当前位置:网站首页>Redis -- cache breakdown, penetration, avalanche
Redis -- cache breakdown, penetration, avalanche
2022-07-02 06:47:00 【Qihai Jianren】
Redis Cache breakdown of 、 through 、 An avalanche , These concepts are the issues that need to be considered when designing large flow interfaces , It's also often asked in interviews Redis Relevant basic knowledge , This article reviews these concepts , Make a summary ;
Everybody knows , One of the bottlenecks of computers is IO, In order to solve the problem of memory and disk speed mismatch , There's a cache ; Put some hot data ( Frequent visits 、 Data that will not be updated frequently ) In memory ( Such as Redis、 Local cache ), Use as you go , Thus reducing the interaction with the disk , Such as reducing the right DB Frequent query pressure , Avoid the database hanging up under a large number of requests ;
It should be noted that , Whether it is cache breakdown or penetration and avalanche , The conditions here all refer to Under the premise of high concurrency , Because the concurrency is not high, there is no need to design the cache ;
1. Cache penetration
Cache penetration means Query for data that doesn't exist at all , Neither the cache layer nor the persistence layer will hit ; Cause the user to request this data every time , You have to look it up in the database , Then return to empty ; for example :
1. Normal user requests , Due to abnormal business logic or dirty data , This leads to the need to query a cache that does not exist id, Such as expired activities id、 Goods that have been removed from the shelves id;
2. Malicious user requests , Forgery does not exist id Initiate request , Neither database nor cache exists ;
Cache penetration will cause nonexistent data to be queried in the persistence layer every request , Lost the use of cache to protect the persistence layer DB The meaning of ; If a malicious attacker keeps asking for data that doesn't exist in the system , It will result in a large number of requests falling on the database in a short time , Cause too much database pressure , Even the database system ;
Cache penetration diagram :
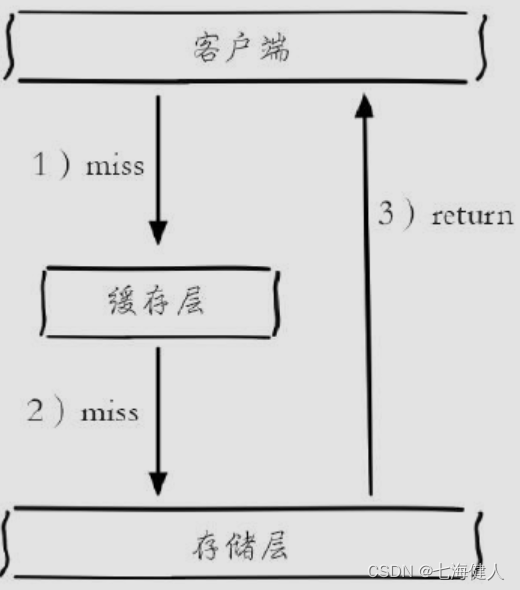
In daily work, for the sake of fault tolerance , If no data can be found from the persistence layer, it will not be written to the cache layer ( The optimization scheme is to write a null value to the cache or use The bloon filter To filter illegal request parameters );
Solution :
1.1 Boom filter intercept
Before accessing the cache , Will be effective keys Put it into the bron filter in advance , When receiving a request, first use the bloom filter to determine the current key There is no ( A certain probability of miscalculation ), If it is judged that it exists in the set ( Valid request , Such as commodities id>0) Then request cache and DB; The bloom filter can be used to retrieve whether an element is in a collection , Its advantage is that the space efficiency and query time are far more than the general algorithm , The disadvantage is that it has certain error recognition rate and deletion difficulty ;
About the bloon filter , You can refer to my article 《Redis—— The bloon filter 》;
Be careful : On the ground , We Bloan filters are rarely used to solve cache penetration problems ! Why? ?
In addition to the error rate and deletion difficulties , The bloon filter The deadliest problem yes : If the data in the database is updated , We expect Sync Update the bloom filter , But we can't do business , The update of Bloom filter cannot affect the normal business process , Therefore, it is asynchronous to update the bloom filter set ; And it and database are two data sources , Then there may be data inconsistency ; For some businesses , This " atypism " The situation is unacceptable !
for example : User purchase B Standing big member scene , After the payment is successful, a new 1 Member users , At this time, the system starts the asynchronous thread to synchronize the user to Bulong filtering ; But due to network anomalies , Synchronization failed ; And the user immediately jumps back to the member page after successful payment , At this time, the user's " Inquire about membership interests " Your request came , Because the bloom filter does not have this key The data of , So the request was rejected directly , Prompt the user " Not open members ", But this user has clearly become B Station member , His membership interest request was blocked ;—— therefore , The customer complaint is coming ,SQA I found you , Pull a double offer ...
Obviously , If such a normal user is intercepted , Some businesses are intolerable ; therefore , Bloom filter depends on the actual business scenario before deciding whether to use , It helps us solve the cache penetration problem , But at the same time, it introduces new problems ;
1.2 Caching empty objects
It uses a bloom filter , Although it can filter out many non-existent users id request , But in addition to increasing the complexity of the system , There are two problems :
1. The misjudgment rate of Bloom filter , Causes elements that are not in the collection to be released ;
2. If you add user information , You need to ensure that you can synchronize to the bloom filter in real time , Otherwise, there will be business problems ;
therefore , Usually , We rarely use Bloom filters to solve cache penetration problems ; Actually , There is another simpler solution , Cache null .
When cache misses , Query persistence layer is also empty , The returned empty object can be written to the cache , So next time you ask for the key Query directly from the cache and return empty objects , Requests don't fall into the persistence layer database ; To avoid storing too many empty objects , An expiration time is usually set for an empty object ;
The scheme of caching empty objects will have 2 A question :
(1)value by null/ An empty string does not mean that memory space is not occupied , Null values are cached , It means that there is more in the cache layer keys, Need more memory space , Therefore, a shorter expiration time is usually set for empty objects , Let it automatically remove ; For all that , In a short time , A large number of requests will still produce more null values keys, It will occupy a certain space within the expiration time ;
(2) The data of cache layer and storage layer will be inconsistent for a period of time , For example, the expiration time is set to 5 minute , If at this time DB newly added / Updated this data , Then the cache will appear as NULL and DB Layer has value ; Usually in DB Update the cache through asynchronous threads when updating , If it is a local cache, it can be broadcast through messages such as Redis The publish and subscribe model of ;
2. Cache breakdown
Cache breakdown , It means a key Very hot , Constantly carrying big concurrency , Large concurrent centralized access to this point , When this key At the moment of failure , Continuous large concurrency breaks through the cache , Direct request database , It's like cutting a hole in a barrier —— The cache used to carry high concurrency is " Punch through " 了 ;
Attention should be paid to the following two problems in the system :
- At present key It's a hot spot key( For example, a second kill activity information ), The amount of concurrency is very large ;
- Rebuilding the cache cannot be done in a short time , It may be a long affair , For example, complicated SQL、 many times IO、 Multiple RPC etc. .
In the moment of cache failure , There are a lot of threads to rebuild the cache , Cause the back-end load to increase ,DB Hung up ; also , At this time, the response of the request tends to slow down ( Because I didn't leave the cache ), The request thread pool may also be full ; so , The harm is still great ;
Solution :
2.1 Apply distributed locks when rebuilding the cache
actually , When the cache fails , There is a thread to execute the query DB, And brush the data into the cache ; Other threads wait for the thread to rebuild the cache to finish , Then get the data from the cache again ; Because it is accessed by a single thread DB,DB The pressure is not big , Generally, it is also very fast to complete the operations of querying and flushing into the cache ; The schematic diagram is as follows :

Under microservice , Generally, it is a multi node Application , Using distributed locks ensures that rebuilding the cache is single threaded ;
2.2 Let the cache never expire
The idea of this scheme is to make the cache exist forever , Therefore, theoretically, there is no cache miss that leads to DB The problem of layer breakdown ; there " Never expire " There are several implementation ideas :
(1) Physically ( Cache storage ), Do not set expiration time , This way is simple and crude , But when the cache is no longer used , You need to actively delete ; otherwise Redis May gradually accumulate some of this " invalid " But the cache that never expires , Waste space ;
(2) From the functional level , Can be " Due time " Written in value in , When removed key Corresponding value when , If it is found that the expiration time is approaching , You can refresh the cache immediately , Like " Renewal "; Of course , This method is applicable to the cache that is often accessed key It is more effective , Because the cache is accessed frequently , Therefore, the value is taken value when , This cache is often not invalidated , But if this buffer exists before failure , Not requested to , There will be a cache miss on the next request ; In this case , Still need to inquire DB Refactoring cache to Redis;
In practice , My advice is , We can use timed tasks to assign key Automatic renewal , for instance , On the day top50 The product information of , The set cache expiration time is 30 minute ( May update , So it doesn't need to be too long ), But there is a scheduled task every 20 Minute execution 1 Time , Automatically update the cache , Reset the expiration time to 30 minute ;
actually , The development specification tells us to use Redis when , Expiration time must be specified , Prevent when some caches are not used , Forget to delete and occupy Redis Space ;
3. Cache avalanche
Because the cache layer carries a lot of requests , Effectively protects the storage tier , But if the cache layer fails and is unavailable for some reason , Such as Redis Downtime 、 Or a large number of caches expire in the same time period due to the same timeout ( Large numbers key invalid / Hot data failure ), A large number of requests arrive directly DB Storage layer ,DB Excessive pressure leads to system avalanche .
An avalanche , It's similar to breakdown , The difference is that breakdown is a hot spot key At some point , And avalanches are a lot of hot spots key In a flash ;
Analyze the reason why batch cache is unavailable , We can have the following solutions :
3.1 Ensure the reliability of cache service
actually , After experiencing some online problems , You can find Redis Not as reliable as we expected , towards redis Node requests data , There is at least one layer of network request , Therefore, multi-level cache can be used , Local JVM As a first level cache ,redis As a second level cache , Different levels of cache have different timeout settings , Even if a level of cache expires , There are also other levels of cache bottoming ;
Use local cache such as GuavaCache、Caffeine, Can be prevented in redis When the cluster is abnormal , It can also prevent a large number of requests from hitting DB, Ensure the reliability of cache service ; however , If the local cache is required to be consistent in different service nodes , You need a distributed cache synchronization mechanism to ensure , Such as using messages 、ZK、Redis Publish, subscribe, etc , It will increase the complexity of the system ;
3.2 Choose appropriate service degradation
If you do a high availability Architecture ,redis The service still hung up , What to do ? Now , You need to downgrade the service , Otherwise, a large number of requests will hang up DB, The whole service is unavailable , That is, make high availability for yourself , Do a good job of business isolation for the whole service ;
Service degradation still depends on the actual business scenario , Such as information flow scenario , It can return non real-time data of users , Ensure that users can see at least part of the data , avoid " Data white pages "; For scenes that require high data accuracy , Then you can only return " The system is busy , Please try again later " This degradation prompts ;
for example , We configure some default data in advance , It can be 30min Before or 1 Data from the day before ; Automatically switch to read old data in case of cache exception , At the same time, open the task to try to query the cache ; When the cache is restored , It can automatically switch to read cache ; Is it a little similar Hystrix The demotion recovery of ?
3.3 Prevent a large number of caches from invalidating at the same time
The expiration time of the cache is a random value , Try to make different key The expiration time of is different ( for example : Create a new batch of scheduled tasks key, Set the expiration time to be the same ); But sometimes , The expiration time of the cache must be the same , Like a 0 Click to update the activity , We can use a new cache , And pass Cache preheating In advance ;
4. Cache preheating
Cache preheating is after the new function goes online , Load the relevant cache data directly into the cache system , In this way, users can avoid , Query database first , And then write the data back to the cache ; This kind of scene is usually the material of festival atmosphere 、 Zero point activities ;
If you don't preheat , that Redis There is no data in , arrive 0 A sudden wave of highly concurrent user requests after clicking , Will access the database , Pressure on database traffic ;
How to warm up the cache
- When the amount of data is small , Load the cache when the project starts ;
- When there's a lot of data , Set up a timed task script , Refresh the cache ;
- When there's too much data , The priority is to ensure that the hot data is loaded into the cache in advance ;
5. In the production environment, we use the general scheme of caching
The following scheme comes from personal development experience , Not necessarily complete and rigorous , But you can refer to ;
(1) First , You can use scheduled tasks to update each key Of value, Such as 1 God 1 Time , The expiration time of the cache is generally greater than the time interval of executing scheduled tasks , To ensure that when the refresh cache task is abnormal , We have some time to deal with , Prevent a large number of requests from coming in and hanging up at this time DB;
(2) meanwhile , When a key The corresponding value is in DB When an update occurs in , We will start an asynchronous thread in the business to try to brush the latest value Redis;
(3) Use L2 cache , Local cache is preferred , Next use redis, And finally DB; The expiration time of local cache is short , Less than redis cache ; When the local cache is missed , Try from redis Get and flush into the local cache ; When redis Also missed , Try from DB Get and return , At the same time, it refreshes asynchronously to redis in , If there are concurrent scenarios , You can use distributed locks for this step , That is, single thread query DB to update redis;
(4) Besides , because JVM Memory space in is limited , Can pass JVM Store a large amount of cached data in other ways , Such as disk storage ; Because of the disk IO Slower than cache , Therefore, the disk cache in this scheme will not be updated frequently , That is not to pursue accuracy , But to ensure reliability , Such as APP The homepage of can be the data of a few hours ago , But it cannot be a blank page ;
(5) Last , If the above methods are used , Still worried that the request will hang up DB, Want to protect as much as possible DB, You can not query DB, Only get data from the cache , When the cache fails or the cache service is abnormal , Return null value directly ; Cache degradation is generally a lossy operation , So try to reduce the impact of the downgrade on the business ;
Reference resources :
Redis Cache penetration + Cache avalanche + Causes and solutions of cache breakdown
Redis breakdown 、 through 、 Avalanche causes and Solutions
Make sense of a picture Redis Cache avalanche 、 Cache penetration 、 Cache breakdown
边栏推荐
- Linux MySQL 5.6.51 community generic installation tutorial
- Latex 编译报错 I found no \bibstyle & \bibdata & \citation command
- 部署api_automation_test过程中遇到的问题
- FE - Eggjs 结合 Typeorm 出现连接不了数据库
- 记录一次RDS故障排除--RDS容量徒增
- Promise中有resolve和无resolve的代码执行顺序
- pytest(2) mark功能
- Eslint configuration code auto format
- Flask-Migrate 检测不到db.string() 等长度变化
- eslint配置代码自动格式化
猜你喜欢
js中正则表达式的使用
Sentinel Alibaba open source traffic protection component

Distributed transactions: the final consistency scheme of reliable messages

Vscode installation, latex environment, parameter configuration, common problem solving

Sublime Text 配置php编译环境

CTF web practice competition
Sentry搭建和使用

Redis - hot key issues

apt命令报证书错误 Certificate verification failed: The certificate is NOT trusted

Redis - big key problem
随机推荐
Asynchronous data copy in CUDA
[daily question 1] write a function to judge whether a string is the string after the rotation of another string.
(第一百篇BLOG)写于博士二年级结束-20200818
Tensorrt command line program
virtualenv和pipenv安装
Code skills - Controller Parameter annotation @requestparam
Flask-Migrate 检测不到db.string() 等长度变化
flex九宫格布局
提高用户体验 防御性编程
Automation - when Jenkins pipline executes the nodejs command, it prompts node: command not found
Deployment API_ automation_ Problems encountered during test
js删除字符串的最后一位
Atcoder beginer contest 253 F - operations on a matrix / / tree array
Linux MySQL 5.6.51 community generic installation tutorial
The table component specifies the concatenation parallel method
Utilisation de la carte et de foreach dans JS
Kali latest update Guide
pytest(2) mark功能
Sentinel rules persist to Nacos
Vector types and variables built in CUDA