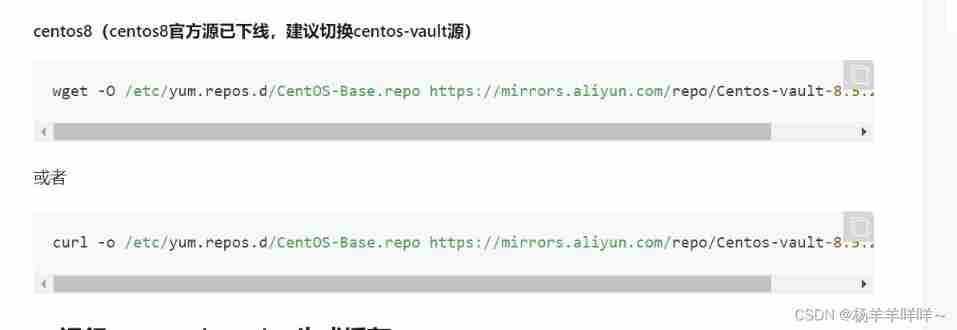
当前位置:网站首页>What is the RDD operator in spark
What is the RDD operator in spark
2022-07-06 21:43:00 【Big data Xiaochen】
RDD The operator of
1- What is an operator ? That's the function. 、 Method 、API、 Behavior
2- There are several kinds of operators ?-transformation and action
3-transformation Characteristics : Convert to new RDD, Delay loading
-transformation What operators are there ?- See the table for example map filter etc.
-transformation Continue to classify
eg:glom- Elements of each partition
1-RDD The element of is single value
map、groupBy、filter、flatMap、distinct
Beijing order case : Local +standalone colony
2- Double value type - The input parameter of the operator is also RDD
union、intersection
3-RDD The element is key_value
groupByKey、reduceByKey、sortByKey、
4-action Characteristics : Execute now , The output motion , It is the last link of the calculation chain .
-action What operators are there ?- See table
eg:collecet、 reduce、 first、take、
takeSample、takeOrdered、top、count
Different names of operators 【 function 】、【 Method 】、【API】
Transformation
Back to a new 【RDD】, be-all transformation function ( operator ) All are 【lazy Delay loading 】 Of , Not immediately , such as wordcount Medium 【flatMap】,【map】,【reduceByKey】
| transformation | meaning |
|---|---|
| map(func) | Back to a new RDD, The RDD Each input element passes through func After function conversion, it is composed of |
| filter(func) | Back to a new RDD, The RDD By the way func The return value of the function is true The input elements of |
| flatMap(func) | Be similar to map, But each input element can be mapped to 0 Or multiple output elements ( therefore func A sequence should be returned , Not a single element ) |
| mapPartitions(func) | Be similar to map, But independently in RDD Running on every segment of , So in type T Of RDD When running on ,func The function type of must be Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) | Be similar to mapPartitions, but func With an integer parameter to represent the index value of fragmentation , So in type T Of RDD When running on ,func The function type of must be (Int, Interator[T]) => Iterator[U] |
| sample(withReplacement, fraction, seed) | according to fraction Sampling data at a specified ratio , You can choose whether to replace it with a random number ,seed Used to specify random number generator seed |
| union(otherDataset) | To the source RDD And parameters RDD Returns a new... After union RDD |
| intersection(otherDataset) | To the source RDD And parameters RDD Returns a new RDD |
| distinct([numTasks])) | To the source RDD Go back to a new RDD |
| groupByKey([numTasks]) | In a (K,V) Of RDD On the call , Return to one (K, Iterator[V]) Of RDD |
| reduceByKey(func, [numTasks]) | In a (K,V) Of RDD On the call , Return to one (K,V) Of RDD, Use specified reduce function , Will be the same key The values of , And groupByKey similar ,reduce The number of tasks can be set through the second optional parameter |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | |
| sortByKey([ascending], [numTasks]) | In a (K,V) Of RDD On the call ,K Must be realized Ordered Interface , Return to a press key sorted (K,V) Of RDD |
| sortBy(func,[ascending], [numTasks]) | And sortByKey similar , But more flexible |
| join(otherDataset, [numTasks]) | In the type of (K,V) and (K,W) Of RDD On the call , Return to the same key All the corresponding elements are aligned together (K,(V,W)) Of RDD |
| cogroup(otherDataset, [numTasks]) | In the type of (K,V) and (K,W) Of RDD On the call , Return to one (K,(Iterable<V>,Iterable<W>)) Type of RDD |
| cartesian(otherDataset) | The cartesian product |
| pipe(command, [envVars]) | Yes rdd Perform piping operations |
| coalesce(numPartitions) | Reduce RDD To the specified number of partitions . After filtering a lot of data , You can do this |
| repartition(numPartitions) | Back to the RDD Partition |
Usage of common operators :
transformation operator
Value type valueType
map
groupBy
filter
flatMap
distinct
import os
from pyspark import SparkConf, SparkContext
os.environ['SPARK_HOME'] = '/export/server/spark'
PYSPARK_PYTHON = "/root/anaconda3/bin/python3.8"
# When multiple versions exist , Failure to specify is likely to result in an error
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
conf = SparkConf().setAppName("2_rdd_from_external").setMaster("local[*]")
sc = SparkContext(conf=conf)
# practice , Introduce glom function , You can get the specific elements of each partition
rdd1=sc.parallelize([5,6,4,7,3,8,2,9,1,10])
rdd2=rdd1.glom()
print(rdd2.collect())
>> result : [[5, 6], [4, 7], [3, 8], [2, 9, 1, 10]]
# The default parallelism is 4, because local[*] The machine has 4 individual core
rdd1.getNumPartitions()
>> result : 4
# You can specify the number of partitions 3
rdd1=sc.parallelize([1,2,3,4,5,6,7,8,9],3)
rdd1.getNumPartitions()
>> result : 3
#1、map operator , The way 1
rdd2=rdd1.map(lambda x:x+1)
print(rdd2.collect())
>> result :[2, 3, 4, 5, 6, 7, 8, 9, 10]
#1、map operator , The way 2
def add(x):
return x+1
rdd2=rdd1.map(add)
print(rdd2.collect())
>> result : [2, 3, 4, 5, 6, 7, 8, 9, 10]
#2、groupBy operator ,
rdd1=sc.parallelize([1,2,3,4])
rdd2=rdd1.groupBy(lambda x: 'even' if x%2==0 else 'odd')
print(rdd2.collect())
>> result : [('even', <pyspark.resultiterable.ResultIterable object at 0x7f9e1c0e33d0>), ('odd', <pyspark.resultiterable.ResultIterable object at 0x7f9e0e2ae0d0>)]
rdd3=rdd2.mapValues(lambda x:list(x))
print(rdd3.collect())
>> result : [('even', [2, 4]), ('odd', [1, 3])]
#3、filter operator
rdd1=sc.parallelize([1,2,3,4,5,6,7,8,9])
rdd2=rdd1.filter(lambda x:True if x>4 else False)
print(rdd2.collect())
>> result : [5, 6, 7, 8, 9]
#4、flatMap operator
rdd1=sc.parallelize(["a b c","d e f","h i j"])
rdd2=rdd1.flatMap(lambda line:line.split(" "))
print(rdd2.collect())
>> result : ['a', 'b', 'c', 'd', 'e', 'f', 'h', 'i', 'j']
#4、distinct operator
rdd1 = sc.parallelize([1,2,3,3,3,5,5,6])
rdd1.distinct().collect()
>> result : [1, 5, 2, 6, 3]
Double value type DoubleValueType
union
intersection
#union operator
rdd1 = sc.parallelize([("a", 1), ("b", 2)])
print(rdd1.collect())
>> result :[('a', 1), ('b', 2)]
rdd2 = sc.parallelize([("c",1),("b",3)])
print(rdd2.collect())
>> result :[('c', 1), ('b', 3)]
rdd3=rdd1.union(rdd2)
print(rdd3.collect())
>> result :[('a', 1), ('b', 2), ('c', 1), ('b', 3)]
#intersection operator
rdd2 = sc.parallelize([("a",1),("b",3)])
rdd3=rdd1.intersection(rdd2)
rdd3.collect()
>> result : [('a', 1)]
Key-Value Value type
groupByKey
reduceByKey
sortByKey
#groupByKey operator 1
rdd = sc.parallelize([("a",1),("b",2),("c",3),("d",4)])
rdd.groupByKey().collect()
>> result :
[('b', <pyspark.resultiterable.ResultIterable at 0x7f9e1c0e33a0>),
('c', <pyspark.resultiterable.ResultIterable at 0x7f9e0e27d430>),
('a', <pyspark.resultiterable.ResultIterable at 0x7f9e0e27df10>),
('d', <pyspark.resultiterable.ResultIterable at 0x7f9e0e27d340>)]
result=rdd.groupByKey().collect()
result[1]
>> result : ('c', <pyspark.resultiterable.ResultIterable at 0x7f9e0e2ae3d0>)
result[1][1]
>> result : <pyspark.resultiterable.ResultIterable at 0x7f9e0e2ae3d0>
list(result[1][1])
>> result : [3]
#groupByKey operator 2, Additional supplementary cases
rdd = sc.parallelize([("M",'zs'),("F",'ls'),("M",'ww'),("F",'zl')])
rdd2=rdd.groupByKey()
rdd2.collect()
>> result :
[('M', <pyspark.resultiterable.ResultIterable at 0x7f9e0e2bc550>),
('F', <pyspark.resultiterable.ResultIterable at 0x7f9e0e2bcfa0>)]
ite=rdd2.collect()
for x in ite : print(' Gender is ',x[0],' People are :',list(x[1]))
>> result : Gender is M People are : ['zs', 'ww']
Gender is F People are : ['ls', 'zl']
#groupByKey operator 3
sc.parallelize([('hadoop', 1), ('hadoop', 5), ('spark', 3), ('spark', 6)])
>> result : ParallelCollectionRDD[60] at readRDDFromFile at PythonRDD.scala:274
rdd1=sc.parallelize([('hadoop', 1), ('hadoop', 5), ('spark', 3), ('spark', 6)])
rdd2=rdd1.groupByKey()
rdd2.collect()
>> result :
[('hadoop', <pyspark.resultiterable.ResultIterable at 0x7f9e0e2bc490>),
('spark', <pyspark.resultiterable.ResultIterable at 0x7f9e0e2bc670>)]
rdd2.mapValues(lambda value:sum(list(value)))
>> result : PythonRDD[67] at RDD at PythonRDD.scala:53
rdd3=rdd2.mapValues(lambda value:sum(list(value)))
rdd3.collect()
>> result : [('hadoop', 6), ('spark', 9)]
#reduceByKey operator
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
rdd.reduceByKey(lambda x,y:x+y).collect()
>> result : [('b', 1), ('a', 2)]
#sortByKey operator
sc.parallelize([('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)])
>> result : ParallelCollectionRDD[75] at readRDDFromFile at PythonRDD.scala:274
rdd1=sc.parallelize([('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)])
rdd2=rdd1.sortByKey()
rdd2.collect()
>> result : [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]
print(rdd1.sortByKey(False))
PythonRDD[90] at RDD at PythonRDD.scala:53
print(rdd1.sortByKey(False).collect())
[('d', 4), ('b', 2), ('a', 1), ('2', 5), ('1', 3)]
print(rdd1.sortByKey(True,2).glom().collect())
[[('1', 3), ('2', 5), ('a', 1)], [('b', 2), ('d', 4)]]
tmp2 = [('Mary', 1), ('had', 2), ('a', 3), ('little', 4), ('lamb', 5), ('whose', 6), ('fleece', 7), ('was', 8), ('white', 9)]
rdd1=sc.parallelize(tmp2)
rdd2=rdd1.sortByKey(True,1,keyfunc=lambda k:k.upper())
rdd2.collect()
>> result :
[('a', 3),
('fleece', 7),
('had', 2),
('lamb', 5),
('little', 4),
('Mary', 1),
('was', 8),
('white', 9),
('whose', 6)]Action
Back to 【 No 】RDD, You can save the results for output , be-all Action operator 【 immediately 】 perform , such as wordcount Medium 【saveAsTextFile】.
| action | meaning |
|---|---|
| reduce(func) | adopt func Function aggregation RDD All elements in , This function must be interchangeable and parallelable |
| collect() | In the driver , Returns all elements of the dataset as an array |
| count() | return RDD Number of elements of |
| first() | return RDD The first element of ( Be similar to take(1)) |
| take(n) | Returns a data set from the front of n An array of elements |
| takeSample(withReplacement,num, [seed]) | Returns an array , The array consists of... Randomly sampled from the dataset num Elements make up , You can choose whether to replace the insufficient part with a random number ,seed Used to specify random number generator seed |
| takeOrdered(n, [ordering]) | Return to the front of natural order or custom order n Elements |
| saveAsTextFile(path) | Set the elements of the dataset as textfile In the form of HDFS File systems or other supported file systems , For each element ,Spark Will call toString Method , Replace it with the text in the file |
| saveAsSequenceFile(path) | Set the elements in the dataset as Hadoop sequencefile Save the format to the specified directory , You can make HDFS Or other Hadoop Supported file systems . |
| saveAsObjectFile(path) | The elements of the dataset , With Java Save it to the specified directory by serialization |
| countByKey() | in the light of (K,V) Type of RDD, Return to one (K,Int) Of map, For each one key The corresponding number of elements . |
| foreach(func) | On every element of the dataset , Operation function func updated . |
| foreachPartition(func) | On every partition of the dataset , Operation function func |
#countByValue operator
x = sc.parallelize([1, 3, 1, 2, 3])
y = x.countByValue()
print(type(y))
<class 'collections.defaultdict'>
print(y)
>> result : defaultdict(<class 'int'>, {1: 2, 3: 2, 2: 1})
#collect operator
rdd = sc.parallelize([1,3,5,2,6,7,11,9,10],3)
rdd.map(lambda x: x + 1).collect()
>> result : [2, 4, 6, 3, 7, 8, 12, 10, 11]
x=rdd.map(lambda x: x + 1).collect()
print(type(x))
>> result : <class 'list'>
#reduce operator
rdd1 = sc.parallelize([1,2,3,4,5])
rdd1.collect()
>> result : [1, 2, 3, 4, 5]
x=rdd1.reduce(lambda x,y:x+y)
print(x)
15
#fold operator
rdd1 = sc.parallelize([1,2,3,4,5], 3)
rdd.glom().collect()
>> result : [[1, 3, 5], [2, 6, 7], [11, 9, 10]]
rdd1 = sc.parallelize([1,2,3,4,5], 3)
rdd1.glom().collect()
>> result : [[1], [2, 3], [4, 5]]
rdd1.fold(10,lambda x,y:x+y)
>> result : 55
#first operator
sc.parallelize([2, 3, 4]).first()
>> result : 2
#take operator
sc.parallelize([2, 3, 4, 5, 6]).take(2)
>> result : [2, 3]
sc.parallelize([2, 3, 4, 5, 6]).take(10)
>> result : [2, 3, 4, 5, 6]
sc.parallelize([5,3,1,1,6]).take(2)
>> result : [5, 3]
sc.parallelize(range(100), 100).filter(lambda x: x > 90).take(3)
>> result : [91, 92, 93]
#top operator
x = sc.parallelize([1, 3, 1, 2, 3])
x.top(3)
>> result : [3, 3, 2]
#count operator
sc.parallelize([2, 3, 4]).count()
>> result : 3
#foreach operator
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark and python"] )
words.foreach(lambda x:print(x))
>> result :
pyspark
pyspark and spark and python
akka
spark vs hadoop
hadoop
spark
scala
java
#saveAsTextFile operator
data = sc.parallelize([1,2,3], 2)
data.glom().collect()
>> result : [[1], [2, 3]]
data.saveAsTextFile("hdfs://node1:8020/output/file1")collecet
reduce
first
take
takeSample
takeOrdered
top
count above Executor Will send the execution results back to Driver
only foreach and saveAsTextFile It will not be sent back uniformly Driver Of .
边栏推荐
- JS get array subscript through array content
- 抖音将推独立种草App“可颂”,字节忘不掉小红书?
- 039. (2.8) thoughts in the ward
- Guava: use of multiset
- 技术分享 | 抓包分析 TCP 协议
- Set up a time server
- 嵌入式开发的7大原罪
- First batch selected! Tencent security tianyufeng control has obtained the business security capability certification of the ICT Institute
- Tiktok will push the independent grass planting app "praiseworthy". Can't bytes forget the little red book?
- 快讯:飞书玩家大会线上举行;微信支付推出“教培服务工具箱”
猜你喜欢
Set up a time server
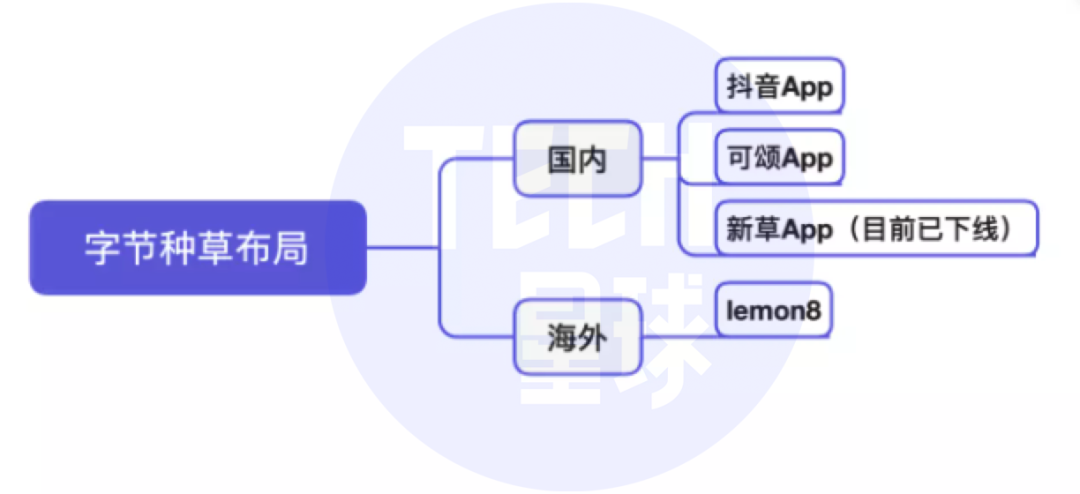
Tiktok will push the independent grass planting app "praiseworthy". Can't bytes forget the little red book?
![[redis design and implementation] part I: summary of redis data structure and objects](/img/2e/b147aa1e23757519a5d049c88113fe.png)
[redis design and implementation] part I: summary of redis data structure and objects
Why does MySQL index fail? When do I use indexes?

Five wars of Chinese Baijiu

对话阿里巴巴副总裁贾扬清:追求大模型,并不是一件坏事
Shake Sound poussera l'application indépendante de plantation d'herbe "louable", les octets ne peuvent pas oublier le petit livre rouge?

Why do job hopping take more than promotion?
PostgreSQL modifies the password of the database user
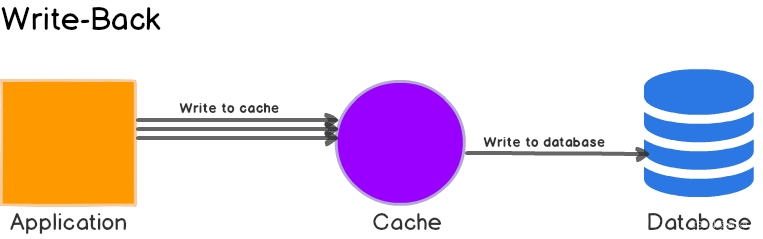
缓存更新策略概览(Caching Strategies Overview)

随机推荐
JPEG2000-Matlab源码实现
Michael smashed the minority milk sign
【滑动窗口】第九届蓝桥杯省赛B组:日志统计
C language: comprehensive application of if, def and ifndef
1292_FreeROS中vTaskResume()以及xTaskResumeFromISR()的实现分析
High precision face recognition based on insightface, which can directly benchmark hongruan
WEB功能测试说明
快讯:飞书玩家大会线上举行;微信支付推出“教培服务工具箱”
Efficiency tool +wps check box shows the solution to the sun problem
Microsoft technology empowerment position - February course Preview
Acdreamoj1110 (multiple backpacks)
Redistemplate common collection instructions opsforset (V)
ACdreamoj1110(多重背包)
The use method of string is startwith () - start with XX, endswith () - end with XX, trim () - delete spaces at both ends
在Pi和Jetson nano上运行深度网络,程序被Killed
How do I remove duplicates from the list- How to remove duplicates from a list?
Replace Internet TV set-top box application through digital TV and broadband network
MySQL - 事务(Transaction)详解
代理和反向代理
爬虫实战(五):爬豆瓣top250