当前位置:网站首页>【向量检索研究系列】产品介绍
【向量检索研究系列】产品介绍
2022-07-06 16:29:00 【Luoyger】
1. 产品概况
1.1 产品对比
向量检索领域有着非常多优秀产品,不同的产品有着各自的特性,适用于不同的场景,接下来将对已了解的8款优秀向量检索产品进行简单的介绍。
- Milvus
- Faiss
- HNSWlib
- ScaNN
- SPTAG
- Vearch
- Zsearch
- Proxima
这些产品的对比如下,优缺点此处进行简要介绍,详细介绍见各个产品详细介绍。
序号 | 产品名 | 来源 | 是否开源 | 开发者 | Github Star数 | 优点 | 缺点 |
|---|---|---|---|---|---|---|---|
1 | Milvus | 外部 | 是 | Zilliz(上海) | 9.1k | 索引类型多,社区活跃 | 不支持数据分片,架构复杂 |
2 | Faiss | 外部 | 是 | 15.9k | 性能好,索引类型多,成熟 | 不支持服务化 | |
3 | HNSWlib | 外部 | 是 | nmslib | 1.8k | 性能好,召回率高 | 不支持服务化 |
4 | ScaNN | 外部 | 是 | 21.4k | 性能好,召回率高 | 不支持服务化 | |
5 | SPTAG | 外部 | 是 | Microsoft | 4.1k | 性能好 | 索引类型少 |
6 | Vearch | 外部 | 是 | 京东 | 1.3k | 性能好 | 不能实时更新 |
7 | Zsearch | 外部 | 否 | 蚂蚁金服 | / | 索引类型多 | 不开源 |
8 | Proxima | 外部 | 否 | 阿里达摩院 | / | 索引类型多 | 不开源 |
1.2 技术对比
序号 | 产品 | 实时更新 | 过滤功能 | CPU和GPU | 集群模式 | 可服务化 | 开发语言 | SDK |
|---|---|---|---|---|---|---|---|---|
1 | Milvus | 是 | 是 | 是 | 是 | 是 | Go/Python | Python/Go/Java/Node |
2 | Faiss | 是 | 否 | 是 | 否 | 否 | C++ | C++/Python |
3 | HNSWlib | 是 | 否 | 是 | 否 | 否 | C++ | C++/Python |
4 | ScaNN | 是 | 否 | 是 | 否 | 否 | C++/Python | C++/Python |
5 | SPTAG | 是 | 否 | 是 | 是 | 是 | C++ | Python/C# |
6 | Vearch | 否 | 否 | 是 | 是 | 是 | Go | Python |
1.3 性能对比
ANN-Benchmark网站对现有流行的向量检索产品进行了性能测试,其测试结果在其官网上展示。
ANN-Benchmark官网:http://ann-benchmarks.com/
Github地址:https://github.com/erikbern/ann-benchmarks
部分性能测试结果如下,更多测试结果参考官网。测试结果中可以看出Google的ScaNN索引和基于HNSW的索引性能较优。
- glove-100-angular (k = 10)数据集的向量检索内积距离top 10测试结果
- fashion-mnist-784-euclidean (k = 10)数据集的向量检索欧式距离top 10测试结果
2. 产品介绍
2.1 Milvus
Milvus是国内的一家名为Zilliz公司开源的向量检索产品,Zilliz公司是上海赜睿信息科技有限公司于2017年创立的AI非结构化数据处理和分析品牌。
Zilliz官网:https://zilliz.com/
Milvus 于 2019 年开源,主要用于存储、索引和管理通过深度神经网络和机器学习模型产生的海量向量数据。参考资料如下:
- Mivlvus官网:https://milvus.io/cn/
- Github地址:https://github.com/milvus-io/milvus
- Hub仓库:https://hub.docker.com/search?q=milvus&type=image
- 集群配置:https://github.com/zilliz-bootcamp/Milvus_distributed_based_mishards
- 监控配置:https://github.com/milvus-io/docs/tree/master/v1.1.0/assets/monitoring
- 开发指引:https://github.com/milvus-io/milvus/blob/master/docs/developer_guides/chap01_system_overview.md
- 性能数据:https://github.com/milvus-io/milvus/blob/master/docs/test_report/milvus_ivfsq8_test_report_detailed_version.md
- 测试结果:https://github.com/milvus-io/bootcamp/tree/master/benchmark_test
- Docker内编译Server:https://github.com/milvus-io/milvus/blob/1.1/INSTALL.md
- 数据目录介绍:https://mp.weixin.qq.com/s/_x5XtbaBMO9JCBG2r6VkWQ
- CSDN:https://zilliz.blog.csdn.net/
Milvus最新2.0版本架构
优点
- 高性能:性能高超,可对海量数据集进行向量相似度检索。
- 高可用、高可靠:Milvus 支持在云上扩展,其容灾能力能够保证服务高可用。
- 混合查询:Milvus 支持在向量相似度检索过程中进行标量字段过滤,实现混合查询。
- 开发者友好:支持多语言、多工具的 Milvus 生态系统。
- 资料多,已经加入linux基金项目,技术社区维护的比较好,也有自己的博客更新及时。
- 支持CPU和GPU模式。
- 支持服务化和集群化部署。
- 支持过滤功能。
- 支持实时更新。
缺点
- 不支持数据分片。
- 使用第三方存储,访问时延稍差。
- 架构复杂,相关依赖组件多,稳定性影响因素多。
2.2 Faiss
Faiss是Facebook开源的一款优秀的产品,支持的索引类型非常丰富,产品也非常成熟,Faiss主要是对各种基础算法进行组合形成不同场景下高性能的索引类型,其它很多优秀产品都是基于Faiss进行进一步优化。
Github地址:https://github.com/facebookresearch/faiss
文档:https://github.com/facebookresearch/faiss/wiki
支持的索引,常见的索引算法均能在Faiss中看到应用。
- IndexFlatL2
- IndexFlatIP
- IndexHNSWFlat
- IndexIVFFlat
- IndexLSH
- IndexScalarQuantizer
- IndexPQ
- IndexIVFScalarQuantizer
- IndexIVFPQ
- IndexIVFPQR
- IndexBinaryFlat
- IndexBinaryIVF
- IndexBinaryHNSW
- IndexBinaryHash
- IndexBinaryMultiHash
优点
- 索引类型非常丰富。
- 产品非常成熟。
- 文档比较齐全。
- 支持CPU和GPU模式。
- 支持实时更新。
缺点
- 不支持服务化和集群化部署。
- 不支持过滤功能。
2.3 HNSWlib
HNSWlib(Hierarchical Navigating Small World lib)nmslib向量检索库中性能最好的一个库,对HNSW算法进行了优化,具有较快的检索速度和较高的召回率,也被大部分其它产品所引用和优化。
Github地址:https://github.com/nmslib/hnswlib
优点
- 检索速度快。
- 召回率高。
- 支持CPU和GPU模式。
- 支持实时更新。
缺点
- 构建索引时间长。
- 内存占用高。
- 不支持服务化和集群化部署。
- 不支持过滤功能。
2.4 ScaNN
ScaNN (Scalable Nearest Neighbors)是Google在2020年开源的一个优秀的向量检索库,是google-research下的一个子项目,有着非常好的一个检索性能。因开源时间不长,所能搜索到的资料非常少。
ScaNN索引的向量搜索主要分为如下三个阶段:
- 分区(可选步骤):在训练时期把数据集进行分区,查询的时候选择Top分区去进行打分。分区使用的是kmeans_tree。
- 打分:计算查询向量与整个数据集或分区内数据的距离,这个距离不需要很精确。
- 重新打分(可选步骤):从打分阶段获取TopK的向量,然后更加精确地计算与查询向量的距离,从计算后的向量中获取TopK向量列表。
ScaNN使用了各向异性矢量量化技术提高了向量检索的精度。
Github地址:https://github.com/google-research/google-research/tree/master/scann
优点
- 检索速度快。
- 召回率高。
- 支持CPU和GPU模式。
- 支持实时更新。
缺点
- 学习资料少。
- 不支持服务化和集群化部署。
- 不支持过滤功能。
2.5 SPTAG
SPATG (Space Partition Tree And Graph) 是由Microsoft Research (MSR) and Microsoft Bing共同发布的空间分区树和图索引,主要采用的是树和图的技术进行加速检索,可支持服务化和集群化部署。
SPTAG提供了两种索引,如下图
- kd-tree和相关邻居图 (SPTAG-KDT),在索引构建方面更有优势。
- 平衡k-means树和相关邻居图 (SPTAG-BKT),在高维度数据搜索精确度上更有优势。
Github地址:https://github.com/microsoft/SPTAG
优点
- 支持服务化和集群化部署。
- 支持CPU和GPU模式。
- 支持实时更新。
缺点
- 不支持过滤功能。
- 不支持内积距离。
2.6 Vearch
Vearch 是京东开源的对大规模深度学习向量进行高性能相似搜索的弹性分布式系统。
Github地址:https://github.com/vearch/vearch
文档:https://vearch.readthedocs.io/zh_CN/latest/overview.html
架构图
优点
- 支持服务化和集群化部署。
- 支持CPU和GPU模式。
缺点
- 不支持过滤功能。
- 数据插入和建索引时不支持搜索。
- 不支持实时添加数据到GPU索引,新增数据只有更新索引后才会生效。
2.7 Zsearch
Zsearch是蚂蚁金服基于ES做了更多扩展和性能优化,在 ES 上实现 LSH、IVSPQ、HNSW 插件,项目不开源。
架构图
优点
- 基于 K8s 底座,快速创建 ZSearch 组件,快捷运维,故障机自动替换;
- 跨机房复制,重要业务方高保;
- 插件平台,用户自定义插件热加载;
- SmartSearch 简化用户搜索,开箱即用;
- Router 配合 ES 内部多租户插件,提高资源利用率;
缺点
- 不开源。
2.8 Proxima
Proxima 是阿里内部达摩院开发的一个通用向量检索引擎框架,类似于Facebook开源的Faiss,支持多种索引类型。
架构图
优点
- 支持多种向量检索算法。
- 统一的方法和架构,方便使用方适配。
- 支持异构计算,GPU。
缺点
- 不开源。
3. 总结
本文主要对向量检索领域相关的优秀产品进行了产品对比、技术对比和性能对比,以及对各个产品进行了简单的介绍,并阐述了其优缺点。由于个人接触的知识有限,有些优秀的产品没能了解到,或者文中某些数据有误,还请各位小伙伴指正。后续还将进一步分享向量检索的技术详细介绍、测试、应用和思考。
4. Reference
- https://milvus.io/cn/
- https://github.com/facebookresearch/faiss
- https://github.com/nmslib/hnswlib.
- https://github.com/google-research/google-research/tree/master/scann
- https://github.com/microsoft/SPTAG
- https://vearch.readthedocs.io/zh_CN/latest/overview.html
- https://git.code.oa.com/elasticfaiss/elasticfaiss
边栏推荐
- Server SMP, NUMA, MPP system learning notes.
- Competition between public and private chains in data privacy and throughput
- Eureka Client启动后就关闭 Unregistering application xxx with eureka with status DOWN
- JS import excel & Export Excel
- Wind chime card issuing network source code latest version - commercially available
- Entropy information entropy cross entropy
- Oracle中使用包FY_Recover_Data.pck来恢复truncate误操作的表
- Gradle knowledge generalization
- Unity color palette | color palette | stepless color change function
- MVC and MVVM
猜你喜欢

Competition between public and private chains in data privacy and throughput
Restoration analysis of protobuf protocol of bullet screen in station B

11 preparations for Web3 and Decentralization for traditional enterprises
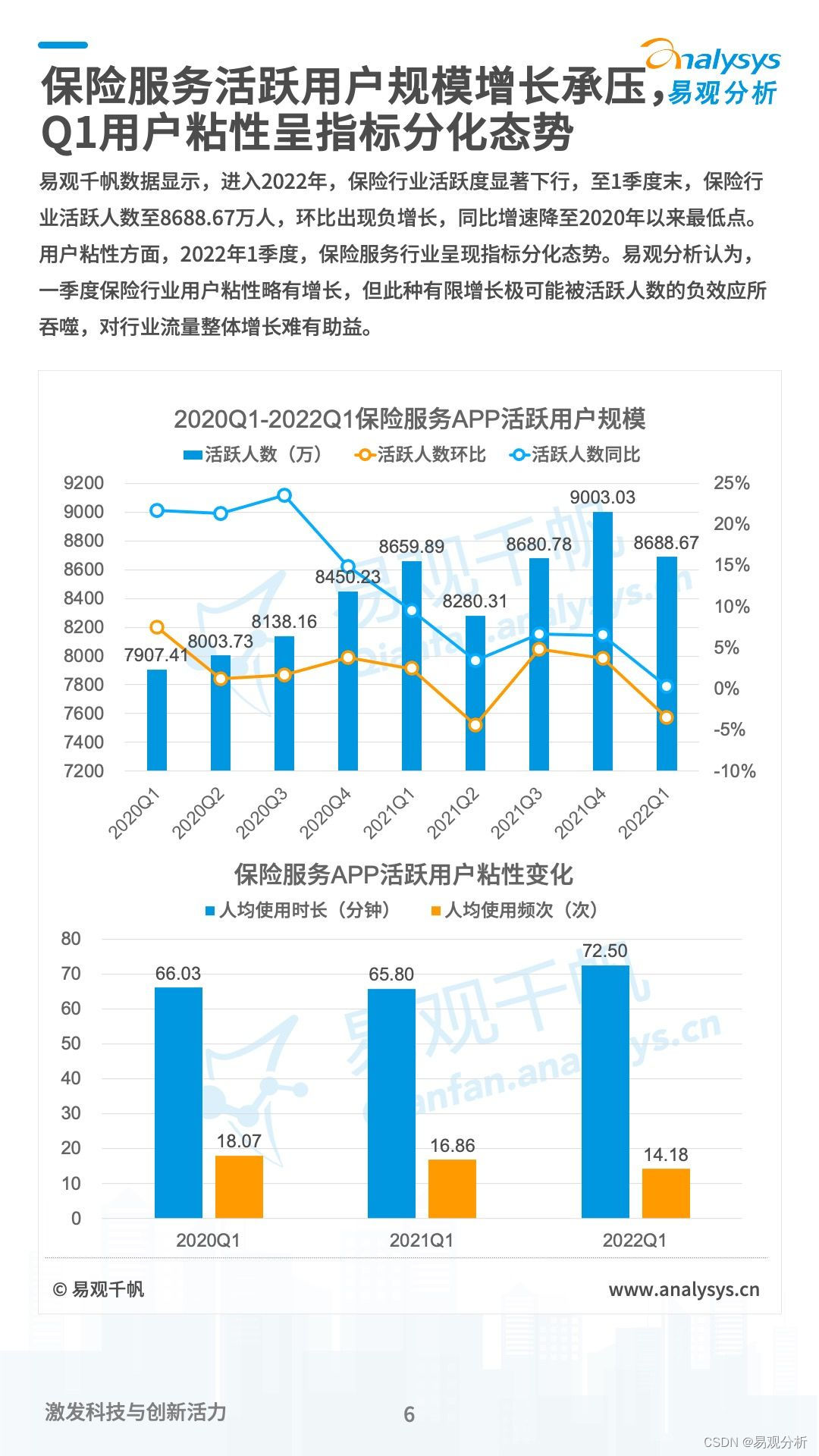
《数字经济全景白皮书》保险数字化篇 重磅发布
Per capita Swiss number series, Swiss number 4 generation JS reverse analysis
The method of reinstalling win10 system is as simple as that

app通用功能测试用例
Rider离线使用Nuget包的方法
Matplotlib draws a histogram and adds values to the graph
Gradle知识概括
随机推荐
How rider uses nuget package offline
Penetration test --- database security: detailed explanation of SQL injection into database principle
Gradle knowledge generalization
编译logisim
DAY SIX
Should the jar package of MySQL CDC be placed in different places in the Flink running mode?
氢创未来 产业加速 | 2022氢能专精特新创业大赛报名通道开启!
JS import excel & Export Excel
The tutorial of computer reinstallation win10 system is simple and easy to understand. It can be reinstalled directly without U disk
The method of reinstalling win10 system is as simple as that
Talking about the current malpractice and future development
Do you still have to rely on Simba to shout for a new business that is Kwai?
Wind chime card issuing network source code latest version - commercially available
Entropy information entropy cross entropy
How much does the mlperf list weigh when AI is named?
How does crmeb mall system help marketing?
JDBC programming of MySQL database
The programmer said, "I'm 36 years old, and I don't want to be rolled, let alone cut."
flinksql select id ,count(*) from a group by id .
Gold three silver four, don't change jobs