当前位置:网站首页>HDR image reconstruction from a single exposure using deep CNNs阅读札记
HDR image reconstruction from a single exposure using deep CNNs阅读札记
2022-07-06 14:11:00 【Cassia tora】
HDR image reconstruction from a single exposure using deep CNNs阅读札记
论文发表于2017年的TOG。
1 Abstract
问题:
低动态范围(LDR)设备捕获高动态范围(HDR)场景图像容易出现过曝光问题,过曝光区域会失去纹理细节,给图像观赏或计算机视觉任务带来挑战。
现状:
现有的大多数HDR图像重建方法都需要一组不同曝光的LDR图像作为输入。
本文方法:
解决了图像饱和区域中丢失信息的估计问题,以便能够从单次曝光的LDR图像重建高质量的HDR图像。
(1)LDR输入图像由编码器网络转换,以产生图像空间上下文的紧凑特征表示。
(2)将编码图像馈送到在对数域中运行的HDR解码器网络,以重建HDR图像。
该网络配备了跳跃连接,可在LDR编码器和HDR解码器域之间传输数据,以便在重建中充分利用高分辨率图像细节。
2 HDR Reconstruction Model
2.1 问题的公式化和约束(Problem formulation and constraints)
最终HDR重构像素 H ^ ( i , c ) \hat{H}_{(i,c)} H^(i,c),是使用混合值(blend value) α i α_i αi的像素级混合(blending)计算得到的,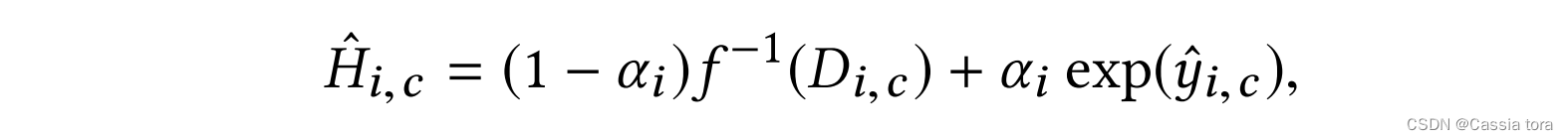
i i i:空间索引
c c c:颜色通道
D ( i , c ) D_{(i,c)} D(i,c):输入LDR图像像素
y ^ ( i , c ) \hat{y} _{(i,c)} y^(i,c):CNN输出(在对数域中):
f ( − 1 ) f^{(-1)} f(−1):逆相机曲线,将输入变换到线性域。
混合(blending)是一个线性斜坡,从阈值 τ τ τ的像素值开始,到最大像素值结束(混合意味着输入图像在非饱和区域保持不变),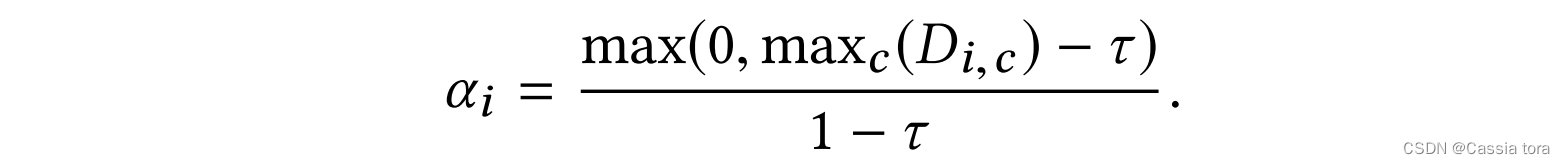
本文使用 τ = 0.95 τ=0.95 τ=0.95,输入定义在 [ 0 , 1 ] [0,1] [0,1]范围内。
线性混合(linear blending)防止了预测的高光与其周围环境之间的带状伪影( α α α还用于定义训练中的损失函数,如第2.4节所述)。
混合分量的说明如下图所示(由于混合预测的重点是饱和区域周围的重建,因此其他图像区域可能会出现伪影(图(b))):
2.2 混合动态范围自动编码器(Hybrid dynamic range autoencoder)
完整的自动编码器架构如图所示: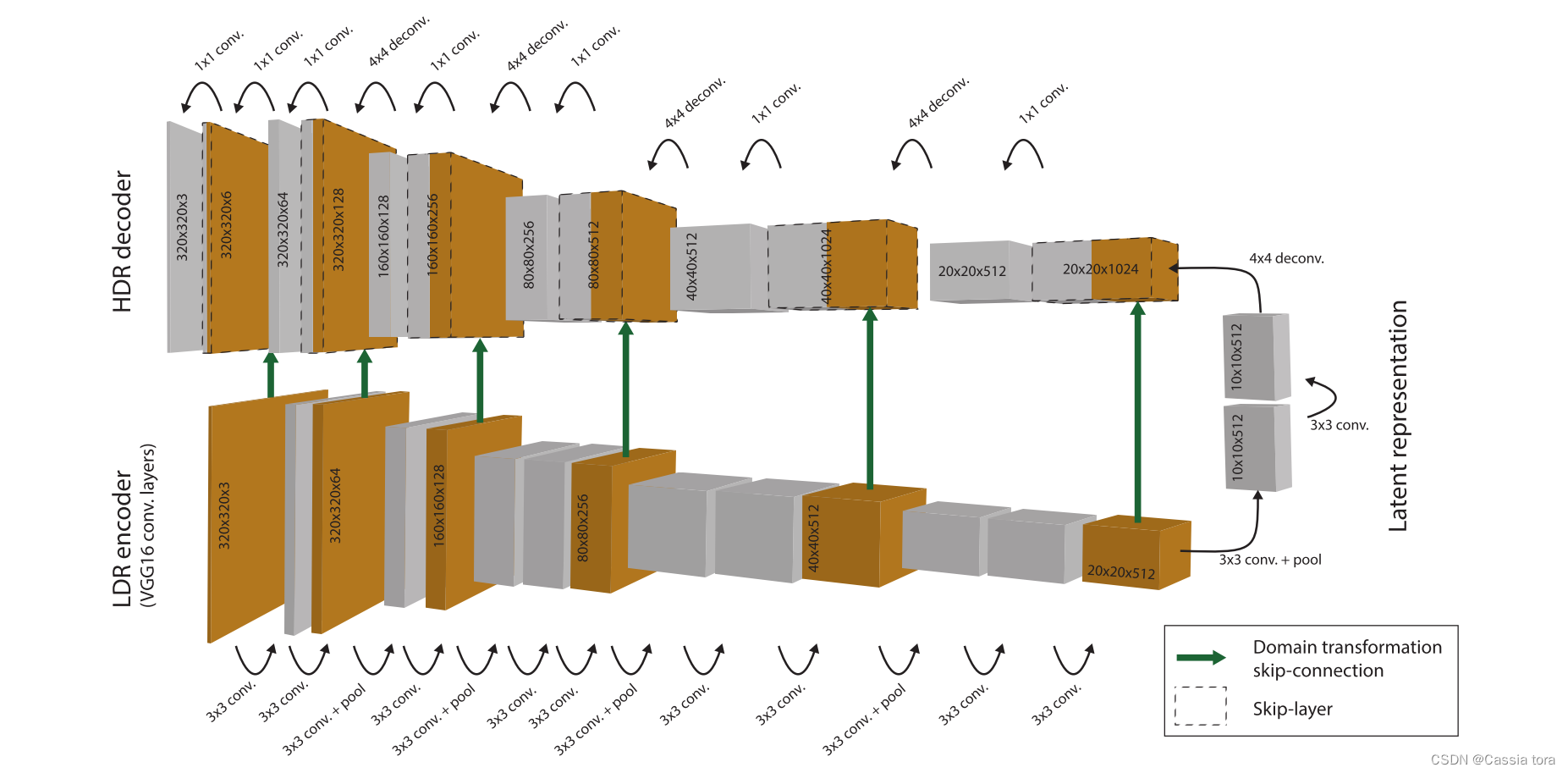
LDR encoder:对输入的LDR图像进行卷积和最大池化,最终生成 W / 32 × H / 32 × 512 W/32 ×H/32 ×512 W/32×H/32×512的低维潜像表示(latent image representation)( W W W和 H H H分别为图像宽度和高度)。
HDR decoder:使用 4 × 4 4×4 4×4的反卷积层实现双线性上采样,将上采样的结果与编码器对应层进行跳跃连接(更好的恢复图像细节),对跳跃连接结果进行卷积;重复以上操作,最终重建高维HDR图像。
(1)由于本文目标是重建比训练中实际使用的图像更大的图像,因此潜在表示不是完全连接层,而是低分辨率多通道图像。这种全卷积网络 (FCN) 可以在任何分辨率下进行预测,该分辨率是自动编码器缩减因子的倍数。
(2)因为编码器直接对LDR输入图像进行操作,解码器负责生成HDR数据,所以解码器在对数域中工作(这是通过使用损失函数来实现的,该函数将网络输出与HDR gt图像的对数进行比较)。
(3)网络的所有层都使用ReLU激活函数,在解码器的每一层之后使用批量规一化层。
2.3 域变换与跳跃连接(Domain transformation and skip-connections)
输入图像的层层卷积池化会导致早期层种的许多高分辨率信息丢失,解码器可使用这些信息来重建饱和区域的高频细节,因此引入跳跃连接,用于在编码器和解码器中的高层和低层特征之间传输数据。
本文的自动编码器使用跳跃连接将编码器的每个层传输到解码器端的相应层。由于编码器和解码器处理不同类型的数据(见第2.2节),连接包括由逆相机曲线描述的域变换和对数变换,将LDR显示值映射到对数HDR表示。本文使用伽马函数 f − 1 ( x ) = x γ f^{-1} (x)=x^γ f−1(x)=xγ来完成跳跃连接的线性化,其中 γ = 2 γ=2 γ=2。
本文沿着特征维度连接两个层,即两个 W × H × K W×H×K W×H×K维层连接为 W × H × 2 K W×H×2K W×H×2K层。然后解码器将这些特征进行线性组合,相当于通过 1 × 1 1×1 1×1的卷积层将 2 K 2K 2K特征数减少为 K K K。完整的LDR到HDR跳跃连接定义为: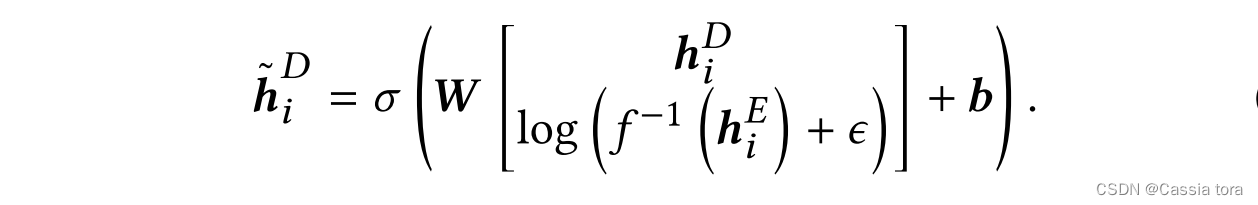
h i E , h i D h_i^E,h_i^D hiE,hiD:编码器层和解码器层张量 y E , y D ∈ R ( W × H × K ) y^E,y^D∈R^(W×H×K) yE,yD∈R(W×H×K)的所有特征通道 k ∈ 1 , . . . , K k∈{1,...,K} k∈1,...,K上的切片
h ~ i D \tilde{h} _i^D h~iD:解码器特征向量,其具有从跳跃连接向量 h i E h_i^E hiE融合的信息
b b b:特征融合的偏差
σ σ σ:激活函数,本文使用ReLU函数
(在域变换中使用小常数 ϵ ϵ ϵ以避免对数变换中的零值。)
给定 K K K个特征, h E 和 h D h^E和h^D hE和hD是 1 × K 1×K 1×K个向量, W W W是一个 2 K × K 2K×K 2K×K的权重矩阵,它将 2 K 2K 2K个串联的特征映射到 K K K维。它被初始化以执行编码器和解码器特征的添加,将权重设置为
添加跳跃连接可以更好地重建图像纹理细节,如图所示:
2.4 HDR损失函数(HDR loss function)
直接损失 L ( y ^ , H ) L(\hat{y},H) L(y^,H):
在本文系统中,HDR解码器被设计为在对数域中运行。因此,在给定预测的对数HDR图像 y ^ \hat{y} y^和线性gt图像H的情况下,直接损失在对数HDR值上被公式化,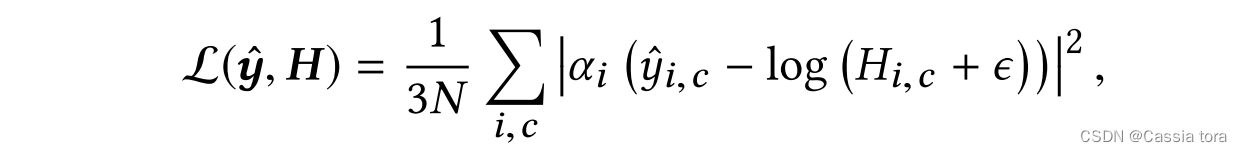
N N N:像素数
H ( i , c ) H_{(i,c)} H(i,c): H ( i , c ) ∈ R + H_{(i,c)}∈\mathbb{R}^+ H(i,c)∈R+
ϵ ϵ ϵ:小常数,消除零像素值处的奇异性
Weber-Fechner定律暗示了物理亮度和感知亮度之间的对数关系,因此在对数域中制定的损失使感知误差在整个亮度范围内大致均匀分布。
I/R损失 L I R ( y ^ , H ) L_{IR}(\hat{y} ,H) LIR(y^,H):
分开处理照度和反射率分量是有意义的,因此本文提出另一种损失函数,分别处理照度和反射率。照明分量 I I I描述全局变化,并且负责高动态范围;反射率 R R R存储关于细节和颜色的信息,这具有较低的动态范围, H ( i , c ) = I i R ( i , c ) H_{(i,c)}=I_iR_{(i,c)} H(i,c)=IiR(i,c)。通过对数亮度 L y ^ L^{\hat{y}} Ly^的高斯低通滤波器 G σ G_σ Gσ来近似对数照度,通过预测的对数HDR图像 y ^ \hat{y} y^和对数照度之间的差值来近似对数反射率,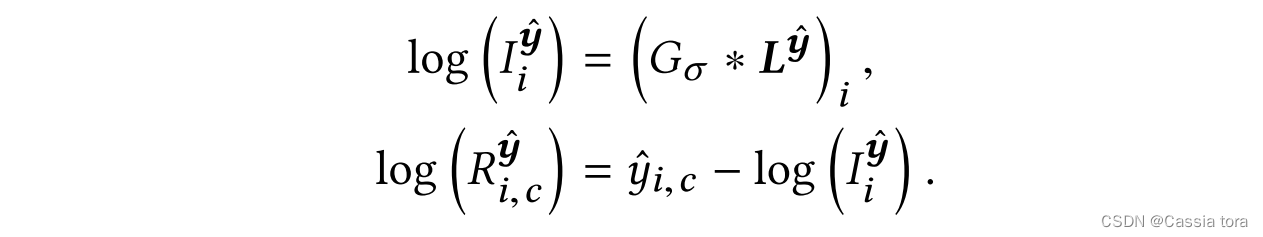
L y ^ L^{\hat{y}} Ly^:颜色通道的线性组合, L i y ^ = l o g ( ∑ c w c e x p ( y ^ i , c ) ) L^{\hat{y}}_i=log(∑_cw_c exp(\hat{y}_{i,c} ) ) Liy^=log(∑cwcexp(y^i,c)),其中 w = { 0.213 , 0.715 , 0.072 } w=\{0.213,0.715,0.072\} w={ 0.213,0.715,0.072}。
高斯滤波器的标准偏差设置为 σ = 2 σ=2 σ=2。
使用 I I I和 R R R得到的损失函数定义为: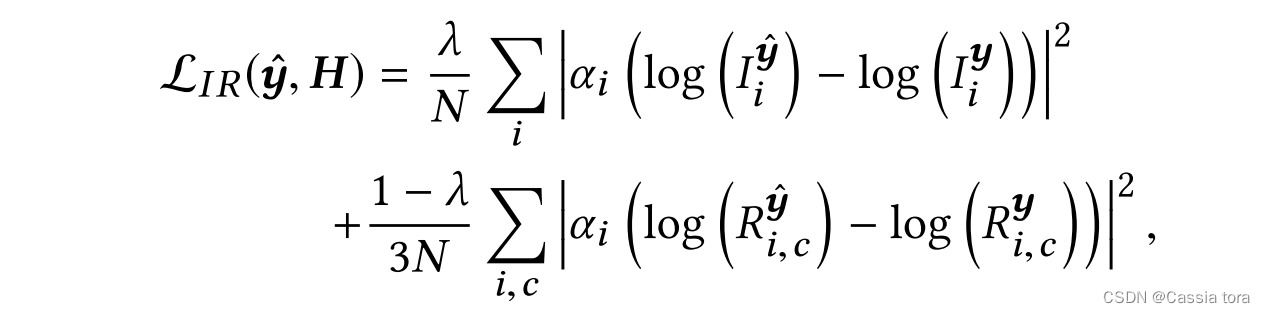
y y y: y = l o g ( H + ϵ ) y=log(H+ϵ) y=log(H+ϵ)
λ λ λ:平衡参数,平衡照度和反射率的重要度。
本文使用 λ = 0.5 λ=0.5 λ=0.5。
使用不同 λ λ λ值进行优化的预测示例结果如图所示:
使用I/R损失,在大的饱和区域中,它往往会产生较少的伪影,如图所示(一种可能的解释是,损失函数中的高斯低通滤波器可能具有正则化效应,因为它使像素中的损失受到其邻域的影响):
3 HDR Image Dataset
下图显示了两个典型LDR数据集以及125K图像的HDR数据集的平均直方图。LDR数据分别由约2.5M和200K的Places和Flickr图像组成,HDR数据由虚拟相机从HDR数据集中捕获得到。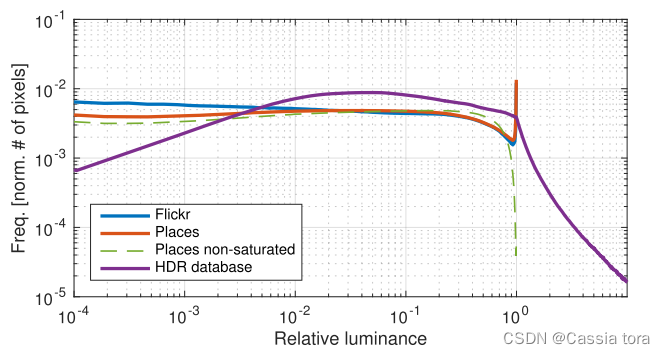
LDR直方图显示出像素值的相对均匀分布,除了接近最大值的明显峰值,表示由于饱和而丢失的信息。HDR直方图中,像素没有饱和,而是由指数衰减的长尾表示。
虚拟相机:
使用随机选择的相机校准来捕获场景的多个随机区域。这些区域被选择为具有随机大小和位置的图像裁剪,然后随机翻转并重新采样到320×320像素。相机校准包括曝光、相机曲线、白平衡和噪声级等参数。这为本文方法提供了一组增广的LDR和相应的HDR图像,分别用作训练的输入和gt值。
4 Training
初始化网络中的权重,本文对网络的不同部分使用不同的策略。
(1)由于使用来自VGG16网络的卷积层,于是可以在Places数据库中使用可用于大规模图像分类的预训练权重来初始化编码器。
(2)使用解码器反卷积以进行双线性上采样,并使用跳跃连接层的融合以执行特征添加。
(3)对于潜在图像表示(网络结构图最右侧)和最终特征缩减(网络结构图左上角)中的卷积,本文使用Xavier初始化。
(4)使用Adam优化器对I/R损失函数进行最小化,学习率为 5 × 1 0 − 5 5×10^{−5} 5×10−5。总共执行了800K步反向传播,批量大小为8,在NVIDIA Titan X GPU上大约需要6天。
4.1 模拟HDR数据的预训练(Pre-training on simulated HDR data)
由于现有的HDR数据有限,本文作者通过在大型模拟HDR数据集上预先训练整个网络来使用迁移学习。本文选择Places数据库中图像的子集,要求图像不应包含饱和图像区域。给定所有Places图像的集合P,该子集 S ⊂ P \mathbb{S}⊂\mathbb{P} S⊂P被定义为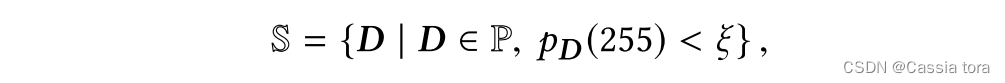
p D p_D pD:图像直方图
ξ ξ ξ:本文使用 ξ = 50 / 25 6 2 ξ=50/256^2 ξ=50/2562(即如果小于50个像素(图像 25 6 2 256^2 2562个像素的0.076%)具有最大值,则在训练集中使用该图像)。
下图绿色虚线与橙色实现对比可以看出,子集 S \mathbb{S} S上的平均直方图没有显示原始集 P \mathbb{P} P的饱和像素峰值: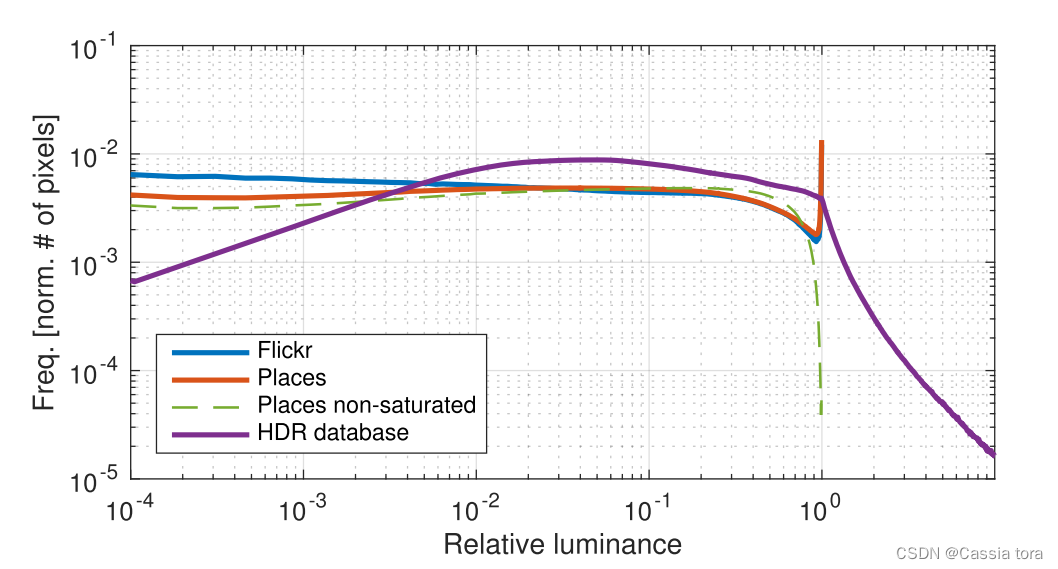
通过将图像 D ∈ S D∈\mathbb{S} D∈S进行 H = s f − 1 ( D ) H=sf^{-1} (D) H=sf−1(D)线性化并增加曝光,创建一个模拟HDR训练数据集。
模拟HDR数据集的准备方式与第3节中相同,但分辨率为224×224像素,无需重新采样。CNN使用ADAM优化器进行训练,学习率为 2 × 1 0 − 5 2×10^{-5} 2×10−5,共执行3.2M 步,批量为4。
这种对合成数据的预培训的结果导致了性能的显著提高。如下图所示,有时被低估的小高光可以更好地恢复,并且在较大的饱和区域中引入的伪影较少:
5 Result
5.1 测试误差(Test errors)
下表显示了不同的训练策略对不同误差的影响: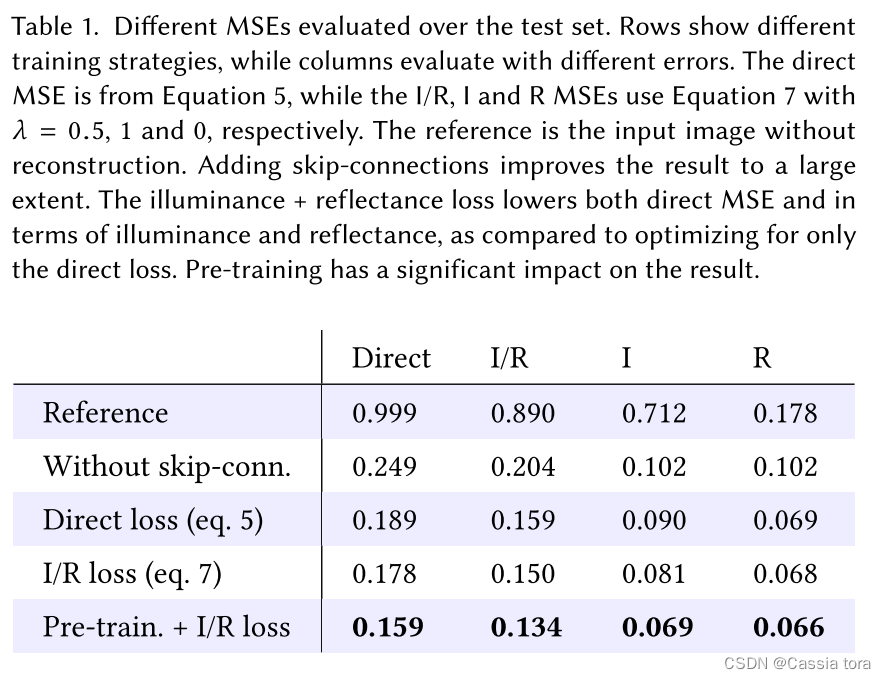
(1)无跳跃连接的CNN可以显著降低输入的MSE,但添加跳跃连接可将误差减少24%,并创建细节有显著改善的图像。
(2)比较Direct loss和I/R loss,I/R loss在I/R和Direct MSE方面显示出较低的误差,减少了5.8%。
(3)通过预训练和I/R loss,实现了最佳训练性能,与未进行预训练相比,误差降低了10.7%。
5.2 与groung truth比较(Comparisons to ground truth)
下图展示了本文方法重建图像与ground truth的比较,其中input是将HDR图像通过虚拟相机转换得到的LDR图像。
为了可视化CNN重建的信息,下图显示了图像的学习残差 r ^ = m a x ( 0 , H ^ − 1 ) \hat{r}=max(0,\hat{H}-1) r^=max(0,H^−1)(左上),以及ground truth残差 r = m a x ( 0 , H − 1 ) r=max(0,H-1) r=max(0,H−1)(右上)。复杂照明区域的预测令人信服(左下),但对于非常强烈的聚光灯,亮度被低估了(右下)。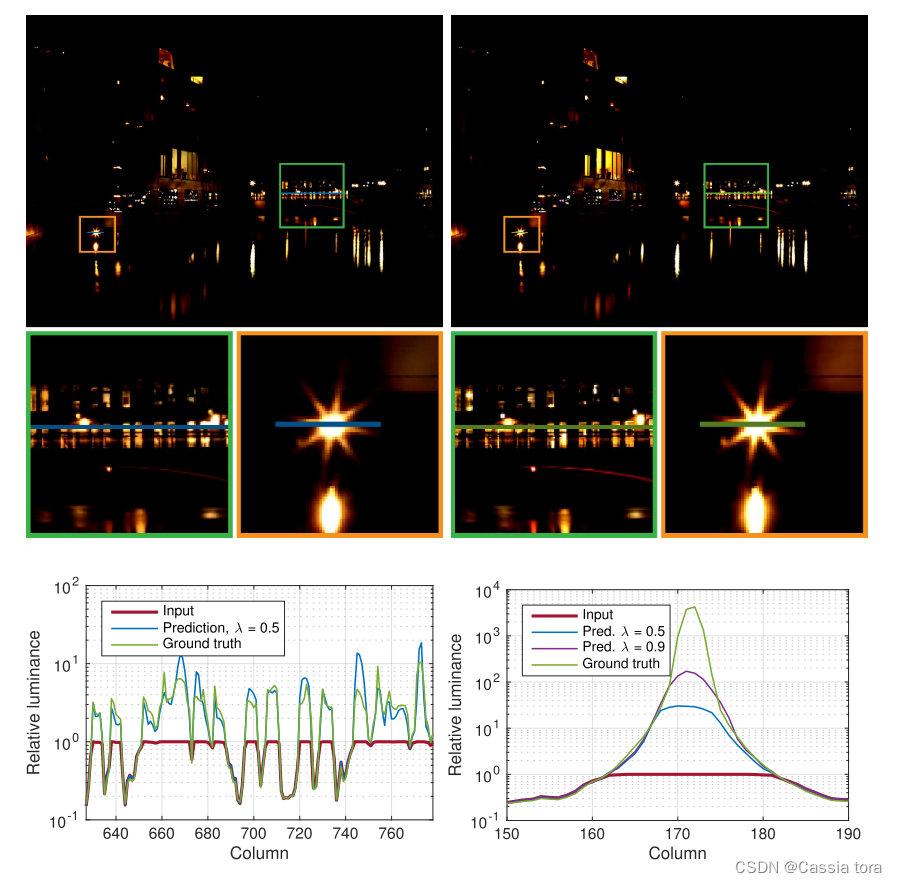
5.3 对真实相机图像重建(Reconstruction with real-world cameras)
用本文的HDR重建模型处理真实相机拍摄的LDR图像,结果如下图所示:
为了进一步探索重建日常图像的可能性,下图显示了一组在各种情况下拍摄的iPhone图像:
5.4 更改剪切点(Changing clipping point)
下图显示了对不同虚拟相机曝光时间的预测(图下的数字表示图像中的饱和区域像素的占比,对图像进行缩放,使图像在剪切之后具有相同的曝光),可以看出较短曝光图像的重建中可以获得更多细节。
5.5 与iTMOs比较(Comparison to iTMOs)
本文HDR重建与三种现有的逆色调映射方法的比较如下图所示:
6 讨论
6.1 限制
下图显示了本文方法难以重建的困难场景示例:
(1)第一行有一个在所有颜色通道中都具有饱和的大区域,因此无法推断结构和细节。
(2)第二行中显示当图像中一块区域具有极端强度时,本文方法会低估这个极端强度。
边栏推荐
- How does the uni admin basic framework close the creation of super administrator entries?
- Reptile practice (V): climbing watercress top250
- GPS from entry to abandonment (XIV), ionospheric delay
- [MySQL] online DDL details
- 2020 Bioinformatics | GraphDTA: predicting drug target binding affinity with graph neural networks
- [10:00 public class]: basis and practice of video quality evaluation
- GPS from getting started to giving up (XVIII), multipath effect
- Force buckle 575 Divide candy
- What a new company needs to practice and pay attention to
- C language: comprehensive application of if, def and ifndef
猜你喜欢

GPS from getting started to giving up (12), Doppler constant speed
GPS from getting started to giving up (XV), DCB differential code deviation

GPS from getting started to giving up (16), satellite clock error and satellite ephemeris error
Powerful domestic API management tool
MPLS experiment

The golden age of the U.S. technology industry has ended, and there have been constant lamentations about chip sales and 30000 layoffs
make menuconfig出现recipe for target ‘menuconfig‘ failed错误
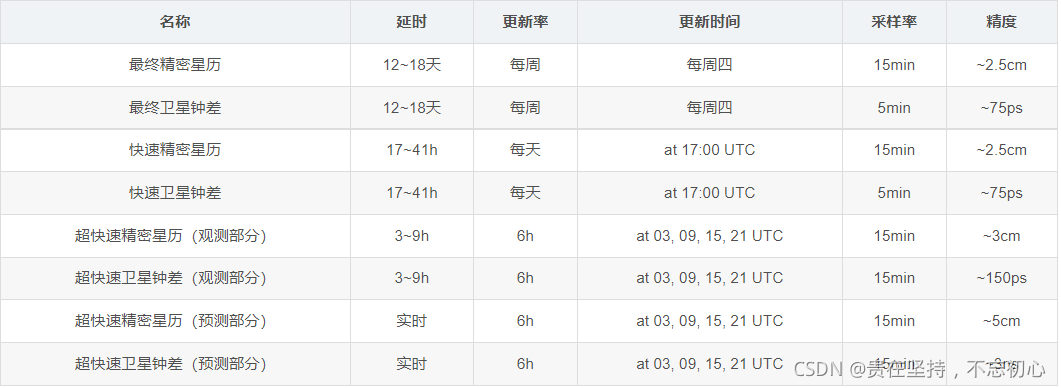
GPS from getting started to giving up (19), precise ephemeris (SP3 format)
墨西哥一架飞往美国的客机起飞后遭雷击 随后安全返航
![[Yu Yue education] higher mathematics of Nanchang University (2) reference materials](/img/ae/a76f360590061229076d00d749b35f.jpg)
[Yu Yue education] higher mathematics of Nanchang University (2) reference materials
随机推荐
GPS从入门到放弃(十一)、差分GPS
Leveldb source code analysis series - main process
Some problems about the use of char[] array assignment through scanf..
Maximum product of three numbers in question 628 of Li Kou
GPS from getting started to giving up (XX), antenna offset
VIP case introduction and in-depth analysis of brokerage XX system node exceptions
JS method to stop foreach
LeetCode学习记录(从新手村出发之杀不出新手村)----1
关于char[]数组通过scanf赋值使用上的一些问题。。
HDU 4912 paths on the tree (lca+)
Reset Mikrotik Routeros using netinstall
[asp.net core] set the format of Web API response data -- formatfilter feature
Sql: stored procedures and triggers - Notes
Method return value considerations
【sciter Bug篇】多行隐藏
Codeforces Round #274 (Div. 2) –A Expression
功能强大的国产Api管理工具
强化学习-学习笔记5 | AlphaGo
Qt | UDP广播通信、简单使用案例
小满网络模型&http1-http2 &浏览器缓存