当前位置:网站首页>GEAR: Graph-based Evidence Aggregating and Reasoning for Fact Verification
GEAR: Graph-based Evidence Aggregating and Reasoning for Fact Verification
2022-07-28 17:12:00 【Name filling】
Graph based evidence aggregation and reasoning are used for fact verification
Abstract
Previous work knowledge information extraction , There is no evidence of communication , Only splicing . therefore , These methods cannot grasp enough relationship and logical information between evidences . Put forward a a graph-based evidence aggregating and reasoning (GEAR) Graph based evidence aggregation and reasoning . This enables information to be transmitted on a fully connected evidence map , Then use different aggregators to collect multiple evidence information .
stay FEVER fraction 67.10% Code :https://githubcom/thunlp/GEAR
Introduction
therefore , Many recent studies have been devoted to fact verification , The purpose is to verify a given statement with evidence retrieved from plain text . More specifically , Given a declaration ,FV The system is required “ Support ”、“ refute ” or “ Not enough information ”, This shows that the evidence can support 、 Refutation or insufficient to support the statement .
Existing problems : Connect evidence or process only each evidence - Claim right . These methods cannot grasp enough relationship and logical information between evidences . in fact , Many statements require the simultaneous integration and reasoning of several evidences for verification . As shown in the table 1 Shown , about “ Supported ” Examples and “ Refuted ” Example , We cannot verify a given statement by examining any evidence alone . These claims can only be confirmed through the understanding and reasoning of various evidences .
say concretely , We first construct a completely connected evidence graph , And encourage the dissemination of information between evidences . then , We gather the evidence , And a classifier is used to determine whether the evidence can support 、 Refutation may not be enough to support this proposition . Intuitively speaking , Through the full exchange and reasoning of the evidence information on the evidence map , The model can make full use of this information to verify the declaration .
for example , Through the evidence map “ Los Angeles County is the most populous county in the United States ” A message to “ Rodney in Los Angeles County · Gold riots ”, Synthetic information can support “ Rodney · The king riots took place in the most populous county in the United States ”. Besides , We adopt an effective preprocessing language representation model BERT (Devlin wait forsomeone ,2019), To better grasp the evidence and claim semantics .
stay FEVER Compare the benchmark model
Related Work
2.1 FEVER Shared Task
2.2 Natural Language Inference
Natural language reasoning (NLI) The task requires the system to mark the relationship between a pair of premises and assumptions as implication 、 Contradictory or neutral . take NLI The model moves to FEVER The claim verification phase of the task is intuitive , Several teams from shared tasks have achieved promising results in this way .
2.3 Pre-trained Language Models
In our experiment , We found fine-tuning BERT Model in FEVER Declare that the verification subtask is superior to other tasks based on NLI Model of . therefore , We use BERT As a sentence encoder , To better encode the semantic information of evidence and claims .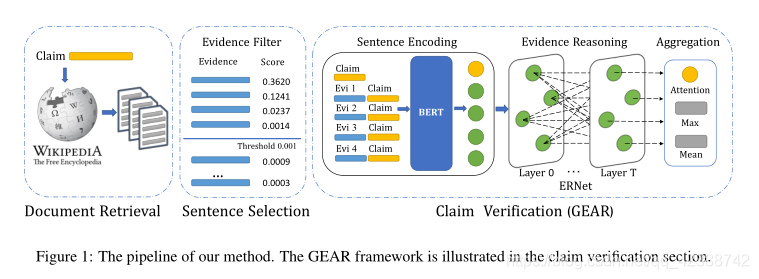
3 Method
We use a method that contains Document Retrieval 、 Sentence selection and Declaration validation Component to solve this task . In the stage of document retrieval and sentence selection , We simply follow Hanselowski wait forsomeone (2018) Methods , Because their method is in the past FEVER Highest evidence recall score in shared tasks . In the final stage of declaration validation , We propose a graph based evidence aggregation and reasoning framework . The whole is shown in the picture 1
3.1 Document Retrieval and Sentence Selection
In this section , We describe our document retrieval and sentence selection components . Besides , We add a threshold filter after the sentence selection component to filter out the noisy evidence .
use entity linking Method . Given a declaration , This method first utilizes AllenNLP Of the constituency parser( Gardner et al ,2018) Extract potential entities from declarations . Then it uses entities as search queries , And find relevant Wikipedia documents through online media Wikipedia . Store the seven highest ranked results of each query , To form a candidate article collection . Last , This method discards articles that are not in the offline Wikipedia dump , And filter the article according to the word overlap between the article title and the statement .
The sentence selection component selects the evidence most relevant to the declaration from all the sentences in the retrieved document .Hanselowski et al. (2018) Revised ESIM Model , To calculate the correlation score between evidence and statement .
In the training phase , Model USES hinge Loss function ∑ m a x ( 0 , 1 + s n − s p ) \sum max(0,1 +s_n-s_p) ∑max(0,1+sn−sp) And negative sampling strategy , among s p s_p sp and s n s_n sn Indicates the correlation score of positive samples and negative samples . In the test phase , The final model is integrated with different random seeds from 10 The result of a model . In the original method , Choose the one with the highest correlation score 5 Sentences to form the final evidence set .
In addition to the original model (Hanselowski wait forsomeone ,2018), We added a threshold τ \tau τ Correlation score filter . The correlation score is lower than τ \tau τ Sentences are filtered out to reduce noise . therefore , The final size of the retrieved evidence set is equal to or less than 5. We choose different τ \tau τ value , And select the value according to the results of the development set . The evaluation results of document retrieval and sentence selection are shown in 5.1 section .
Claim Verification with GEAR
In this section , We described our GEAR Declare the validation framework . Pictured 1 Shown , Given a statement and retrieved evidence , We first use the sentence encoder (sentence encoder) To obtain the representation of claims and evidence . Then we establish a fully connected evidence graph , An evidential reasoning network is proposed (evidence reasoning network,ERNet) To spread information between evidence and reasoning . Last , We use evidence aggregators (evidence aggregator) To infer the final result .
Sentence Encoder
Given an input sentence , We use BERT(Devlin et al., 2019) As our sentence coder , extract [CLS] The final hidden state of the token is represented , among [CLS] yes BERT Special classification embedded in . To be specific , Given a statement c c c and N N N Pieces of retrieved evidence e 1 , e 2 , . . . , e N {e_1,e_2,...,e_N} e1,e2,...,eN, We will each evidence - Statement to ( e i , c ) (e_i,c) (ei,c) Input BERT To obtain evidence that e i e_i ei. We will also enter the claim statement separately BERT, To get a statement that c c c.
e i = B E R T ( e i , c ) , c = B E R T ( c ) (1) e_i=BERT(e_i, c), \\ c=BERT(c) \tag{1} ei=BERT(ei,c),c=BERT(c)(1)
Please note that , We splice evidence and statements to extract evidence that ( namely , e i e_i ei), Because the evidence nodes in the reasoning diagram need information from the declaration to guide the message transmission process between them .
Evidence Reasoning Network
In order to encourage the dissemination of information between evidences , We construct a completely connected evidence graph , Each node represents an evidence . First, add self-loop, Because every node needs information from itself in the process of message propagation . Use h t = { h 1 t , h 2 t , . . . , h N t } h^t = \{h_1^t,h_2^t,...,h_N^t\} ht={ h1t,h2t,...,hNt} Indicates that the node is at t t t The hidden state of the layer , here h i t ∈ R F × 1 h_i^t \in R^{F\times 1} hit∈RF×1,f Is the number of features in each node . Each evidence node h i 0 h_i^0 hi0 The initial hidden state of is initialized by evidence : h i 0 = e i h_i^0= e_i hi0=ei.
Inspired by recent semi supervised graph learning and relational reasoning . We propose an evidential reasoning network (ERNet) To spread information between evidence nodes . We use MLP To compute nodes i i i And its neighbors j , j ∈ N i j,j\in N_i j,j∈Ni Attention coefficient between .
p i j = W 1 t − 1 ( R e L U ( W 0 t − 1 ( h i t − 1 ∣ ∣ h j t − 1 ) ) ) . (2) p_{ij}=W_1^{t-1}(ReLU(W_0^{t-1}(h_i^{t-1}||h_j^{t-1}))). \tag{2} pij=W1t−1(ReLU(W0t−1(hit−1∣∣hjt−1))).(2)
N i N_i Ni Represents a node i i i Neighbor node , w 0 t − 1 ∈ R H × 2 F w_0^{t-1} \in R^{H\times 2F} w0t−1∈RH×2F and W 1 t − 1 ∈ R 1 × H W_1^{t-1} \in R^{1 \times H} W1t−1∈R1×H It's the weight matrix , ∣ ∣ || ∣∣ Stands for splicing
then , We use softmax Function normalizes the coefficients ,
α i j = s o f t m a x j ( p i j = e x p ( p i j ) ∑ k ∈ N i e x p ( p i k ) ) (3) \alpha_{ij} = softmax_j(p_{ij} = \frac{exp(p_{ij})}{\sum_{k \in N_i} exp(p_{ik})}) \tag{3} αij=softmaxj(pij=∑k∈Niexp(pik)exp(pij))(3)
Last , The normalized attention coefficient is used to calculate the linear combination of adjacent features , So we get layers t t t Node at i i i Characteristics of ,
h i t = ∑ j ∈ N i α i j h j t − 1 (4) h_i^t =\sum_ {j \in N_i} \alpha_{ij} h_j^{t-1} \tag{4} hit=j∈Ni∑αijhjt−1(4)
By stacking ERNet Of T layer , We assume that each evidence can master enough information by communicating with other evidence . We will take the evidence node h 1 T , h 2 T , . . . , h N T {h_1^T,h_2^T,...,h_N^T} h1T,h2T,...,hNT Enter our evidence aggregator to make the final inference .
Evidence Aggregator
We use the evidence aggregator to collect information from different evidence nodes , And get the final hidden state O ∈ R F × 1 O \in R^{F \times 1} O∈RF×1. Aggregators may use different aggregation strategies , We recommend using three aggregators in the framework :
- Attention Aggregator. ad locum , We use the declaration c c c To pay attention to the hidden state of evidence , And get the final aggregation state o o o.
p j = W ∗ ( R e L U ( W 0 ∗ ( c ∣ ∣ h j T ) ) ) p_j = W^* (ReLU(W_0^* (c||h_j^T))) pj=W∗(ReLU(W0∗(c∣∣hjT)))
α j = s o f t m a x ( p j ) = e x p ( p j ) ∑ k = 1 N e x p ( p k ) (5) \alpha_j = softmax(p_j)= \frac{exp(p_j)}{\sum_{k=1}^N exp(p_k)} \tag{5} αj=softmax(pj)=∑k=1Nexp(pk)exp(pj)(5)
o = ∑ k = 1 N α k h k T o=\sum_{k=1}^N \alpha_kh_k^T o=k=1∑NαkhkT
here W 0 ∗ ∈ R H × 2 F W_0^* \in R^{H \times 2F} W0∗∈RH×2F and W 1 ∗ ∈ R 1 × H W_1^* \in R^{1 \times H} W1∗∈R1×H
- Max Aggregator. The maximum aggregator performs element level maximum operations between hidden states .
o = M a x ( h i T , h 2 T , . . . , h N T ) (6) o = Max(h_i^T, h_2^T,...,h_N^T) \tag{6} o=Max(hiT,h2T,...,hNT)(6) - Mean Aggregator. The average aggregator performs the average operation of element mode between hidden states .
o = M e a n ( h i T , h 2 T , . . . , h N T ) (7) o = Mean(h_i^T, h_2^T,...,h_N^T) \tag{7} o=Mean(hiT,h2T,...,hNT)(7)
Once the final state is obtained o o o, We use single layer MLP To get the final prediction l l l
l = s o f t m a x ( R e L U ( W o + b ) ) (8) l = softmax(ReLU(W_o + b)) \tag{8} l=softmax(ReLU(Wo+b))(8)
here W ∈ R C × F W \in R^{C\times F} W∈RC×F and b ∈ R C × 1 b \in R^{C\times 1} b∈RC×1 Is the parameter ,C Is to predict the number of tags .
4 Experimental Settings
4.1 Dataset
FEVER Data sets ,185455 Comment statement ,5,416,537 Wikipedia documents 
4.2 Baselines
In this section , We describe the baseline system in the experiment . Let's first introduce from FEVER Before sharing tasks 3 A system . because BERT (Devlin wait forsomeone ,2019) In a few days NLP Encouraging performance has been achieved on the mission , We also fine tune it in the declaration verification task BERT To implement two baseline systems .
4.3 Hyperparameter Settings
B E R T B A S E BERT_{BASE} BERTBASE lr=2e-5 See the detailed explanation of the paper
4.4 Evaluation Metrics
In addition to traditional evaluation indicators , Such as label accuracy and F1, We also use two other indicators to evaluate our model .
FEVER score
FEVER Scoring is based on providing at least a complete set of evidence for label accuracy . Declare the label as “NEI” The claim of does not need evidence .
OFEVER score
Document retrieval and sentence selection components are usually composed of oracle FEVER(OFEVER) Score to evaluate , This score is when assuming a perfect downstream system FEVER The upper limit of the score .
about GEAR All of our experiments , We are dev Scores reported on the set (label accuracy, FEVER score) It's the average ,10 This run is initialized by different random seeds .
5 Experimental Results and Analysis
In this section , We first introduce the evaluation of document retrieval and sentence selection components . Then we evaluate our... From several different aspects GEAR frame . Last , We present a case study , To prove the effectiveness of our framework .
5.1 Document Retrieval and Sentence Selection
We use OFEVER Metrics to evaluate document retrieval components .
Table 3 Comparison OFEVER fraction , Table 4 compares sentence selection components with different thresholds .
We found that the threshold is 0 The model obtained the highest recall rate and OFEVER fraction . When the threshold increases , Recall value and OFEVER The score drops gradually , And accuracy and F1 Scores increase . The result is consistent with our intuition . If we don't sift out the evidence , More statements may provide a complete set of evidence . If we increase the threshold value , More noisy evidence is filtered out , This contributes to accuracy and F1 An increase in .
5.2 Claim Verification with GEAR
In this part , We evaluate our... From different aspects GEAR frame . We first compare the label accuracy scores between our framework and the baseline system . Then we discuss the influence of different thresholds on upstream sentence filtering . We also conducted additional experiments to check the effect of sentence embedding . Because it's close 39% Your statement requires reasoning about multiple pieces of evidence , We built a difficult development subset , And checked our ERNet The effectiveness of evidential reasoning . Last , We conducted an error analysis , The accuracy of the theoretical upper bound of the frame is given .
Model Evaluation
We use the label accuracy measure to evaluate the effectiveness of different declaration validation models . surface 7 The second column of shows the accuracy . We found that BERT Fine tuning models are better than all models from shared tasks , This shows BERT Strong ability in representation learning and semantic understanding .BERT-Concat Model ratio BERT-Pair The model is slightly improved , Improved 0.37%.
Because our framework provides a better method for evidence aggregation and reasoning , So the improvement shows , Our framework spreads 、 Analyze and aggregate features , The ability to better integrate features from different evidences .
Effect of Sentence Thresholds
surface 4 The rightmost column shows our GEAR The results of the framework under different sentence selection thresholds . We choose the threshold τ = 1 0 − 3 τ= 10^{-3} τ=10−3、 The model with the highest label accuracy is the final model . When threshold from 0 Add to $10^{-3} when , The label accuracy will be improved due to the information with less noise . However , When threshold from 1 0 − 3 10^{-3} 10−3 Add to 1 0 − 1 10^{-1} 10−1 when , Because the information evidence is filtered , The model cannot obtain enough evidence to make a correct inference , Therefore, the accuracy of labels is reduced .
Effect of Sentence Embedding
We used in the sentence encoding step BERT Model in FEVER A epoch Fine tuning of . We need to find out whether to fine tune the process or simply combine BERT Whether the sentence embedding of has made a major contribution to the final result . We use BERT The model is tested without fine-tuning process , We found that the accuracy of the final development tag is close to the result of random guess . therefore , Fine tuning process rather than sentence embedding plays an important role in this task .
We need to fine tune the process to capture the semantic and logical relationship between evidence and statements . Sentence embedding is more general , Poor performance in this particular task . therefore , We can't just use other methods ( Such as ELMo、CNN) Instead of the sentence embedding we use here .
Effectiveness of ERNet
In our observation ,dev More than half of the statements in the data set only need one evidence to make a correct inference . In order to verify the effectiveness of our framework on multiple evidential reasoning , We build a difficult development subset by selecting samples from the original development set . about SUPPORTED and REFUTED class , Statements that are fully supported by only one piece of evidence will be filtered out . Why choose all NEI Statement , Because the model needs all the retrieved evidence to come out NOT ENOUGH INFO” Conclusion . Difficult subset contains 7870 Samples , Including more than 39% Development set of .
We test our final model on a difficult subset , And on the table 5 The results are given in . We found that we have ERNet Our model is better than none ERNet Our model performs better , The smallest improvement between them is 1.27%. We can also find from the table , have 2 individual ERNet The model of layer obtains the best result , This indicates that claims from difficult subsets require multi-step evidence dissemination . This result proves the ability of our framework to deal with claims that require multiple evidences .
Error Analysis
In this section , We will study the impact of errors propagated from upstream components . We used an evidence enhanced development subset to test our GEAR The theoretical upper limit score of the framework , This subset assumes that all basic factual evidence is retrieved .
In our analysis , The main error of our framework comes from the upstream document retrieval and sentence selection components , They cannot extract enough evidence to reason . for example , To verify the statement Giada at Home was only available on DVD
We need to Giada at Home is a television show and first aired on October 18, 2008, on the Food Network and Food Network is an American basic cable and satellite television channel. However , The entity linking method used in our document retrieval component cannot be retrieved only by parsing the declared content Food Network file . therefore , The claim verification part cannot make a correct inference in the case of insufficient evidence .
In order to explore the impact of this problem , We're in evidence dev Our model was tested on the set , Among them, we score the relevance as 1 Basic factual evidence of is added to the evidence set . It ensures that each statement in the evidence enhancement set provides basic factual evidence and retrieved evidence .
The experimental results are shown in the table 6 Shown . We can find out , And watch 7 Compared with the accuracy of the original development set labels , All scores in the table have increased 1.4% above , Because the basic factual evidence is added . because oracle Assumptions of upstream components , surface 6 The results in show the theoretical upper bound label accuracy of our framework .
The results show the challenges of previous evidence retrieval tasks , These challenges cannot be solved by existing models .Nie wait forsomeone (2019 year ) A two hop evidence enhancement method is proposed , Improved on the final fever score 0.08%. Due to the increase of basic factual evidence, our experiments have increased 1.4% above , Therefore, it is worthwhile to design a better evidence retrieval pipeline , This is still our future research direction .
5.3 Full Pipeline
In this section, we introduce the evaluation of all our pipelines . Please note that , Due to the integrity of the evidence set , Label accuracy and final FEVER There is a gap between the scores . We found that , A good predictor NEI Example models tend to get higher fever scores . therefore , In all experiments, we based on dev FEVER Score selection final model . The model contains a layer ERNet, And use the attention aggregator . Threshold of sentence selection 1 0 − 3 10^{-3} 10−3
surface 7 The evaluation of the whole pipeline is given . We found that BERT Test of fine tuning system FEVER The score is nearly higher than other shared task models 1%. Besides , The performance ratio of our complete pipeline BERT-Concat Baseline above 1.46%, And achieved significant improvements .
5.4 Case study

surface 8 It shows an example in our experiment , It requires multiple pieces of evidence to make a correct inference . The basic factual evidence set contains articles “Al Jardine” pass the civil examinations 0 Xing He 1 Line sentences . These two evidences also rank in the top two in the evidence set we have retrieved .
In order to verify “ Al · Is Justin an American rhythm guitarist ”, Our model needs evidence “ He is famous as a rhythm guitarist in the band ” And the evidence “ Allen 900 Charles · Justin ”… American musician ”. We use a layer ERNet Sum graph 2 The attention concentrator in draws the attention map of the final model . We can find out , All evidence nodes tend to participate in the first and second evidence nodes , These two nodes provide the most useful information in this case . The attention weight in other evidence nodes is quite low , This shows that our model has the ability to select useful information from multiple evidences .
6 Conclusion
We propose a new graph based evidence aggregation and reasoning framework . The framework uses BERT Statement encoder 、 Evidential reasoning network (ERNet) And the evidence aggregator 、 Disseminate and aggregate information from multiple pieces of evidence . The framework proved to be effective , Our final pipeline has achieved significant improvements . some time , We hope to design a multi-step Evidence Extractor , And bring external knowledge into our framework .
边栏推荐
- Android Development - set cache
- UNIQUE VISION Programming Contest 2022(AtCoder Beginner Contest 248)G. GCD cost on the tree
- [deep learning]: day 1 of pytorch introduction to project practice: data operation and automatic derivation
- 【深度学习】:《PyTorch入门到项目实战》:简洁代码实现线性神经网络(附代码)
- SUSE Storage6 环境搭建详细步骤 – Win10 + VMware WorkStation
- 【深度学习】:《PyTorch入门到项目实战》第五天:从0到1实现Softmax回归(含源码)
- 传英伟达已与软银展开会谈,将出价超过320亿美元收购Arm
- : No such file or directory
- SUSE Ceph 增加节点、减少节点、 删除OSD磁盘等操作 – Storage6
- Function接口之andThen
猜你喜欢

Re10: are we really making much progress? Revisiting, benchmarking, and refining heterogeneous gr

浏览器解码过程分析

HTAP comes at a price

Unity editor learning (I) using features to change the display of fields in components

Unity shader procedural texture
Atcoder regular contest 133 d.range XOR (digital dp+ classification discussion)

微服务架构-服务注册中心和服务网关(6.8) (转载)

Outline and principle of structured design -- modularization
Read excel xlsx format file in unity

总数据量超万亿行,玉溪卷烟厂通过正确选择时序数据库轻松应对

随机推荐
Easypoi --- excel file export
【深度学习】:《PyTorch入门到项目实战》第五天:从0到1实现Softmax回归(含源码)
[deep learning]: day 9 of pytorch introduction to project practice: dropout implementation (including source code)
Re12: read these3 semantic self segmentation for abstract summary of long legal documents in low
【深度学习】:《PyTorch入门到项目实战》第六天:多层感知机(含代码)
Re11: read EPM legal judgment prediction via event extraction with constraints
RE14: reading paper illsi interpretable low resource legal decision making
Create a self-organizing / safe / controllable Lora network! Semtech responded for the first time to the impact of the "new regulations of the Ministry of industry and information technology"
Unity shader screen post-processing
深入理解 DeepSea 和 Salt 部署工具 – Storage6
总数据量超万亿行,玉溪卷烟厂通过正确选择时序数据库轻松应对
负整数及浮点数的二进制表示
Some opinions on bug handling
How should I understand craft
mysql 最大建议行数2000w,靠谱吗?
Re10: are we really making much progress? Revisiting, benchmarking, and refining heterogeneous gr
Codeforces Round #750 (Div. 2) F.Korney Korneevich and XOR (easy&&hard version)(dp)
Applet: scroll view slides to the bottom by default
Codeforces round 770 (Div. 2) e. fair share
Unity editor learning (I) using features to change the display of fields in components