当前位置:网站首页>《动手学深度学习》(三) -- 卷积神经网络 CNN
《动手学深度学习》(三) -- 卷积神经网络 CNN
2022-07-04 19:06:00 【长路漫漫2021】
1 图像卷积
1.1 互相关运算
在⼆维互相关运算中,卷积窗口从输⼊张量的左上⻆开始,从左到右、从上到下滑动。当卷积窗口滑动到新⼀个位置时,包含在该窗口中的部分张量与卷积核张量进⾏按元素相乘,得到的张量再求和得到⼀个单⼀的标量值,由此我们得出了这⼀位置的输出张量值。如下图所示:
注意,输出⼤小略小于输⼊⼤小。这是因为卷积核的宽度和⾼度⼤于1,而卷积核只与图像中每个⼤小完全适合的位置进⾏互相关运算。所以,输出⼤小等于输⼊⼤小 n h × n w n_h \times n_w nh×nw减去卷积核⼤小 k h × k w k_h\times k_w kh×kw,即:
( n h − k h + 1 ) × ( n w − k w + 1 ) (n_h-k_h+1)\times(n_w-k_w+1) (nh−kh+1)×(nw−kw+1)
这是因为我们需要⾜够的空间在图像上“移动”卷积核。稍后,我们将看到如何通过在图像边界周围填充零来保证有⾜够的空间移动内核,从而保持输出⼤小不变。接下来,我们在corr2d函数中实现如上过程,该函数接受输⼊张量X和卷积核张量K,并返回输出张量Y。
import torch
def corr2d(X, K):
"""计算二维互相关运算"""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h +1, X.shape[1] - w +1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i+h, j: j+w] * K).sum()
return Y
输⼊张量X和卷积核张量K,来验证上述⼆维互相关运算的输出。
X = torch.tensor([[3, 3, 2, 1, 0], [0, 0, 1, 3, 1], [3, 1, 2, 2, 3], [2, 0, 0, 2, 2], [2, 0, 0, 0, 1]])
K = torch.tensor([[0, 1, 2], [2, 2, 0], [0, 1, 2]])
corr2d(X, K) # tensor([[12., 12., 17.], [10., 17., 19.], [ 9., 6., 14.]])
1.2 卷积层
卷积层对输⼊和卷积核权重进⾏互相关运算,并在添加标量偏置之后产⽣输出。所以,卷积层中的两个被训练的参数是卷积核权重和标量偏置。就像我们之前随机初始化全连接层⼀样,在训练基于卷积层的模型时,我们也随机初始化卷积核权重。
基于上⾯定义的corr2d函数实现⼆维卷积层。在__init__构造函数中,将weight和bias声明为两个模型参数。前向传播函数调⽤corr2d函数并添加偏置。
from torch import nn
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self ,x):
return corr2d(x, self.weight) + self.bias
1.3 图像中目标的边缘检测
如下是卷积层的⼀个简单应⽤:通过找到像素变化的位置,来检测图像中不同颜⾊的边缘。⾸先,我们构造⼀个 6 × 8 6 \times 8 6×8像素的⿊⽩图像。中间四列为⿊⾊(0),其余像素为⽩⾊(1)。
X = torch.ones(6, 8)
X[:, 2:6] = 0
接下来,构造⼀个⾼度为1、宽度为2的卷积核K。当进⾏互相关运算时,如果⽔平相邻的两元素相同,则输出为零,否则输出为⾮零。
K = torch.tensor([[1.0, -1.0]])
现在,我们对参数X(输⼊)和K(卷积核)执⾏互相关运算。如下所⽰,输出Y中的1代表从⽩⾊到⿊⾊的边缘,-1代表从⿊⾊到⽩⾊的边缘,其他情况的输出为0。
Y = corr2d(X, K)
Y

将输⼊的⼆维图像转置,再进⾏如上的互相关运算。其输出如下,之前检测到的垂直边缘消失了。不出所料,这个卷积核K只可以检测垂直边缘,⽆法检测⽔平边缘。
corr2d(X.T, K)
2 填充和步幅
2.1 填充
在应⽤多层卷积时,我们常常丢失边缘像素。由于我们通常使⽤小卷积核,因此对于任何单个卷积,我们可能只会丢失⼏个像素。但随着我们应⽤许多连续卷积层,累积丢失的像素数就多了。解决这个问题的简单⽅法即为填充(padding):在输⼊图像的边界填充元素(通常填充元素是0)。例如,在下图中,我们将 3 × 3 3\times3 3×3输⼊填充到 5 × 5 5\times5 5×5,那么它的输出就增加为 4 × 4 4\times4 4×4。阴影部分是第⼀个输出元素以及⽤于输出计算的输⼊和核张量元素: 0 × 0 + 0 × 1 + 0 × 2 + 0 × 3 = 0 0 \times 0 + 0 \times 1 + 0 \times 2 + 0 \times 3 = 0 0×0+0×1+0×2+0×3=0。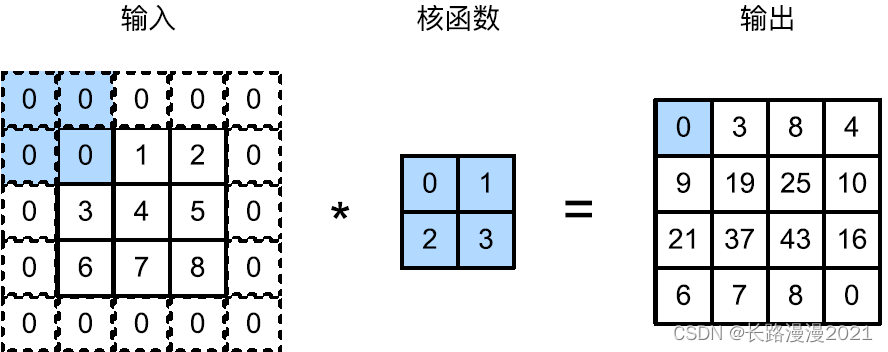
通常,如果我们添加 p h p_h ph⾏填充(⼤约⼀半在顶部,⼀半在底部)和 p w p_w pw列填充(左侧⼤约⼀半,右侧⼀半),则输出形状将为
( n h − k h + p h + 1 ) × ( n w − k w + p w + 1 ) (n_h-k_h+p_h+1)\times(n_w-k_w+p_w+1) (nh−kh+ph+1)×(nw−kw+pw+1)
这意味着输出的⾼度和宽度将分别增加 p h p_h ph和 p w p_w pw。
在许多情况下,我们需要设置 p h = k h − 1 p_h = k_h - 1 ph=kh−1和 p w = k w − 1 p_w = k_w - 1 pw=kw−1,使输⼊和输出具有相同的⾼度和宽度。这样可以在构建⽹络时更容易地预测每个图层的输出形状。假设 k h k_h kh是奇数,我们将在⾼度的两侧填充 p h / 2 p_h/2 ph/2⾏。如果 k h k_h kh是偶数,则⼀种可能性是在输⼊顶部填充 ⌈ p h / 2 ⌉ ⌈p_h/2⌉ ⌈ph/2⌉⾏,在底部填充 ⌊ p h / 2 ⌋ ⌊p_h/2⌋ ⌊ph/2⌋⾏。同理,我们填充宽度的两侧。
卷积神经⽹络中卷积核的⾼度和宽度通常为奇数,例如1、3、5或7。选择奇数的好处是,保持空间维度的同时,我们可以在顶部和底部填充相同数量的⾏,在左侧和右侧填充相同数量的列。
import torch
from torch import nn
def comp_conv2d(conv2d, X):
"""此函数初始化卷积层权重,并对输⼊和输出提⾼和缩减相应的维数"""
X = X.reshape((1, 1) + X.shape) # 这⾥的(1,1)表⽰批量⼤⼩和通道数都是1
Y = conv2d(X)
return Y.reshape(Y.shape[2:]) # 省略前两个维度:批量⼤⼩和通道
创建⼀个⾼度和宽度为3的⼆维卷积层,并在所有侧边填充1个像素。给定⾼度和宽度为8的输⼊,则输出的⾼度和宽度也是8。
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1) # 每边都填充了1⾏或1列,总共添加了2⾏或2列
X = torch.rand(size=(8, 8))
comp_conv2d(conv2d, X).shape # torch.Size([8, 8])
当卷积内核的⾼度和宽度不同时,我们可以填充不同的⾼度和宽度,使输出和输⼊具有相同的⾼度和宽度。在如下⽰例中,我们使⽤⾼度为5,宽度为3的卷积核,⾼度和宽度两边的填充分别为2和1。
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))
comp_conv2d(conv2d, X).shape # torch.Size([8, 8])
2.2 步幅
有时候为了⾼效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素。
每次滑动元素的数量称为步幅(stride)。到⽬前为⽌,我们只使⽤过⾼度或宽度为1的步幅,那么如何使⽤较⼤的步幅呢?下图是垂直步幅为3,⽔平步幅为2的⼆维互相关运算。着⾊部分是输出元素以及⽤于输出计算的输⼊和内核张量元素: 0 × 0 + 0 × 1 + 1 × 2 + 2 × 3 = 8 、 0 × 0 + 6 × 1 + 0 × 2 + 0 × 3 = 6 0 \times 0 + 0 \times 1 + 1 \times 2 + 2 \times 3 = 8、0 \times 0 + 6 \times 1 + 0 \times 2 + 0 \times 3 = 6 0×0+0×1+1×2+2×3=8、0×0+6×1+0×2+0×3=6。

通常,当垂直步幅为 s h s_h sh、⽔平步幅为 s w s_w sw时,输出形状为
⌊ ( n h − k h + p h + s h ) / s h ⌋ × ⌊ ( n w − k w + p w + s w ) / s w ⌋ \left\lfloor\left(n_{h}-k_{h}+p_{h}+s_{h}\right) / s_{h}\right\rfloor \times\left\lfloor\left(n_{w}-k_{w}+p_{w}+s_{w}\right) / s_{w}\right\rfloor ⌊(nh−kh+ph+sh)/sh⌋×⌊(nw−kw+pw+sw)/sw⌋
下⾯将⾼度和宽度的步幅设置为2,从而将输⼊的⾼度和宽度减半。
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
comp_conv2d(conv2d, X).shape # torch.Size([4, 4])
当高度和宽度的卷积核尺寸不一样,填充和步长不一样时,
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
comp_conv2d(conv2d, X).shape # torch.Size([2, 2])
3 多输入多输出通道
3.1 多输入通道
当输⼊包含多个通道时,需要构造⼀个与输⼊数据具有相同输⼊通道数的卷积核,以便与输⼊数据进⾏互相关运算。假设输⼊的通道数为 c i c_i ci,那么卷积核的输⼊通道数也需要为 c i c_i ci。如果卷积核的窗口形状是 k h × k w k_h\times k_w kh×kw,那么当 c i = 1 c_i = 1 ci=1时,我们可以把卷积核看作形状为 k h × k w k_h \times k_w kh×kw的⼆维张量。
然而,当 c i > 1 c_i > 1 ci>1时,我们卷积核的每个输⼊通道将包含形状为 k h × k w k_h\times k_w kh×kw的张量。将这些张量 c i c_i ci连结在⼀起可以得到形状为 c i × k h × k w c_i \times k_h \times k_w ci×kh×kw的卷积核。由于输⼊和卷积核都有 c i c_i ci个通道,我们可以对每个通道输⼊的⼆维张量和卷积核的⼆维张量进⾏互相关运算,再对通道求和(将 c i c_i ci的结果相加)得到⼆维张量。
下图演⽰了⼀个具有两个输⼊通道的⼆维互相关运算的⽰例。阴影部分是第⼀个输出元素以及⽤于计算这个输出的输⼊和核张量元素: ( 1 × 1 + 2 × 2 + 4 × 3 + 5 × 4 ) + ( 0 × 0 + 1 × 1 + 3 × 2 + 4 × 3 ) = 56 (1\times 1+2\times 2+4\times 3+5\times 4)+(0\times 0+1\times 1+3\times 2+4\times 3) = 56 (1×1+2×2+4×3+5×4)+(0×0+1×1+3×2+4×3)=56。
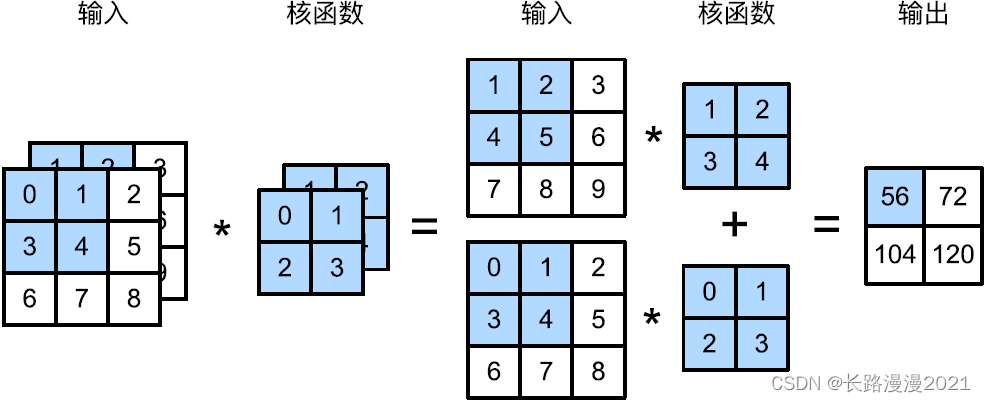
下面实现⼀下多输⼊通道互相关运算。简而⾔之,我们所做的就是对每个通道执⾏互相关操作,然后将结果相加。
def corr2d_multi_in(X, K):
"""先遍历“X”和“K”的第0个维度(通道维度),再把它们加在⼀起"""
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
3.2 多输出通道
在最流⾏的神经⽹络架构中,随着神经⽹络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更⼤的通道深度。直观地说,我们可以将每个通道看作是对不同特征的响应。而现实可能更为复杂⼀些,因为每个通道不是独⽴学习的,而是为了共同使⽤而优化的。因此,多输出通道并不仅是学习多个单通道的检测器。
⽤ c i c_i ci和 c o c_o co分别表⽰输⼊和输出通道的数⽬,并让 k h k_h kh和 k w k_w kw为卷积核的⾼度和宽度。为了获得多个通道的输出,我们可以为每个输出通道创建⼀个形状为 c i × k h × k w c_i \times k_h \times k_w ci×kh×kw的卷积核张量,这样卷积核的形状是 c o × c i × k h × k w c_o \times c_i \times k_h \times k_w co×ci×kh×kw。在互相关运算中,每个输出通道先获取所有输⼊通道,再以对应该输出通道的卷积核计算出结果。
如下所⽰,我们实现⼀个计算多个通道的输出的互相关函数。
def corr2d_multi_in_out(X, K):
# 迭代“K”的第0个维度,每次都对输⼊“X”执⾏互相关运算
# 最后把所有的结果都叠加在一起
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
3.3 1×1卷积层
使⽤了最小窗口, 1 × 1 1 \times 1 1×1卷积失去了卷积层的特有能⼒——在⾼度和宽度维度上,识别相邻元素间相互作⽤的能⼒。其实 1 × 1 1 \times 1 1×1卷积的唯⼀计算发⽣在通道上。
下图展⽰了使⽤ 1 × 1 1\times 1 1×1卷积核与3个输⼊通道和2个输出通道的互相关计算。这⾥输⼊和输出具有相同的⾼度和宽度,输出中的每个元素都是从输⼊图像中同⼀位置的元素的线性组合。我们可以将 1 × 1 1\times 1 1×1卷积层看作是在每个像素位置应⽤的全连接层,以 c i c_i ci个输⼊值转换为co个输出值。因为这仍然是⼀个卷积层,所以跨像素的权重是⼀致的。同时, 1 × 1 1 \times 1 1×1卷积层需要的权重维度为 c o × c i c_o \times c_i co×ci,再额外加上⼀个偏差。
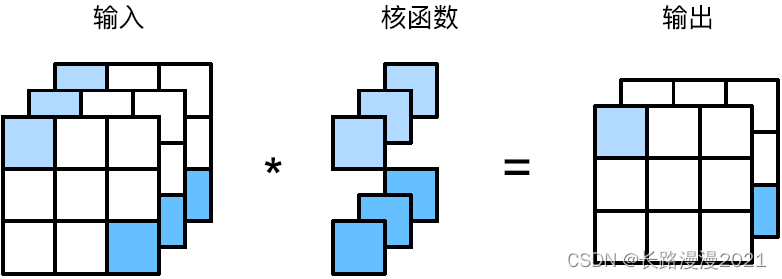
下⾯,我们使⽤全连接层实现 1 × 1 1 \times 1 1×1卷积。请注意,我们需要对输⼊和输出的数据形状进⾏微调。
def corr2d_multi_in_out_1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = X.reshape(c_i, h * w)
K = K.reshape(c_o, c_i)
# 全连接层层中的矩阵乘法
Y = torch.matmul(K, X)
return Y.reshape(c_o, h, w)
4 汇聚层
4.1 最大汇聚层和平均汇聚层
与卷积层类似,汇聚层运算符由⼀个固定形状的窗口组成,该窗口根据其步幅⼤小在输⼊的所有区域上滑动,为固定形状窗口(有时称为汇聚窗口)遍历的每个位置计算⼀个输出。然而,不同于卷积层中的输⼊与卷积核之间的互相关计算,汇聚层不包含参数。相反,池运算符是确定性的,我们通常计算汇聚窗口中所有元素的最⼤值或平均值。这些操作分别称为最⼤汇聚层(maximum pooling)和平均汇聚层(average pooling)。
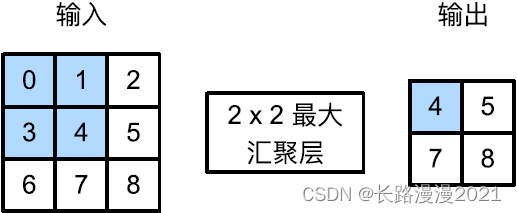
在这两种情况下,与互相关运算符⼀样,汇聚窗口从输⼊张量的左上⻆开始,从左往右、从上往下的在输⼊张量内滑动。在汇聚窗口到达的每个位置,它计算该窗口中输⼊⼦张量的最⼤值或平均值。计算最⼤值或平均值是取决于使⽤了最⼤汇聚层还是平均汇聚层。
在下⾯的代码中的pool2d函数,实现汇聚层的前向传播。此功能类似于上一节中的corr2d函数。然而,这⾥我们没有卷积核,输出为输⼊中每个区域的最⼤值或平均值。
def pool2d(X, pool_size, mode='max'):
p_h, p_w = pool_size
Y = torch.zeros(X.shape[0] - p_h + 1, X.shape[1] - p_w + 1)
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j : j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i+p_h, j : j + p_w].mean()
return Y
4.2 填充和步幅
默认情况下,深度学习框架中的步幅与汇聚窗口的⼤小相同。因此,如果我们使⽤形状为(3, 3)的汇聚窗口,那么默认情况下,我们得到的步幅形状为(3, 3)。
pool2d = nn.MaxPool2d((2, 3), padding= (0, 1), stride=(2, 3))
4.3 多个通道
在处理多通道输⼊数据时,汇聚层在每个输⼊通道上单独运算,而不是像卷积层⼀样在通道上对输⼊进⾏汇总。这意味着汇聚层的输出通道数与输⼊通道数相同。
边栏推荐
- Flet tutorial 05 outlinedbutton basic introduction (tutorial includes source code)
- Free soldier
- Informatics Olympiad 1336: [example 3-1] find roots and children
- The problem of the maximum difference between the left and right maxima
- go笔记(3)Go语言fmt包的用法
- word中插入图片后,图片上方有一空行,且删除后布局变乱
- 针对深度学习的“失忆症”,科学家提出基于相似性加权交错学习,登上PNAS
- So this is the BGP agreement
- Six stones programming: about code, there are six triumphs
- repeat_ P1002 [NOIP2002 popularization group] cross the river pawn_ dp
猜你喜欢
复杂因子计算优化案例:深度不平衡、买卖压力指标、波动率计算
![[in-depth learning] review pytoch's 19 loss functions](/img/c1/07650a6755d5c64ebf8ce370456fb7.png)
[in-depth learning] review pytoch's 19 loss functions
YOLOv5s-ShuffleNetV2

Jiuqi ny8b062d MCU specification /datasheet
强化学习-学习笔记2 | 价值学习
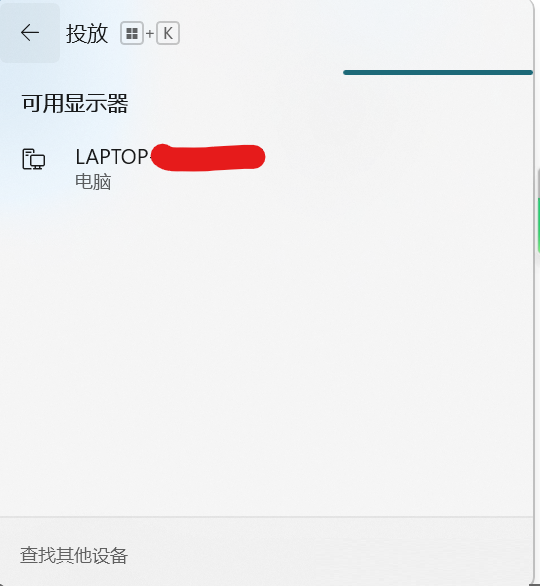
Win11怎么搜索无线显示器?Win11查找无线显示器设备的方法
Practice examples to understand JS strong cache negotiation cache
Reinforcement learning - learning notes 2 | value learning
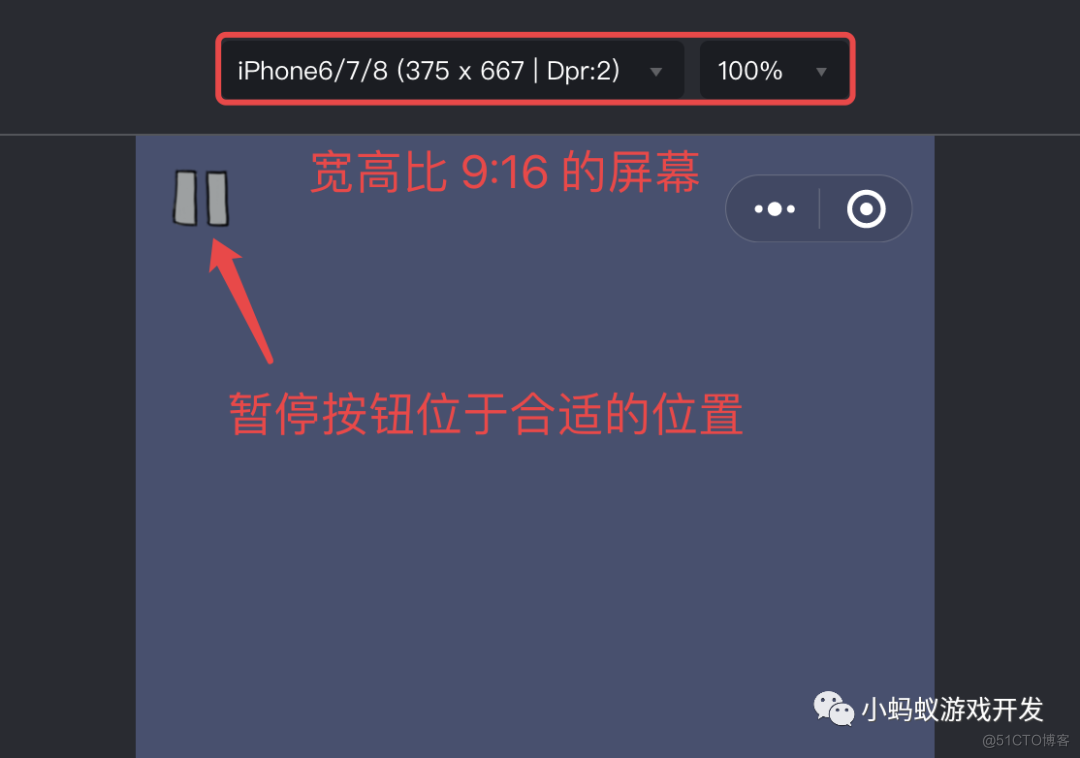
How to adapt your games to different sizes of mobile screen

【历史上的今天】7 月 4 日:第一本电子书问世;磁条卡的发明者出生;掌上电脑先驱诞生
随机推荐
Process of manually encrypt the mass-producing firmware and programming ESP devices
九齐单片机NY8B062D单按键控制4种LED状态
mysql语句执行详解
[today in history] July 4: the first e-book came out; The inventor of magnetic stripe card was born; Palm computer pioneer was born
Taishan Office Technology Lecture: about the order of background (shading and highlighting)
Ziguang zhanrui completed the first 5g R17 IOT NTN satellite on the Internet of things in the world
Informatics Olympiad 1336: [example 3-1] find roots and children
What are the consequences of closing the read / write channel?
go语言笔记(2)go一些简单运用
易周金融 | Q1保险行业活跃人数8688.67万人 19家支付机构牌照被注销
FS4061A升压8.4V充电IC芯片和FS4061B升压12.6V充电IC芯片规格书datasheet
电脑怎么保存网页到桌面上使用
15million employees are easy to manage, and the cloud native database gaussdb makes HR office more efficient
更强的 JsonPath 兼容性及性能测试之2022版(Snack3,Fastjson2,jayway.jsonpath)
YOLOv5s-ShuffleNetV2
二叉树的四种遍历方式以及中序后序、前序中序、前序后序、层序创建二叉树【专为力扣刷题而打造】
Decryption function calculates "task state and lifecycle management" of asynchronous task capability
华为云云商店首页 Banner 资源位申请
九齐NY8B062D MCU规格书/datasheet
Hash哈希竞猜游戏系统开发如何开发丨哈希竞猜游戏系统开发(多套案例)