当前位置:网站首页>深度学习简史(二)
深度学习简史(二)
2022-07-06 17:04:00 【老齐】
深度学习简史(二)
本文系列文章《深度学习简史》第二部分
2018 - 2020年代
自 2017 年以来,深度学习算法、应用和技术突飞猛进。为了清楚起见,之后的发展是按类别划分的。在每个类别中,我们都会回顾主要趋势和一些最重要的突破。
应用在图像上的 Transformers
自从 transformers 在 NLP 中大显身手之后,一些具有开创者就迫不及待地把 attention 应用在图像上了。几名谷歌的研究人员发表了一篇名为《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》^{[7]} 的论文,文章认为,一个普通的 transformer 稍加修改后,直接用于一个图像序列,就可以实现效果良好的分类。这些研究者将他们的框架命名为 Vision Transformer,简称 ViT。在很多 CV 研究中,都会看到 ViT,截至撰写本文时,它是 Cifar-10 上最先进的分类模型。ViT 的研究者其实不是第一个将 attention 用于视觉的识别工作的,论文《Attention Augmented Convolutional Networks》^{[8]} 中的示例则更早,该论文试图将 self-attentions 与卷积相结合,从而解决卷积中的归纳偏差问题。另一个更早使用 attentions 的案例则出现在《Visual Transformers: Token-based Image Representation and Processing for Computer Vision》^{[9]} 中,它将 transformers 用于词语过滤器或图像过滤器上。这两篇论文和许多没有在这里列出的论文共同推动了基础框架的发展,但没有超越 ViT ,所以参考资料 [7] 是业界重要文献之一,最伟大的创举在于 ViT 开发者直接用图像作为输入,不对 transformer 做太多改变。
ViT
上面的图片来自于参考资料 [7] 的论文,除了直接用图像作为输入外,另外两个强悍特征也引人注目:并行和可伸缩性。当然,ViT 也不是十全十美,比如早期在目标检测和图像分割上就表现不佳,直到后来引入了 Swin Transformer 之后才有所好转。Swin Transformer 的核心亮点在于:它在连续的 attention 层之间使用了滑动窗口。下图描述了Swin Transformer 和 ViT 在构建分层特征映射的方式上的区别。
Vison Transformers 是近期最令人兴奋的研究领域之一,更多内容可以在参考资料 [10] 中查阅,这方面的前沿研究还有 CrossViT
^{[11]}、ConViT^{[12]} 和 SepViT^{[13]} 。
V-L 模型
V-L 模型是指同时涉及到视觉(vision)和语言(language)的模型,也称为多模型(multi-models),例如,根据文本内容生成与之匹配的图像、根据图像生成对其文本描述、根据图像内容生成相关答案等。transformer 在视觉和语言领域的成功很大程度上促成了单个统一网络的多模型。事实上,所有的视觉和语言任务都使用了预训练技术。在计算机视觉中,预训练通常是用大型数据集(例如 ImageNet)进行训练;在 NLP 中,一般对网络进行微调,通常是基于 BERT。要了解更多关于 V-L 任务的预训练,请阅读论文《A Survey of Vision-Language Pre-Trained Models》^{[14]} 。另外一篇论文,对这方面的发展做了表好的概括,请查阅参考资料 [15] 的文章 《Trends in Integration of Vision and Language Research: A Survey of Tasks, Datasets, and Methods》。
最近,V-L 模型的典型代表 OpenAI 发布了新版本 DALL·E 2 ,它可以从文本生成逼真的图像。在众多竞争者中,DALL·E 2在分辨率、图像标题匹配和真实感方面都非常出色。下图的示例是使用DALL·E 2 生成的一些图片。
语言大模型
实现自然语言处理的语言模型有很多用途,如预测句子中的下一个单词或字符;总结一份文件;将文本内容从一种语言翻译成另一种语言;语音识别或将一段文本转换为语音,等等。对于 transformers ,不论是谁,都关注它在 NLP 中的应用。Transformer 是 21 世纪的第一个 10 年中最伟大的发明之一。如果有足够的数据和计算,大模型的效果总是令人震惊和惊羡的。在过去的 5 年里,语言模型规模一直在不断地扩大。论文《attention is all you need》^{[6]} 发表一年以后,一切都开始改变。2018年,OpenAI 发布了 GPT (Generative Pre-trained Transformer),这是当时最大的语言模型之一。一年后,OpenAI 又发布了 GPT-2,这是一个拥有 15 亿个参数的模型。又过了一年,他们发布了拥有 1750 亿个参数的 GPT-3,并且在 570GB 的文本上训练了 GPT-3。整个模型采用 1750 亿个参数,大小为 700GB。 GPT-3 到底有多大?LAMBDA实验室做了这样的估算^{[16]} ,如果用当前市场价格最低的提供 GPU 的云服务来训练它,需要花费 366 年和 460 万美元。然而,GPT-n系列只是一个开始,还有其他大模型。它们的大小接近 GPT-3 或者更大。例如:NVIDIA Megatron-LM 有83亿个参数。最新的 DeepMind Gopher 有2800亿个参数。2022年4月12日,DeepMind 发布了另一个有着700亿个参数的语言模型。这个模型名为 Chinchilla,尽管它比 Gopher、GPT-3 和 Megattron-turing NLG(5300亿个参数)更小,但它的性能超过了许多语言模型。Chinchilla 的论文表明:现有的语言模型训练不足,若将模型的大小翻倍,数据也应该翻倍。与之相当的,谷歌PaLM(Pathways Language Model)几乎在同一时间,它包括 5400 亿个参数。
Chinchilla 模型
这里要补充一个应该引起中文语言处理的模型:文心大模型,这是百度推出了。
代码生成模型
代码生成模型,即可以编程的人工智能系统,它可以编写特定的一段代码、或者根据自然语言或文本的要求生成函数。你可能会猜到,现代的代码生成器都是基于 Transformer 的。很久以来,就如同我们希望计算机能做其他事情一样,也在研究如何让计算机能自己编写程序。这方面的工作首先因为 OpenAI 发布了 Codex 之后得备受关注。Codex 是基于 GitHub 公开代码库和其他源代码训练过的GPT-3。OpenAI 表示:“OpenAI Codex 是一个通用编程模型,它基本上可以用于任何编程任务(尽管结果可能会有所不同)。我们已经成功地将它用于翻译、解释和重构代码。但我们知道,我们所能做的只是冰山一角。” Codex 现在支持 GitHub Copilot ,这是一款 AI 结对编程工具。
OpenAI 发布 Codex 几个月后,DeepMind 发布了 AlphaCode ,这是一种基于 transformer 的语言模型,可以解决竞争性编程比赛中的问题。AlphaCode 发布的博客称,“在编程比赛中,AlphaCode 通过解决需要批判性思维、逻辑、算法、编码和自然语言理解相结合的新问题,在参与者中获得了大约前 54% 的排名。” 解决编程问题非常困难。正如 Dzmitry 所说,超越人类水平还有若干光年之遥。不久前,Meta AI 的科学家发布了 InCoder,这是一种可以生成和编辑程序的生成模型。
回到感知机
在卷积神经网络和 transformer 兴起之前的很长一段时间里,深度学习都是围绕感知机发展的。后来,卷积神经网络在各种识别任务中表现出了优异的性能,取代了多层感知器。从 Vision Transformers 目前的状况来看,仍然是是很有前途的框架。但是感知器彻底消亡了吗?可能不会。就在 2021年7月,两篇基于感知器的论文得以发表,一篇是《MLP-Mixer: An all-MLP Architecture for Vision》^{[17]} ,另一个是《Pay Attention to MLPs(gMLP)》^{[18]} 。MLP-Mixer 声称,卷积和 attention 都是非必要的,它仅使用 MLP,就能够在图像分类上取得了很高的精度。MLP-mixer 的一个重要特征是它包含两个主要的 MLP 层:一个层独立应用于图像数据,称为通道混合;另一个层则是用于各个图像,称为空间混合。gMLP 还表明,抛弃了 self-attention 和卷积后,依然可以在图像识别和NLP任务中取得很高的准确度。
MLP-Mizers和g-MLP
显然,你没有将 MLPs 应用到极致,令人着迷的是它们的确与最先进的深度网络可一决高下。
再谈卷积神经网络:面向21世纪20年代的卷积神经网络
自 2020 年以来,计算机视觉的研究一直围绕 transformers 展开。在 NLP 中,transformer 也已经成为一种规范。ViT 在图像分类方面表现优异,但在目标检测和图像分割则令人失望。随着 Swin Transformers 问世,没过多久,这些难关也被攻克。很多人都喜欢卷积神经网络,它真的很有效,我们很难放弃它们。怀着这种挚爱,一些科学家不断推动卷积神经网络的发展,进而提出了残差神经网络(ResNet)。Saining Xie和他在 Meta AI 的同事们正在致力于这项研究,他们在论文阐述研究成果,并最终得到了一个名为 ConvNeXt 的卷积网络框架。根据不同的测试标准,ConvNeXt 都取得了与Swin Transformer 相当的结果。关于 ConvNeXt 的详细内容,可以阅读参考资料 [19] 。
结论
深度学习是一个广阔天地,且日新月异,很难用较短的篇幅概括一切,此处仅仅是管中窥豹。这方面的论文浩如烟海,每个人只能了解很小的一个领域。在本文中,我们没有讨论的内容还很多,例如著名的 AlphaGo,深度学习框架、硬件加速器、图神经网络等等,还有很多很多。
参考资料
[1]. https://www.getrevue.co/profile/deeprevision/issues/a-revised-history-of-deep-learning-issue-1-1145664?continueFlag=0d4c136e098ffe282d51bc9870b62335
[2]. https://github.com/Nyandwi/ModernConvNets?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[3]. https://www.deeplearningbook.org/contents/generative_models.html?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[4]. https://www.zhihu.com/question/434784733
[5]. https://www.jiqizhixin.com/articles/2018-01-10-20
[6]. https://arxiv.org/pdf/1706.03762.pdf?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[7]. https://arxiv.org/abs/2010.11929v2?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[8]. https://arxiv.org/abs/1904.09925?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[9]j. https://arxiv.org/abs/2006.03677?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[10]. https://arxiv.org/pdf/2101.01169.pdf?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[11]. https://arxiv.org/abs/2103.14899v2?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[12]. https://arxiv.org/abs/2103.10697v2?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[13]. https://arxiv.org/abs/2203.15380v2?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[14]. https://arxiv.org/abs/2202.10936?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[15]. https://arxiv.org/abs/1907.09358?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[16]. https://lambdalabs.com/blog/demystifying-gpt-3/?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[17]. https://arxiv.org/pdf/2105.01601v4.pdf?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[18]. https://arxiv.org/pdf/2105.08050.pdf?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[19]. https://github.com/Nyandwi/ModernConvNets/blob/main/convnets/13-convnext.ipynb?utm_campaign=Deep%20Learning%20Revision&utm_medium=email&utm_source=Revue%20newsletter
边栏推荐
- QT tutorial: creating the first QT program
- 【YoloV5 6.0|6.1 部署 TensorRT到torchserve】环境搭建|模型转换|engine模型部署(详细的packet文件编写方法)
- alexnet实验偶遇:loss nan, train acc 0.100, test acc 0.100情况
- St table
- 准备好在CI/CD中自动化持续部署了吗?
- 37頁數字鄉村振興智慧農業整體規劃建設方案
- @TableId can‘t more than one in Class: “com.example.CloseContactSearcher.entity.Activity“.
- dynamic programming
- How engineers treat open source -- the heartfelt words of an old engineer
- What is time
猜你喜欢

一图看懂对程序员的误解:西方程序员眼中的中国程序员
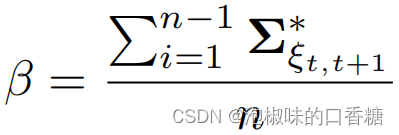
Attention slam: a visual monocular slam that learns from human attention
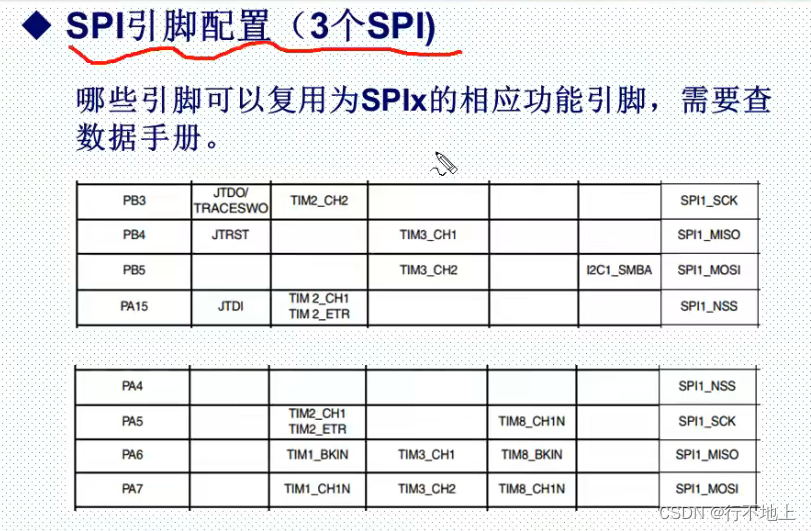
Stm32f407 ------- SPI communication
Business process testing based on functional testing

Core knowledge of distributed cache
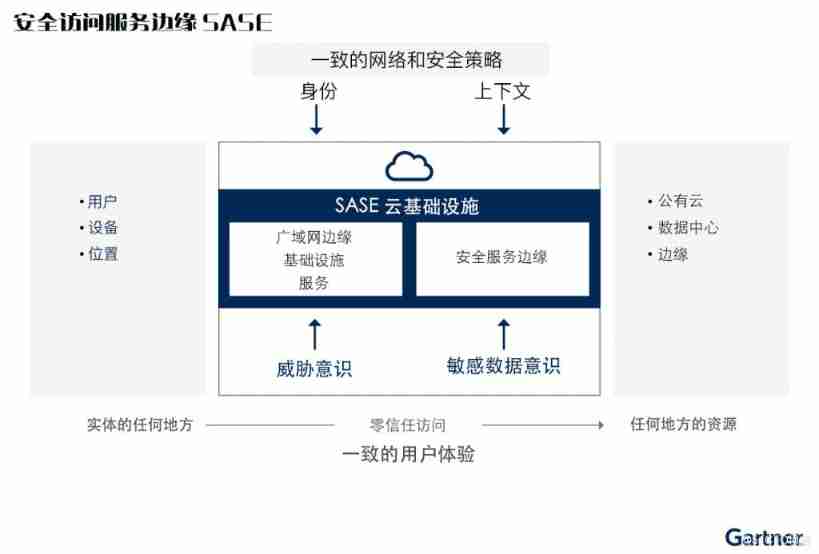
2021 SASE integration strategic roadmap (I)
Idea automatically imports and deletes package settings
Linear algebra of deep learning

Data sharing of the 835 postgraduate entrance examination of software engineering in Hainan University in 23

New feature of Oracle 19C: automatic DML redirection of ADG, enhanced read-write separation -- ADG_ REDIRECT_ DML
随机推荐
Telerik UI 2022 R2 SP1 Retail-Not Crack
集合(泛型 & List & Set & 自定义排序)
工程师如何对待开源 --- 一个老工程师的肺腑之言
【YoloV5 6.0|6.1 部署 TensorRT到torchserve】环境搭建|模型转换|engine模型部署(详细的packet文件编写方法)
Business process testing based on functional testing
Command line kills window process
一图看懂对程序员的误解:西方程序员眼中的中国程序员
Js+svg love diffusion animation JS special effects
ActiveReportsJS 3.1中文版|||ActiveReportsJS 3.1英文版
Slow database query optimization
Lombok makes ⽤ @data and @builder's pit at the same time. Are you hit?
Zynq transplant ucosiii
Leecode brushes questions to record interview questions 17.16 massagist
Configuring OSPF basic functions for Huawei devices
Leecode brush questions record sword finger offer 44 A digit in a sequence of numbers
dynamic programming
基於GO語言實現的X.509證書
Advanced learning of MySQL -- Fundamentals -- concurrency of transactions
mongodb客户端操作(MongoRepository)
fastDFS数据迁移操作记录