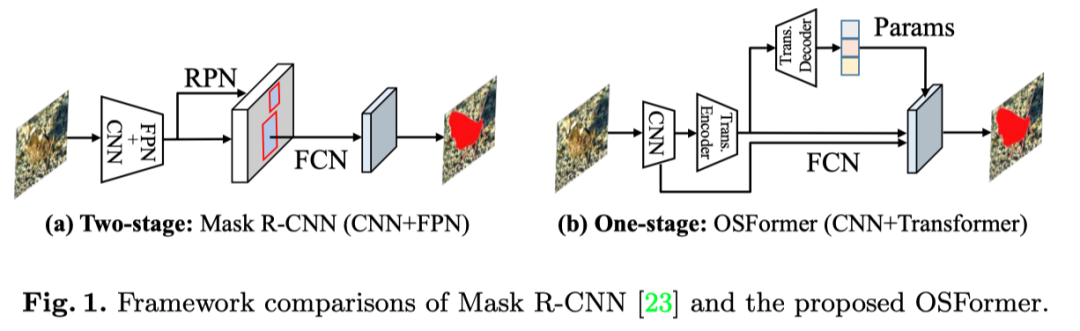
当前位置:网站首页>ECCV 2022 华科&ETH提出首个用于伪装实例分割的一阶段Transformer的框架OSFormer!代码已开源!...
ECCV 2022 华科&ETH提出首个用于伪装实例分割的一阶段Transformer的框架OSFormer!代码已开源!...
2022-07-31 16:47:00 【我爱计算机视觉】
关注公众号,发现CV技术之美
本篇分享 ECCV 2022 论文『OSFormer: One-Stage Camouflaged Instance Segmentation with Transformers』,华科Ð提出首个用于伪装实例分割的一阶段Transformer的框架OSFormer!代码已开源!
详细信息如下:

论文地址:https://arxiv.org/abs/2207.02255[1]
代码地址:https://github.com/PJLallen/OSFormer[2]
01
摘要
在本文中,作者提出了OSFormer,这是第一个用于伪装实例分割(CIS)的一阶段Transformer框架。OSFormer基于两个关键设计。
首先,通过引入位置引导查询和混合卷积前馈网络,作者设计了一个位置感知Transformer(LST)来获取位置标签和实例感知参数。
其次,作者开发了一种从粗到精的融合(CFF),以合并来自LST编码器和CNN主干的不同上下文信息。耦合这两个组件使OSFormer能够有效地混合局部特征和长期上下文依赖,以预测伪装实例。
与两阶段框架相比,本文的OSFormer在不需要大量训练数据的情况下达到了41%的AP,并实现了良好的收敛效率。
02
Motivation
伪装是一种强大且广泛的手段,可以避免来自生物学的检测或识别。在自然界中,伪装对象已经进化出一套隐藏策略来欺骗猎物或捕食者的感知和认知机制,例如背景匹配、自阴影隐藏、擦除阴影、破坏性着色等。与一般的目标检测相比,这些防御行为使得伪装目标检测(COD)成为一项非常具有挑战性的任务。COD的目标是区分与背景具有高度内在相似性的伪装物体。
由于COD10K、CAMO、CAMO++和NC4K等大规模标准基准的建立,COD的性能得到了显著的提高。然而,COD仅将伪装物体从场景中以对象的级别进行分离,而忽略进一步的实例级别标识。最近,研究者提出了一个新的伪装实例分割(CIS)基准和CFL框架。捕获伪装实例可以在真实场景中提供更多线索(例如语义类别、对象数量),因此CIS更具挑战性。
与通用实例分割相比,CIS需要在更复杂的场景中执行,具有较高的特征相似性,并产生类别不可知mask。此外,各种实例可能在场景中显示不同的伪装策略,并且将它们结合起来可能形成相互伪装。这些衍生的整体伪装使CIS任务更加艰巨。当人类注视着一个伪装得很深的场景时,视觉系统会本能地扫描整个场景中的一系列局部范围,以寻找有价值的线索。受这种视觉机制的启发,作者提出了一种新的位置感知CIS方法,该方法从全局角度仔细捕获所有位置(即局部上下文)的关键信息,并直接生成伪装实例掩码(即一阶段模型)。
由于transformer在视觉领域的兴起,可以利用自注意力和交叉注意力来捕捉长期依赖关系,并构建全局内容感知交互。尽管transformer模型在一些密集预测任务上表现出了强大的性能,但它需要包含大规模的训练数据和更长的训练周期。然而,作为一项全新的下游任务,目前只有有限的实例级训练数据可用。
为此,作者提出了一种基于的位置感知Transformer(LST),以在更少的训练样本下实现更快的收敛和更高的性能。为了动态生成每个输入图像的位置引导查询,作者将LST编码器输出的多尺度全局特征网格化为一组具有不同局部信息的特征块。与vanilla DETR中的零初始化对象查询相比,提出的位置引导查询可以专注于位置特定的特征,并通过交叉注意与全局特征交互,以获得实例感知嵌入。
该设计有效地加快了收敛速度,显著提高了伪装实例的检测。为了增强局部感知和相邻token之间的相关性,作者将卷积运算引入标准前馈网络,将其称为混合卷积前馈网络(BC-FFN)。因此,本文基于LST的模型可以无缝集成局部和全局上下文信息,并有效地提供位置敏感特征来分割伪装实例。
此外,作者设计了一种从粗到精的融合(CFF)来集成从ResNet和LST相继产生的多尺度低层次和高层次特征,以产生共享掩码特征。由于伪装实例的边缘难以捕捉,作者在CFF模块中嵌入了反向边缘注意(REA)模块,以提高对边缘特征的敏感性。
最后,作者引入了动态伪装实例归一化(DCIN),通过结合高分辨率掩码特征和实例感知嵌入来生成掩码。基于上述两种新设计,即LST和CFF,作者提供了一种新的用于伪装实例分割的单阶段框架OSFormer(如上图)。OSFormer是第一个为CIS任务探索基于transformer的框架的工作。
本文的贡献如下:
提出了OSFormer,这是为伪装实例分割任务设计的第一个基于Transformer的一阶段框架。这是一个灵活的框架,可以端到端的方式进行训练。
提出了一种位置感知Transformer(LST)来动态捕捉不同位置的实例线索。本文的LST包含一个带有混合卷积前馈网络的编码器,用于提取多尺度全局特征,以及一个带有位置引导查询的解码器,用于实现实例感知嵌入。所提出的LST结构可以快速收敛到有限的训练数据。
提出了一种新的粗到细融合(CFF)方法,通过融合主干和LST块的多尺度低层和高层特征来获得高分辨率掩模。在该模块中,嵌入了反向边缘注意(REA),以突出伪装实例的边缘信息。
广泛的实验表明,OSFormer在具有挑战性的CIS任务中表现良好,在很大程度上优于11种流行的实例分割方法,例如,在COD10K测试集上实现了8.5% 的AP改进。
03
方法

本文提出的OSFormer包括四个基本组件:(1)用于提取对象特征表示的CNN主干,(2)利用全局特征和位置引导查询生成实例感知嵌入的位置感知Transformer(LST)。(3) 粗到细融合(CFF)用于集成多尺度低和高级别特征并产生高分辨率掩码特征,以及(4)用于预测最终实例掩码的动态伪装实例归一化(DCIN)。上图展示了整个架构。
3.1 CNN Backbone
给定输入图像,走着使用来自CNN主干的多尺度特征(即ResNet-50)。为了降低计算成本,作者直接将最后三个特征映射()展平并连接成一个256个通道的序列作为LST编码器的输入。对于特征,将其作为高分辨率低层特征输入到CFF模块中,以捕获更多伪装的实例线索。
3.2 Location-Sensing Transformer
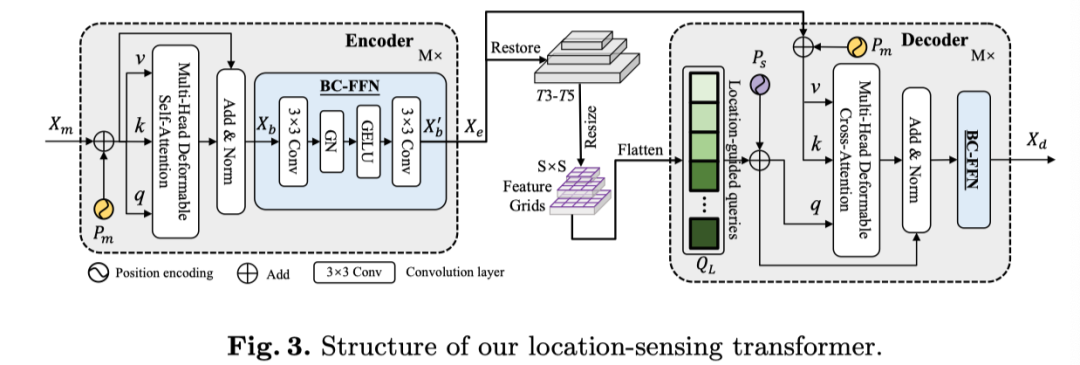
虽然transformer可以通过自注意力层更好地提取全局信息,但它需要大规模训练样本和高计算量。由于CIS的数据有限,本文的目标是设计一种高效的架构,可以更快地收敛并实现有竞争力的性能。在上图中,作者展示了本文的位置感知Transformer(LST)。
LST Encoder
与仅向transformer编码器输入单尺度低分辨率特征的DETR不同,本文的LST编码器接收多尺度特征以获得丰富的信息。遵循可变形自注意力层,为了更好地捕捉局部信息并增强相邻token之间的相关性,作者将卷积运算引入前馈网络,称为混合卷积前馈网络(BC-FFN)。
首先,根据的形状将特征向量恢复到空间维度。然后,执行核大小为3×3的卷积层来学习归纳偏置。最后,作者添加了一个组归一化(GN)和一个GELU激活来形成前馈网络。在3×3卷积层之后,作者将特征展平为序列。与混合FFN相比,本文的BC-FFN不包含MLP操作和残差连接。
与之前工作在每个阶段开始时设计卷积token嵌入并在Transformer块中采用深度可分离卷积运算不同,作者在BC-FFN中只引入了两个卷积层。具体来说,给定输入特征,BC-FFN的过程可以公式化为:
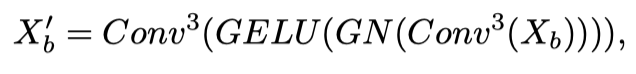
其中,是3×3卷积运算。总的来说,LST编码器层描述如下:
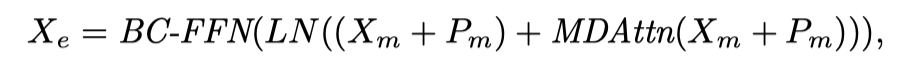
其中表示为位置编码。和分别表示多头可变形自注意力和层归一化。
Location-Guided Queries
对象查询在transformer架构中起着关键作用,transformer架构用作解码器的初始输入,并通过解码器层实现输出嵌入。然而,vanilla DETR收敛缓慢的原因之一是对象查询是零初始化的。为此,作者提出了位置引导查询,该查询具有LST编码器的多尺度特征映射的优势。
值得注意的是,DETR中的每个查询都集中在特定的领域。受SOLO的启发,作者首先将恢复的特征映射调整为的形状,。然后,将调整大小的特征划分为特征网格,并将其展平,以生成位置引导查询。
在这种情况下,提出的位置引导查询可以利用不同位置的可学习局部特征来优化初始化,并有效地聚合伪装区域中的特征。与零初始化或随机初始化相比,该查询策略提高了transformer解码器中查询更新的效率,并加速了训练收敛。
LST Decoder
LST解码器对于与LST编码器生成的全局特征和位置引导查询交互以生成实例感知嵌入至关重要。空间位置编码也被添加到本文的位置引导查询和编码器memory中。然后,通过可变形交叉注意力层对其进行融合。
与一般transformer解码器不同,作者直接使用交叉注意力而不使用自注意力,因为提出的查询已经包含可学习的全局特征。与LST编码器类似,BC-FFN也在可变形注意力操作后使用。给定位置引导查询,本文的LST解码器可以表示为:

其中表示基于特征网格的位置编码。表示为多头可变形交叉注意力操作。是实例感知表示的输出嵌入。最后,恢复以送到以下DCIN模块,用于预测掩码。
3.3 Coarse-to-Fine Fusion

作为一种基于自底向上Transformer的模型,OSFormer利用LST编码器输出的多级全局特征,以产生共享掩码特征。为了合并不同的上下文信息,作者还融合了来自CNN主干的低级特征作为补充,以生成统一的高分辨率特征映射。
粗到细融合(CFF)模块的详细结构如上图所示。将多级特征C2、T3、T4和T5作为级联融合的输入。从输入尺度为1/32的T5开始,通过3×3卷积、GN和2×双线性上采样,并添加更高分辨率特征(T4为1/16比例)。
将1/4比例的融合后,特征继续进行1×1卷积、GN和RELU操作,以生成掩码特征。请注意,每个输入特征在第一次卷积后将通道从256个减少到128个,然后在最终输出时增加到256个通道。
考虑到伪装的边缘特征更难捕捉,作者设计了嵌入CFF的反向边缘注意(REA)模块,以在迭代过程中监督边缘特征。与之前的反向注意不同,本文的REA对边缘特征而不是预测的二进制掩码进行操作。
此外,用于监督的边缘标签是通过实例掩码标签获得的,无需任何手动标记。受卷积块注意的启发,输入特征由平均池化(AvgPool)和最大池(MaxPool)操作。然后,将它们concat并送到7×7卷积和sigmoid函数。
然后,反转注意力权重,并将其与融合特征进行元素乘法。最后,作者使用3×3卷积来预测边缘特征。假设输入特征为,每个REA模块的整个过程可以公式化如下:

其中,表示7×7卷积层,表示通道轴上的concat。所提出的CFF提供了共享掩码特征F,然后送到DCIN中,以预测最终的伪装实例掩码。
3.4 Dynamic Camouflaged Instance Normalization
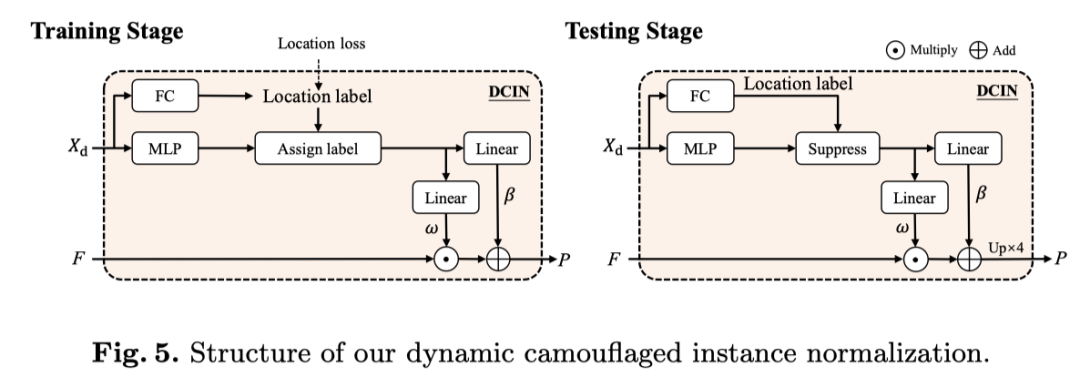
受样式迁移域中实例归一化操作的启发,作者引入了一种动态伪装实例归一化(DCIN)来预测最终掩码。当DCIN接收从LST解码器到输出嵌入时,采用全连接层(FC)来获得位置标签。
并行地,使用多层感知器(MLP)获得大小为D(即256)的实例感知参数。作者在训练阶段根据ground truth分配正位置和负位置。应用正位置的实例感知参数来生成分割掩码。在测试阶段,作者利用位置标签的置信值来过滤(如上图所示)无效参数(例如,阈值>0.5)。
随后,对滤波的位置感知参数操作两个线性层,以获得仿射权重和偏差。最后,它们与共享掩码特征
一起使用来预测伪装实例,可以描述为:
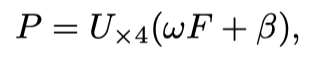
其中是预测的掩码。N是预测实例数。是一个4倍的上采样操作。最后,应用矩阵NMS得到最终实例。
3.5 Loss Function
在训练期间,总损失函数可以写成:
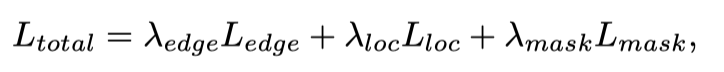
其中,是边缘损失,用于监督CFF中不同级别的边缘。边缘损失可定义为,其中j表示用于监督的边缘特征的总级别。是边缘损失的权重,默认设置为1。
由于CIS任务是类别不可知的,因此作者使用每个位置中伪装存在的置信度()与实例分割中的分类置信度进行比较。此外,由Focal Loss实现,由Dice损失计算,用于分割。和分别设置为1和3,以平衡总损失。
04
实验

Transformer的深度是影响基于Transformer的模型的性能和效率的关键因素。作者在LST中尝试了不同数量的编码器和解码器层的多种组合,以优化OSFormer的性能。如表所示。如上表所示,三层编码器不足以使OSFormer的性能最大化。AP最高的情况为编码器数量为6,解码器数量为3。

作者利用从ResNet-50中提取的多级特征作为LST的输入。为了更准确地捕捉不同尺度下的伪装,同时保持模型效率,作者在主干中结合了不同数量的特征,包括C3-C5、C2-C5、C3-C6和C2-C6。在上表中,可以观察到C3-C5的组合以最少的参数和训练显存实现了强大的性能。

对象查询在transformer架构中对于密集预测任务至关重要。如上表所示,本文的位置引导查询明显优于其他查询设计。这说明了在查询中插入有监督的全局特征对于有效回归不同伪装线索和定位实例至关重要。
此外,作者还比较了三种策略的学习能力。可以发现,本文的位置引导查询方案在早期训练阶段具有更快的收敛速度,并且最终的收敛性也优于其他两种模型。它还表明,位置引导查询可以有效地利用全局特征,通过交叉注意机制在不同位置捕获伪装信息。

在CFF模块中,多尺度输入特征直接影响通过融合操作的掩码特征F的质量。为了探索ResNet-50和LST编码器的最佳融合方案,作者在上表中进行了不同的组合。通过将C2、T3、T4和T5馈入CFF模块来获得最佳结果。

作者在上图中可视化了输入到CFF模块的每个比例的特征和掩码特征F。

上表展示了不同Backbone下的实验结果。

为了提高OSFormer的应用价值,作者提供了一个名为OSFormer-550的实时版本。具体来说,作者将输入短边调整为550,同时将LST编码器层减少为3层。如上表所示,尽管AP值下降到36%,但推理时间增加到25.8fps,参数和浮点数也显著改善。
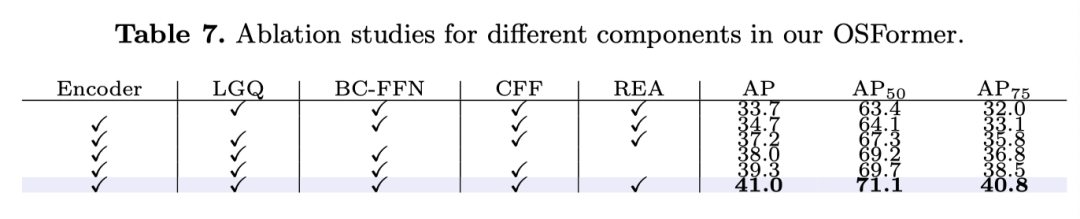
上表展示了本文提出的不同模块的有效性。

如上表所示,尽管CIS任务具有挑战性,但本文的OSFormer在所有指标上仍优于其他竞争对手。特别是,OSFormer的AP分数大大高于排名第二的SOLOv2。理想的结果应归因于本文的LST,因为它提供了更高级别的全局特征,并与LST解码器中不同位置的伪装线索相互作用。
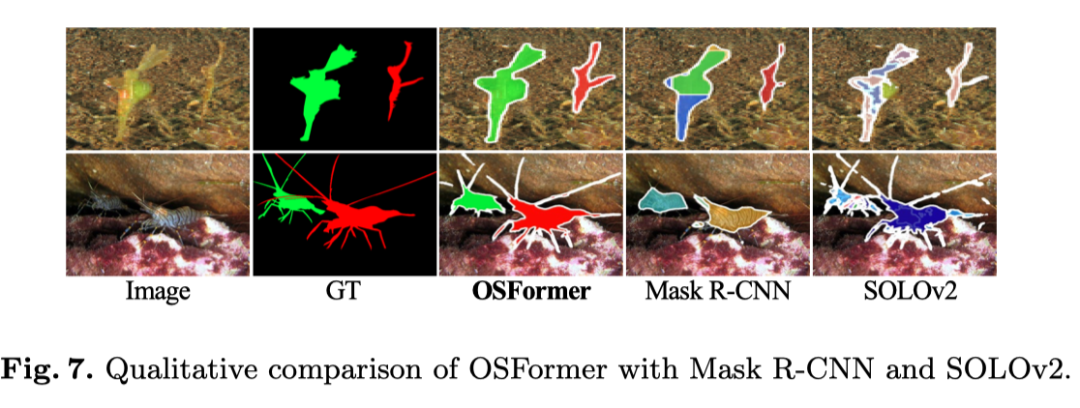
为了验证OSFormer的有效性,作者还在上图中展示了两个具有代表性的可视化结果。具体来说,顶部样本表明,OSFormer可以在多个实例中轻松区分伪装。底部结果表明,本文的方法优于捕捉细长边界,这可以归因于本文的REA模块增强了边缘特征。总的来说,与其他方法的可视化结果相比,OSFormer能够克服更具挑战性的情况并获得良好的性能。
05
总结
本文提出了一种新的位置感知单阶段Transformer框架,称为OSFormer,用于伪装实例分割(CIS)。OSFormer包含一个高效的位置感知Transformer,用于捕捉全局特征并动态回归伪装实例的位置和主体。作为第一个一阶段自底向上的CIS框架,作者进一步设计了从粗到精的融合,以整合多尺度特征并突出伪装边缘以产生全局特征。
大量实验结果表明,OSFormer的性能优于所有其他已知模型。此外,OSFormer只需要约3000张图像进行训练,并且收敛速度很快。它可以轻松灵活地扩展到具有较小训练样本的其他下游视觉任务。
参考资料
[1]https://arxiv.org/abs/2207.02255
[2]https://github.com/PJLallen/OSFormer
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「实例分割」交流群备注:分割

边栏推荐
猜你喜欢

AcWing 1282. 搜索关键词 题解((AC自动机)Trie+KMP)+bfs)
Graham‘s Scan法求解凸包问题

2022年必读的12本机器学习书籍推荐

Huawei's top engineers lasted nine years "anecdotal stories network protocol" PDF document summary, is too strong
新型电信“套路”,我爸中招了!

每日练习------随机产生一个1-100之间的整数,看能几次猜中。要求:猜的次数不能超过7次,每次猜完之后都要提示“大了”或者“小了”。
![[pytorch] pytorch automatic derivation, Tensor and Autograd](/img/99/c9632a7d3f70a13e1e26b9aa67b8b9.png)
[pytorch] pytorch automatic derivation, Tensor and Autograd

二分查找的细节坑
![[TypeScript]OOP](/img/d7/b3175ab538906ac1b658a9f361ba44.png)
[TypeScript]OOP
SringMVC中个常见的几个问题
随机推荐
宁波大学NBU IT项目管理期末考试知识点整理
After Effects 教程,如何在 After Effects 中调整过度曝光的快照?
The article you worked so hard to write may not be your original
After Effects tutorial, How to adjust overexposed snapshots in After Effects?
AcWing 1282. Search Keyword Problem Solution ((AC Automata) Trie+KMP)+bfs)
动态规划之线性dp(上)
Masterless replication system (1) - write DB when node fails
组合学笔记(六)局部有限偏序集的关联代数,Möbius反演公式
20.支持向量机—数学原理知识
Huawei's top engineers lasted nine years "anecdotal stories network protocol" PDF document summary, is too strong
MySQL multi-table union query
无主复制系统(2)-读写quorum
智能垃圾桶(九)——震动传感器(树莓派pico实现)
联邦学习:联邦场景下的多源知识图谱嵌入
flutter设置statusbar状态栏的背景颜色和 APP(AppBar)内部颜色一致方法。
Golang go-redis cluster模式下不断创建新连接,效率下降问题解决
多数据中心操作和检测并发写入
useragent在线查找
【Yugong Series】July 2022 Go Teaching Course 022-Dictionary of Go Containers
牛客网刷题(一)