当前位置:网站首页>Masterless replication system (1) - write DB when node fails
Masterless replication system (1) - write DB when node fails
2022-07-31 16:39:00 【Huawei cloud】
The idea of single-master and multi-master replication is that the client sends a write request to a master node, and the DB system is responsible for copying the write request to other replicas.The master node decides the write order, and the slave nodes apply the write logs sent by the master node in the same order.
Some data storage systems use a different design: abandoning the primary node, allowing any replica to accept writes directly from clients.The earliest replicated data systems were masterless (or called decentralized replication, centerless replication), but later in the era of relational database dominance, this idea was almost forgotten.After Amazon used it for its in-house Dynamo system[^vi], it was once again a popular DB architecture.Riak, Cassandra, and Voldemort are all open source data stores with a masterless replication model inspired by Dynamo, so such databases are also known as Dynamo style.
[^vi]: Dynamo is not available for users outside of Amazon.Confusingly, AWS offers a managed database product called DynamoDB that uses a completely different architecture: it's based on single-leader replication.
In some unowned implementations, the client sends write requests directly to multiple replicas, while in other implementations, there is a coordinator node that writes on behalf of the client, but unlike the master node's database,The coordinator is not responsible for maintaining write order.This design difference has profound implications for how DBs are used.
4.1 Write DB when node fails
Assuming a three-replica DB, one of which is currently unavailable, perhaps rebooting to install system updates.Under the primary node replication model, to continue processing writes, a failover needs to be performed.
Without a master model, there is no such switch.
Figure-10: Client (user 1234) sends write requests to three replicas in parallel, two available replicas accept writes, and the unavailable replica cannot handle it.Assuming two successful confirmations of the three copies, the user 1234 can consider the writing to be successful after receiving the two confirmation responses.The case where one of the replicas cannot be written can be completely ignored.
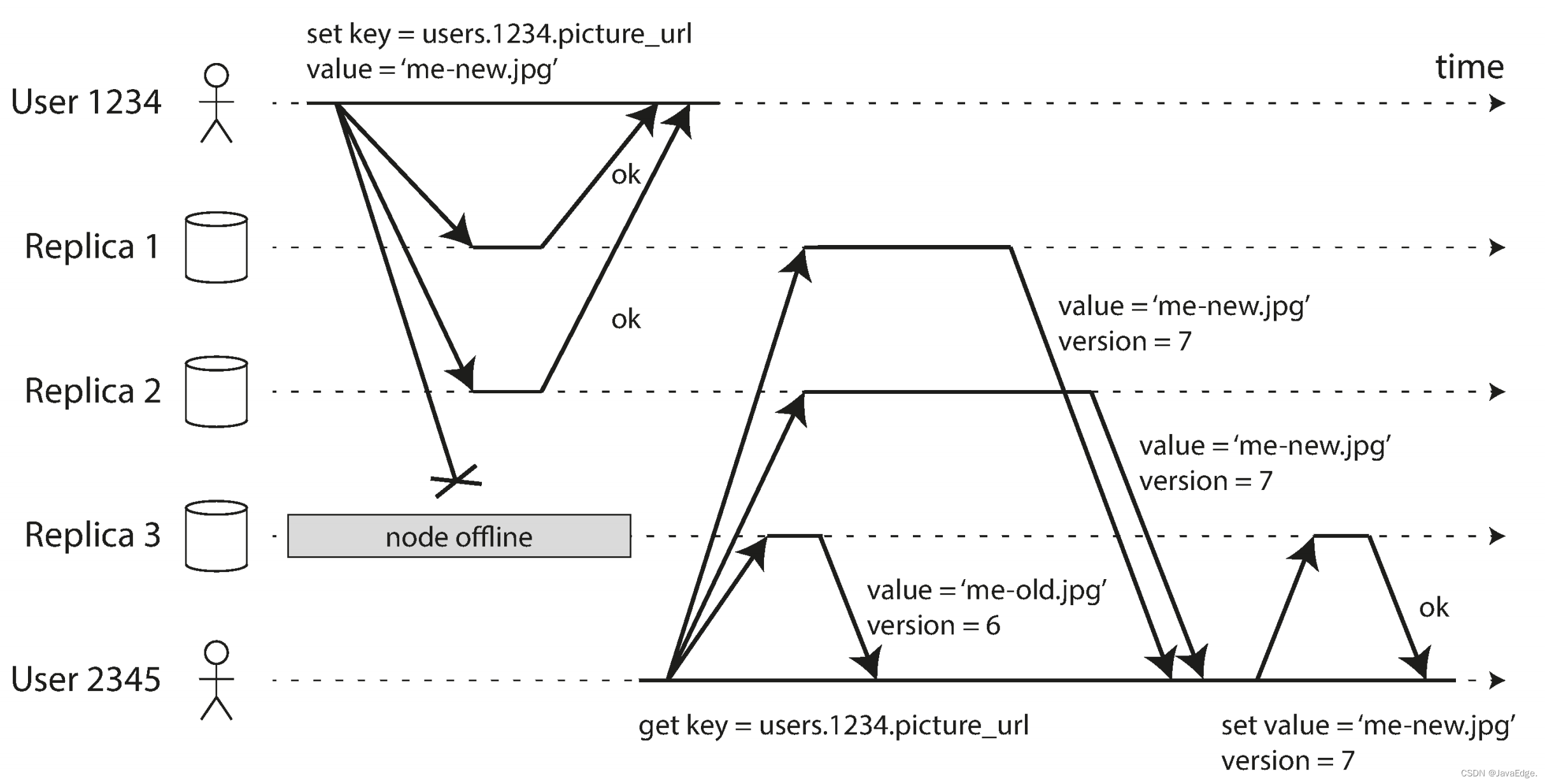
The failed node comes back online and clients start reading it.Any writes that occur during a node failure are not yet synchronized at that node, so reads may get stale data.
To solve this problem, when a client reads data from the DB, it does not send a request to 1 replica, but to multiple replicas in parallel.Clients may get different responses from different nodes, i.e. the latest value from one node and the old value from another node.The version number can be used to determine which value is updated.
4.1.1 Read Repair and Anti-Entropy
The replication model should ensure that all data is eventually replicated to all replicas.After a failed node comes back online, how does it catch up with missed writes?
Dynamo-style data storage system mechanism:
Read repair
When a client reads multiple copies in parallel, an expired return value can be detected.As shown in Figure-10, user 2345 gets version 6 from R3 and version 7 from replicas 1 and 2.The client can determine that replica 3 is the expired value, and then write the new value to that replica.Suitable for read-intensive scenarios
Anti-entropy process
Some data stores have background processes that constantly look for data differences between replicas, copying any missing data from one replica to another.Unlike replicated logs based on primary replication, this anti-entropy process does not guarantee any particular order of replicated writes and introduces significant synchronization lag
Not all systems implement either scheme.For example, Voldemort currently has no anti-entropy process.If there is no anti-entropy process, because [read repair] is only possible to perform repair when a read occurs, those rarely accessed data may be lost in some replicas and can no longer be detected, thus reducing the durability of writes.
边栏推荐
- 2020 WeChat applet decompilation tutorial (can applet decompile source code be used)
- [Meetup Preview] OpenMLDB+OneFlow: Link feature engineering to model training to accelerate machine learning model development
- Dialogue with Zhuang Biaowei: The first lesson of open source
- MySQL基础篇【单行函数】
- Applicable scenario of multi-master replication (2) - client and collaborative editing that require offline operation
- Qt实战案例(54)——利用QPixmap设计图片透明度
- 多主复制的适用场景(2)-需离线操作的客户端和协作编辑
- go图书管理系统
- 6. 使用 Postman 工具高效管理和测试 SAP ABAP OData 服务
- LevelSequence源码分析
猜你喜欢

基于ABP实现DDD

Qt实战案例(54)——利用QPixmap设计图片透明度
Graham's Scan method for solving convex hull problems

How to switch remote server in gerrit

【网络通信三】研华网关Modbus服务设置

t-sne 数据可视化网络中的部分参数+

.NET 20th Anniversary Interview - Zhang Shanyou: How .NET technology empowers and changes the world
C language "the third is" upgrade (mode selection + AI chess)

MySQL基础篇【单行函数】
After Effects 教程,如何在 After Effects 中调整过度曝光的快照?
随机推荐
最后写入胜利(丢弃并发写入)
adb shell error error: device unauthorized
ML.NET related resources
多主复制下处理写冲突(3)-收敛至一致的状态及自定义冲突解决逻辑
LeetCode_733_Image rendering
阿里三面:MQ 消息丢失、重复、积压问题,如何解决?
【网络通信三】研华网关Modbus服务设置
Premiere Pro 2022 for (pr 2022)v22.5.0
Snake Project (Simple)
SringMVC中个常见的几个问题
网站漏洞修复服务商关于越权漏洞分析
多主复制的适用场景(1)-多IDC
使用互相关进行音频对齐
Graham's Scan method for solving convex hull problems
研发过程中的文档管理与工具
ansible学习笔记02
第二届中国PWA开发者日
[Meetup Preview] OpenMLDB+OneFlow: Link feature engineering to model training to accelerate machine learning model development
Implementing DDD based on ABP
Summary of the implementation method of string inversion "recommended collection"