当前位置:网站首页>Improving Multimodal Accuracy Through Modality Pre-training and Attention
Improving Multimodal Accuracy Through Modality Pre-training and Attention
2022-07-06 14:53:00 【Rainylt】
paper:
发现多模态模型不同模态的收敛速度不一致,于是各自单独预训练,再用attention(非self-attn)得到不同模态的权重,乘上权重后concat->FC->logits
首先讲一下这里的attention。不是self-attention那种Q*K的机制,而是直接把三个模态的feature concat后,过FC得到权重: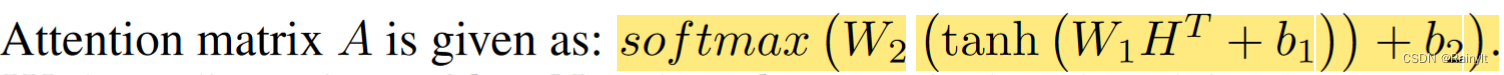
H为三个模态(v, a, t)的feature,shape为(3,m)。输出三个模态的权重
根据作者观察发现,直接训多模态模型,不同模态的Loss下降速度不一致(收敛速度):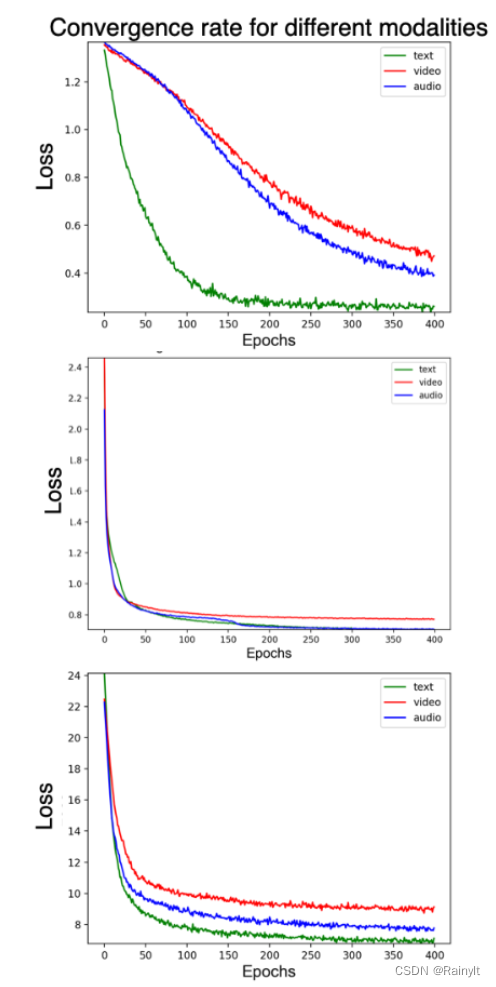
三个图是不同数据集,第二个和第三个数据集还稍微好点,第一个数据集就text收敛太快。
看不同模态的权重: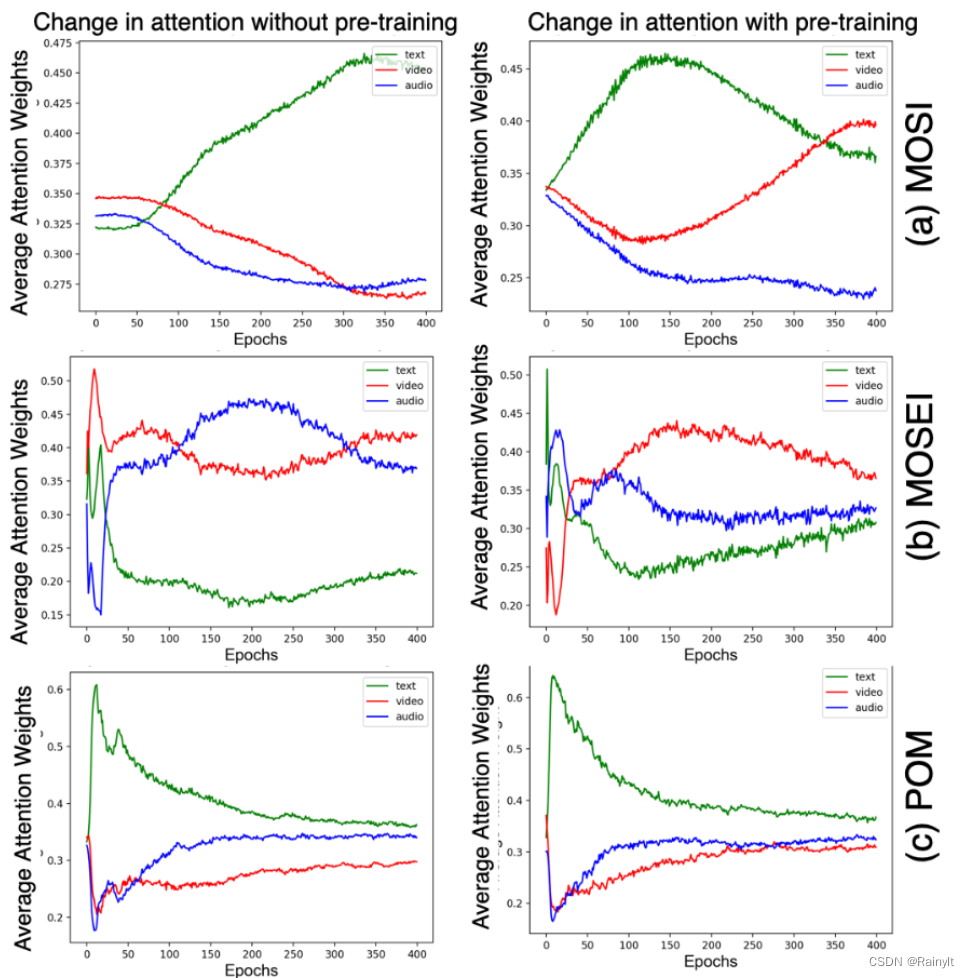
可以看到第一个数据集在预训练之前text占了大部分权重,也许因为它比较重要,也可能是因为他的feature更优质。在预训练后video赶了上来,说明video之前只是feature没怎么训好而已。
三个模态,谁更重要其实是要视具体情况而定的: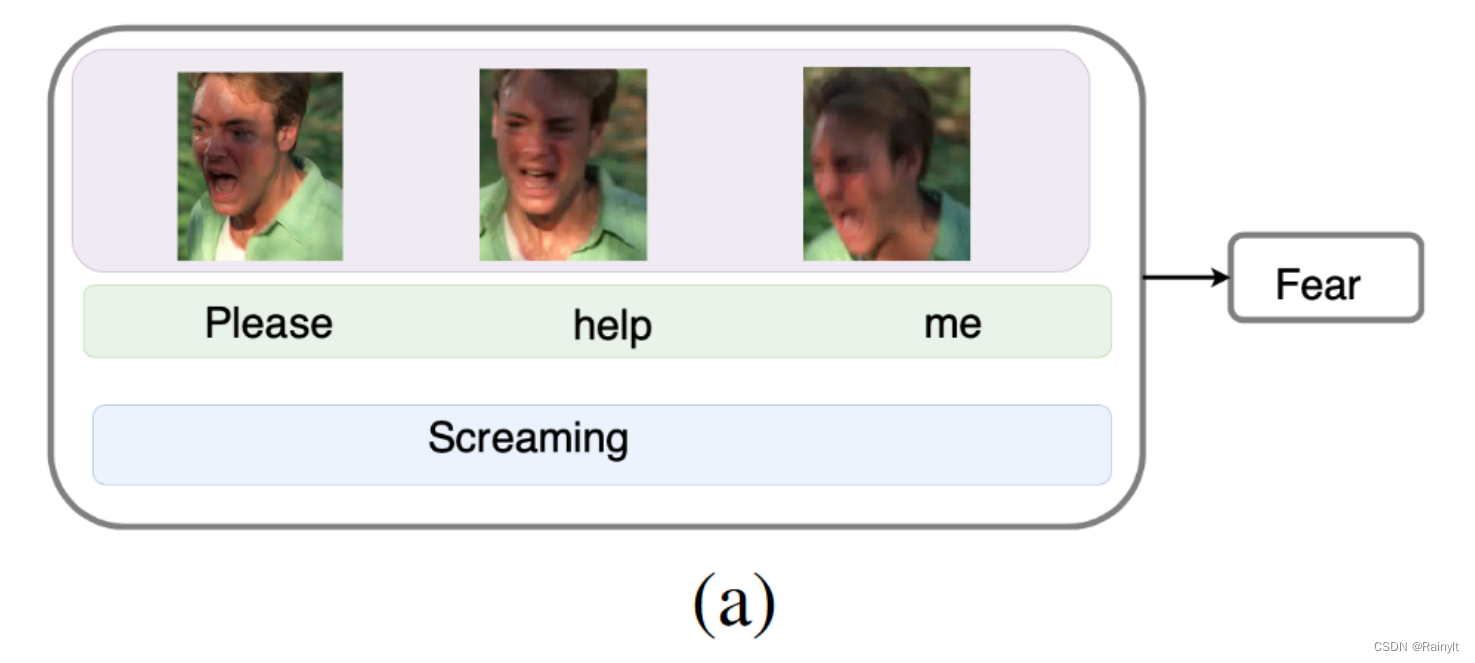
这里三种模态都能表现出害怕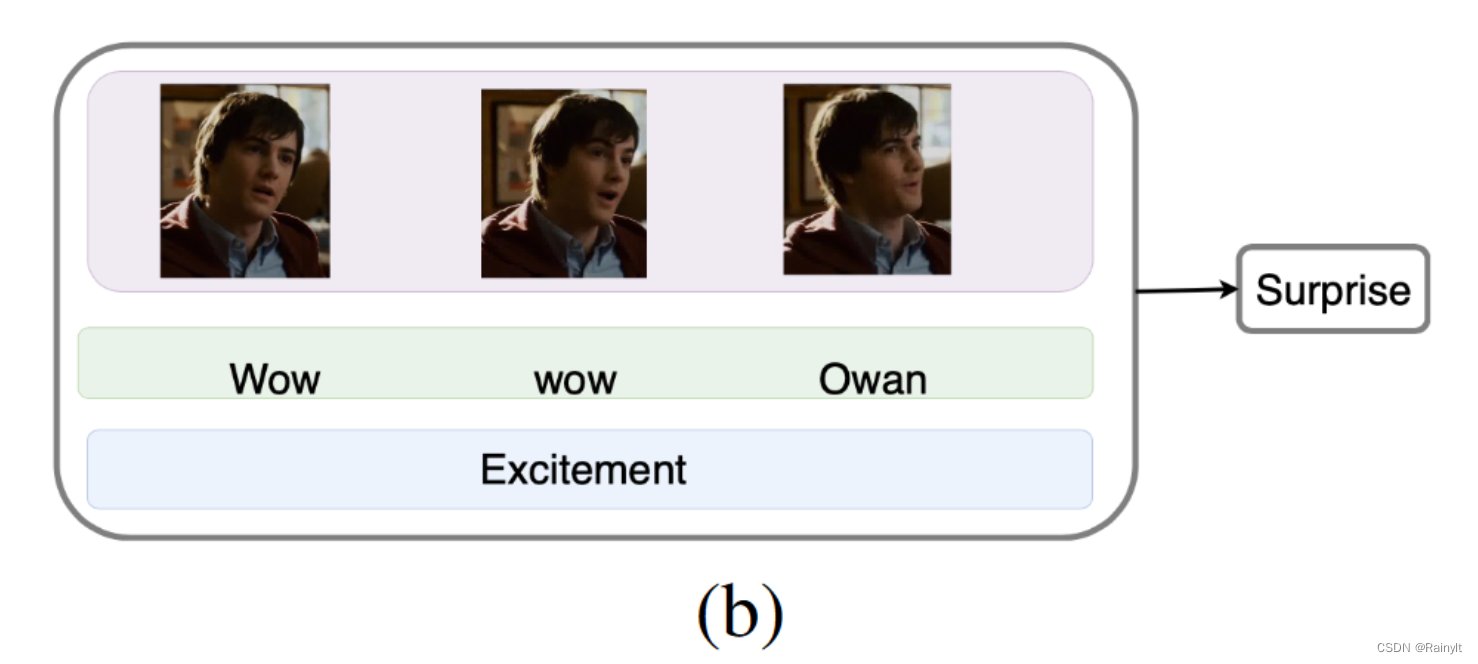
这里text和audio能表现出惊讶,但img就不行,表情比较平淡(其实不好说)
这个例子比较好,他虽然嘴上在道歉,但是实际上却在大笑,应该是一种开心的情绪,所以这里应该是audio占主导
本文提出的attention权重和这些重要性是能够对应上的:
边栏推荐
猜你喜欢
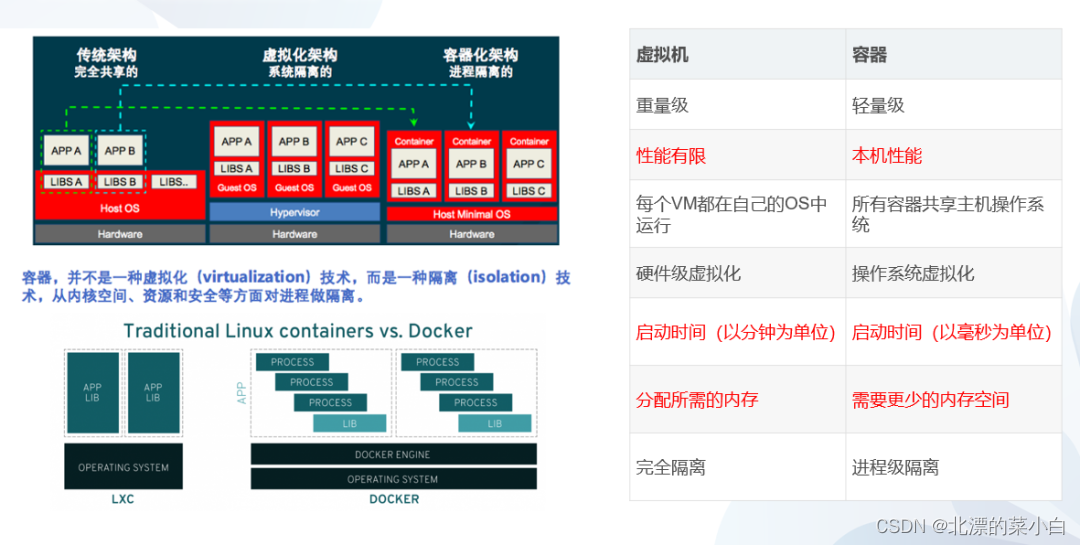
云原生技术--- 容器知识点
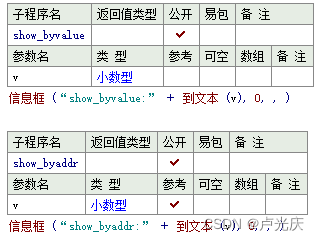
Aardio - 不声明直接传float数值的方法
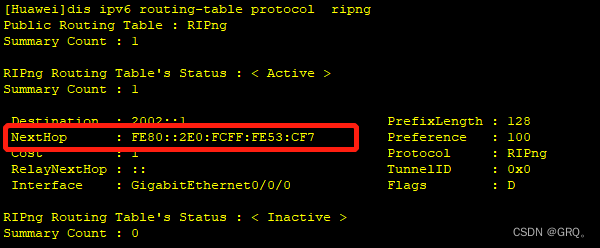
在IPv6中 链路本地地址的优势
Management background --1 Create classification
Aardio - 通过变量名将变量值整合到一串文本中

Oracle-控制文件及日志文件的管理
Clip +json parsing converts the sound in the video into text
The nearest common ancestor of binary (search) tree ●●
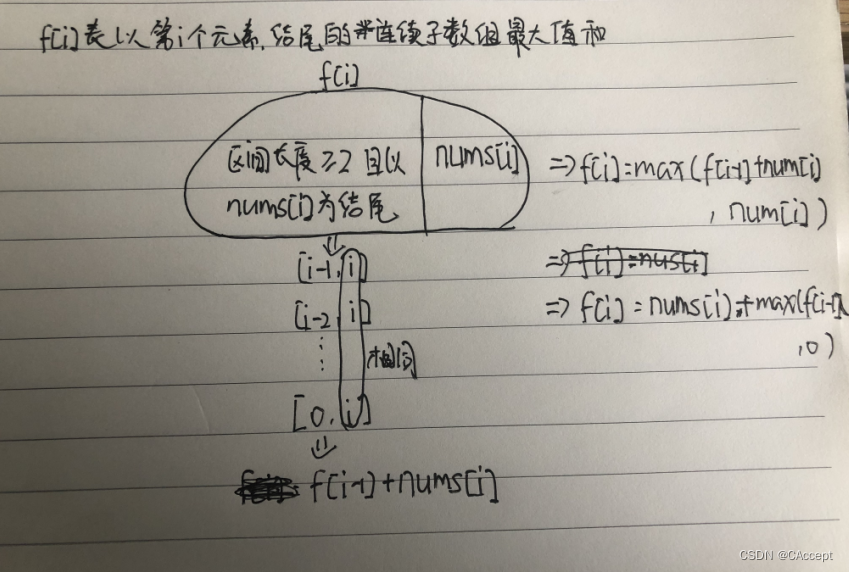
LeetCode刷题(十一)——顺序刷题51至55
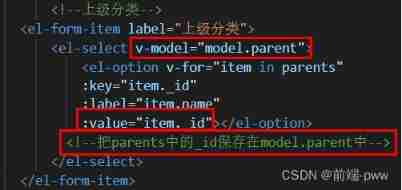
Management background --5, sub classification
随机推荐
Installation and use of labelimg
二分图判定
UDP编程
手写ABA遇到的坑
基于 QEMUv8 搭建 OP-TEE 开发环境
The nearest common ancestor of binary (search) tree ●●
第3章:类的加载过程(类的生命周期)详解
Should novice programmers memorize code?
3DMAX assign face map
[线性代数] 1.3 n阶行列式
2022-07-05 使用tpcc对stonedb进行子查询测试
OpenCV VideoCapture. Get() parameter details
2021 geometry deep learning master Michael Bronstein long article analysis
Management background --5, sub classification
2022年6月国产数据库大事记-墨天轮
SQL Server生成自增序号
Advantages of link local address in IPv6
GD32F4XX串口接收中断和闲时中断配置
【LeetCode】19、 删除链表的倒数第 N 个结点
Applet system update prompt, and force the applet to restart and use the new version