当前位置:网站首页>学习光线跟踪一样的自3D表征Ego3RT
学习光线跟踪一样的自3D表征Ego3RT
2022-07-06 16:56:00 【3D视觉工坊】
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

作者丨黄浴
来源丨 计算机视觉深度学习和自动驾驶
arXiv上传于2022年6月8日的论文“Learning Ego 3D Representation as Ray Tracing“,是复旦大学张力教授团队的工作。

自动驾驶感知模型旨在将多个摄像头的3D语义表征集中提取到自车的BEV坐标系中,为下游规划器奠定基础。现有的感知方法通常依赖于对整个场景进行易出错的深度估计,或者在没有目标几何结构的情况下学习稀疏的虚拟3D表征,这两种方法在性能和/或能力上仍然有限。
本文提出一种端到端架构,Ego3RT,用于从任意数量无约束摄像头视图学习自3D表征。受光线追踪(ray-tracing)原理的启发,设计一个“想象眼(imaginary eye)”的极化网格作为可学习的自3D表征,并结合“3D到2D投影”,利用自适应注意机制制定了这个学习过程。
关键的是,该公式允许从2D图像提取丰富的3D表征,无需任何深度监督信号,并且具有与BEV一致的嵌入几何结构。尽管具有简单性和多功能性,但标准BEV视觉任务(例如,基于摄像机的3D目标检测和BEV分割)的大量实验表明,该模型在多任务学习的计算效率方面具有额外优势。
如图所示是自3D表征学习(Ego3RT)的示意图:BEV、多摄像头输入和3D目标检测

代码链接:https://fudan-zvg.github.io/Ego3RT
以图像为输入,现有视觉模型通常要么忽略(例如,图像分类)、要么直接消费(例如,目标检测,图像分割)结果预测期间输入的坐标框架。
尽管如此,这种范式并不符合自动驾驶“开箱即用(out-of-the-box)”的感知环境,其中输入源是多个摄像机,每个摄像机都有一个特定的坐标系,与所有输入帧完全不同,下游任务的感知模型(例如,3D目标检测、车道分割)需要在自车坐标系中进行预测。
也就是说,自动驾驶的感知模型需要从多视图图像的2D视觉表示中推理3 D语义,这是一个非常复杂且极具挑战性的问题。
如图所示,大多数方法采取以下两种策略:
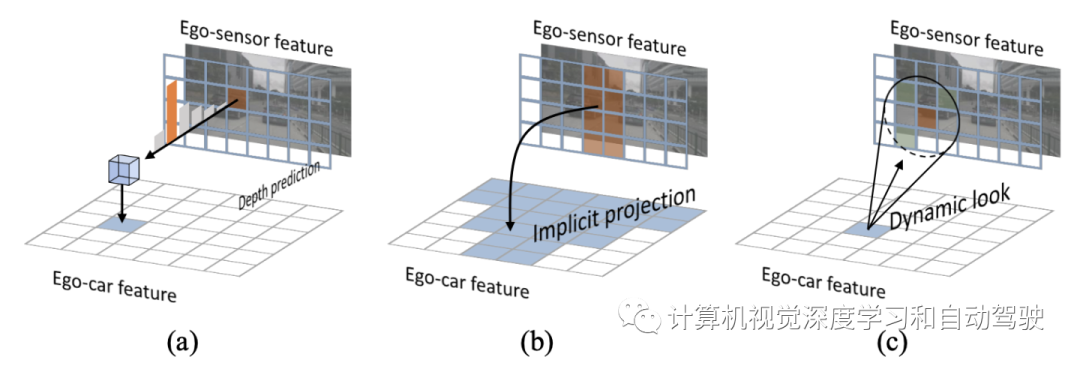
(a)显示第一种策略(例如LSS和CaDDN)依赖于像素级深度估计,用于将2D视觉表示投影到自车坐标系,以及内外参的投影。通常,深度预测在模型内进行端到端学习,无需监督,或有额外的3D监督。这些方法的一个缺点是,无约束场景中的深度估计通常容易出错,这将进一步传播到后续组件。这也称为误差传播问题,这在很大程度上是此类流水线不可避免的。
为了解决上述问题,第二种策略(例如Image2Map、OFT、DETR3D)通过架构创新从2D图像直接学习3D表示来消除深度维度。这种方法已证明优于基于深度估计的对应方法,这意味着学习3D表示是一种优越的一般策略。特别是,Image2Map和PON利用Transformer或FC层向前学习从2D图像帧到BEV坐标帧的投影。然而,如(b)所示,3D表示在结构上与2D的对应不一致,因为无法利用严格的内外参投影,即坐标系之间没有明确的一一对应关系,因此产生次优解。受基于图像的目标检测模型的启发,最近最先进的DETR3D制定了一个带有Transformer模型的3D表征学习模型。然而,其3D表征不仅稀疏,而且虚拟,在没有明确涉及自车坐标系几何结构的意义上。因此无法执行密集的预测任务,例如分割。
本文方法属于第三种策略(c)从BEV几何中专门设计的“假想眼”中回溯2D信息。整个方法架构可以分为两个部分(1)自车3D表示学习(Ego3RT)和(2)下游任务头。如下图所示:
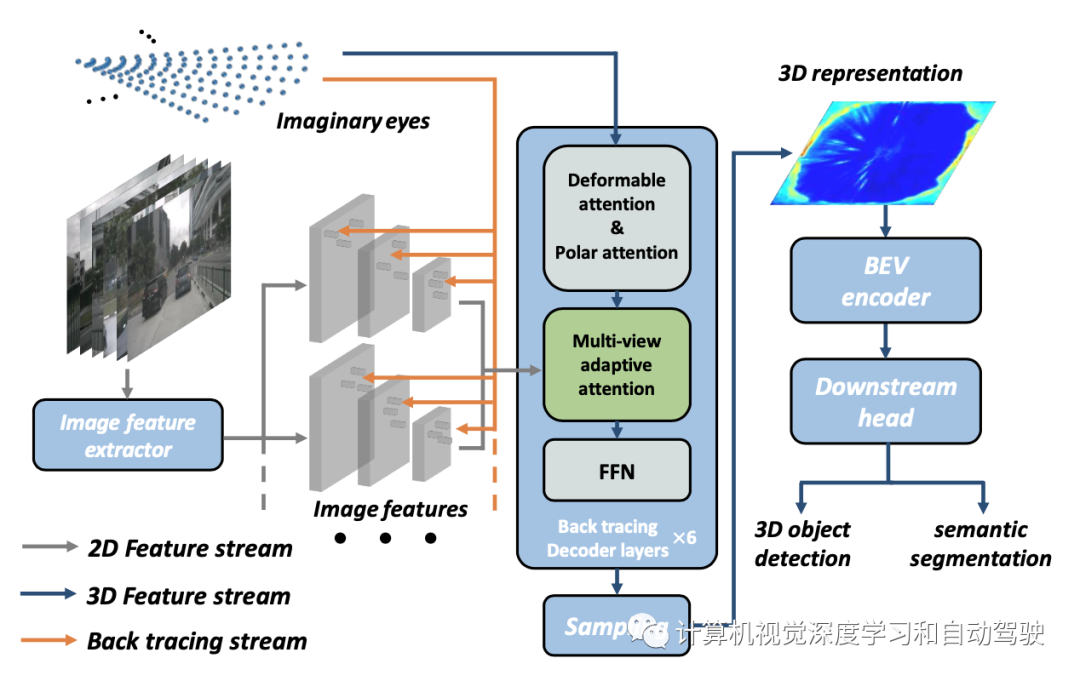
Ego3RT由两部分组成:图像特征提取和回溯(back tracing)解码器。为了清楚地说明回溯解码器,首先介绍“假想眼“、3D回溯到2D机制和多视图多尺度自适应注意机制。
下面详细说明Ego3RT如何从2D学习3D表示。为了避免穷举像素级预测和不一致的坐标投影,通过光线跟踪对回溯思想进行模拟。
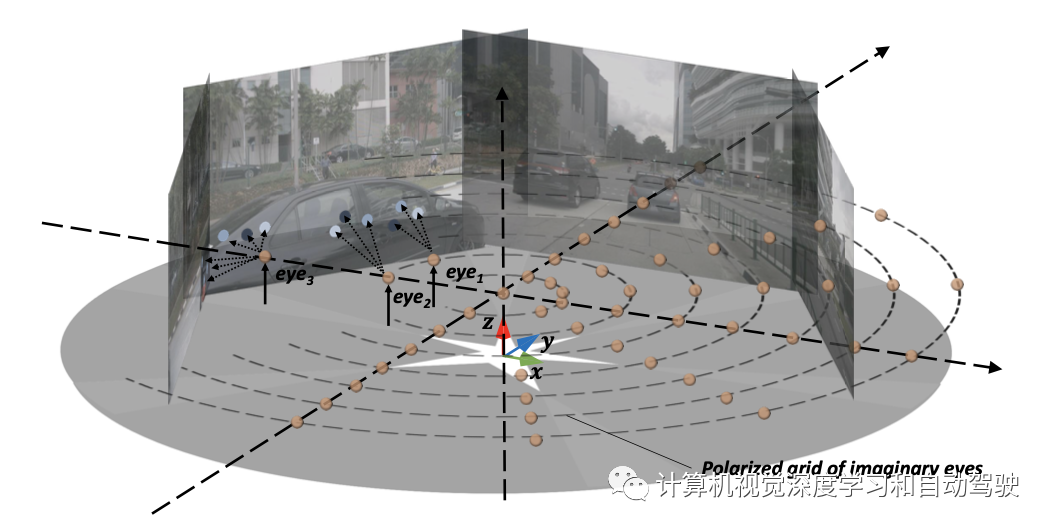
首先引入密集“假想眼”的极化网格(polarized grid),用于BEV表示,每只眼自然占据具有内置深度信息的特定几何位置。眼睛的网格大小为R×S,其中R是每个极射线的眼睛数,S是极射线数。为了构造或“渲染”BEV表示,这些假想眼按照上述3D-2D投影程序向后发送射线到2D视觉表征。由于每只眼睛只占据一个固定的几何位置,局部观测的限制使相应的2D位置回溯信息较少。为了解决这个问题,鼓励眼睛环视周围,跨每张图像多尺度和多摄像机视图,自适应地聚焦关键的特征点。这导致一个多视图多尺度自适应注意模块(MVAA)。最后,这些假想眼的特征将是最终的3D表示。
”假想眼“示意如图所示:金球代表密集的“假想眼”的极化网格;特别是,对于有多个可见图像(例如eye3)的眼睛,会回溯多个图像,而只有单个可见图像(例如eye1)的眼睛会回溯单个图像;图像上从浅蓝色到深蓝色的蓝点显示了眼睛的重要程度,从而促进自适应性注意。
为了说明回溯机制,首先说明3D和2D之间的坐标变换。在典型情况下,通常有一个激光雷达坐标(3D)、Nview个摄像机坐标(3D)和Nview个图像坐标(2D)。首先,将校正的激光雷达坐标3D点xlidar转换为校正的摄像头坐标xcam,并用外参给定的矩阵Mex。接下来,通过以下公式将xcam投影到图像平面点ximg:
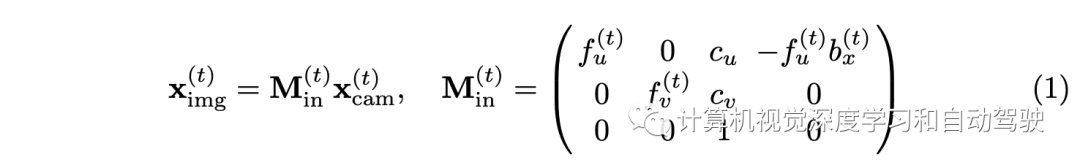
总之,通过投影矩阵M=MinMex将3D点xlidar投影到图像点ximg。如果0<u,v<1,则这3D点将投影到图像内,否则投影到图像外。如果ximg在图像内,称该图像对相应的点xlidar可见。在该方法中,鼓励假想眼在每个图像坐标中“注视”其2D投影点周围。将第q个眼睛的可见图像集表示为Iq。
MVAA是将2D表示转换为3D的核心。在自适应自注意检测框架中对这些假想眼进行学习。这是基于将眼睛视为目标查询的思想,记作y。让 r 记作眼睛在自车坐标中的位置。形式上,每只眼睛(即查询)将在2D图像表示的每个尺度上动态选择Npoint个特征点。然后,MVAA从中选择最重要的特征点,并跨多个尺度和视图将其融合到所需的3D表示中。该过程可以表示为

向量yq是第q个查询(eye),rq是其位置,Nh是头的数,M(t)是投影矩阵。A和∆r通过可学习参数被yq制约:
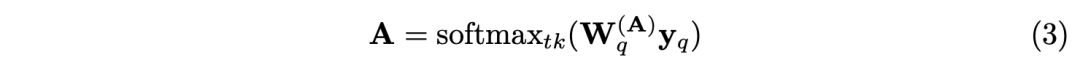
其中
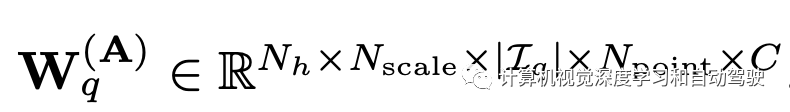
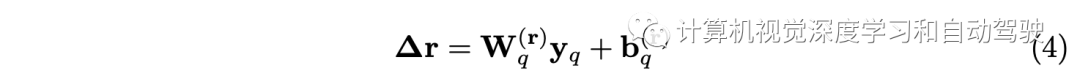
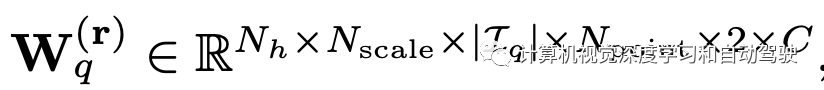
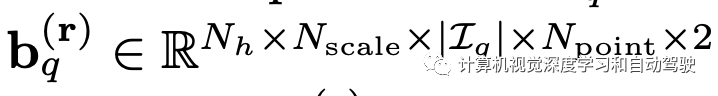
为了避免这些Npoint个特征点塌陷为一个点,用| bq[·,·,·,k]|=k初始化bq,因此Npoint越多,这些特征点的偏移量越大。因此,参数Npoint可以用来控制感受野。φ(x,r)表示通过索引从x访问第r个特征点。为了自适应地将重要性分配给Nscale×| Iq |×Npoint点,在所有参与的特征点、尺度和视图上应用Softmax函数:
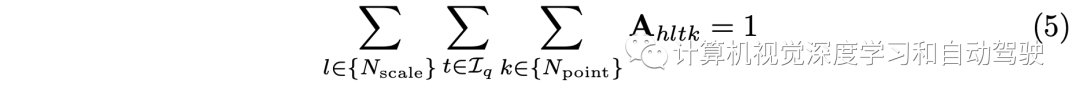
从技术上讲,回溯解码器随机提取假想眼的初始化特征和图像特征提取器的2D特征尺度作为输入,最后输出假想眼的细粒度特征作为3D表征。回溯解码器由一堆注意层组成,这些注意层改自transformer解码器层。每层按顺序堆叠两个自注意模块和一个交叉注意模块:可变形注意模块、极注意模块和MVAA。
与自注意相比,变形注意的记忆效率更高。在3D表征上,对相同极射线的一组眼睛应用标准自注意做极注意。此外,前馈网络(FFN)块配备了逐深度(depth-wise)卷积。MVAA负责将2D特征回溯到3D表征中。
下面是下游任务的头设计:
下游任务中在处理假想眼的特征之前,首先将极化特征网格化采样到矩形自车坐标系中,匹配数据集标注。
为了对多任务的3D表征进行编码,采用来自OFT的相同BEV编码器模块。这种子网络也广泛用于基于激光雷达的3D检测器。
检测头旨在预测目标在3D空间的位置、尺寸和方向,以及目标类别。虽然已经生成了密集的BEV特征,在检测任务中采用流行的CenterPoint中的3D检测头,无需任何修改。
对于BEV分割任务,选择一组基于渐进上采样卷积的语义分割解码器头,来处理地图中的不同元素。从技术上讲,1×1 Conv层、具有ReLU的BN层和双线性上采样卷积层共同构成一个上采样模块。用于预测不同地图元素的解码器头在BEV编码器之后使用精确的BEV特征。
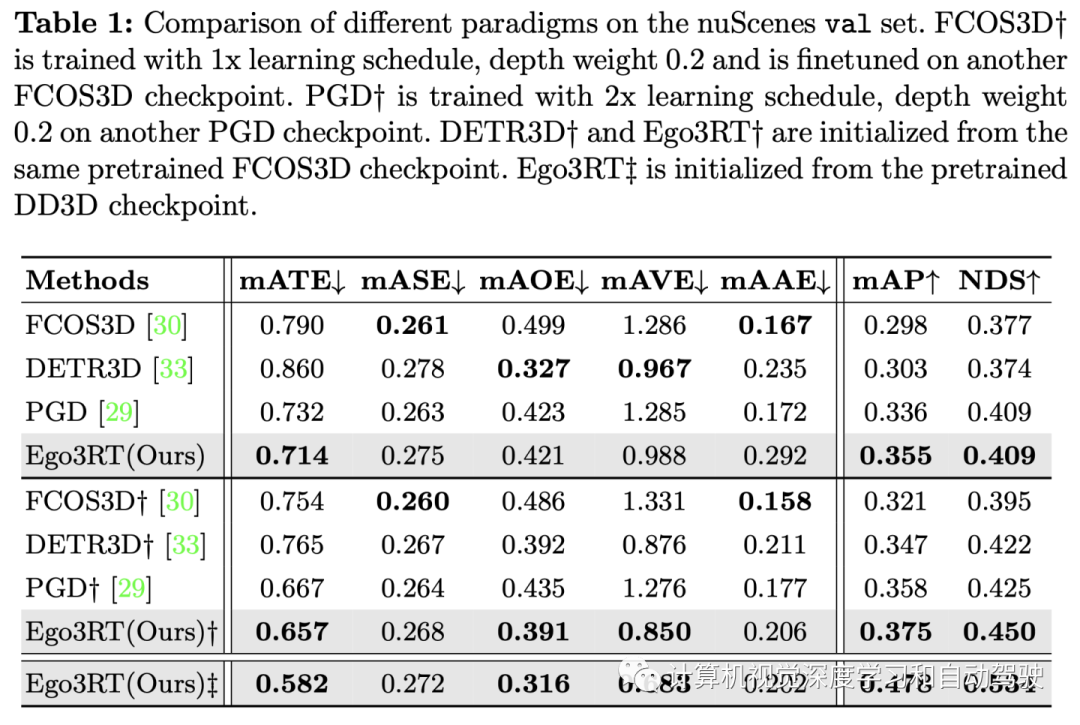
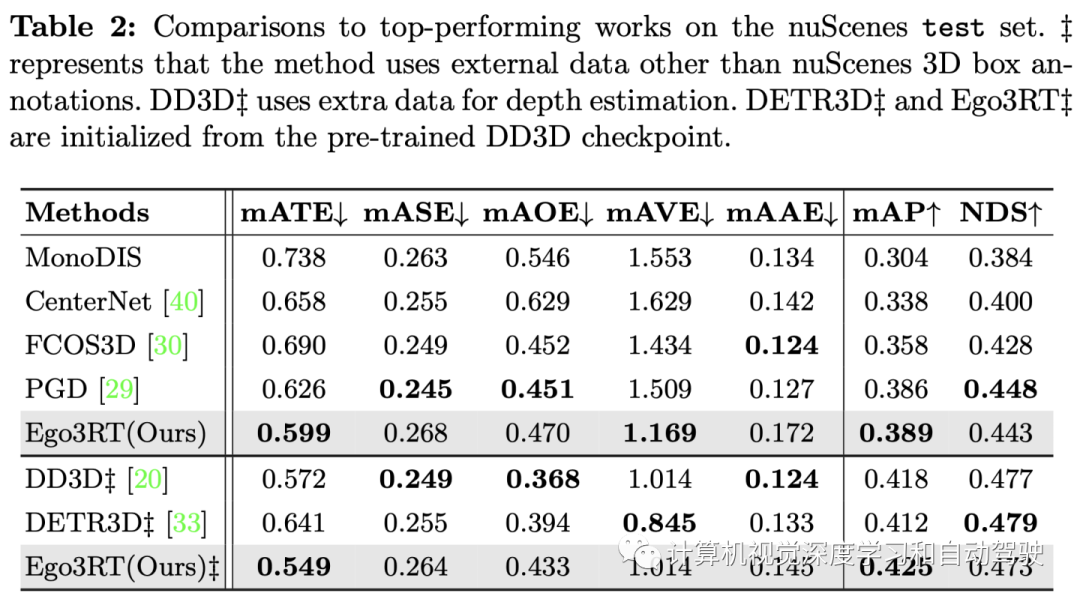
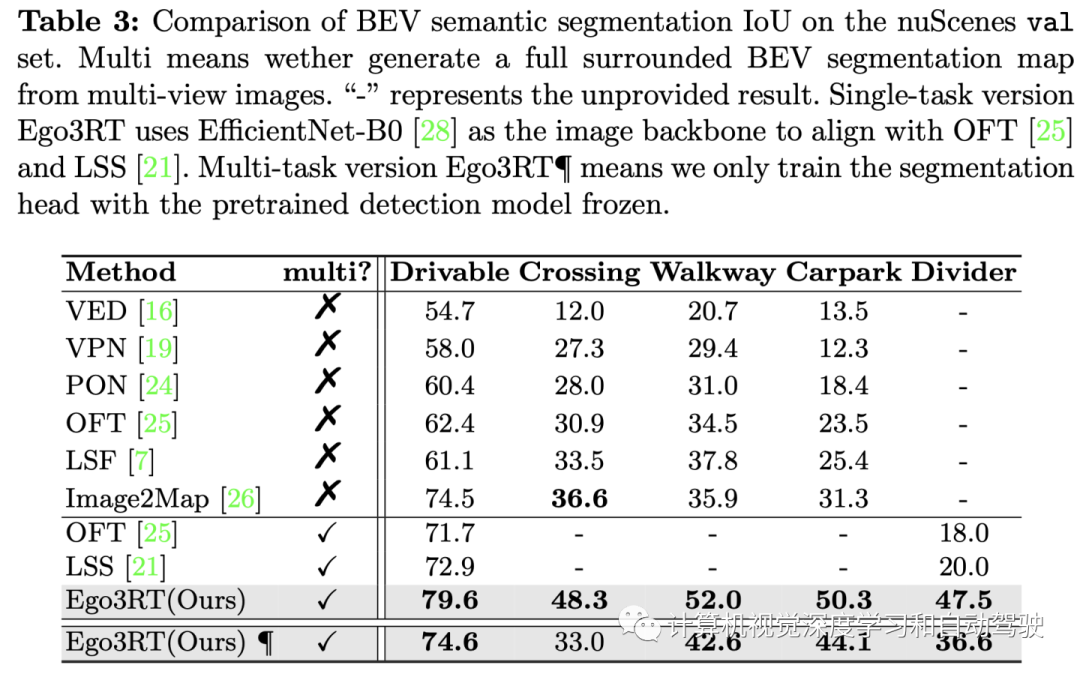
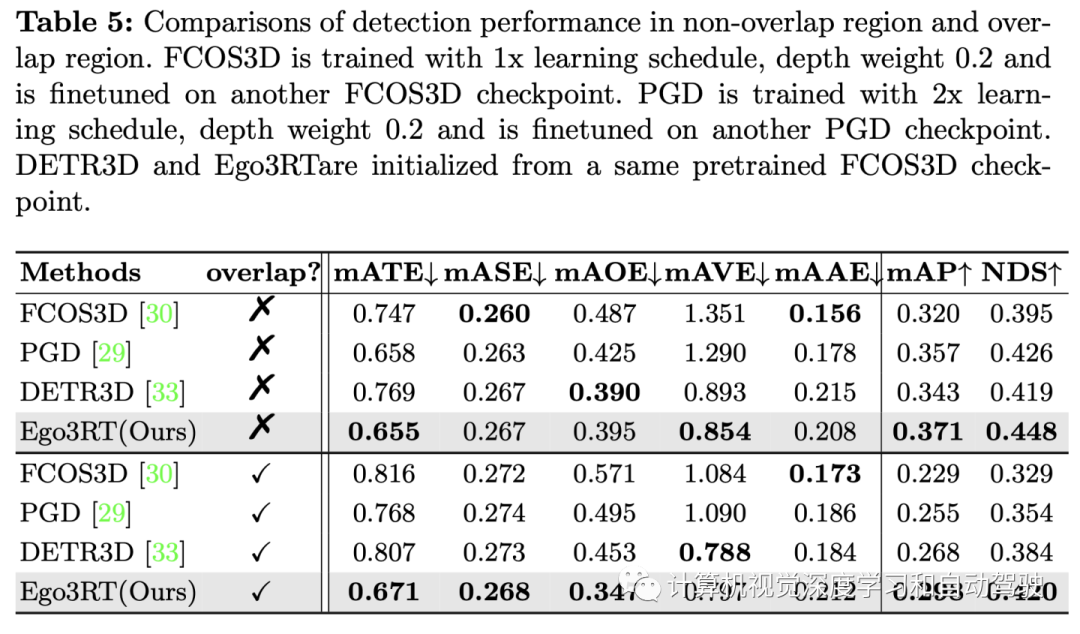
实验结果如下:
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:3dcver.com
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款
圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~
边栏推荐
- kubernetes部署ldap
- Model-Free Control
- The difference between redirectto and navigateto in uniapp
- Mujoco second order simple pendulum modeling and control
- Are you ready to automate continuous deployment in ci/cd?
- Policy Gradient Methods
- Advanced learning of MySQL -- basics -- multi table query -- self join
- Hero League | King | cross the line of fire BGM AI score competition sharing
- @TableId can‘t more than one in Class: “com.example.CloseContactSearcher.entity.Activity“.
- 三维扫描体数据的VTK体绘制程序设计
猜你喜欢
英雄联盟|王者|穿越火线 bgm AI配乐大赛分享
How to judge whether an element in an array contains all attribute values of an object

Three application characteristics of immersive projection in offline display
VTK volume rendering program design of 3D scanned volume data

equals()与hashCode()
509 certificat basé sur Go
X.509 certificate based on go language
The way of intelligent operation and maintenance application, bid farewell to the crisis of enterprise digital transformation

37页数字乡村振兴智慧农业整体规划建设方案
MySQL learning notes (mind map)
随机推荐
The way of intelligent operation and maintenance application, bid farewell to the crisis of enterprise digital transformation
threejs图片变形放大全屏动画js特效
uniapp中redirectTo和navigateTo的区别
Policy Gradient Methods
什么是时间
JWT signature does not match locally computed signature. JWT validity cannot be asserted and should
2022/2/12 summary
一图看懂对程序员的误解:西方程序员眼中的中国程序员
Advanced learning of MySQL -- basics -- multi table query -- self join
DAY TWO
Compilation of kickstart file
Advanced learning of MySQL -- Fundamentals -- concurrency of transactions
After leaving a foreign company, I know what respect and compliance are
互动滑轨屏演示能为企业展厅带来什么
Racher integrates LDAP to realize unified account login
【软件逆向-自动化】逆向工具大全
AI超清修复出黄家驹眼里的光、LeCun大佬《深度学习》课程生还报告、绝美画作只需一行代码、AI最新论文 | ShowMeAI资讯日报 #07.06
What is a responsive object? How to create a responsive object?
JS+SVG爱心扩散动画js特效
Leecode brush questions record sword finger offer 43 The number of occurrences of 1 in integers 1 to n