当前位置:网站首页>Redis6 data type and operation summary
Redis6 data type and operation summary
2022-07-05 13:39:00 【Do you know what a code monster is?】
Catalog
Geographical space (geospatial)
key operation
Add key value pair
set <key> <value>View all of the current library key
keys *Judge a certain key Whether there is
exists <key>see key Data type of
type <key>Delete specified key
del <key>according to value Select non blocking delete , Only will keys from keyspace Delete from metadata , The real deletion will be done asynchronously later
unlink <key>by key Set expiration time ( Time unit : second )
expire <key> 10See how many seconds are left to expire ,-1 Never expire ,-2 Indicates that it has expired
ttl <key>Switch database
select 15Check the... Of the current database key The number of
dbsizeEmpty the current library
flushdbEmpty all libraries
flushallcharacter string (String)
String yes Redis Basic data types ,Redis Middle string value At most 512M. It's binary safe , in other words Redis Of String Can contain any data , such as jpg Picture or serialized object .
Redis in ,String The data structure of is a simple dynamic string , Is a string that can be modified , The internal structure is similar to java Of ArrayList, Reduce the frequent allocation of memory by pre allocating redundant space .
Add key value pair ( same key To cover )
set <key> <value>Query the corresponding key value
get <key>Will be given value Append to the end of the original value , Return string length
append <key> <value>Get the length of the value
strlen <key>When key When there is no , Set up key Value
setnx <key> <value>take key Increase the value of the number stored in 1, Can only operate on numeric values , If it is empty , The new value added is 1, Returns the result value
incr <key>take key The number stored in minus 1, Can only operate on numeric values , If it is empty , The new value added is -1, Returns the result value
decr <key>take key Increase or decrease the number value stored in . Custom step size
incrby/decrby <key> < step >Set one or more... At the same time value
mset <key1> <value1> <key2> <value2> <key3> <value3>Set one or more... At the same time key-value Yes , If and only if all given key It doesn't exist
msetnx <key1> <value1> <key2> <value2> <key3> <value3>Get one or more at the same time value
mget <key1> <key2> <key3>Get content in scope
getrange <key> < The starting position > < End position >use value overwrite key String value stored
setrange <key> < The starting position > <value>While setting the key value , Set expiration time ( Company : second )
setex <key> < Expiration time > <value>Set the new value and get the old value
getset <key> <value>list (List)
Redis The middle list is a simple string list , Sort by insertion order , You can add an element to the head of the list ( On the left ) Or tail ( On the right ). Its bottom layer is actually a two-way linked list , High performance on both ends , The performance of the nodes in the middle of the index subscript operation will be poor .
First, in the case of fewer list elements will use a block of continuous memory storage , This structure is ziplist, That is, compressed list . It stores all the elements next to each other , Allocated is a continuous block of memory . When there is a large amount of data, it will be changed to quicklist. Because the use of a two-way list , Two extra pointers will be used prev、next, This will cause great spatial redundancy , Will be multiple ziplist Use two-way pointer string to use , Fast insertion and deletion performance , There will not be too much space redundancy .
From the left / Insert one or more values... To the right
lpush/rpush <key> <value1> <value2> <value3>From the left / Spit out a value on the right ,( It's like getting out of the stack )
After all elements are out of the stack, use ttl Look at the expiration time of the key , by -2, namely “ Value at key at , The value of the light key ”.
lpop/rpop <key>from key1 Spit a value on the right side of the list , insert key2 To the left of the list
If key2 non-existent , Automatically create .
rpoplpush <key1> <key2>Get elements according to index subscript ( From left to right )
lrange <key> < Start subscript > < End subscript >Get elements according to index subscript ( From left to right )
lindex <key> <value>Get list length
llen <key>stay value In front of / Insert... At the back newvalue Insert value
linsert <key> before/after <value> <newValue>Delete from the left n individual value( From left to right )
lrem <key> <value>Will list key Subscript to be index Replace the value of with value
lset <key> <index> <value>aggregate (Set)
Set The data structure is a dictionary , Dictionaries are implemented with hash tables .
Set The functions and List List like functions , What's special is Set Yes. Automatic weight removal Of , When you need to store a list of data , You don't want duplicate data ,Set Is a good choice , also Set Provides a way to determine whether a member is in a Set Important interfaces within a collection , This is also List What cannot be provided .
Redis Of Set yes String Unordered collection of type . The bottom of it is actually a value by null Of hash surface , So add the , Delete , The complexity of searching is O(1). An algorithm , As data increases , The length of execution , If it is O(1), Data increase , The time to find the data remains the same .
Put one or more member Elements are added to the collection key in , What already exists member Elements will be ignored
sadd <key> <value1> <value2> <value3>Take all the values of the set
smembers <key>Judgment set key Whether it contains the value value , There is a return 1, No return 0
sismember <key> <value>Returns the number of elements in the collection
scard <key>Delete elements from the collection
srem <key> <value1> <value2>Spit a value out of the set at random
spop <key>Randomly take... From the set n It's worth , Will not be removed from the collection
srandmember <key> <n>Move a value in a set from one set to another
smove <key1> <key2> <value>Returns the intersection element of two sets
sinter <key1> <key2>Returns the union element of two sets
sunion <key1> <key2>Returns the difference set element of two sets (key1 There is ,key2 There is no )
sdiff <key1> <key2>Hash (Hash)
Hash There are two kinds of data structures corresponding to types :ziplist( Compressed list ),hashtable( Hashtable ). When field-value When the length is short and the number is small , Use ziplist, Otherwise use hashtable.
Redis hash It's a String Type of field and value Mapping table ,hash Ideal for storing objects .
to key In the collection field Key assignment value
hset <key> <field> <value>Batch settings hash Value
hmset <key1> <value1> <key2> <value2> <key3> <value3>Hash table key In the domain field Is set to value , If and only if domain field non-existent
hsetnx <key> <field> <value>from key aggregate field Take out value
hget <key> <field>Look at the hash table key in , Given domain field Whether there is
hexists <key> <field>List the hash All of the collection field
hkeys <key>List the hash All of the collection value
hvals <key>Hash table key In the domain field Plus the increment ( Value must be numeric ), Minus is plus a negative number
hincrby <key> <field> <increment>Ordered set (Zset)
Redis Ordered set zset With the common set set Very similar , Is a collection of strings without repeating elements .
zset yes Redis A very special data structure provided , On the one hand, it is equivalent to Java Data structure of Map<String, Double>, You can give each element value Give a weight score, On the other hand, it is similar to TreeSet, Internal elements are weighted score Sort , You can get the rank of each element , You can also use score To get a list of elements .
zset The bottom layer uses two data structures
hash,hash The role of is to associate elements value And weight score, Guarantee elements value Uniqueness , You can use the element value Find the appropriate score value
Skip list , The purpose of jump tables is to give elements value Sort , according to score Scope get element list for
Put one or more elements and their score Value added to ordered set key among
zadd <key> <score1> <value1> <score2> <value2>Return to ordered set key in , The subscript is min、max Between the elements
zrange <key> <min> <max>If you add withscores, Then the score will be displayed together
zrange <key> <min> <max> withscoresReturn to ordered set key in , all score The value is between min and max Between ( Including equal to min or max ) Members of , Press score Value increment ( From small to large ) Order
zrangebyscore <key> <min> <max> Sort from large to small
zrevrangebyscore <key> <max> <min> For the elements score Plus the increment
zincrby <key> <increment> <value>Delete... Under this collection , The element that specifies the value
zrem <key> <value>Count the set , The number of elements in the fraction range
zcount <key> <min> <max>Returns the rank of the value in the collection , from 0 Start
zrank <key> <value>Bitmap (bitmap)
Bitmap (bitmap) It also belongs to string data type . Each string consists of multiple bytes , Each byte is again composed of 8 individual Bit A composition . The bitmap structure uses “ position ” To realize the storage of , It sets the bit to 0 or 1 To achieve the purpose of data access , This greatly increases value Storage quantity , Its storage limit is 2^32.
Set or clear the value on a bit , The return value is the value stored in the original bit
key In the initial state, all bits are 0,offset Represents the offset , from 0 Start .
setbit <key> <offset> <value>Get the value of a bit
When the offset offset The length of the string is larger than , Or when key When there is no , return 0.
getbit <key> <offset>Statistics refers to the positioning interval , The value is 1 The number of
bitcount <key>You can also specify start and end Parameters , Count on bytes in a specific range .
bitcount <key> start endIntersection of bitmaps 、 Combine 、 Not 、 Exclusive or operation
and Find the intersection 、or Union 、not Non operational 、xor Exclusive or operation , The results are stored in destkey in . For multiple key To operate .
bitop and/or/not/xor <destkey> <key1> <key2> <key3>HyperLogLog
stay Redis The content occupied by each key in is 12K, The theoretical storage is close to 2^64 It's worth , This is an algorithm based on cardinality estimation , We can only estimate the cardinality more accurately , A small amount of fixed memory can be used to store and identify unique elements in the collection . But the base of this estimate is not necessarily accurate , It's one with 0.81% Approximate value of standard error .
Any number of elements are added to the specified HyperLogLog Inside
pfadd <key> <element1> <element2>Calculation HyperLogLog The approximate cardinality of
Multiple... Can be calculated HyperLogLog, Just add... At the end key that will do
pfcount <key>Merge one or more HyperLogLog The result of is stored in another HyperLogLog in
destkey Store the merged results
pfmerge <destkey> <key1> <key2>Geographical space (geospatial)
This type is the two-dimensional coordinates of the element , On the map is latitude and longitude . This type provides the setting of longitude and latitude 、 Inquire about 、 Range queries 、 Distance inquiry 、 Longitude and latitude Hash And so on .
Add geographic location information
geoadd <key> < longitude > < latitude > <name>Get the corresponding geographic location information
geopos <key> <name>Get the straight-line distance between two positions
geodist <key> <name1> <name2> The distance unit can be added after the command , rice :m, km :km, miles :mi, feet :ft, The default is meters
geodist <key> <name1> <name2> kmCentered on a given latitude and longitude , Find the elements in a certain radius
georadius <key> < longitude > < latitude > < distance > < Distance units >边栏推荐
- Nantong online communication group
- [public class preview]: basis and practice of video quality evaluation
- Multi person cooperation project to see how many lines of code each person has written
- [深度学习论文笔记]使用多模态MR成像分割脑肿瘤的HNF-Netv2
- Clock cycle
- 面试官灵魂拷问:为什么代码规范要求 SQL 语句不要过多的 join?
- APICloud Studio3 WiFi真机同步和WiFi真机预览使用说明
- mysql econnreset_ Nodejs socket error handling error: read econnreset
- Datapipeline was selected into the 2022 digital intelligence atlas and database development report of China Academy of communications and communications
- 网络安全-HSRP协议
猜你喜欢
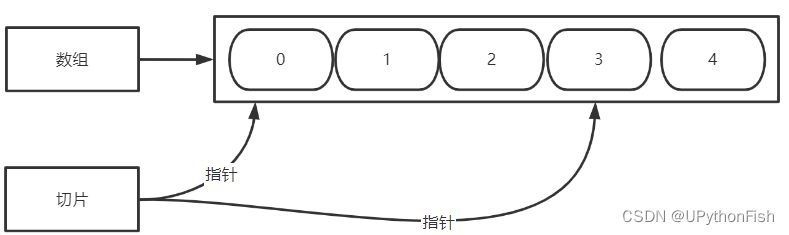
Go array and slice

Backup and restore of Android local SQLite database

数据泄露怎么办?'华生·K'7招消灭安全威胁
C object storage

MySQL --- 数据库查询 - 排序查询、分页查询
Don't know these four caching modes, dare you say you understand caching?

“百度杯”CTF比赛 九月场,Web:Upload
![[深度学习论文笔记]TransBTSV2: Wider Instead of Deeper Transformer for Medical Image Segmentation](/img/70/6de0346df8527af6c88db1ff89947b.png)
[深度学习论文笔记]TransBTSV2: Wider Instead of Deeper Transformer for Medical Image Segmentation
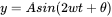
Flutter draws animation effects of wave movement, curves and line graphs
TortoiseSVN使用情形、安装与使用
随机推荐
Datapipeline was selected into the 2022 digital intelligence atlas and database development report of China Academy of communications and communications
Address book (linked list implementation)
CAN和CAN FD
With 4 years of working experience, you can't tell five ways of communication between multithreads. Dare you believe it?
多人合作项目查看每个人写了多少行代码
Wonderful express | Tencent cloud database June issue
Godson 2nd generation burn PMON and reload system
Apicloud studio3 API management and debugging tutorial
Jasypt configuration file encryption | quick start | actual combat
leetcode 10. Regular Expression Matching 正则表达式匹配 (困难)
Talking about fake demand from takeout order
精彩速递|腾讯云数据库6月刊
Interviewer soul torture: why does the code specification require SQL statements not to have too many joins?
Could not set property ‘id‘ of ‘class XX‘ with value ‘XX‘ argument type mismatch 解决办法
mysql econnreset_ Nodejs socket error handling error: read econnreset
The "Baidu Cup" CTF competition was held in February 2017, Web: explosion-2
这18个网站能让你的页面背景炫酷起来
Data Lake (VII): Iceberg concept and review what is a data Lake
A detailed explanation of ASCII code, Unicode and UTF-8
[深度学习论文笔记]使用多模态MR成像分割脑肿瘤的HNF-Netv2