}+\boldsymbol{e}_{i_{t+1}}\right)\right) PT(it+1∣s)=Softmax(s~⋅(vit+1+eit+1))
It's in the second Encoder Add before e.
Both types of fine-tuning use cross entropy loss.
experiment
Data sets

stay Amazon Data sets 5 individual domain(Food, Home, CDs, Kindle, Movies) Pre training , Then the pre trained UniSRec Fine tune the downstream dataset .
Downstream datasets can be divided into two categories :
- Span domain: take Amazon Another in the dataset 5 A smaller domain(Pantry, Scientific, Instruments, Arts, Office) As new domain And test the UniSRec The effect of .
- Cross platform : A British e-commerce data set Online Retail Test as a new platform .
There is no overlap between users and products in the pre training dataset and the six downstream datasets
Experimental results
UnisRec Model structure and SASRec It's basically the same

边栏推荐
- 【GCN】《Adaptive Propagation Graph Convolutional Network》(TNNLS 2020)
- Chapter5 : Deep Learning and Computational Chemistry
- 程序的内存布局
- Mid 2022 review | latest progress of large model technology Lanzhou Technology
- Convolutional neural network model -- vgg-16 network structure and code implementation
- [ai4code final chapter] alphacode: competition level code generation with alphacode (deepmind)
- Convolutional neural network model -- googlenet network structure and code implementation
- Atcoder beginer contest 261 f / / tree array
- 业务可视化-让你的流程图'Run'起来(3.分支选择&跨语言分布式运行节点)
- Selenium use -- installation and testing
猜你喜欢

Eccv2022 | transclassp class level grab posture migration

R语言GLM广义线性模型:逻辑回归、泊松回归拟合小鼠临床试验数据(剂量和反应)示例和自测题

【GCN】《Adaptive Propagation Graph Convolutional Network》(TNNLS 2020)
![Detailed explanation of the training and prediction process of deep learning [taking lenet model and cifar10 data set as examples]](/img/70/2b5130be16d7699ef7db58d9065253.png)
Detailed explanation of the training and prediction process of deep learning [taking lenet model and cifar10 data set as examples]
Zero basic learning canoe panel (16) -- clock control/panel control/start stop control/tab control
Shell common script: judge whether the file of the remote host exists
![[review SSM framework series] 15 - Summary of SSM series blog posts [SSM kill]](/img/fb/6ca8e0eb57c76c515e2aae68e9e549.png)
[review SSM framework series] 15 - Summary of SSM series blog posts [SSM kill]
![[Video] Markov chain Monte Carlo method MCMC principle and R language implementation | data sharing](/img/20/bb43ab1bc447b519c3b1de0f809b31.png)
[Video] Markov chain Monte Carlo method MCMC principle and R language implementation | data sharing

Date and time function of MySQL function summary

yum和vim须掌握的常用操作
随机推荐
【CSDN 年终总结】结束与开始,一直在路上—— “1+1=王”的2021总结
The programmer's father made his own AI breast feeding detector to predict that the baby is hungry and not let the crying affect his wife's sleep
Lu MENGZHENG's "Fu of broken kiln"
Atcoder beginer contest 261e / / bitwise thinking + DP
零基础学习CANoe Panel(16)—— Clock Control/Panel Control/Start Stop Control/Tab Control
程序员成长第二十七篇:如何评估需求优先级?
[problem solving] ibatis.binding BindingException: Type interface xxDao is not known to the MapperRegistry.
The larger the convolution kernel, the stronger the performance? An interpretation of replknet model
好友让我看这段代码
AtCoder Beginner Contest 261E // 按位思考 + dp
Shell common script: judge whether the file of the remote host exists
Azure Devops(十四) 使用Azure的私有Nuget仓库
卷积核越大性能越强?一文解读RepLKNet模型
Zero basic learning canoe panel (15) -- CAPL output view
"Autobiography of Franklin" cultivation
Vim技巧:永远显示行号
卷积神经网络模型之——GoogLeNet网络结构与代码实现
Clickhouse notes 03-- grafana accesses Clickhouse
pytorch创建自己的Dataset加载数据集
B树和B+树