当前位置:网站首页>ICLR 2022 | 基于对抗自注意力机制的预训练语言模型
ICLR 2022 | 基于对抗自注意力机制的预训练语言模型
2022-07-06 15:33:00 【智源社区】

论文名称:
Adversarial Self-Attention For Language Understanding
ICLR 2022
https://arxiv.org/pdf/2206.12608.pdf
大量的证据表明,自注意力可以从 allowing bias 中获益,allowing bias 可以将一定程度的先验(如 masking,分布的平滑)加入原始的注意力结构中。这些先验知识能够让模型从较小的语料中学习有用的知识。但是这些先验知识一般是任务特定的知识,使得模型很难扩展到丰富的任务上。 adversarial training 通过给输入内容添加扰动来提升模型的鲁棒性。作者发现仅仅给 input embedding 添加扰动很难 confuse 到 attention maps. 模型的注意在扰动前后没有发生变化。
最大化 empirical training risk,在自动化构建先验知识的过程学习得到biased(or adversarial)的结构。 adversial 结构是由输入数据学到,使得 ASA 区别于传统的对抗训练或自注意力的变体。 使用梯度反转层来将 model 和 adversary 结合为整体。 ASA 天然具有可解释性。
边栏推荐
- Advantages of link local address in IPv6
- 2022-07-04 mysql的高性能数据库引擎stonedb在centos7.9编译及运行
- ThreadLocal详解
- config:invalid signature 解决办法和问题排查详解
- Leetcode: interview question 17.24 Maximum cumulative sum of submatrix (to be studied)
- LeetCode 练习——剑指 Offer 26. 树的子结构
- HDU 5077 NAND (violent tabulation)
- volatile关键字
- (18) LCD1602 experiment
- OpenSSL:适用TLS与SSL协议的全功能工具包,通用加密库
猜你喜欢

Aardio - 利用customPlus库+plus构造一个多按钮组件

(十八)LCD1602实验
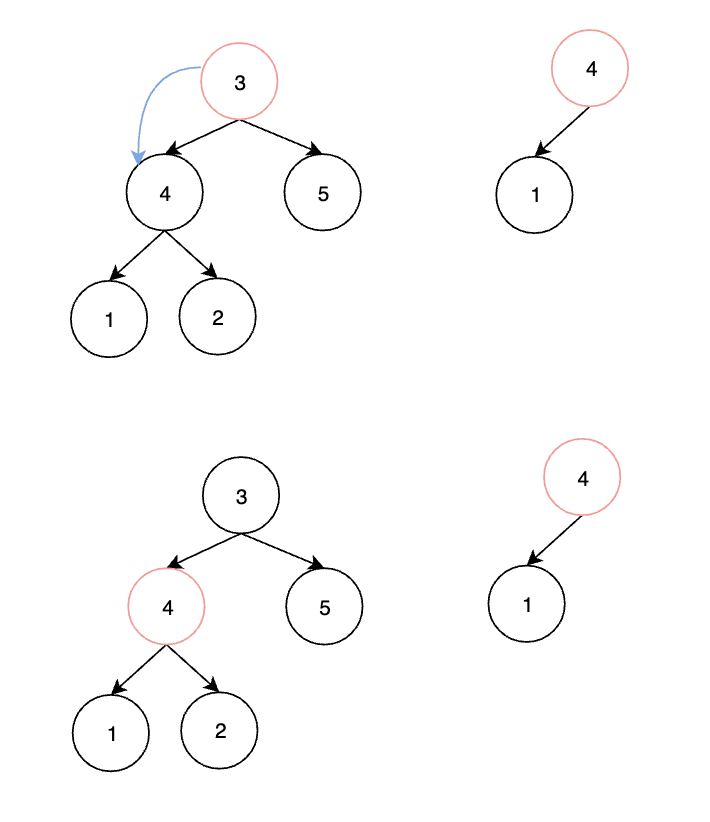
Leetcode exercise - Sword finger offer 26 Substructure of tree

树的先序中序后序遍历
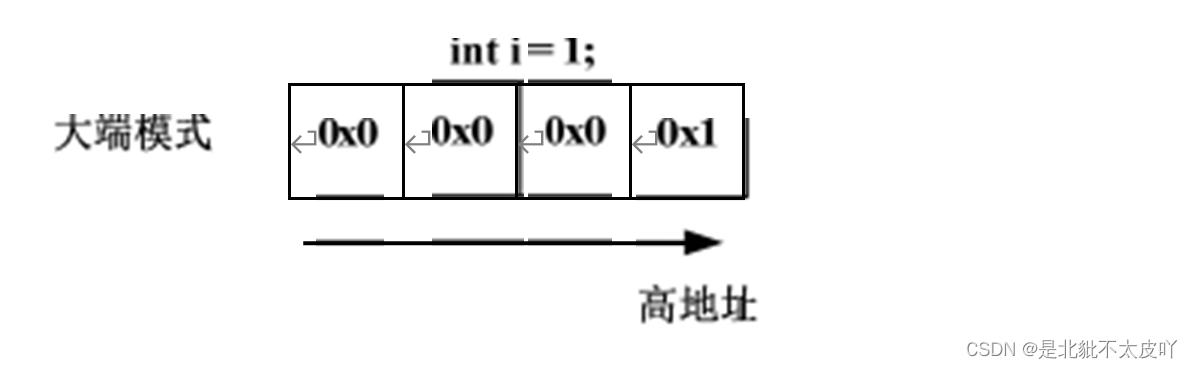
How to confirm the storage mode of the current system by program?
(18) LCD1602 experiment

Should novice programmers memorize code?

MySQL ---- first acquaintance with MySQL
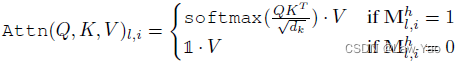
Adavit -- dynamic network with adaptive selection of computing structure
Improving Multimodal Accuracy Through Modality Pre-training and Attention
随机推荐
LeetCode 练习——剑指 Offer 26. 树的子结构
uniapp设置背景图效果demo(整理)
return 关键字
枚举与#define 宏的区别
动作捕捉用于蛇运动分析及蛇形机器人开发
void关键字
自制J-Flash烧录工具——Qt调用jlinkARM.dll方式
Use ECs to set up an agent
Adavit -- dynamic network with adaptive selection of computing structure
Aardio - 利用customPlus库+plus构造一个多按钮组件
2022-07-05 使用tpcc对stonedb进行子查询测试
Balanced Multimodal Learning via On-the-fly Gradient Modulation(CVPR2022 oral)
2022-07-04 the high-performance database engine stonedb of MySQL is compiled and run in centos7.9
Machine test question 1
NPDP certification | how do product managers communicate across functions / teams?
Aardio - Method of batch processing attributes and callback functions when encapsulating Libraries
ACL 2022 | 序列标注的小样本NER:融合标签语义的双塔BERT模型
Puppeteer连接已有Chrome浏览器
做国外LEAD2022年下半年几点建议
C# 三种方式实现Socket数据接收