当前位置:网站首页>第一个scrapy爬虫
第一个scrapy爬虫
2022-07-25 11:23:00 【托塔天王李】
scrapy目录结构如下
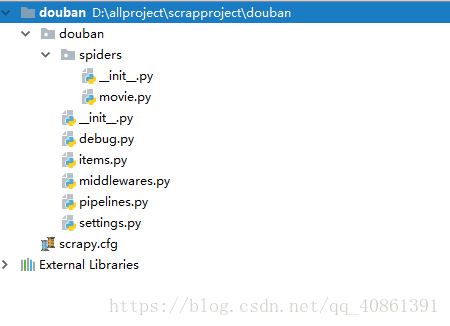
我们要爬取的是读书网里面的书名,作者,和对书的描写
首先我们要定义爬取数据的模型,在items.py文件中
import scrapy
class MoveItem(scrapy.Item): # 定义爬取的数据的模型 title = scrapy.Field() auth = scrapy.Field() desc = scrapy.Field() 主要的还是spiders目录下的move.py文件
import scrapy
from douban.items import MoveItem
class MovieSpider(scrapy.Spider):
# 表示蜘蛛的名字,每个蜘蛛的名字必须是唯一的
name = 'movie'
# 表示过滤爬取的域名
allwed_domians = ['dushu.com']
# 表示最初要爬取的url
start_urls = ['https://www.dushu.com/book/1188.html']
def parse(self,response):
li_list = response.xpath('/html/body/div[6]/div/div[2]/div[2]/ul/li')
for li in li_list:
item = MoveItem()
item['title'] = li.xpath('div/h3/a/text()').extract_first()
item['auth'] = li.xpath('div/p[1]/a/text()').extract_first()
item['desc'] = li.xpath('div/p[2]/text()').extract_first()
# 生成器
yield item
href_list = response.xpath('/html/body/div[6]/div/div[2]/div[3]/div/a/@href').extract()
for href in href_list:
# 把在页面上爬取的url补全
url = response.urljoin(href)
# 一个生成器,response的里面链接,再进行子request,不断执行parse,是个递归。
yield scrapy.Request(url=url,callback=self.parse)
想要持久化数据只有把数据保存起来:在settings.py文件里设置 
在pipelines.py文件里:
import pymongo
class DoubanPipeline(object):
def __init__(self):
self.mongo_client = pymongo.MongoClient('mongodb://39.108.188.19:27017')
def process_item(self, item, spider):
db = self.mongo_client.data
message = db.messages
message.insert(dict(item))
return item边栏推荐
- Figure neural network for recommending system problems (imp-gcn, lr-gcn)
- 【Debias】Model-Agnostic Counterfactual Reasoning for Eliminating Popularity Bias in RS(KDD‘21)
- Hystrix使用
- [high concurrency] a lock faster than read-write lock in high concurrency scenarios. I'm completely convinced after reading it!! (recommended Collection)
- Brpc source code analysis (I) -- the main process of RPC service addition and server startup
- Sword finger offer 22. the penultimate node in the linked list
- 【GCN】《Adaptive Propagation Graph Convolutional Network》(TNNLS 2020)
- Intelligent information retrieval (overview of intelligent information retrieval)
- NLP的基本概念1
- selenium使用———xpath和模拟输入和模拟点击协作
猜你喜欢

From cloud native to intelligent, in-depth interpretation of the industry's first "best practice map of live video technology"

Location analysis of recording an online deadlock

Client open download, welcome to try

Atomic atomic class

LeetCode第303场周赛(20220724)

Application of comparative learning (lcgnn, videomoco, graphcl, XMC GaN)

【GCN-RS】Learning Explicit User Interest Boundary for Recommendation (WWW‘22)

OSPF comprehensive experiment

Meta-learning(元学习与少样本学习)

GPT plus money (OpenAI CLIP,DALL-E)
随机推荐
Brpc source code analysis (IV) -- bthread mechanism
银行理财子公司蓄力布局A股;现金管理类理财产品整改加速
GPT plus money (OpenAI CLIP,DALL-E)
【GCN-RS】Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for RS (SIGIR‘22)
I advise those students who have just joined the work: if you want to enter the big factory, you must master these concurrent programming knowledge! Complete learning route!! (recommended Collection)
【AI4Code】《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》 EMNLP 2020
Brpc source code analysis (VII) -- worker bthread scheduling based on parkinglot
OSPF comprehensive experiment
嵌套事务 UnexpectedRollbackException 分析与事务传播策略
【高并发】高并发场景下一种比读写锁更快的锁,看完我彻底折服了!!(建议收藏)
How to solve the problem of the error reported by the Flink SQL client when connecting to MySQL?
【对比学习】Understanding the Behaviour of Contrastive Loss (CVPR‘21)
Innovation and breakthrough! AsiaInfo technology helped a province of China Mobile complete the independent and controllable transformation of its core accounting database
【Debias】Model-Agnostic Counterfactual Reasoning for Eliminating Popularity Bias in RS(KDD‘21)
Qin long, a technical expert of Alibaba cloud: a prerequisite for reliability assurance - how to carry out chaos engineering on the cloud
Brpc source code analysis (V) -- detailed explanation of basic resource pool
Transformer variants (routing transformer, linformer, big bird)
氢能创业大赛 | 国家能源局科技司副司长刘亚芳:构建高质量创新体系是我国氢能产业发展的核心
Intelligent information retrieval(智能信息检索综述)
The bank's wealth management subsidiary accumulates power to distribute a shares; The rectification of cash management financial products was accelerated