当前位置:网站首页>NEON优化:log10函数的优化案例
NEON优化:log10函数的优化案例
2022-07-06 17:22:00 【来知晓】
NEON优化系列文章:
背景
在进行音频样点计算中,经常需要将振幅值转换到对数域,涉及到大量的log运算,这里总结下提升log运算速度的一些优化方法。
log10功能描述
- 输入:x>0,浮点数
- 输出:log10(x),浮点数
- 峰值误差(Peak Error):~0.000465339053%
- 均方根误差(RMS Error):~0.000008%
优化方法
对log10运算进行NEON优化的基本依据是:log10运算可用泰勒近似展开成多项式计算,然后根据IEEE浮点存储格式,对相关数据进行查表运算,转化为乘加运算,加快运算速度。
多项式系数展开为如下表:
const float LOG10_TABLE[8] = {
// 8长度
-0.99697286229624F, // a0
-1.07301643912502F, // a4
-2.46980061535534F, // a2
-0.07176870463131F, // a6
2.247870219989470F, // a1
0.366547581117400F, // a5
1.991005185100089F, // a3
0.006135635201050F, // a7
};
优化版本1
优化方法为从对数运算转化为查表和多项式拟合,计算过程展开分析如下:
- step1
- A = a4 * x + a0
- B = a5 * x + a1
- C = a6 * x + a2
- D = a7 * x + a3
- step2
- A := A + B * x^2
- C := C + D * x^2
- step3
- F = A + C * x^4 = a0 + a4 * x + a2 * x^2 + a6 * x^3 + a1 * x^4 + a5 * x^5 + a3 * x^6 + a7 * x^7
- 公共算子:
x, x^2, x^4
从原理到代码实现,代码如下:
float Log10FloatNeonOpt(float fVarin)
{
float fTmpA, fTmpB, fTmpC, fTmpD, fTmpxx;
int32_t iTmpM;
union {
float fTmp;
int32_t iTmp;
} aVarTmp1;
// extract exponent
aVarTmp1.fTmp = fVarin;
iTmpM = (int32_t)((uint32_t)aVarTmp1.iTmp >> 23); // 乘2^-23缩小, 取 32-9=23的高9位
iTmpM = iTmpM - 127; // 减2^8-1=127,取反码
aVarTmp1.iTmp = aVarTmp1.iTmp - (int32_t)((uint32_t)iTmpM << 23); // 减去乘2^23复原的值, 取出指数
// Taylor Polynomial (Estrins)
fTmpxx = aVarTmp1.fTmp * aVarTmp1.fTmp;
fTmpA = (LOG10_TABLE[4] * aVarTmp1.fTmp) + (LOG10_TABLE[0]); // 4: a1 0: a0
fTmpB = (LOG10_TABLE[6] * aVarTmp1.fTmp) + (LOG10_TABLE[2]); // 6: a3 2: a2
fTmpC = (LOG10_TABLE[5] * aVarTmp1.fTmp) + (LOG10_TABLE[1]); // 5: a5 1: a4
fTmpD = (LOG10_TABLE[7] * aVarTmp1.fTmp) + (LOG10_TABLE[3]); // 7: a7 3: a6
fTmpA = fTmpA + fTmpB * fTmpxx;
fTmpC = fTmpC + fTmpD * fTmpxx;
fTmpxx = fTmpxx * fTmpxx;
aVarTmp1.fTmp = fTmpA + fTmpC * fTmpxx;
// add exponent
aVarTmp1.fTmp = aVarTmp1.fTmp + ((float)iTmpM) * (0.3010299957f);
return aVarTmp1.fTmp;
}
优化版本2
优化方法为将版本1中的内部乘加运算并行起来做。
float Log10FloatNeonOpt(float fVarin)
{
float fTmpxx;
int32_t iTmpM;
union {
float fTmp;
int32_t iTmp;
} aVarTmp1;
// extract exponent
aVarTmp1.fTmp = fVarin;
iTmpM = (int32_t)((uint32_t)aVarTmp1.iTmp >> 23); // 乘2^-23缩小, 取 32-9=23的高9位
iTmpM = iTmpM - 127; // 减2^8-1=127,取反码
aVarTmp1.iTmp = aVarTmp1.iTmp - (int32_t)((uint32_t)iTmpM << 23); // 减去乘2^23复原的值, 取出指数
// Taylor Polynomial (Estrins)
fTmpxx = aVarTmp1.fTmp * aVarTmp1.fTmp;
/* origin code fTmpA = (LOG10_TABLE[4] * aVarTmp1.fTmp) + (LOG10_TABLE[0]); // 4: a1 0: a0 fTmpB = (LOG10_TABLE[6] * aVarTmp1.fTmp) + (LOG10_TABLE[2]); // 6: a3 2: a2 fTmpC = (LOG10_TABLE[5] * aVarTmp1.fTmp) + (LOG10_TABLE[1]); // 5: a5 1: a4 fTmpD = (LOG10_TABLE[7] * aVarTmp1.fTmp) + (LOG10_TABLE[3]); // 7: a7 3: a6 fTmpA = fTmpA + fTmpB * fTmpxx; fTmpC = fTmpC + fTmpD * fTmpxx; */
// optcode: A C B D
float32x4_t vf32x4fTmpACBD, vf32x4fTmp1, vf32x4fTmp2;
vf32x4fTmp1 = vld1q_f32(&LOG10_TABLE[0]);
vf32x4fTmp2 = vld1q_f32(&LOG10_TABLE[4]); // 4 is for sth
vf32x4fTmpACBD = vmlaq_n_f32(vf32x4fTmp1, vf32x4fTmp2, aVarTmp1.fTmp); // fTmp1 + fTmp2 * fTmp
float32x2_t vf32x2fTmpAC, vf32x2fTmpBD;
vf32x2fTmpAC = vget_low_f32(vf32x4fTmpACBD);
vf32x2fTmpBD = vget_high_f32(vf32x4fTmpACBD);
vf32x2fTmpAC = vmla_n_f32(vf32x2fTmpAC, vf32x2fTmpBD, fTmpxx); // fTmpAC + fTmpBD * fTmpxx
float tmpAC[2]; // 2 is for sth
vst1_f32(tmpAC, vf32x2fTmpAC);
fTmpxx = fTmpxx * fTmpxx;
aVarTmp1.fTmp = tmpAC[0] + tmpAC[1] * fTmpxx;
// add exponent
aVarTmp1.fTmp = aVarTmp1.fTmp + ((float)iTmpM) * (0.3010299957f);
return aVarTmp1.fTmp;
}
优化版本3
对原函数Log10FloatNeonOpt()做接口扩展,使外部调用时可以一次输入4个x值,计算4个log10的运算结果。
代码中,假设输入/输出都在NEON寄存器中读写,均为4个浮点寄存器值。
#define PARALLEL_NUM (4)
#define EXP_SHIFT_NUM (23)
float32x4_t Log10FloatX4NeonOpt(float32x4_t vf32x4Varin)
{
int32x4_t vs32x4VarTmpI = vreinterpretq_s32_f32(vf32x4Varin); // aVarTmp1.iTmp
uint32x4_t vu32x4VarTmpU = vreinterpretq_u32_s32(vs32x4VarTmpI); // (uint32_t)aVarTmp1.iTmp
vu32x4VarTmpU = vshrq_n_u32(vu32x4VarTmpU, EXP_SHIFT_NUM); // (uint32_t)aVarTmp1.iTmp >> 23
int32x4_t vs32x4TmpM = vreinterpretq_s32_u32(vu32x4VarTmpU); // (int32_t)((uint32_t)aVarTmp1.iTmp >> 23)
int32x4_t vs32x4RevsCode = vdupq_n_s32(-127); // -127 is shift
vs32x4TmpM = vaddq_s32(vs32x4TmpM, vs32x4RevsCode); // iTmpM = iTmpM - 127, used later
vu32x4VarTmpU = vreinterpretq_u32_s32(vs32x4TmpM);
vu32x4VarTmpU = vshlq_n_u32(vu32x4VarTmpU, EXP_SHIFT_NUM); // (uint32_t)iTmpM << 23
int32x4_t vs32x4SubVal = vreinterpretq_s32_u32(vu32x4VarTmpU);
vs32x4VarTmpI = vsubq_s32(vs32x4VarTmpI, vs32x4SubVal); // aVarTmp1.iTmp-(int32_t)((uint32_t)iTmpM<<23)
float32x4_t vf32x4TVarTmpF = vreinterpretq_f32_s32(vs32x4VarTmpI);
float32x4_t vf32x4TmpXX = vmulq_f32(vf32x4TVarTmpF, vf32x4TVarTmpF);
float32x4_t vf32x4TmpXXXX = vmulq_f32(vf32x4TmpXX, vf32x4TmpXX);
// input: vf32x4TVarTmpF vs32x4TmpM vf32x4TmpXX vf32x4TmpXXXX
float32x4x4_t vf32x4x4fTmpACBD;
float32x4_t vf32x4fTmp1, vf32x4fTmp2;
float fTmp[PARALLEL_NUM];
vst1q_f32(fTmp, vf32x4TVarTmpF);
vf32x4fTmp1 = vld1q_f32(&LOG10_TABLE[0]);
vf32x4fTmp2 = vld1q_f32(&LOG10_TABLE[4]); // 4 is for sth
vf32x4x4fTmpACBD.val[0] = vmlaq_n_f32(vf32x4fTmp1, vf32x4fTmp2, fTmp[0]); // fTmp1 + fTmp2 * fTmp
vf32x4x4fTmpACBD.val[1] = vmlaq_n_f32(vf32x4fTmp1, vf32x4fTmp2, fTmp[1]);
vf32x4x4fTmpACBD.val[2] = vmlaq_n_f32(vf32x4fTmp1, vf32x4fTmp2, fTmp[2]); // 2 is ACBD[2]
vf32x4x4fTmpACBD.val[3] = vmlaq_n_f32(vf32x4fTmp1, vf32x4fTmp2, fTmp[3]); // 3 is ACBD[3]
// transpose
// a1 b1 c1 d1 => a1 a2 a3 a4
// a2 b2 c2 d2 => b1 b2 b3 b4
// ...
// a4 b4 c4 d4 => d1 d2 d3 d4
float32x4x2_t vf32x4x2fTmpACBD01 = vtrnq_f32(vf32x4x4fTmpACBD.val[0], vf32x4x4fTmpACBD.val[1]);
float32x4x2_t vf32x4x2fTmpACBD23 = vtrnq_f32(vf32x4x4fTmpACBD.val[2], vf32x4x4fTmpACBD.val[3]); // 2, 3 is row b/d
float32x4x2_t vf32x4x2fTmpACBD02 = vuzpq_f32(vf32x4x2fTmpACBD01.val[0], vf32x4x2fTmpACBD23.val[0]); // row02
float32x4x2_t vf32x4x2fTmpACBD13 = vuzpq_f32(vf32x4x2fTmpACBD01.val[1], vf32x4x2fTmpACBD23.val[1]); // row13
vf32x4x2fTmpACBD02 = vtrnq_f32(vf32x4x2fTmpACBD02.val[0], vf32x4x2fTmpACBD02.val[1]);
vf32x4x2fTmpACBD13 = vtrnq_f32(vf32x4x2fTmpACBD13.val[0], vf32x4x2fTmpACBD13.val[1]);
vf32x4x4fTmpACBD.val[0] = vf32x4x2fTmpACBD02.val[0]; // a0 a1 a2 a3
vf32x4x4fTmpACBD.val[2] = vf32x4x2fTmpACBD02.val[1]; // 2 is row c
vf32x4x4fTmpACBD.val[1] = vf32x4x2fTmpACBD13.val[0];
vf32x4x4fTmpACBD.val[3] = vf32x4x2fTmpACBD13.val[1]; // d0 d1 d2 d3, row d
// A = A + B * xx, C = C + D * xx
float32x4_t vf32x4fTmpA = vmlaq_f32(vf32x4x4fTmpACBD.val[0], vf32x4x4fTmpACBD.val[2], vf32x4TmpXX); // 2 row b
float32x4_t vf32x4fTmpC = vmlaq_f32(vf32x4x4fTmpACBD.val[1], vf32x4x4fTmpACBD.val[3], vf32x4TmpXX); // 3 row d
vf32x4TVarTmpF = vmlaq_f32(vf32x4fTmpA, vf32x4fTmpC, vf32x4TmpXXXX);
// add exponent
float32x4_t vf32x4fTmpM = vcvtq_f32_s32(vs32x4TmpM);
vf32x4TVarTmpF = vmlaq_n_f32(vf32x4TVarTmpF, vf32x4fTmpM, (0.3010299957f));
return vf32x4TVarTmpF;
}
小结
本文以log10函数的NEON优化为例,总结了三种不同的优化方式,可根据具体场景结合使用。其中,寄存器内4x4矩阵的转置运算,用到了博客《NEON优化3:矩阵转置的指令优化案例》提到的方法。
值得注意的是,log10/log2的运算能力并无差别,原理类似,只是查表中不同的系数,如果需要log2的结果,可以用换底公式转换。
如果想举一反三,类似地,也可用这种方法去优化powf函数的计算。
边栏推荐
- 学习光线跟踪一样的自3D表征Ego3RT
- UI control telerik UI for WinForms new theme - vs2022 heuristic theme
- 建立自己的网站(17)
- 深度学习简史(二)
- 重上吹麻滩——段芝堂创始人翟立冬游记
- Part V: STM32 system timer and general timer programming
- C9高校,博士生一作发Nature!
- Link sharing of STM32 development materials
- 迈动互联中标北京人寿保险,助推客户提升品牌价值
- Provincial and urban level three coordinate boundary data CSV to JSON
猜你喜欢
【批处理DOS-CMD命令-汇总和小结】-字符串搜索、查找、筛选命令(find、findstr),Find和findstr的区别和辨析
Dell Notebook Periodic Flash Screen Fault

Maidong Internet won the bid of Beijing life insurance to boost customers' brand value
界面控件DevExpress WinForms皮肤编辑器的这个补丁,你了解了吗?

力扣1037. 有效的回旋镖
![[Niuke] [noip2015] jumping stone](/img/9f/b48f3c504e511e79935a481b15045e.png)
[Niuke] [noip2015] jumping stone
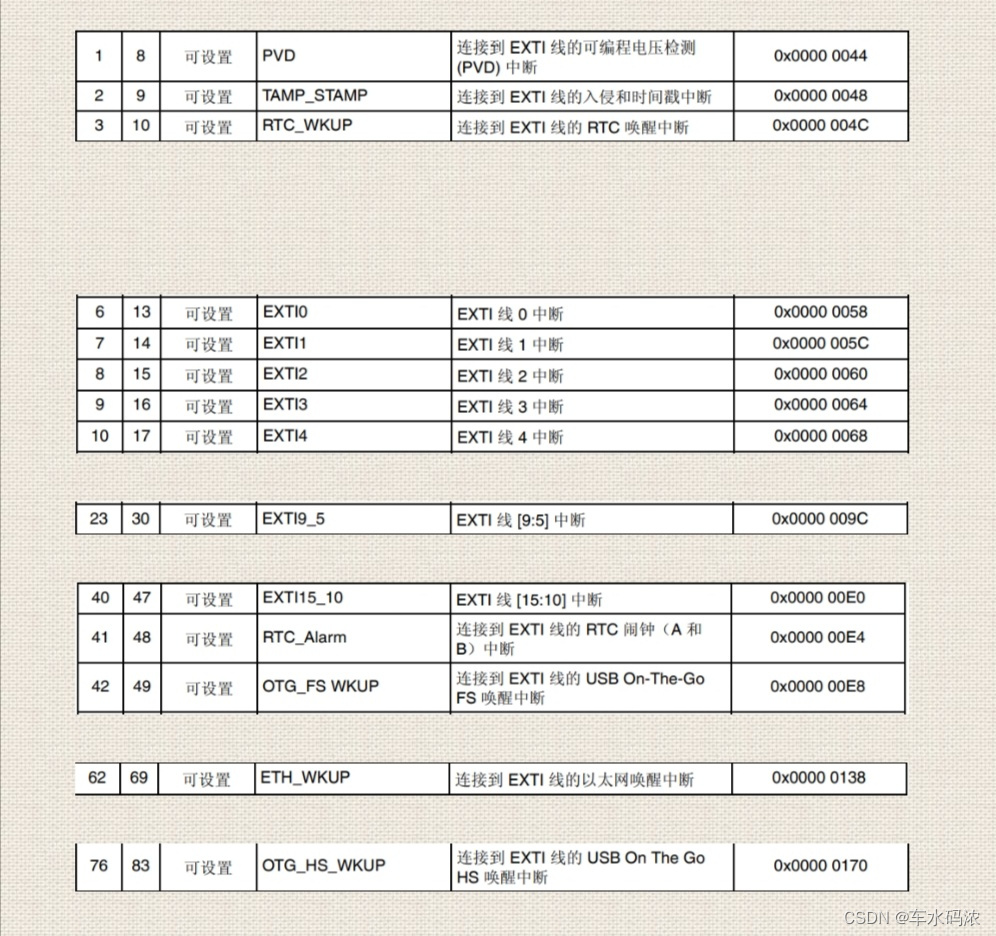
第四篇,STM32中断控制编程
Part 7: STM32 serial communication programming
Configuring OSPF basic functions for Huawei devices
Learn to use code to generate beautiful interface documents!!!
随机推荐
mysql: error while loading shared libraries: libtinfo. so. 5: cannot open shared object file: No such
【JVM调优实战100例】04——方法区调优实战(上)
Data type of pytorch tensor
Levels - UE5中的暴雨效果
力扣1037. 有效的回旋镖
Tensorflow 1.14 specify GPU running settings
随时随地查看远程试验数据与记录——IPEhub2与IPEmotion APP
[Batch dos - cmd Command - Summary and Summary] - String search, find, Filter Commands (FIND, findstr), differentiation and Analysis of Find and findstr
.class文件的字节码结构
Dynamic planning idea "from getting started to giving up"
Part V: STM32 system timer and general timer programming
pyflink的安装和测试
Part VI, STM32 pulse width modulation (PWM) programming
Configuring OSPF basic functions for Huawei devices
[Niuke classic question 01] bit operation
Interface (interface related meaning, different abstract classes, interface callback)
How do novices get started and learn PostgreSQL?
paddlehub应用出现paddle包报错的问题
腾讯云 WebShell 体验
第六篇,STM32脉冲宽度调制(PWM)编程