当前位置:网站首页>Knowledge * review
Knowledge * review
2022-07-06 23:23:00 【Daily Xiaoxin】
Knowledge review
1、 Please briefly HBase Data structure and storage architecture
data structure :hbase The data structure includes : Namespace , The line of key , Column cluster , Column , Time stamp , data ceil.
- Namespace : Similar to relational database , Space for storing tables
- The line of key : That is to say rowkey, Unique identification
- Column cluster : That is, a large class , A data set , The quantity is fixed
- Column : Column is a popular column , A column cluster can have multiple columns , Columns can be added
Time stamp : Each data update will be followed by a new timestamp , You can get the latest data through timestamp , It also solved hdfs Disadvantages that cannot be modified over time- data ceil: That is to say hbase The data in is all string type
Storage architecture :Client( client )、Master( Master node )、HRegionServer( maintain HRegion)、HLog( journal )、HRegion( Maintain several Store)、Store( Specific data storage )、StoreFile( Persist to HDFS)、MemStore( Memory storage )、Zookeeper( Monitor the cluster and storage root The mapping information )
2、 Please briefly HBase The process of querying data
First visit zookeeper, obtain meta Where are the documents HRegionServer The location of , obtain meta Memory for file loading , obtain rowkey Corresponding HRegion Due to the existence of multiple HRegion in , So create multiple HRegionScanner,StoreScanner Scanner , Scan first MemStore Whether it is stored in , Scan again StoreFile, Last result returned
3、 Please briefly HBase The process of writing inquiry data
Connect first , Append the write operation to HLog In the log , In obtaining zookeeper in meta File location information , obtain meta Specified in the rowkey The mapping of HRegion After the message , Write data , writes MemStore, Reach by default 128MB when , Perform a brush write to the hard disk , become StoreFile, With constant StoreFile More ,StoreFile It will merge data
4、 Please elaborate Spark Caching mechanism in cache and persist And checkpoint The difference and connection
cache:One of the control operators ,cache() = persist() = persist(StorageLevel.Memory_Only), amount to persist A case of , It belongs to inert loading , The cache will not be used for the first time, but only for the second operation ( The code implementation is as follows )persist:One of the control operators : Support persistence , Common patterns are Memory_Only and Memory_and_Diskcheckpoint:Mainly used for persistence RDD, Persist the results to specific files , Also inert loading ( The code implementation is as follows )- All three are control operators , A control and persistence of different forms of data , among cache Memory based ,checkpoints Based on hard disk , and persist The most comprehensive multiple modes can be realized
/* Control operator cache() Lazy loading */
object CtrlCache {
def main(args: Array[String]): Unit = {
// Create connection
val context = new SparkContext(new SparkConf().setMaster("local").setAppName("cache" + System.currentTimeMillis()))
// Get data element
val value: RDD[String] = context.textFile("src/main/resources/user.log")
// Start cache
value.cache()
// Recording time
val start: Long = System.currentTimeMillis()
// Count the number of data rows
val count: Long = value.count()
// Record the end time
val end: Long = System.currentTimeMillis()
// Output results
println(" The data is "+count+" That's ok , Time consuming :"+(end-start)+"s")
// Recording time
val start1: Long = System.currentTimeMillis()
// Count the number of data rows
val count1: Long = value.count()
// Record the end time
val end1: Long = System.currentTimeMillis()
// Output results
println(" The data is "+count1+" That's ok , Time consuming :"+(end1-start1)+"s")
}
}

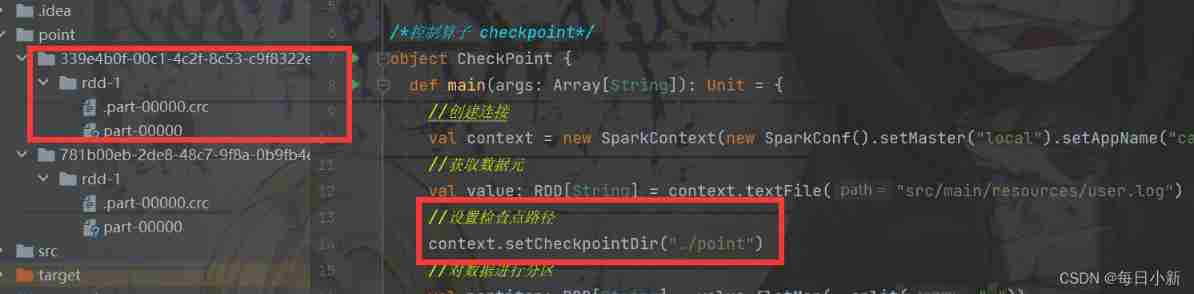
/* Control operator checkpoint*/
object CheckPoint {
def main(args: Array[String]): Unit = {
// Create connection
val context = new SparkContext(new SparkConf().setMaster("local").setAppName("cache" + System.currentTimeMillis()))
// Get data element
val value: RDD[String] = context.textFile("src/main/resources/user.log")
// Set checkpoint path
context.setCheckpointDir("./point")
// Partition the data
val partiton: RDD[String] = value.flatMap(_.split(" "))
// Get the number of partitions
println(" Partition number :"+partiton.getNumPartitions)
// Persistence
value.checkpoint()
// Number of persistence
value.count()
context.stop()
}
}
5、RDD The five attributes of ? Please list the commonly used RDD Operator and action ?
- Five attributes :
① RDD By a group partition Partition composition
② RDD Interdependence between
③ RDD Calculate the best calculation position
④ The partition is used for key -value Of RDD On
⑤ Function acts on each partition- RDD Common operators and functions :
– Conversion operator :
map: In one out one , Data segmentation and other processing
flatMap: And map Similar to first map after flat, It is mostly used for partition
sortByKey: be used for k-vRDD On , Sort
reduceByKey: Will be the same Key Data processing
– Action operator :
count: Returns the number of elements in the dataset
foreach: Loop through each element in the dataset
collect: The calculation results are recycled to Driver End
– Control operator :cache ,persist,checkpoint( A little )
6、Spark What is the role of width dependence ?
Wide dependence :It means the father RDD And son RDD Between partition Partition relationship is one to many , And that leads to shuffle The generation of shuffleNarrow dependence :It means the father RDD And son RDD Between partition The relationship between partitions is one-to-one or many to one , Will not produce shuffle Shuffle operation
effect :spark Divide by width dependence stage
边栏推荐
- 新手问个问题,我现在是单机部署的,提交了一个sql job运行正常,如果我重启了服务job就没了又得
- Unified Focal loss: Generalising Dice and cross entropy-based losses to handle class imbalanced medi
- Motion capture for snake motion analysis and snake robot development
- How to choose indoor LED display? These five considerations must be taken into account
- 今日睡眠质量记录78分
- Bipartite graph determination
- Where does this "judge the operation type according to the op value and assemble SQL by yourself" mean? It means simply using Flink tab
- Docker mysql5.7 how to set case insensitive
- 允许全表扫描 那个语句好像不生效set odps.sql.allow.fullscan=true;我
- B 站弹幕 protobuf 协议还原分析
猜你喜欢
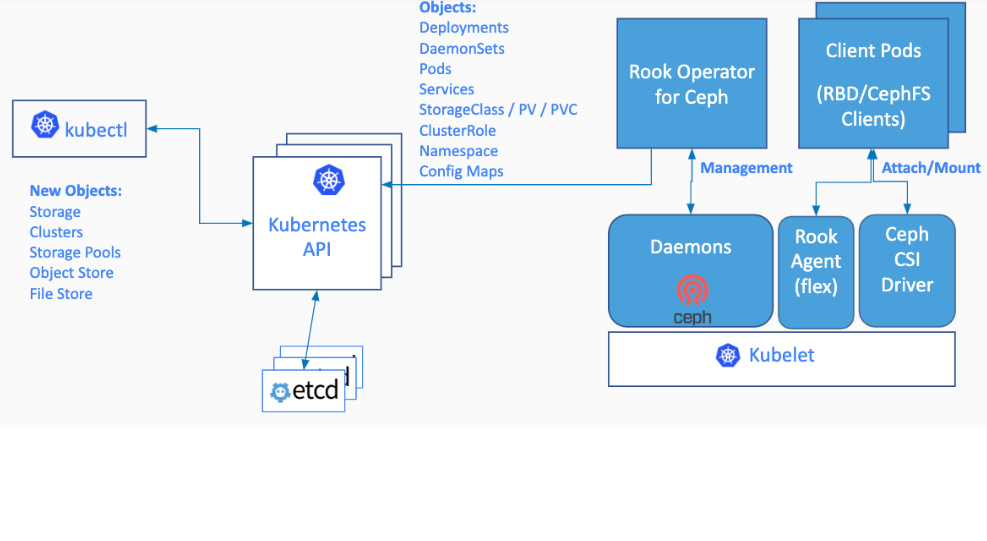
云原生(三十二) | Kubernetes篇之平台存储系统介绍

GPT-3当一作自己研究自己,已投稿,在线蹲一个同行评议
MySQL中正则表达式(REGEXP)使用详解

Cocoscreator+typescripts write an object pool by themselves

为了交通安全,可以做些什么?
今日睡眠质量记录78分
Thinkphp5 multi table associative query method join queries two database tables, and the query results are spliced and returned

How to choose indoor LED display? These five considerations must be taken into account
Modules that can be used by both the electron main process and the rendering process

(1)长安链学习笔记-启动长安链
随机推荐
#DAYU200体验官# 在DAYU200运行基于ArkUI-eTS的智能晾晒系统页面
mysql拆分字符串作为查询条件的示例代码
Some suggestions for foreign lead2022 in the second half of the year
Example code of MySQL split string as query condition
js對JSON數組的增删改查
Let me ask you if there are any documents or cases of flynk SQL generation jobs. I know that flynk cli can create tables and specify items
How to choose indoor LED display? These five considerations must be taken into account
The application of machine learning in software testing
浅谈现在的弊端与未来的发展
Motion capture for snake motion analysis and snake robot development
DockerMySQL无法被宿主机访问的问题解决
石墨文档:4大对策解决企业文件信息安全问题
What does front-end processor mean? What is the main function? What is the difference with fortress machine?
Precise drag and drop within a contentable
Pdf batch splitting, merging, bookmark extraction, bookmark writing gadget
COSCon'22 社区召集令来啦!Open the World,邀请所有社区一起拥抱开源,打开新世界~
这个『根据 op 值判断操作类型来自己组装 sql』是指在哪里实现?是指单纯用 Flink Tabl
Introduction to network basics
Method of canceling automatic watermarking of uploaded pictures by CSDN
What can be done for traffic safety?