当前位置:网站首页>Hero League | King | cross the line of fire BGM AI score competition sharing
Hero League | King | cross the line of fire BGM AI score competition sharing
2022-07-07 00:33:00 【weixin_ forty-two million one thousand and eighty-nine】
Preface
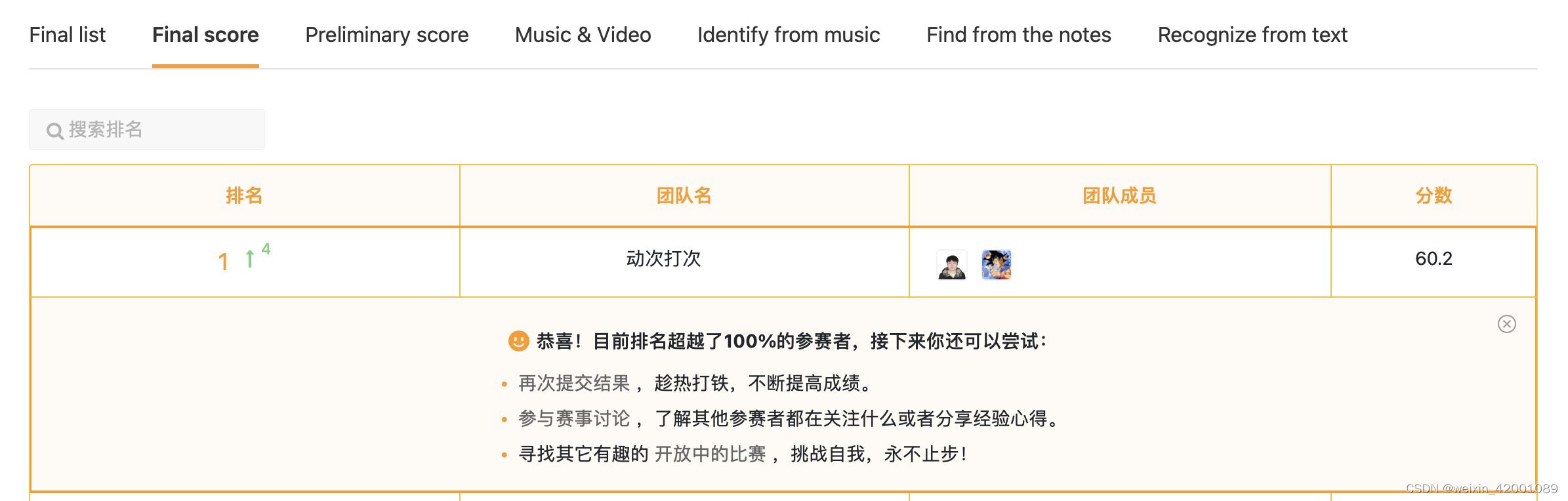
Recently, I played a multimodal game with my colleagues , Finally, I won the first place . Share with you , Here's an episode , It was always in the leading position during the preliminary round , As a result, he was suddenly overtaken on the last day , But in the defense of the time overturned , The final competition score is mainly through the technical thinking ( Occupy 30%)、 Theoretical depth ( Occupy 30%)、 Live performance ( Occupy 10%) And accuracy ( Occupy 30%, It is converted by the score of the preliminary contest ) Score calculation of four dimensions .
I don't say much nonsense , Start the theme
Competition questions
Simply put, it is to automatically match videos bgm, There are three kinds of games involved : Glory of Kings (HoK)、 Hero alliance (LOL) And crossing the line of fire (CF). The goal is to give a game video, Output its embedding And all candidates bgm District Library embedding.
The evaluation indicators are as follows :

Due to authorization issues , Data sets are not provided here , But I found a similar data on the Internet 【 Infringement can be deleted by contacting the author 】, You can feel it ( because csdn Can't upload , If you want to see it, you can see what the author knows :)
EDA
We have a thorough understanding of the data
(1) Video picture example :
It can be seen that the picture of the same game is actually quite similar
(2) Duration

Training set : Long tail distribution , Median : 67.6s, The average : 94.6s. Test set : The duration is 32s.
(3) There are separated anchor commentary audio data , but After separation BGM The noise is too loud .
(4) Lack of text data ( Such as the title , ASR etc. )
Method
The overall framework

In general, it is also a simple two tower model , The input end has text 、 Audio 、 Three modes of video .
Based on the preliminary investigation , We think the pictures of the video are very similar , Unless we can accurately extract representative frames such as transitions, random frame acquisition is not very helpful , And the anchor's commentary is very critical , tone ( Audio ) It can directly reflect excitement 、 Funny and so on , The second is the content of the commentary ( Text ) It's also crucial .
Note that this is not to say that video is not important , What we are talking about here is cost performance , It's easier to get higher profits in a certain period of time by focusing on the latter two , If we go to the depth of Technology , Video mode must be well explored .
To make a point , Here are just some useful strategies .
(1) Audio
First, feature extraction of audio , At present, people often use VGGish, I also found that most of them are basically VGGish, But we adopted HuBERT, It is based on bert An audio pre training model of thought training , The framework is as follows :

You can see more details :Light Sea:HuBERT: be based on BERT Self supervision of (self-supervised) Pronunciation means learning
(2) Data to enhance
The official data set is very few , How to make full use of data sets is also a consideration , Here we segment the video . With 20s Cut the video for intervals , Video and corresponding BGM Synchronous cutting , Data enhancement . We also carried out experiments on the cutting duration ,5s, 20s, 32s, among 20s The best effect .
The main points of : Training and prediction use the same length , Keep the strategy consistent , Otherwise, the effect will be very poor
(3)loss
The final request is embedding, It can be guessed that the probability is based on the European similarity to judge the result , So we use the method based on comparative learning Triplet Loss

Core code :

Final :

Harvest
See here actually trick That's it , Does it feel very simple , however ! The author believes that the above is not the most important , Next, the most important thing is : The thinking and experimental details in the whole process !
About video mode , Although at the beginning we expected that it would not have much profit , However, the experiment verifies that each video segment is extracted 10 Frame picture , Integrate with dubbing mode , The result is really no gain .
In addition, dubbing ASR, utilize BERT The extracted features , The effect is not improved , This is quite unexpected , It's not in line with expectations , The reason may be ASR The effect is not good , Here is a direct identification of an open source model , The text result also has no punctuation , Because of time, I didn't try again .
Add game category prediction as an auxiliary task , The effect is not improved , A possible explanation here is BGM It's universal .
Another episode is that it was far ahead of the list in the early stage , But on the last night, a classmate suddenly rose 14 name , To the second , Then the last hour came to the first , This once made us very curious about what it was trick? ha-ha , Finally, I learned that the key to the whole is to use two strong audio backbone, Although many players have designed some small trick spot , But it is eclipsed by the absolute strong model , This shows the importance of explanation on this task and the importance of baseline model selection .
In addition, there are some small points of fragmentary thoughts , Don't say , If you are interested, please contact the author
Explore the direction
Here we also give some possible optimization points in the future .
(1) Text mode : Can you provide some, such as the title , tag Wait for text mode and a good ASR Commentary text , This ceiling is still very high .
(2) How to better capture visual modal features ? For example, scene switching 、 Key frames of game moves, special effects, etc .
(3) Dubbing and BGM Audio does not share the same backbone, Our framework is currently shared , Theoretically speaking, explanation and bgm The distribution of is still different
(4) How to better interact with different modal features ?
If you are interested, you can communicate together ~
Focus on
Welcome to your attention , See you next time ~
Welcome to WeChat official account :

github:
Mryangkaitong · GitHubhttps://github.com/Mryangkaitong
You know :
边栏推荐
- Three sentences to briefly introduce subnet mask
- DAY FIVE
- QT tutorial: creating the first QT program
- Uniapp uploads and displays avatars locally, and converts avatars into Base64 format and stores them in MySQL database
- How engineers treat open source -- the heartfelt words of an old engineer
- Designed for decision tree, the National University of Singapore and Tsinghua University jointly proposed a fast and safe federal learning system
- Liuyongxin report | microbiome data analysis and science communication (7:30 p.m.)
- Interesting wine culture
- C language input / output stream and file operation [II]
- 2022年PMP项目管理考试敏捷知识点(9)
猜你喜欢
工程师如何对待开源 --- 一个老工程师的肺腑之言
St table
2022/2/12 summary

陀螺仪的工作原理

37 page overall planning and construction plan for digital Village revitalization of smart agriculture
![[automated testing framework] what you need to know about unittest](/img/4d/0f0e0a67ec41e41541e0a2b5ca46d9.png)
[automated testing framework] what you need to know about unittest
GEO数据挖掘(三)使用DAVID数据库进行GO、KEGG富集分析

The programmer resigned and was sentenced to 10 months for deleting the code. Jingdong came home and said that it took 30000 to restore the database. Netizen: This is really a revenge
uniapp实现从本地上传头像并显示,同时将头像转化为base64格式存储在mysql数据库中
MySQL learning notes (mind map)
随机推荐
Notes of training courses selected by Massey school
Interface master v3.9, API low code development tool, build your interface service platform immediately
1000 words selected - interface test basis
Imeta | Chen Chengjie / Xia Rui of South China Agricultural University released a simple method of constructing Circos map by tbtools
【CVPR 2022】半监督目标检测:Dense Learning based Semi-Supervised Object Detection
Data operation platform - data collection [easy to understand]
509 certificat basé sur Go
Why should a complete knapsack be traversed in sequence? Briefly explain
Sword finger offer 26 Substructure of tree
Rails 4 asset pipeline vendor asset images are not precompiled
37頁數字鄉村振興智慧農業整體規劃建設方案
TypeScript中使用类型别名
Leecode brush questions record interview questions 32 - I. print binary tree from top to bottom
华为mate8电池价格_华为mate8换电池后充电巨慢
互动滑轨屏演示能为企业展厅带来什么
Three application characteristics of immersive projection in offline display
Operation test of function test basis
Value Function Approximation
Command line kills window process
The programmer resigned and was sentenced to 10 months for deleting the code. Jingdong came home and said that it took 30000 to restore the database. Netizen: This is really a revenge