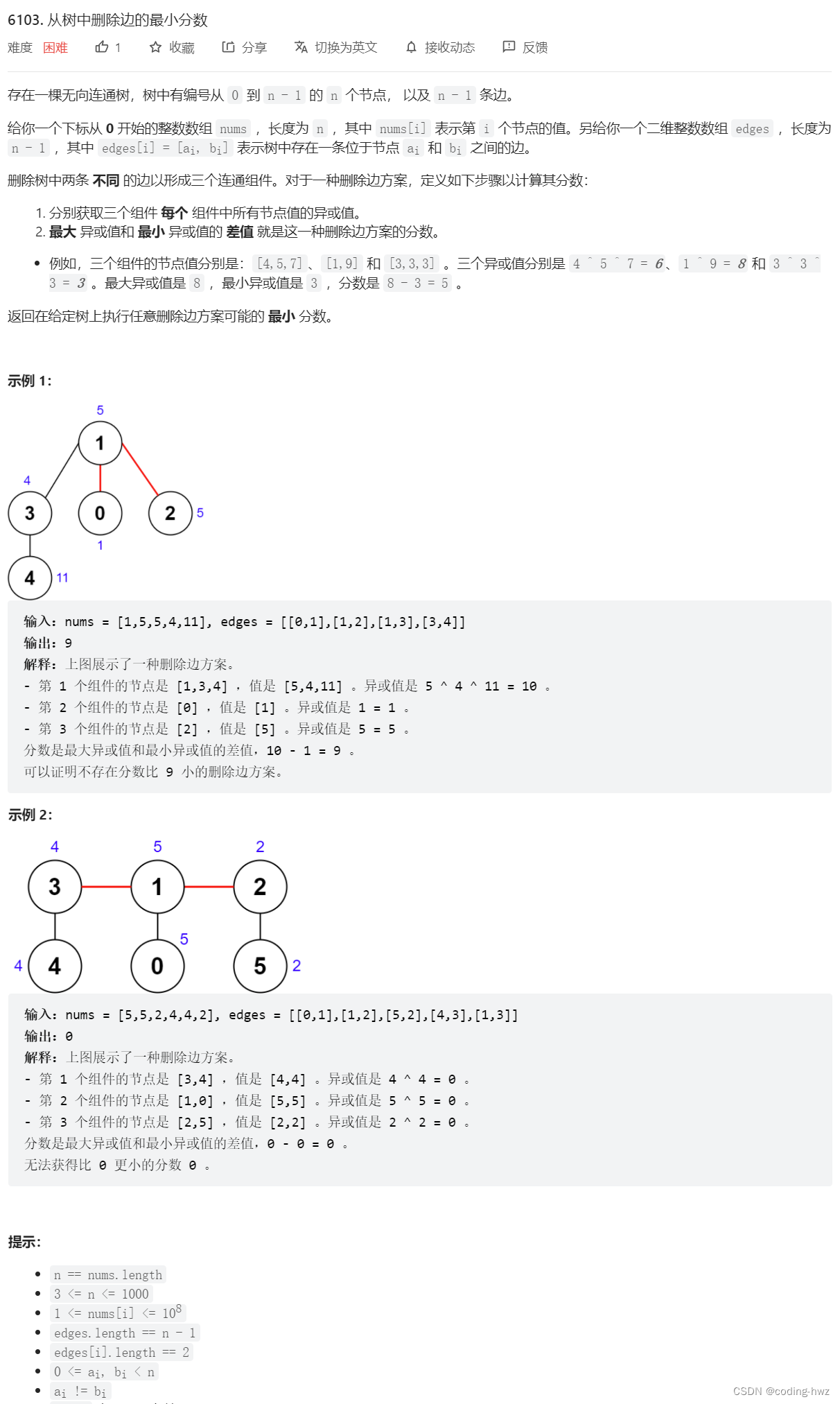
当前位置:网站首页>[data mining] task 5: k-means/dbscan clustering: double square
[data mining] task 5: k-means/dbscan clustering: double square
2022-07-03 01:34:00 【zstar-_】
requirement
Program the following data clustering : Double square
Import library and global settings
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans, DBSCAN
plt.rcParams['font.sans-serif'] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
Generate double-layer square data
a = np.arange(1, 10, 0.01)
b = np.arange(3, 8, 0.01)
w = np.zeros((5600, 3))
# Outer square dot
w[:900, 0] = a
w[:900, 1] = 1
w[900:1800, 0] = 1
w[900:1800, 1] = a
w[1800:2700, 0] = a
w[1800:2700, 1] = 10
w[2700:3600, 0] = 10
w[2700:3600, 1] = a
# Inner square dot
w[3600:4100, 0] = b
w[3600:4100, 1] = 3
w[4100:4600, 0] = 3
w[4100:4600, 1] = b
w[4600:5100, 0] = b
w[4600:5100, 1] = 8
w[5100:, 0] = 8
w[5100:, 1] = b
w[3600:, 2] = 1
K-Means clustering
Parameter description
n_clusters: Number of clusters
random_state: Randomness of control parameters
cluster = KMeans(n_clusters=2, random_state=0)
y = cluster.fit_predict(w)
colors = ['black', 'red']
plt.figure(figsize=(15, 15))
plt.subplot(2, 2, 1)
for i in range(len(w)):
plt.scatter(w[i][0], w[i][1], color=colors[int(w[i][2])])
plt.title(" Raw data ")
plt.subplot(2, 2, 2)
for i in range(len(y)):
plt.scatter(w[i][0], w[i][1], color=colors[y[i]])
plt.title(" After clustering data ")

DBSCAN clustering
Parameter description
eps:ϵ- Distance threshold of neighborhood , The distance from the sample exceeds ϵ The sample point of is not in ϵ- In the neighborhood , The default value is 0.5.
min_samples: The minimum number of points to form a high-density area . As the core point, the neighborhood ( That is, take it as the center of the circle ,eps Is a circle of radius , Including points on the circle ) Minimum number of samples in ( Including the point itself ).
if y=-1, Is the outlier .
because DBSCAN The generated category is uncertain , Therefore, define a function to filter out the most appropriate parameters that meet the specified category .
The appropriate criterion is to minimize the number of outliers .
# Filter parameters
def search_best_parameter(N_clusters, X):
min_outliners = 999
best_eps = 0
best_min_samples = 0
# Iterating different eps value
for eps in np.arange(0.001, 1, 0.05):
# Iterating different min_samples value
for min_samples in range(2, 10):
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
# Model fitting
y = dbscan.fit_predict(X)
# Count the number of clusters under each parameter combination (-1 Indicates an outlier )
if len(np.argwhere(y == -1)) == 0:
n_clusters = len(np.unique(y))
else:
n_clusters = len(np.unique(y)) - 1
# Number of outliers
outliners = len([i for i in y if i == -1])
if outliners < min_outliners and n_clusters == N_clusters:
min_outliners = outliners
best_eps = eps
best_min_samples = min_samples
return best_eps, best_min_samples
eps, min_samples = search_best_parameter(2, w)
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
y = dbscan.fit_predict(w)
colors = ['black', 'red']
plt.figure(figsize=(15, 15))
plt.subplot(2, 2, 1)
for i in range(len(w)):
plt.scatter(w[i][0], w[i][1], color=colors[int(w[i][2])])
plt.title(" Raw data ")
plt.subplot(2, 2, 2)
for i in range(len(y)):
plt.scatter(w[i][0], w[i][1], color=colors[y[i]])
plt.title(" After clustering data ")
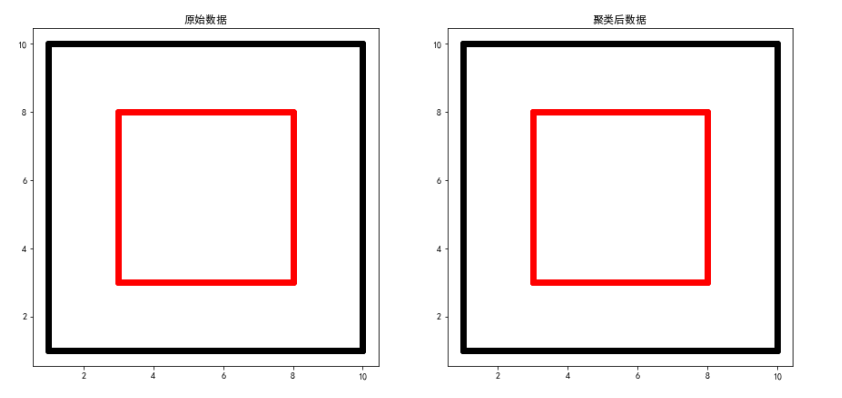
summary
For double-layer square data ,K-Means Clustering method is not suitable for clustering , And use DBSCAN This method can achieve better results .
边栏推荐
- 测试右移:线上质量监控 ELK 实战
- [FPGA tutorial case 5] ROM design and Implementation Based on vivado core
- MySQL --- 数据库查询 - 条件查询
- Button wizard play strange learning - automatic return to the city route judgment
- [Cao gongzatan] after working in goose factory for a year in 2021, some of my insights
- Steps to obtain SSL certificate private key private key file
- Why is it not recommended to use BeanUtils in production?
- 数学知识:能被整除的数—容斥原理
- After reading this article, I will teach you to play with the penetration test target vulnhub - drivetingblues-9
- tp6快速安装使用MongoDB实现增删改查
猜你喜欢

JDBC courses

MySQL basics 03 introduction to MySQL types
MySQL foundation 05 DML language
Why can't the start method be called repeatedly? But the run method can?
Basic remote connection tool xshell

C application interface development foundation - form control (2) - MDI form
Leetcode 6103 - minimum fraction to delete an edge from the tree
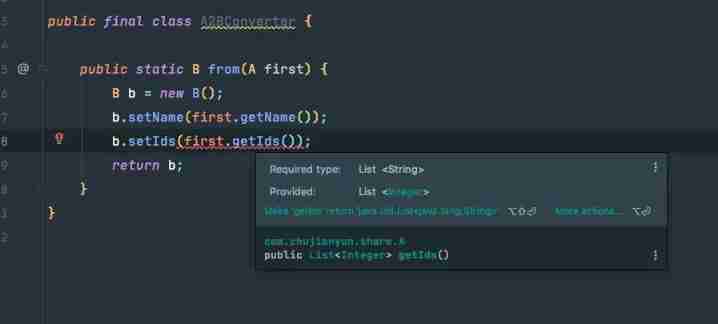
Why is it not recommended to use BeanUtils in production?
![[fh-gfsk] fh-gfsk signal analysis and blind demodulation research](/img/8a/8ca80f51a03341c982d52980c54b01.png)
[fh-gfsk] fh-gfsk signal analysis and blind demodulation research

Scheme and practice of cold and hot separation of massive data
随机推荐
leetcode刷题_两数之和 II - 输入有序数组
MySQL basics 03 introduction to MySQL types
C application interface development foundation - form control (4) - selection control
[system analyst's road] Chapter V double disk software engineering (development model development method)
Three core issues of concurrent programming - "deep understanding of high concurrent programming"
Meituan dynamic thread pool practice ideas, open source
Wireshark data analysis and forensics a.pacapng
Key wizard hit strange learning - automatic path finding back to hit strange points
数学知识:Nim游戏—博弈论
[机缘参悟-36]:鬼谷子-飞箝篇 - 面对捧杀与诱饵的防范之道
The difference between tail -f, tail -f and tail
【C语言】指针与数组笔试题详解
Work experience of a hard pressed programmer
Why can't the start method be called repeatedly? But the run method can?
Test shift right: Elk practice of online quality monitoring
[Cao gongzatan] after working in goose factory for a year in 2021, some of my insights
Swiftui component Encyclopedia: using scenekit and swiftui to build interactive 3D pie charts (tutorial with source code)
Do not log in or log in to solve the problem that the Oracle database account is locked.
Expérience de recherche d'emploi d'un programmeur difficile
QTableWidget懒加载剩内存,不卡!