当前位置:网站首页>Bowen dry goods | Apache inlong uses Apache pulsar to create data warehousing
Bowen dry goods | Apache inlong uses Apache pulsar to create data warehousing
2022-06-11 09:17:00 【StreamNative】
About Apache Pulsar
Apache Pulsar yes Apache Software foundation top projects , It is the next generation cloud native distributed message flow platform , Set message 、 Storage 、 Lightweight functional calculation as a whole , Using the separation of computing and storage architecture design , Multi tenant support 、 Persistent storage 、 Multi machine room cross regional data replication , With strong consistency 、 High throughput 、 Low latency and high scalability streaming data storage features .
GitHub Address :http://github.com/apache/pulsar/
The article is transferred from the official account. :Apache InLong, Original address :https://mp.weixin.qq.com/s/WgVJzu77Hncu-okce8_qaQ
Apache InLong Increased by Apache Pulsar The ability to access data , Make the most of it Pulsar Different from others MQ Technical advantages of , For Finance 、 Billing and other data access scenarios with higher data quality requirements , Provide a complete solution . In the following , We'll show you how to use... Through a complete example Apache InLong Use Apache Pulsar Access to the data .

Apache InLong(incubating) brief introduction
Apache InLong( winged dragon https://inlong.apache.org) Tencent donated it to Apache Community one-stop data flow access service platform , Provide automatic 、 Security 、 Reliable and high-performance data transmission capability , Facilitate business construction and data analysis based on streaming 、 Modeling and Application .InLong Original project name TubeMQ , Focus on high performance 、 Low cost Message Queuing service . To further release TubeMQ The surrounding ecological capacity , We upgraded the project to InLong, Focus on building a one-stop data flow access service platform .Apache InLong With the internal use of Tencent TDBank As a prototype , Relying on trillion level data access and processing capacity , Integrated data collection 、 Converge 、 Storage 、 The whole process of sorting data processing , Easy to use 、 Flexible expansion 、 Stable and reliable .

Apache InLong Serve the whole life cycle from data acquisition to landing , Provide different processing modules according to different stages of data , It mainly includes :
•inlong-agent, Data collection Agent, Support reading general logs from specified directories or files 、 Report item by item . It will also be extended in the future DB collection 、HTTP Reporting and other capabilities ;•inlong-dataproxy, One is based on Flume-ng Of Proxy Components , Support data transmission blocking and falling disk retransmission , Have the ability to forward the received data to different sites MQ( Message queue ) The ability of ;•inlong-tubemq, Tencent's self-developed Message Queuing service , Focus on high-performance storage and transmission of massive data in big data scenarios , It has good core advantages in massive practice and low cost ;•inlong-sort, Yes, from different MQ The data consumed is analyzed ETL Handle , Then aggregate and write Hive、ClickHouse、Hbase、Iceberg And so on ;•inlong-manager, Provide complete data service management and control capability , Including metadata 、 Task flow 、 jurisdiction ,OpenAPI etc. ;•inlong-website, Front end page for managing data access , Simplify the whole InLong Use of control platform .
About Apache Pulsar

Apache Pulsar yes Pub/Sub Model message system , And the separation of storage and calculation is made in the design .Apache Pulsar An architecture that separates computing from storage , And the design of segmented storage is Apache Pulsar Compared with traditional partition based storage MQ Some advantages of :
•Broker and Bookie Are independent of each other , It is convenient to realize independent expansion and independent fault tolerance ;•Broker No state , It's easy to get on quickly 、 Offline , More suitable for cloud native scenes ;• Partitioned storage is not limited to the storage capacity of a single node ;• The partition data is evenly distributed .
Preparation conditions
• install Apache Pulsar, edition 2.6+• install Apache Hive, edition 2.3+
install InLong
Deploy InLong , have access to Docker Compose Implement one click deployment , It can also be deployed on ordinary machines through binary files .
•Docker Compose Deploy :https://inlong.apache.org/zh-CN/docs/next/deployment/docker• Deploy using the installation package :https://inlong.apache.org/zh-CN/docs/next/deployment/bare_metal
The difference in InLong TubeMQ, If you use Apache Pulsar, Need to be in Manager Components are configured during installation Pulsar Cluster information , The format is as follows :
# Pulsar admin URL
pulsar.adminUrl=http://127.0.0.1:8080,127.0.0.2:8080,127.0.0.3:8080
# Pulsar broker address
pulsar.serviceUrl=pulsar://127.0.0.1:6650,127.0.0.1:6650,127.0.0.1:6650
# Default tenant of Pulsar
pulsar.defaultTenant=publicCreate data access
Configure data flow Group Information

When creating data access , Data flow Group Optional message oriented middleware Pulsar, Others follow Pulsar Related configuration items also include :
•Queue module: The queue model , Parallel or sequential , When parallel is selected, you can set Topic The number of partitions , The order is a partition ;•Write quorum: Number of copies written to the message ;•Ack quorum: Confirm write Bookies The number of ;•retention time: Has been consumer The time when the confirmed message is saved ;•ttl: Expiration time of unacknowledged messages ;•retention size: Has been consumer The size of the confirmation message saved .
Configure data flow

When configuring the message source , The path to the data source in the file , Referable inlong-agent in File Agent Detailed guidelines for [1].
Configure data format

To configure Hive colony
preservation Hive flow , Click on “ Submit for approval ”.

Data access approval
Get into Approval management page , Click on My approval , Approve the access application submitted above , After the approval, it will be in Pulsar It is necessary for the cluster to create data flow synchronously Topic And subscriptions .
We can do it in Pulsar The cluster uses the command line tool to check Topic Whether to create successfully :

The configuration file Agent
In profile Agent when , You need to create files according to the directory specified when creating data access :
touch /data/test_file.txt;
Follow the data source format when creating the data flow , Write data to file ( More data can be written in format ):
echo -e "1|test\n2|test\n" >> /data/test_file.txt
Data landing inspection
Last , We log in Hive colony , adopt Hive Of SQL Command view test_stream Whether data has been successfully inserted into the table .
Troubleshoot problems
If the data is not written correctly Hive colony , You can check Dataproxy and Sort Whether relevant information is synchronized :
• Check Inlong-Dataproxy Of conf/topics.properties Whether the file corresponding to the data stream is correctly written in the folder Topic Information b_test_group/test_stream=persistent://public/b_test_group/test_stream• Check InLong Sort Monitoring ZooKeeper Whether the configuration information of the data stream is successfully pushed in :get /inlong_hive/dataflows/{{sink_id}}
Reference link
[1] File Agent Detailed guidelines for : https://inlong.apache.org/docs/next/modules/agent/file#file-agent-configuration
▼ Focus on 「Apache Pulsar」, Get more technical dry goods ▼
Join in Apache Pulsar Chinese communication group

This article is from WeChat official account. - ApachePulsar(ApachePulsar).
If there is any infringement , Please contact the [email protected] Delete .
Participation of this paper “OSC Source creation plan ”, You are welcome to join us , share .
边栏推荐
- [FAQ for novices on the road] about data visualization
- What problems can ERP system help enterprises deal with?
- Interview question 17.10 Main elements
- PD chip ga670-10 for OTG while charging
- 844. compare strings with backspace
- Sword finger offer 18 Delete the node of the linked list
- 445. 两数相加 II
- OpenCV CEO教你用OAK(五):基于OAK-D和DepthAI的反欺骗人脸识别系统
- 1400. construct K palindrome strings
- 剑指 Offer II 036. 后缀表达式
猜你喜欢

Machine learning notes - spatial transformer network using tensorflow

Kubelet error getting node help

openstack详解(二十四)——Neutron服务注册

Opencv oak-d-w wide angle camera test

Talk about reading the source code

Version mismatch between installed deeply lib and the required one by the script
kubelet Error getting node 问题求助

CUMT学习日记——ucosII理论解析—任哲版教材
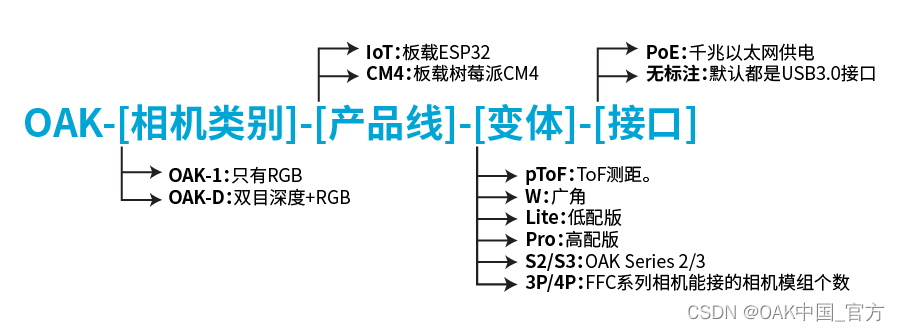
Comparison and introduction of OpenCV oak cameras

Complexity analysis of matrix inversion operation (complexity analysis of inverse matrix)
随机推荐
Award winning survey streamnational sponsored 2022 Apache pulsar user questionnaire
Do you know these advantages of ERP system?
Openstack explanation (XXIII) -- other configurations, database initialization and service startup of neutron
Comparison and introduction of OpenCV oak cameras
基于SIC32F911RET6设计的腕式血压计方案
206. reverse linked list
OpenCV OAK-D-W广角相机测试
Install jupyter in the specified environment
Openstack explanation (21) -- installation and configuration of neutron components
【软件】大企业ERP选型的方法
剑指 Offer 06. 从尾到头打印链表
机器学习笔记 - Kaggle大师Janio Martinez Bachmann的故事
Fabric.js 动态设置字号大小
Fabric.js 動態設置字號大小
20. valid brackets
86. 分隔链表
shell脚本之sed详解 (sed命令 , sed -e , sed s/ new / old / ... )
[ERP system] how much do you know about the professional and technical evaluation?
Fabric. JS dynamically set font size
[share] how do enterprises carry out implementation planning?