当前位置:网站首页>spark调优(二):UDF减少JOIN和判断
spark调优(二):UDF减少JOIN和判断
2022-07-06 15:38:00 【InfoQ】
1. 起因
2. 优化开始
2.1 改成java代码编写程序
2.2 使用UDF
public class UDF implements UDF2<Long, Long, Long> {
Map<Long, TreeMap<Long, Long>> map;
public TripUDF(Broadcast<Map<Long, TreeMap<Long, Long>>> bmap) {
this.map = bmap.getValue();
}
@Override
public Long call(Long id, Long time) throws Exception {
if (map.containsKey(terminalId)) {
Map.Entry<Long, Long> a = map.get(id).floorEntry(time);
Map.Entry<Long, Long> b = map.get(id).ceilingEntry(time);
if (null != a && null != b) {
if (a.getValue().equals(b.getValue())) {
return a.getValue();
}
}
}
return -1L;
}
}
tablea join tableb
on tablea.id=tableb.id and
tablea.time >= tableb.timeStart and
tablea.time <= tableb.timeEnd
String udfMethod = "structureMap";
spark.udf().register(udfMethod, new UDF(broadcast1), DataTypes.StringType);
select id,time,structureMap(id,time) as tag from tablea
结束语
边栏推荐
- On the problems of born charge and non analytical correction in phonon and heat transport calculations
- OpenSSL:适用TLS与SSL协议的全功能工具包,通用加密库
- 让我们,从头到尾,通透网络I/O模型
- Matlab tips (27) grey prediction
- (DART) usage supplement
- Sword finger offer question brushing record 1
- [unity] upgraded version · Excel data analysis, automatically create corresponding C classes, automatically create scriptableobject generation classes, and automatically serialize asset files
- 2014 Alibaba web pre intern project analysis (1)
- UE4 blueprint learning chapter (IV) -- process control forloop and whileloop
- 监控界的最强王者,没有之一!
猜你喜欢

Hard core observation 545 50 years ago, Apollo 15 made a feather landing experiment on the moon

DR-Net: dual-rotation network with feature map enhancement for medical image segmentation
Dayu200 experience officer runs the intelligent drying system page based on arkui ETS on dayu200
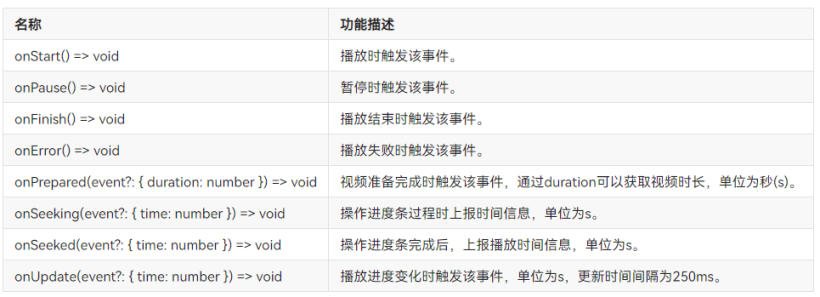
#DAYU200体验官# 首页aito视频&Canvas绘制仪表盘(ets)
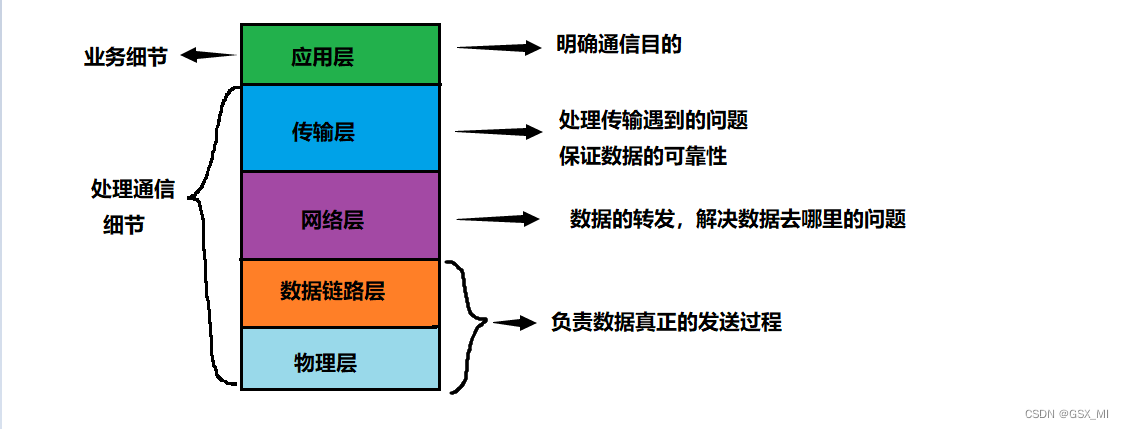
Introduction to network basics

室内LED显示屏应该怎么选择?这5点注意事项必须考虑在内

企业不想换掉用了十年的老系统

Aardio - construct a multi button component with customplus library +plus

机试刷题1
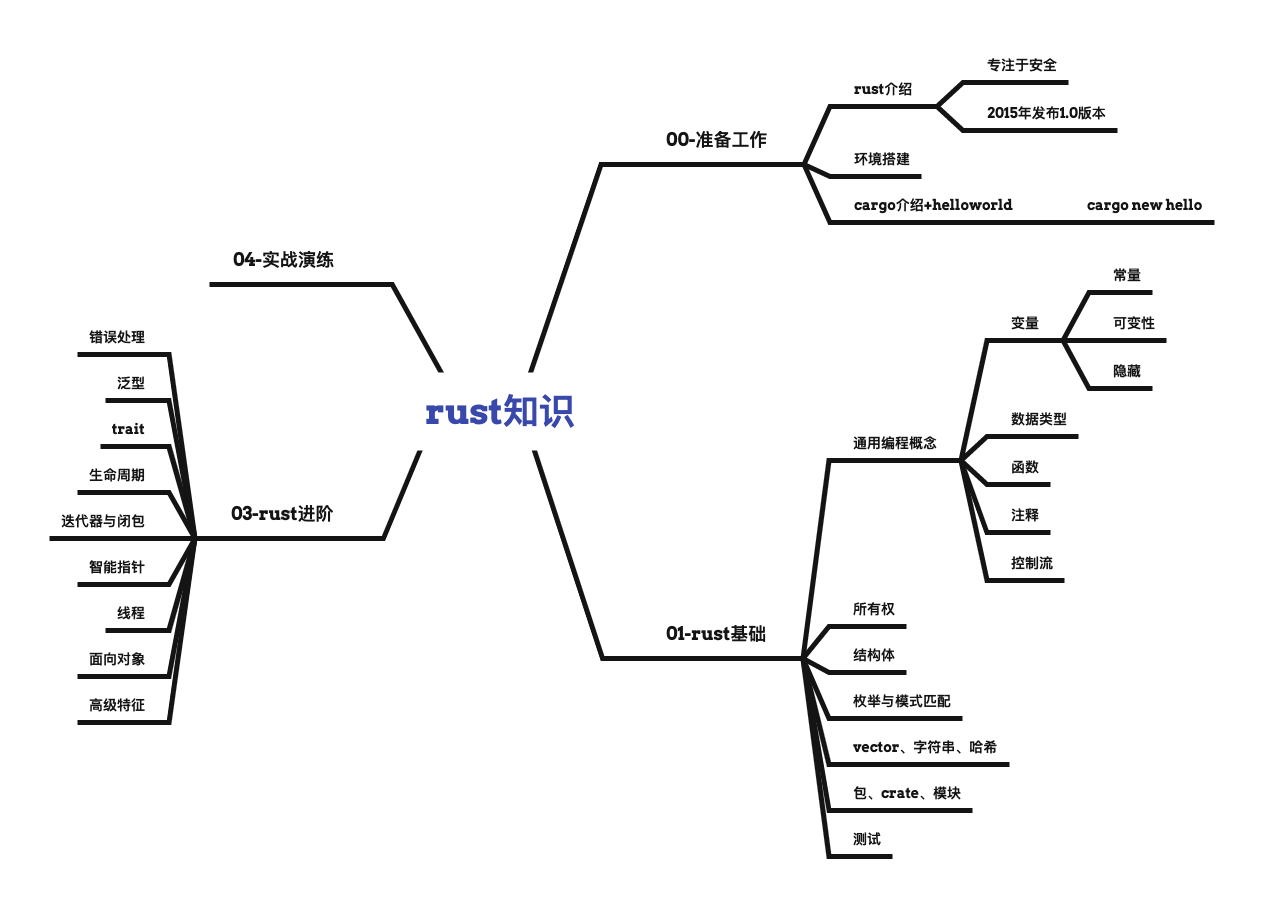
rust知识思维导图xmind
随机推荐
Designed for decision tree, the National University of Singapore and Tsinghua University jointly proposed a fast and safe federal learning system
[untitled]
Balanced Multimodal Learning via On-the-fly Gradient Modulation(CVPR2022 oral)
UDP programming
[leetcode] 19. Delete the penultimate node of the linked list
使用云服务器搭建代理
视图(view)
Windows auzre background operation interface of Microsoft's cloud computing products
Motion capture for snake motion analysis and snake robot development
浅谈网络安全之文件上传
MySQL教程的天花板,收藏好,慢慢看
QT signal and slot
hdu 5077 NAND(暴力打表)
HDU 5077 NAND (violent tabulation)
The statement that allows full table scanning does not seem to take effect set odps sql. allow. fullscan=true; I
项目复盘模板
Children's pajamas (Australia) as/nzs 1249:2014 handling process
None of the strongest kings in the monitoring industry!
Improving Multimodal Accuracy Through Modality Pre-training and Attention
MATLAB小技巧(27)灰色预测