当前位置:网站首页>【编译原理】做了一半的LR(0)分析器
【编译原理】做了一半的LR(0)分析器
2022-07-06 14:49:00 【苏念心】
前言
我们的火,要把世界都点燃——《龙族》
\;\\\;\\\;
LR(0)
目标(未完成)
从文法到状态转移表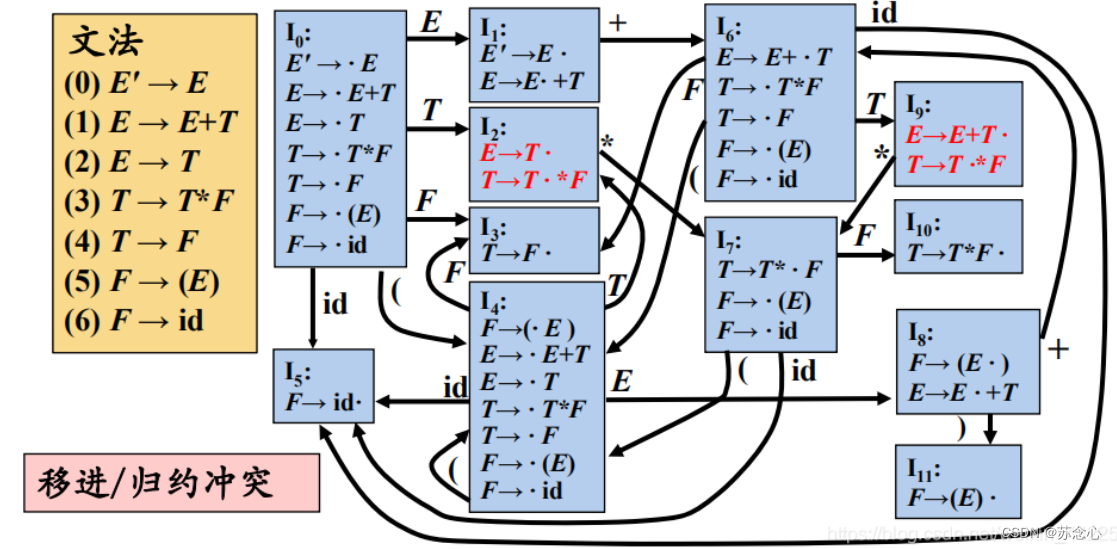
#include "LR0.h"
//项 E->E.*T
// 9 7 29
// 0 12
// dot=1
typedef struct item {
i8 vt;//非终结符 E T F
i8 production[10];//产生式,每个元素都是数字(符号)
i8 size;//0~10
i8 dot;//点的位置,0是开始,当dot==size时,就归约了
}item;
//项集I0~I11
//I0
// E'->.E
// E ->.E + T
// E ->.T
// T ->.T * F
// T ->.F
// F ->.(E)
// F ->.id
typedef struct state {
DA* vec;
i8 index; //用来标识状态号
}state;
//action-goto条目
//语法分析表到底多大,和状态个数有关,算完才知道
typedef struct unit{
//终结符 id + * ( ) $
// 0 1 2 3 4 5
i8 _action[6];
//非终结符 E T F
// 6 7 8
i8 _goto[3];
}unit;
#define Eh 9
#define E 6
#define T 7
#define F 8
#define id 0
#define add 1
#define mul 2
#define lp 3
#define rp 4
#define end 5
#define int2string(x) (x==9?"E'": \ (x==6?"E": \ (x==7?"T": \ (x==8?"F": \ (x==0?"id": \ (x==1?"+": \ (x==2?"*": \ (x==3?"(": \ (x==4?")": \ (x==5?"$":"错误"))))))))))
/* 原始文法 E ->E+T|T T ->T*F|F F ->(E)|id 增广文法 E'->.E E'=9 E ->.E+T 0 E ->.T 1 T ->.T*F 2 T ->.F 3 F ->.(E) 4 F ->.id 5 added */
/*----------------------------------------------------------------------------*/
//静态变量
char* input = "i+i*i$"; //用i代替id
DA* statelist; //所有的项集
DA* predict;//预测分析表
bool added[7]; //I0中该项是否在I中
bool self_added[7]; //.后面跟非终结符时,self_added用来判断I0某项是否加入I中。 E’->.E不算
DA* buf;//存用过的符号
state* I0;//第一个项集
/*----------------------------------------------------------------------------*/
/*----------------------------------------------------------------------------*/
//函数声明
void through(state* I);
item* new_item();
unit* new_unit();
state* new_state();
bool isVT(i8 symbol);//是否是非终结符
unit* find_unit(state* I);//state对应的预测表条目
item* move_item(item* it);//修改了dot位置
item* copy_item(item* it);//没有修改dot位置
void print_statelist();
void print_predict();
void init_self_added();//初始化self_added
bool myjudge(void* mydata, void* DAdata);
/*----------------------------------------------------------------------------*/
void exec_LR0() {
/*---------------------------------------*/
predict = newDA(11);
statelist = newDA(11);
/*---------------------------------------*/
/*---------------------------------------*/
I0 = new_state();
I0->index = 0; //I0
pushDA(statelist, I0);
pushDA(predict, new_unit());
/*---------------------------------------*/
/*---------------------------------------*/
item* i_0 = new_item();
//E'->.E
i_0->vt = Eh;
i_0->production[0] = E;
i_0->size = 1;
pushDA(I0->vec, i_0);
item* i_2 = new_item();
//E ->.T
i_2->vt = E;
i_2->production[0] = T;
i_2->size = 1;
pushDA(I0->vec, i_2);
item* i_1 = new_item();
//E ->.E + T
i_1->vt = E;
i_1->production[0] = E;
i_1->production[1] = add;
i_1->production[2] = T;
i_1->size = 3;
pushDA(I0->vec, i_1);
item* i_4 = new_item();
//T ->.F
i_4->vt = T;
i_4->production[0] = F;
i_4->size = 1;
pushDA(I0->vec, i_4);
item* i_5 = new_item();
//F ->.(E)
i_5->vt = F;
i_5->production[0] = lp;
i_5->production[1] = E;
i_5->production[2] = rp;
i_5->size = 3;
pushDA(I0->vec, i_5);
item* i_6 = new_item();
//F ->.id
i_6->vt = F;
i_6->production[0] = id;
i_6->size = 1;
pushDA(I0->vec, i_6);
item* i_3 = new_item();
//T ->.T * F
i_3->vt = T;
i_3->production[0] = T;
i_3->production[1] = mul;
i_3->production[2] = F;
i_3->size = 3;
pushDA(I0->vec, i_3);
//item* i_7 = new_item();
F ->.(id)
//i_7->vt = F;
//i_7->production[0] = lp;
//i_7->production[1] = T;
//i_7->production[2] = rp;
//i_7->size = 3;
//pushDA(I0->vec, i_7);
/*---------------------------------------*/
//第一轮生成I_1、I_2、I_3、I_4、I_5
through(I0);
print_statelist();
print_predict();
}
void through(state* I) {
ASSERT(I == null, "I为空");
ASSERT(I->vec->size > I0->vec->size, "I(%d)项集中项太多", I->index);
//初始化added和self_added
for (i8 i = 0; i < 7; ++i)
added[i] = false;
///遍历I0中的项1
for (u8 i = 0; i < I->vec->size; ++i) {
if (added[i] == true) //此项已经加过了
continue;
item* it = (item*)(I->vec->v[i]);
if (it->dot == it->size) //此项已经结束
continue;
i8 X = it->production[0]; //首字符
//1.
added[i] = true; //此项已经加过了
///定义新项集I_1
state* new_I = new_state();
///将E'->E.加入I_1
pushDA(new_I->vec, move_item(it));
new_I->index = statelist->size;
pushDA(statelist, new_I);
//2.
//有相同符号X的其他项也加入I_1
///遍历I0中的项2
for (i8 j = 0; j < I->vec->size; ++j) {
if (added[j] == true) //此项已经加过了
continue;
item* it2 = (item*)(I->vec->v[j]);
if (it2->dot == it2->size)
continue;
i8 X2 = it2->production[0]; //首字符
if (X2 == X) {
added[j] = true; //此项已经加过了
///将E'->E.+T加入I_1
pushDA(new_I->vec, move_item(it2));
}
}
//3.
//设置上一个状态I_0的条目的跳转表
///Goto(I_0,I_1)=X
unit* t = find_unit(I); //前面的项集对应的条目
if (isVT(X)) //非终结符
t->_goto[X - E] = new_I->index;//指向当前状态
else
t->_action[X] = new_I->index;
pushDA(predict, new_unit()); //当前条目不设置
//4.
//有时候.后面有非终结符VT,需要把该符号1的所有项加入
//如果新加入的.后面(首字符)还有非终结符VT,还需要把该符号2的所有项加入
//直到.后面没有非终结符
///遍历I_4的项3
//用来处理.后面跟非终结符
init_self_added();
buf = newDA(10);
for (i4 k = 0; k < new_I->vec->size; ++k) {
item* it3 = (item*)new_I->vec->v[k];
if (it3->dot == it3->size)
continue;
i8 X3 = it3->production[it3->dot]; //dot位置字符
//如果是新符号并且是非终结符就存入
if (haveDA(buf, X3, myjudge) == false && isVT(X3) == true)
pushDA(buf, X3);
//是非终结符
//一般一轮就结束了,k不会走第二轮
while (isVT(X3)) {
//遍历I_0
//不能遍历E'->.E
for (i8 l = 1; l < I0->vec->size; ++l) {
if (self_added[l] == true)
continue;
item* it4 = (item*)I->vec->v[l];
if (it4->dot == it4->size)
continue;
i8 X4 = it4->vt; //左边非终结符
if (X4 == X3) {
self_added[l] = true;
///将E'->.E+T加入I_4
pushDA(new_I->vec, copy_item(it4));
//如果是新符号就存入
if(haveDA(buf,it4->production[0],myjudge)==false)
pushDA(buf, it4->production[0]);
}
}
//把第一级的几项加入了I_4
//但是新加入的项中的.后面还有非终结符
X3 = buf->v[buf->size - 1]; //最后一个符号是新的
}
}
}
destroyDA(buf);
}
item* new_item() {
item* it = (item*)malloc(sizeof(item));
ASSERT(it == null, "item创建失败");
it->dot = 0;
for (i4 i = 0; i < 10; ++i)
it->production[i] = 0;
it->vt = -1;
it->size = 0;
return it;
}
unit* new_unit() {
unit* it = (unit*)malloc(sizeof(unit));
ASSERT(it == null, "unit创建失败");
for (i4 i = 0; i < 6; ++i)
it->_action[i] = 0;
for (i4 i = 0; i < 3; ++i)
it->_goto[i] = 0;
return it;
}
state* new_state() {
state* it = (state*)malloc(sizeof(state));
ASSERT(it == null, "state创建失败");
it->vec = newDA(11);
it->index = -1;
return it;
}
bool isVT(i8 symbol) {
//是否是非终结符
if (symbol == E || symbol == T || symbol == F)
return true;
return false;
}
unit* find_unit(state* I) {
ASSERT(I == null, "I为空");
return predict->v[I->index];
}
item* move_item(item* it) {
ASSERT(it == null, "item为空");
item* iter = new_item();
iter->dot = it->dot + 1; ///修改了dot位置
for (i4 i = 0 ;i < 10;++i)
iter->production[i] = it->production[i];
iter->vt = it->vt;
iter->size = it->size;
return iter;
}
item* copy_item(item* it) {
ASSERT(it == null, "item为空");
item* iter = new_item();
iter->dot = it->dot ; ///没有修改dot位置
for (i4 i = 0; i < 10; ++i)
iter->production[i] = it->production[i];
iter->vt = it->vt;
iter->size = it->size;
return iter;
}
void print_statelist() {
if (statelist->size == 0) {
printf("无状态\n");
return;
}
printf("--------------------\n");
for (i4 i = 0;i<statelist->size; ++i) {
state* s = (state*)statelist->v[i];
printf("I%d\n", i);
for (i4 j = 0;j<s->vec->size; ++j) {
item* it = (item*)s->vec->v[j];
printf("\t%s->", int2string(it->vt));
i4 k = 0;
for (; k < it->size; ++k) {
if (it->dot == k)
printf(".");
printf("%s", int2string(it->production[k]));
}
if (it->dot == k)
printf(".");
printf("\n");
}
}
printf("--------------------\n");
}
void print_predict() {
printf("-------------------------------------\n");
printf("\t ACTION \t| GOTO\n");
printf(" id + * ( ) $ | E T F\n");
for (i4 i=0;i<predict->size;++i) {
printf("[%-2d] ", i);
unit* u = (unit*)predict->v[i];
for (i4 j = 0; j < 6; ++j)
printf("%3d",u->_action[j]);
printf(" |");
for (i4 j = 0; j < 3; ++j)
printf("%3d", u->_goto[j]);
printf("\n");
}
printf("-------------------------------------\n");
}
void init_self_added() {
self_added[0] = true;
self_added[1] = false;
self_added[2] = false;
self_added[3] = false;
self_added[4] = false;
self_added[5] = false;
self_added[6] = false;
}
bool myjudge(void* mydata, void* DAdata) {
i8 d1 = (i8)mydata;
i8 d2 = (i8)DAdata;
if (mydata == DAdata)
return true;
return false;
}
\;\\\;\\\;
效果
只分析了一轮,从I0到I1~I5
第二轮应该是I1~I5
第三轮
第四轮
直到所有的项集中,所有的项都处理完了。
我这个程序,每次都新建一个项集,所有处理二轮内存会爆炸。处理方法是每此更改项后判断之前所有的项集中的项,是否有一样的,有的话就指向。没有就新建新的项集。
--------------------
I0
E'->.E E->.T E->.E+T T->.F F->.(E) F->.id T->.T*F I1 E'->E.
E->E.+T
I2
E->T.
T->T.*F
I3
T->F.
I4
F->(.E)
E->.T
E->.E+T
T->.F
T->.T*F
F->.(E)
F->.id
I5
F->id.
--------------------
-------------------------------------
ACTION | GOTO
id + * ( ) $ | E T F
[0 ] 5 0 0 4 0 0 | 1 2 3
[1 ] 0 0 0 0 0 0 | 0 0 0
[2 ] 0 0 0 0 0 0 | 0 0 0
[3 ] 0 0 0 0 0 0 | 0 0 0
[4 ] 0 0 0 0 0 0 | 0 0 0
[5 ] 0 0 0 0 0 0 | 0 0 0
-------------------------------------
边栏推荐
- Mise en place d'un environnement de développement OP - tee basé sur qemuv8
- void关键字
- Daily question 1: force deduction: 225: realize stack with queue
- Classification, function and usage of MySQL constraints
- PVL EDI 项目案例
- CCNA Cisco network EIGRP protocol
- MySQL约束的分类、作用及用法
- Attack and defense world miscall
- 每日一题:力扣:225:用队列实现栈
- Unity3d minigame-unity-webgl-transform插件转换微信小游戏报错To use dlopen, you need to use Emscripten‘s...问题
猜你喜欢
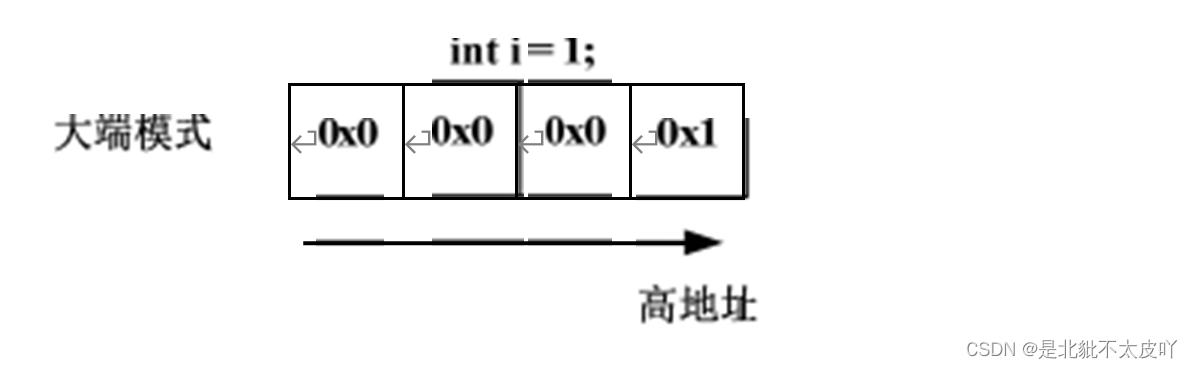
如何用程序确认当前系统的存储模式?
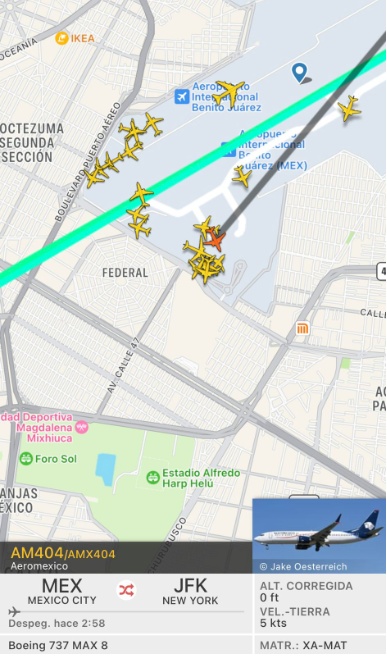
墨西哥一架飞往美国的客机起飞后遭雷击 随后安全返航
PVL EDI project case

Oracle control file and log file management
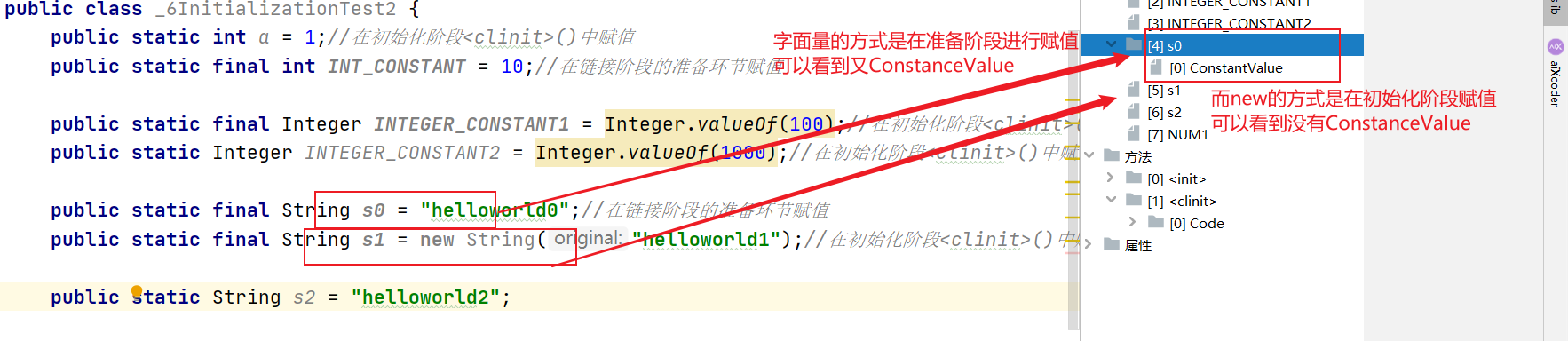
第3章:类的加载过程(类的生命周期)详解
Chapter 3: detailed explanation of class loading process (class life cycle)
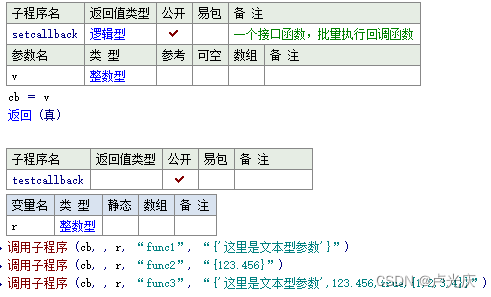
Aardio - 封装库时批量处理属性与回调函数的方法
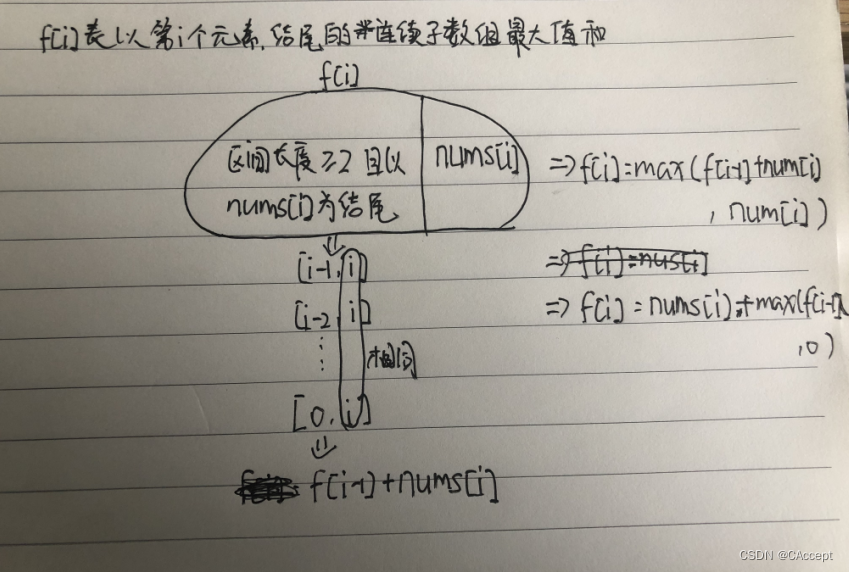
LeetCode刷题(十一)——顺序刷题51至55
![[linear algebra] determinant of order 1.3 n](/img/6e/54f3a994fc4c2c10c1036bee6715e8.gif)
[linear algebra] determinant of order 1.3 n
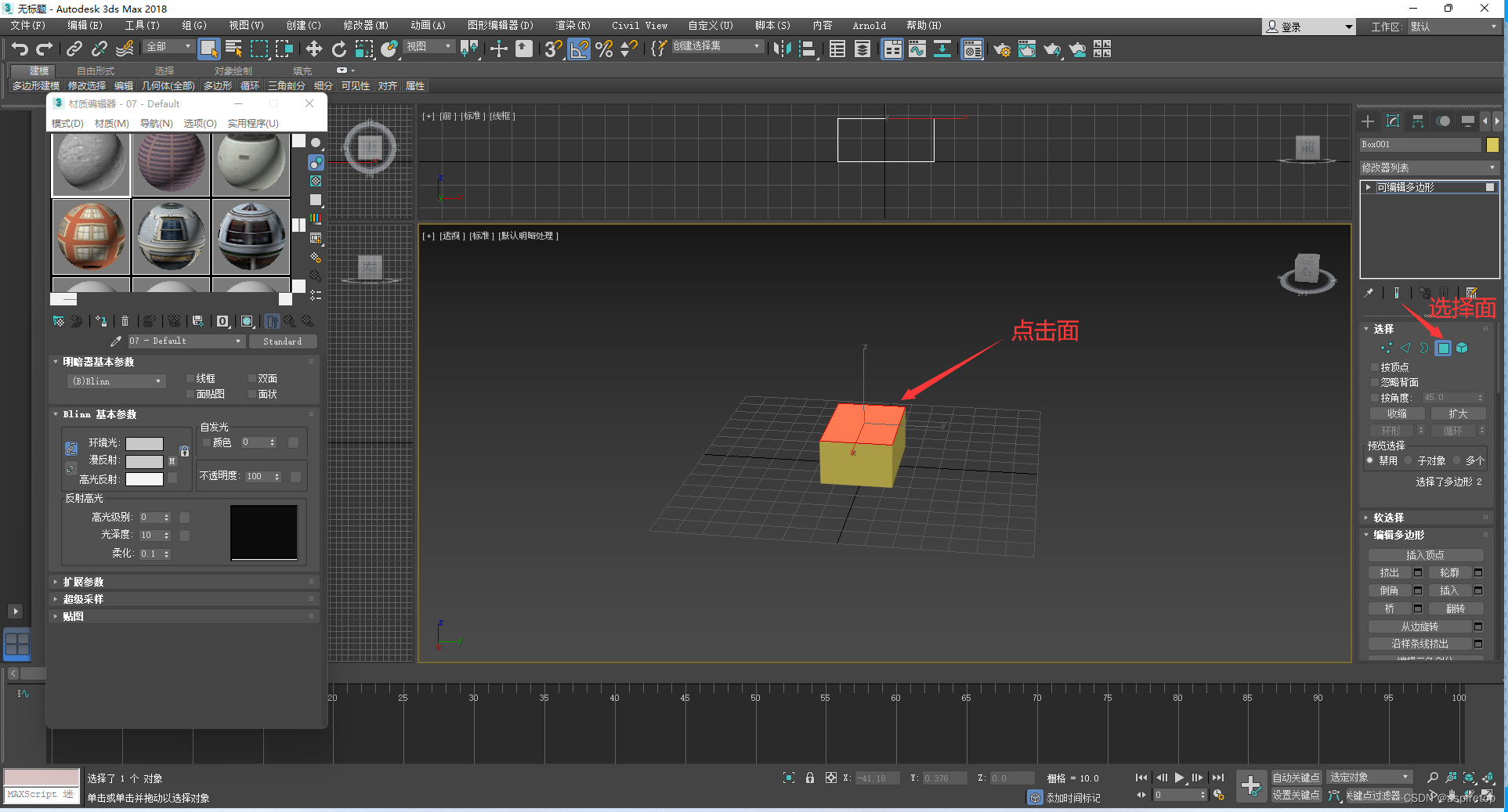
3DMax指定面贴图
随机推荐
【sdx62】WCN685X将bdwlan.bin和bdwlan.txt相互转化操作方法
Dealing with the crash of QT quick project in offscreen mode
Spatial domain and frequency domain image compression of images
小程序系统更新提示,并强制小程序重启并使用新版本
每日一题:力扣:225:用队列实现栈
手写ABA遇到的坑
A Mexican airliner bound for the United States was struck by lightning after taking off and then returned safely
0 basic learning C language - digital tube
Leetcode question brushing (XI) -- sequential questions brushing 51 to 55
NetXpert XG2帮您解决“布线安装与维护”难题
2021 geometry deep learning master Michael Bronstein long article analysis
CCNA-思科网络 EIGRP协议
二分图判定
Learn the principle of database kernel from Oracle log parsing
Unity3d minigame-unity-webgl-transform插件转换微信小游戏报错To use dlopen, you need to use Emscripten‘s...问题
NPDP认证|产品经理如何跨职能/跨团队沟通?
C#實現水晶報錶綁定數據並實現打印4-條形碼
C # réalise la liaison des données du rapport Crystal et l'impression du Code à barres 4
lora同步字设置
pytorch_ Yolox pruning [with code]