原文链接: https://blog.csdn.net/Ax0592/article/details/122623533
https://blog.csdn.net/jj89929665/article/details/124178040
delete from tbl where id not in
(
select a.id from
(
select id from table group by column1, column2 having
count(column1) > 1 and count(column2) >1
) a
)
1.(错误操作)查所有的重复数据
很明显下列代码运行速度很慢
select * from 表 t where (select count(*) from 表 where 字段1=t.字段1 AND 字段2=t.字段2)>1
1
所以我们使用下面的分组
1.(速度优化) 查所有的重复数据
SELECT *
FROM 表
WHERE (字段1, 字段2, 字段3) IN (SELECT 字段1, 字段2, 字段3 FROM 表
GROUP BY 字段1, 字段2, 字段3 HAVING COUNT(*) > 1)
ORDER BY 排序字段
1
2
3
4
5
2.查找出重复的数据
SELECT id, 字段1, 字段2, 字段3
FROM 表
WHERE id
IN (SELECT MIN(id) FROM 表 GROUP BY 字段1, 字段2, 字段3 HAVING COUNT(*) > 1)
1
2
3
4
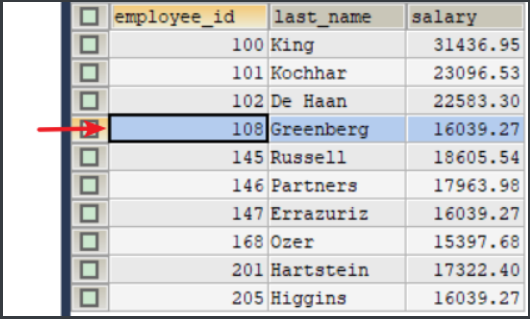
3.过滤(字段1, 字段2, 字段3)全部重复相同的数据,只显示一条(id最小或最大等)数据,包含原本不重复的数据(建议使用)
SELECT *
FROM 表
WHERE id
IN (SELECT MIN(id) FROM 表 GROUP BY 字段1, 字段2, 字段3)
1
2
3
4
4.获取到2的结果后就可以通过单条或者多条一起进行删除




![[sliding window] group B of the 9th Landbridge cup provincial tournament: log statistics](/img/2d/9a7e88fb774984d061538e3ad4a96b.png)