当前位置:网站首页>None of the strongest kings in the monitoring industry!
None of the strongest kings in the monitoring industry!
2022-07-06 20:52:00 【Java technology stack】
source :javadoop.com/post/apm
Preface
This article talks about what is APM System , That is what we usually call monitoring system , And how to achieve a APM System . For some special reason , I will use Dog As the name of our system .
We are Dog The goal of the plan is to access most of the company's Applications , Estimated processing per second 500MB-1000MB The data of , Single machine per second 100MB about , Use multiple ordinary AWS EC2.
Because many of the readers of this article work for companies that don't necessarily have comprehensive APM System , So I try to take care of the feelings of more readers , I'll talk a little bit about some things , I hope you can understand . I'll talk about it in the article prometheus、grafana、cat、pinpoint、skywalking、zipkin Wait for a series of tools , It doesn't matter if you haven't used it , I will take this into full consideration .
This article presupposes some background :Java Language 、web service 、 Each application has multiple instances 、 Deploy as a microservice . in addition , Considering from the readability of the article , I assume that different instances of each application are distributed in different IP On , Maybe your application scenario doesn't have to be like this .
APM brief introduction
APM It's usually thought to be Application Performance Management Abbreviation , It mainly includes three aspects , Namely Logs( journal ) 、Traces( Link tracking ) and Metrics( Report statistics ) . In the future, we will contact any one APM System time , We can analyze what kind of system it is from these three aspects .
In some scenes ,APM Of the three above Metrics, We are not going to discuss this concept here
In this section, let's start with 3 Introduce every aspect , At the same time, let's talk about 3 Some commonly used tools in this field .
1、 First Logs It's better to understand , It's printing in various applications log Collect and provide query capabilities .
Logs The importance of the system is self-evident , Usually when we're looking for specific requests , Is very context dependent logging .
We used to go through terminal Log in to the machine and check log( I've been here like this for years ), But because of clustering and micro service , Continue to use this way, the work efficiency will be lower , Because you may need to log on several machines to search the log to find the information you need , So there needs to be a place to centrally store logs , And provide log query .
Logs A typical implementation of is ELK (ElasticSearch、Logstash、Kibana), All three projects are made up of Elastic Open source , The core of it is ES The performance of storage and query is recognized by everyone , It has been tested by many companies .
Logstash Responsible for collecting logs , Then parse and store it in ES. There are usually two main ways to collect logs , One is through a client program FileBeat, Collect logs that each application prints to the local disk , Send to Logstash; The other is that each application does not need to store the log to disk , It's sent directly to Kafka In the cluster , from Logstash To consume .
Kibana It's a very useful tool , Used to deal with ES Data visualization , Simply speaking , It is ES The client of .
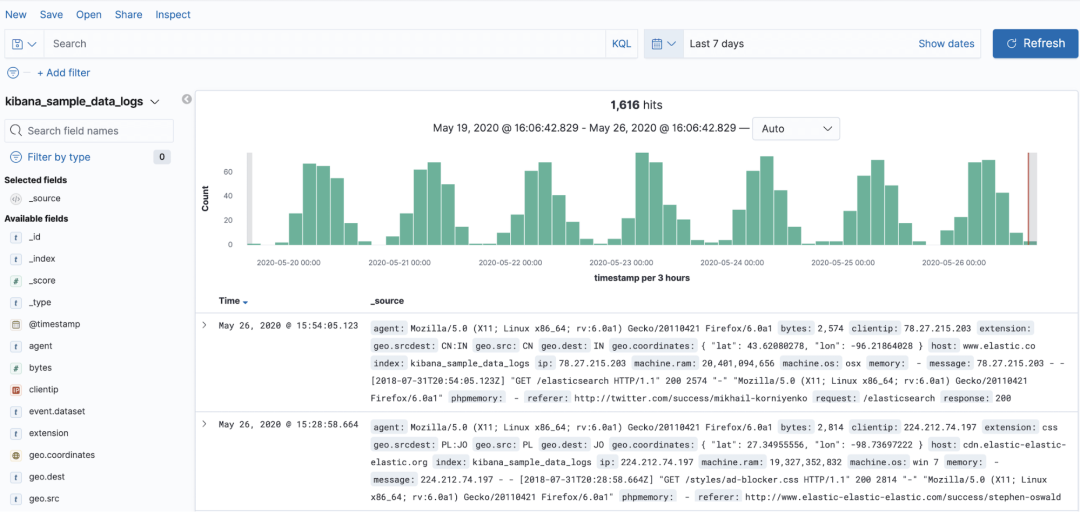
Let's go back and analyze Logs System ,Logs The data of the system comes from the log printed in the application , It is characterized by a large amount of data , It depends on how the application developer logs ,Logs The system needs to store the full amount of data , Usually support at least 1 Weekly storage .
Each log contains ip、thread、class、timestamp、traceId、message Etc , The technical points involved are very easy to understand , Is the log storage and query .
It's very easy to use , When troubleshooting , Usually, a log is searched by keywords first , And then through its traceId To search the log of the whole link .
Digression ,Elastic Except Logs outside , Also provided Metrics and Traces Solutions for , But at present domestic users mainly use it Logs function .
2、 Let's see Traces System , It is used to record the entire call link .
Previously introduced Logs The system uses the log printed by the developer , So it's closest to the business . and Traces The system is further away from the business , It's about a request coming in , After what application 、 What methods , How much time is spent on each node , Where to throw the exception, etc , To quickly locate problems .
After years of development ,Traces Although the design of the system on the server side is various , But the design of the client is gradually becoming unified , So there is OpenTracing project , We can simply understand it as a norm , It defines a set of API, Solidify the client model . Current relatively mainstream Traces In the system ,Jaeger、SkyWalking It's using this specification , and Zipkin、Pinpoint The specification is not used . Limited to space , This article is wrong OpenTracing An introduction .
Here's a sequence diagram of a request I drew :
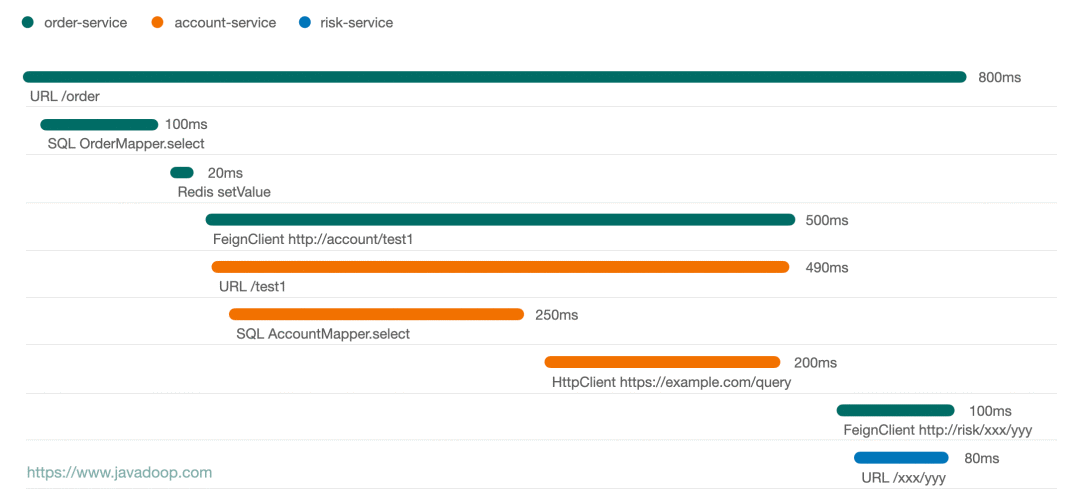
From the picture above , It's very convenient to see that , This request went through 3 Applications , Through the length of the line, it is very easy to see the time-consuming situation of each node . Usually click on a node , We can have more information to show , For example, click on HttpClient We may have request and response The data of .
Here is the graph Skywalking Graph , its UI It's also very good :

SkyWalking It should be used by more companies in China , It is an excellent open source project initiated by Chinese people , Entered Apache The foundation .
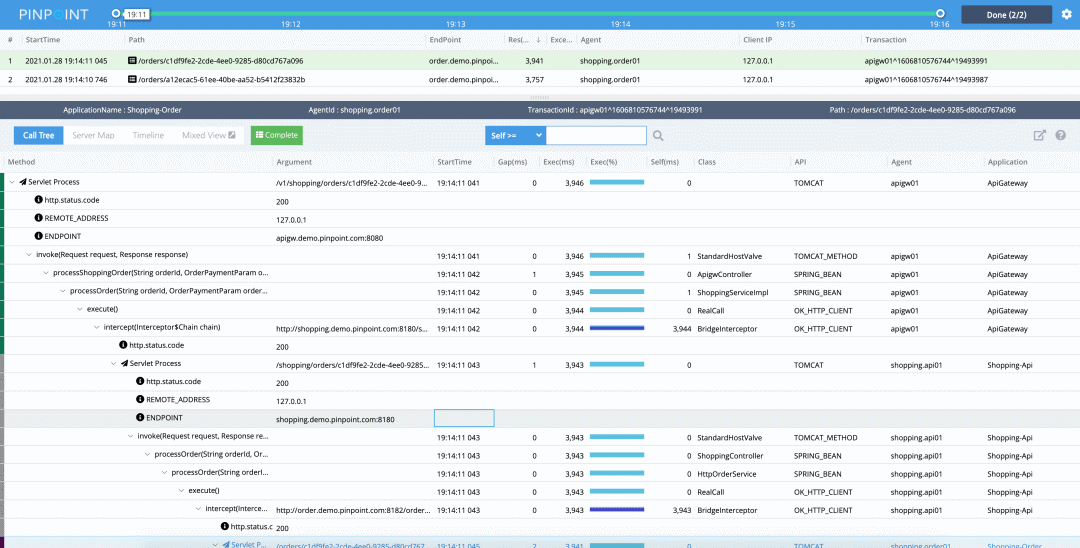
Another good open source Traces The system is open source by Korean people Pinpoint, Its management data is very rich , Here's the official Live Demo, You can go and play .
What's hot recently is that CNCF(Cloud Native Computing Foundation) Managed by the foundation Jeager:
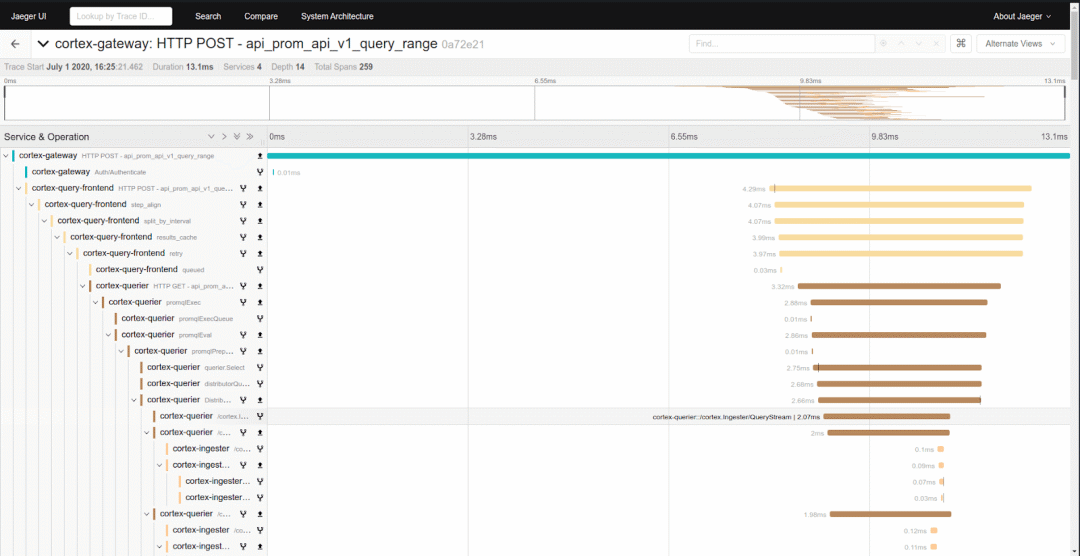
Of course, a lot of people use Zipkin, Count as Traces I'm a veteran of open source projects in the system :
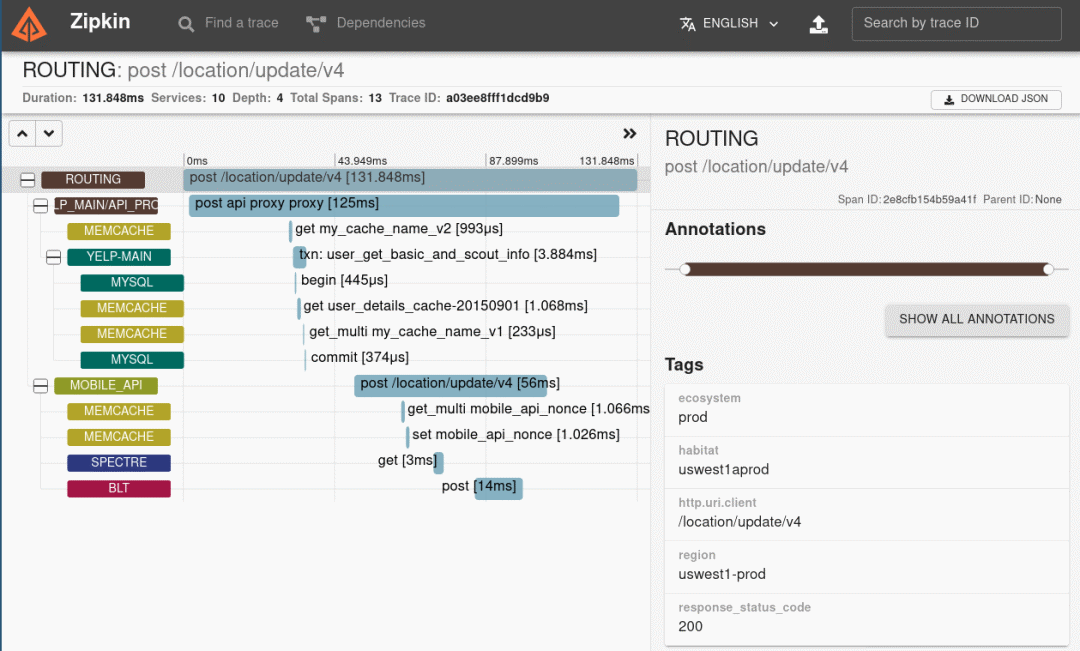
The above is the current mainstream Traces System , They're very useful when looking at specific problems , Through link analysis , It's easy to see which nodes the request went through 、 Time spent on each node 、 Whether to execute exception in a node, etc .
Although a few of the Traces Systematic UI Dissimilarity , You may have a preference , But to be specific , It's all about one thing , That's a call tree , So we're going to talk about every project except UI It's different from other places .
First of all, it must be the richness of the data , You pull up and look Pinpoint The tree of , You'll find that it's very rich in burial points , It's clear at a glance how to implement a request .
But is this really a good thing ? It's worth thinking about . Two aspects , One is the performance impact on the client , The other is the pressure on the server .
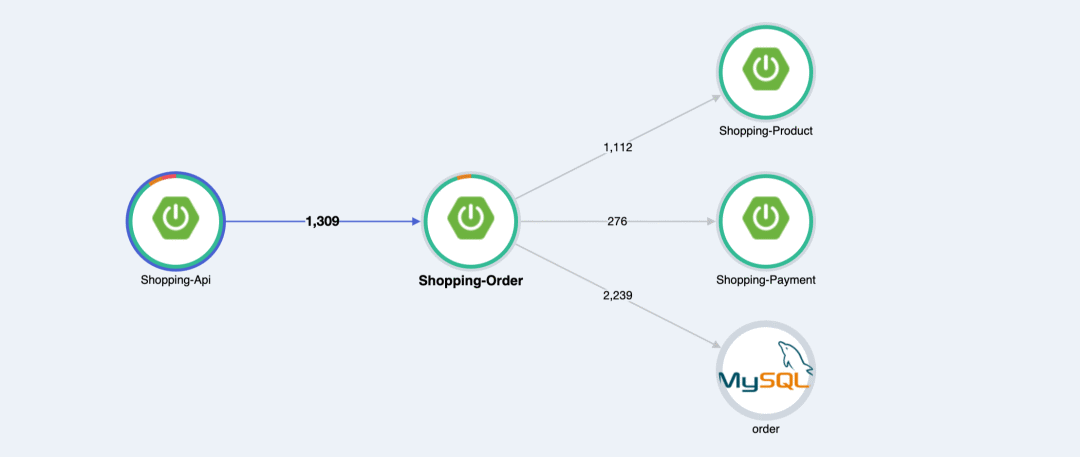
secondly ,Traces Because the system has data called between systems , So a lot of Traces The system will use this data to do call statistics between systems , For example, the following figure is actually quite useful :
in addition , What I mentioned above is the complete link analysis of a request , So that leads to another question , How do we get this “ A request ”, This is every one of them Traces The difference in the system .
For example, above , It is Pinpoint Graph , We see that the circles of the first two nodes are not perfect , Click on the circle in front , You can see why :

The two red circles on the right in the picture are added by me . We can see in the Shopping-api call Shopping-order In the request of , Yes 1 A failed request , We use the mouse to frame the red dot in the scatter diagram , You can enter trace View , Look at the specific call link . Limited to space , I'm not going to demonstrate anything else here Traces The entrance to the system .
Or look at the picture above , Let's look at the two graphs in the lower right corner , We can see that recently 5 Within minutes Shopping-api call Shopping-order Time spent on all requests for , And time distribution . When something unusual happens , For example, traffic burst , The function of these graphs comes out .
about Traces system , These are the most useful things , Of course, in the process of using , Maybe we also found Traces The system has many statistical functions or machine health monitoring , These are each Traces The differentiation function of the system , We don't want to make a specific analysis .
3、 Last , Let's talk about it again Metrics, It focuses on the collection and display of various report data .
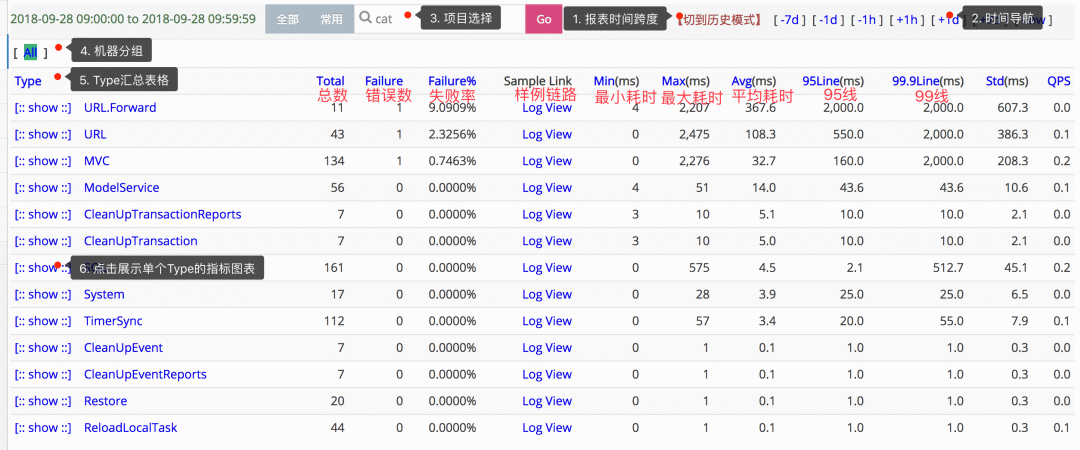
stay Metrics Open source systems that do a good job in this area , It's open source for public comments Cat, The picture below is Cat Medium transaction View , It shows a lot of statistics that we often need to care about :
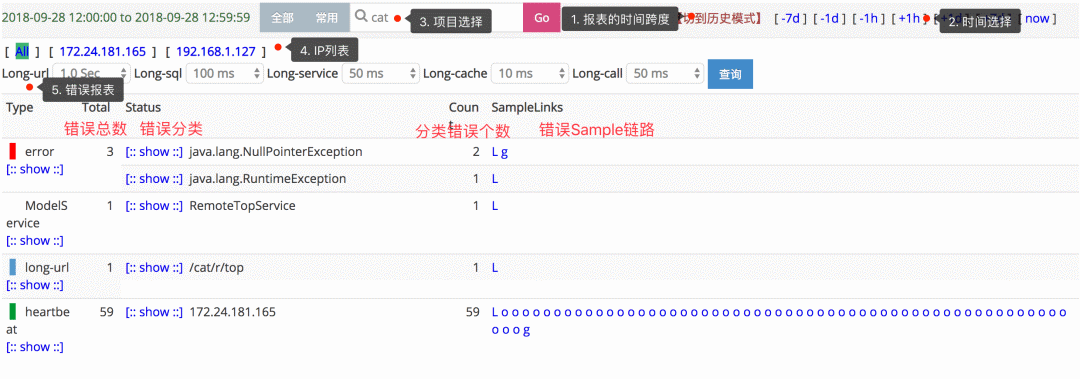
The picture below is Cat Of problem View , It's very useful for us developers , The goal of application developers is to make the less data in this view, the better .
The content after this article is mainly around Metrics In the , So there's no more going on here .
in addition , Speaking of APM Or system monitoring , I have to say Prometheus+Grafana This pair , They are very important to the health of the machine 、URL Interview Statistics 、QPS、P90、P99 And so on, these needs , Very good support , They are very suitable for monitoring large screens , But it doesn't usually help us sort things out , What it sees is that the system pressure is high 、 The system doesn't work , But we can't see why it's so high all at once 、 Why not .
The popular science :Prometheus It's a service that uses memory for storage and computing , Every machine / Application passed Prometheus Report data through the interface of , The characteristic of it is fast , But machine down or restart will lose all data .
Grafana It's a funny thing , It uses various plug-ins to visualize various system data , Such as query Prometheus、ElasticSearch、ClickHouse、MySQL wait , It's cool , It's better to use it as a monitor screen .
Metrics and Traces
Because what we will introduce later in this article is Dog The system is classified , Focus on Metrics, At the same time, we also provide tracing function , So here's a separate section , Look at the Metrics and Traces The connections and differences between systems .
The difference in use is easy to understand ,Metrics It's statistics , For example, a certain URL or DB How many times have access been requested ,P90 How many milliseconds , What is the number of errors . and Traces It's used to analyze a request , What links does it go through , Such as into the A After the application , What methods are called , And then maybe I asked B application , stay B Which methods are called in the application , Or where the whole link goes wrong .
But in front of me Traces When , We also found that this kind of system will do a lot of statistical work , It also covers a lot of Metrics The content of .
So we need to have a concept first ,Metrics and Traces The connection between them is very close , Their data structure is a call tree , The difference is whether the tree has many branches and leaves . stay Traces In the system , The link data that a request passes through is very complete , It's very useful for troubleshooting , But if you want to be right Traces Do report statistics on the data of all nodes in , It's going to be very resource intensive , Low cost performance . and Metrics The system is born for data statistics , So we do statistics for every node in the tree , So this tree can't be too “ Exuberant ”.
What we care about is , Which data are worth counting ? The first is the entrance , Secondly, it takes a lot of time , such as db visit 、http request 、redis request 、 Cross service calls, etc . When we have the statistics of these key nodes , It's very easy to monitor the health of the system .
I'm not going to tell you the difference here , After reading this article Metrics After the implementation of the system , It would be better to come back and think about it .
Dog In design , It's mainly about making a Metrics System , Count the data of key nodes , It also provides trace The ability of , But because our trees are not very ” Exuberant “, So the link may be intermittent , There will be a lot of missing areas in the middle , Of course, the application developers can also join in .
Dog Because it's the internal monitoring system of the company , So the middleware we will use inside the company is relatively certain , It doesn't need to be like open source APM We need to play a lot of points , We mainly implement the following node's automatic management :
- http entrance : By implementing a Filter To intercept all requests
- MySQL: adopt Mybatis Interceptor The way
- Redis: adopt javassist enhance RedisTemplate The way
- Cross application calls : Through agency feign client The way ,dubbo、grpc And so on may need to pass the interceptor
- http call : adopt javassist by HttpClient and OkHttp increase interceptor The way
- Log Dot : adopt plugin The way , take log Printed in error Report it
The technical details of Management , Not here , It mainly uses some interfaces provided by various frameworks , In addition, it uses javassist Do bytecode enhancement .
These statistics are what we need to do , Of course, because the management is limited , our tracing Function is relative to professional Traces The system is much thinner .
Dog brief introduction
Here is DOG The architecture of the figure , The client delivers the message to Kafka, from dog-server To consume news , Storage uses Cassandra and ClickHouse, What data will be stored in the future .
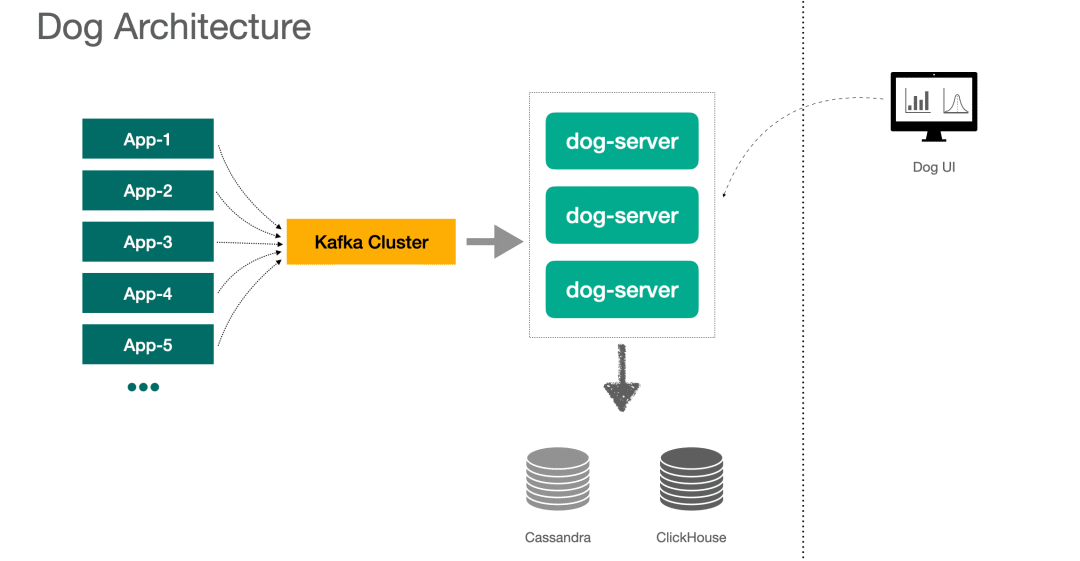
1、 Also have APM The system does not use message middleware , such as Cat Is the client through Netty Connect to the server to send messages .
2、Server End use Lambda Architecture mode ,Dog UI Data queried on , By every Dog-server And the data stored downstream are aggregated .
below , Let's briefly introduce Dog UI Some of the more important functions on the Internet , We will analyze how to realize the corresponding function later .
Be careful : The pictures below are all drawn by myself , It's not a real screenshot , The numbers may not be very accurate
The following example transaction report form :
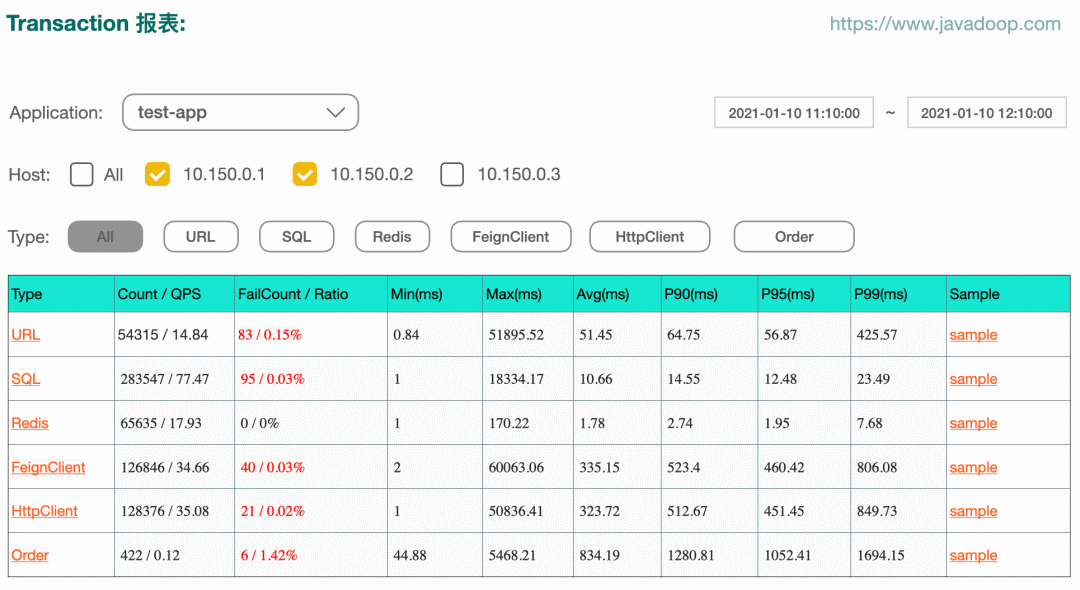
Click in the figure above type One of the items , We have this type Each of the following name The report of . For example, click on URL, We can get statistics for each interface :
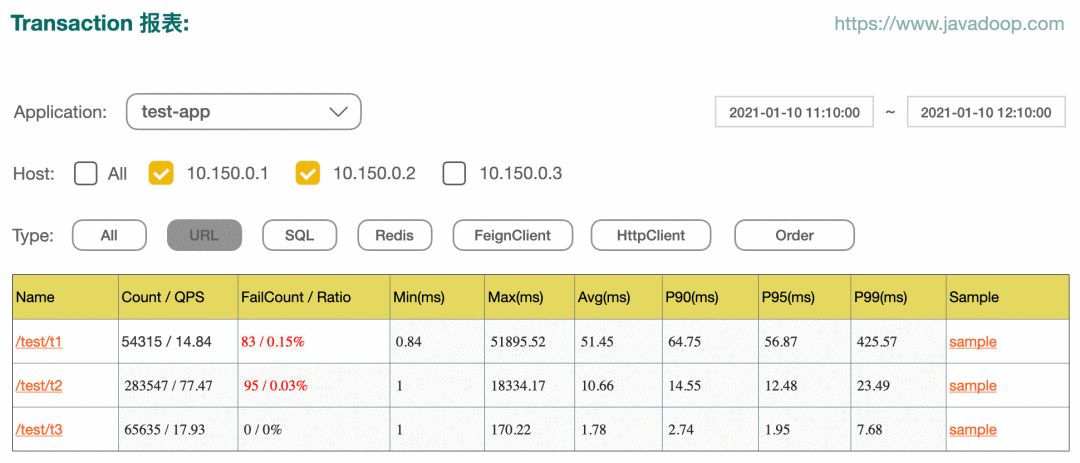
Of course , In the picture above, click specific name, There's the next level status Statistical data , No more mapping here .Dog A total of type、name、status Three attributes . The last column in the two figures above is sample, It can lead to sample View :

Sample It means sampling , When we see an interface with a high failure rate , perhaps P90 When it's high , You know something's wrong , But because it only has statistics , So you don't know what's wrong , This is the time , We need some sample data . We do it every minute type、name、status Different combinations of are saved up to 5 A success 、5 A failure 、5 A slow sample data .
Click on the top sample One of the tables T、F、L In fact, it will enter our trace View , Show the entire link to the request :
Through the above trace View , You can quickly know which link is wrong . Of course , We've said that before , our trace Depending on the richness of our burial sites , however Dog It's a Metrics The main system , So it's Traces Ability is not enough , But most of the time , It should be enough for troubleshooting .
For application developers , The following Problem Views should be very useful :
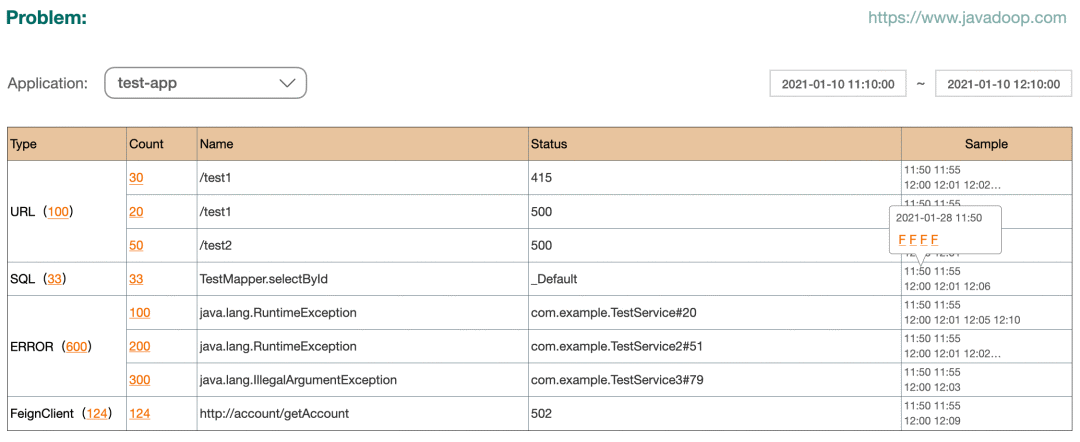
It shows all kinds of wrong statistics , And it provides sample Let developers check the problem .
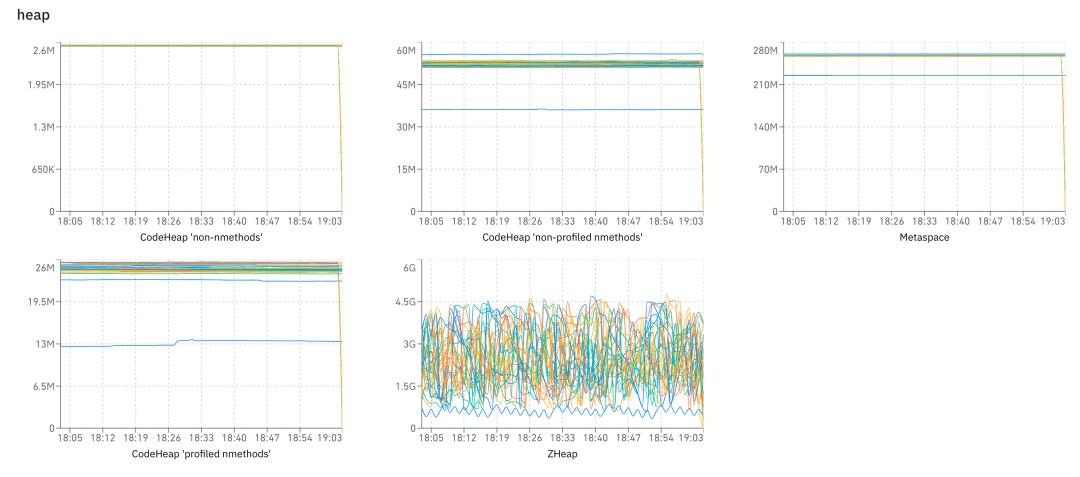
Last , Let's briefly introduce Heartbeat View , It has nothing to do with the previous functions , It's a lot of pictures , We have gc、heap、os、thread And so on , So we can observe the health of the system .
This section mainly introduces a APM What functions does the system usually contain , It's very simple, isn't it , Next, from the perspective of developers , Let's talk about the implementation details .
Client data model
We are all developers , I'll be more direct , The following figure describes the data model of the client :
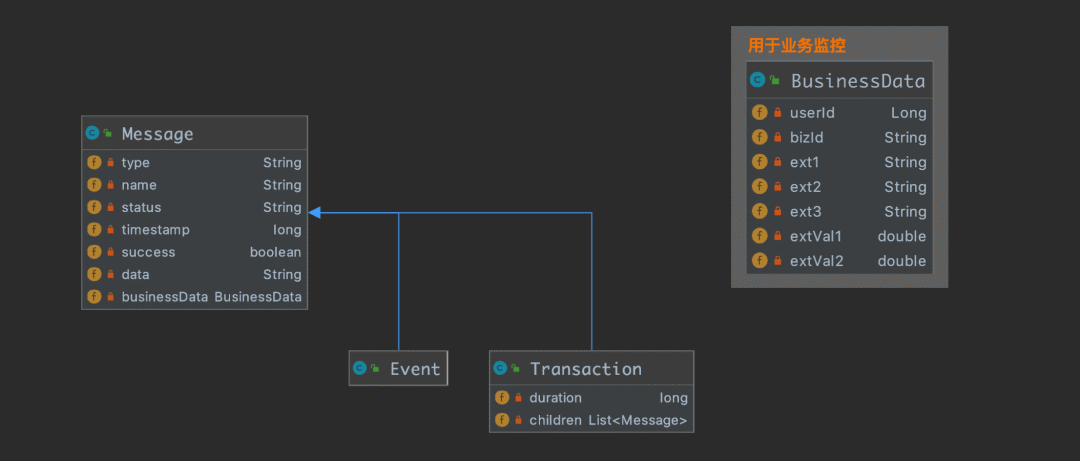
For one Message Come on , The fields used for statistics are type, name, status , So we can base on type、type+name、type+name+status Three dimensions of data statistics .
Message Other fields in :timestamp Indicates when the event occurred ;success If it is false, Then the event will be problem Statistics in the report ;data Not statistically significant , It's only useful for link tracking problems ;businessData Used to report to the business system Business data , It needs to be done manually , Then it is used for business data analysis .
Message There are two subclasses Event and Transaction , The difference lies in Transaction with duration attribute , Used to identify the transaction How long does it take , Can be used to do max time, min time, avg time, p90, p95 etc. , and event It means something happened , It can only be used to count how many times it happened , There's no concept of length of time .
Transaction There's a property children, Can be nested Transaction perhaps Event, Finally, a tree structure is formed , Used to do trace, We'll talk about it later .
The following table is an example of data management , This is more intuitive :
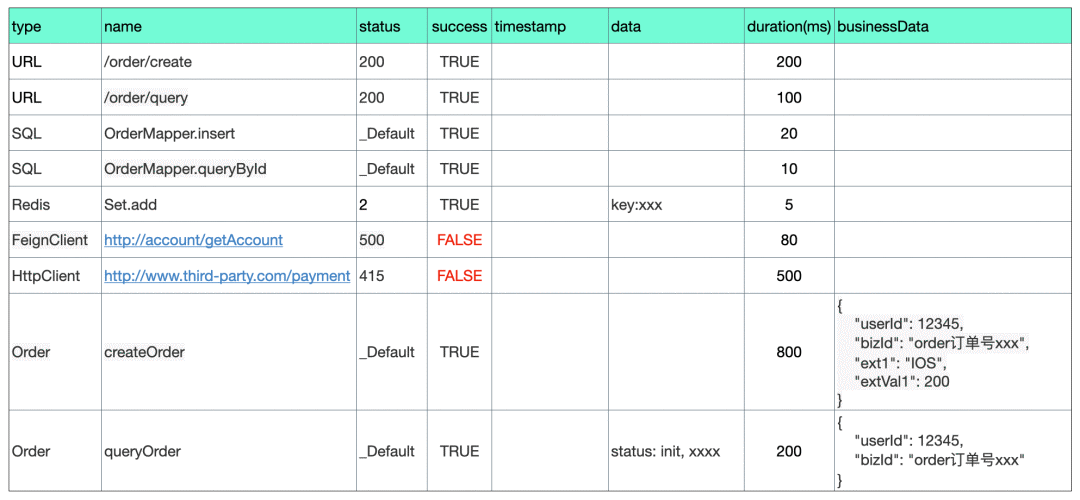
Let's give you a brief introduction :
- type by URL、SQL、Redis、FeignClient、HttpClient Wait for the data , It belongs to the category of automatic point embedding . it is customary to APM Systematic , We have to complete some automatic point embedding work , In this way, application developers don't need to do any buried point work , You can see a lot of useful data . Like the last two lines type=Order Data belonging to manual burying point .
- Management needs special attention type、name、status Dimensions “ The explosion ”, Too many of them can be very resource intensive , It could directly drag us down Dog System .type Maybe not too many dimensions , But we may need to be aware that developers may abuse name and status, So we have to do normalize( Such as url It could be with dynamic parameters , It needs to be formatted ).
- The last two in the table are developers Manual burying point The data of , Usually used to count specific scenes , For example, I want to know when a method is called , Call the number 、 Time consuming 、 Whether to throw the abnormality 、 Enter the reference 、 Return value, etc . Because the business doesn't want to close the automatic burial point , Cold data , Developers may want to bury some data they want to count .
- When developers are manually burying points , You can also report more business-related data , Refer to the last column of the table , This data can be used for business analysis . For example, I work in payment system , Usually a payment order involves a lot of steps ( Payment abroad and wechat we usually use 、 Alipay is a little different. ), By reporting the data of each node , In the end, I'll be able to Dog Upper use bizId To connect the entire link , It's very useful in troubleshooting ( When we do payment business , The success rate of payment is not as high as you think , Many nodes may have problems ).
Client design
In the last section, we introduced the single message The data of , Let's cover the rest of this section .
First , Let's introduce the client's API Use :
public void test() {
Transaction transaction = Dog.newTransaction("URL", "/test/user");
try {
Dog.logEvent("User", "name-xxx", "status-yyy");
// do something
Transaction sql = Dog.newTransaction("SQL", "UserMapper.insert");
// try-catch-finally
transaction.setStatus("xxxx");
transaction.setSuccess(true/false);
} catch (Throwable throwable) {
transaction.setSuccess(false);
transaction.setData(Throwables.getStackTraceAsString(throwable));
throw throwable;
} finally {
transaction.finish();
}
}The above code example shows how to use nested Transaction and Event, When the outermost Transaction stay finally Code block call finish() When , Finished creating a tree , Send messages .
We went to Kafka It's not one of the Message example , Because one request can produce a lot of Message example , It should be organized into One Tree The instance will be delivered later . The following figure describes Tree Properties of :
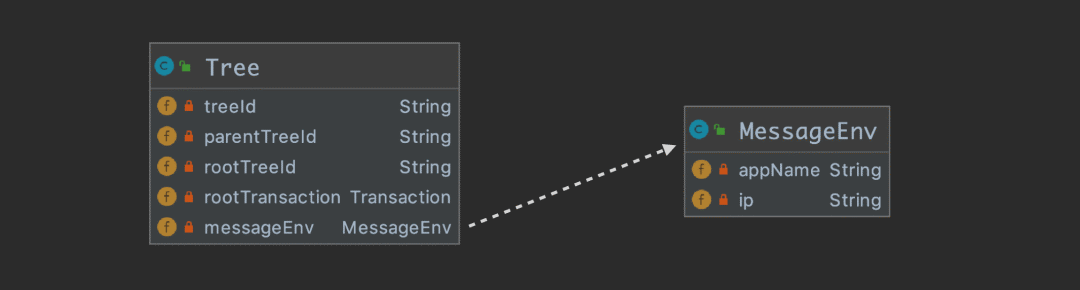
Tree It's easy to understand the properties of , It holds root transaction References to , To traverse the whole tree . The other is to carry machine information messageEnv.
treeId There should be an algorithm that guarantees global uniqueness , A brief introduction Dog The implementation of the :{encode(ip)}- Current minute { Self increasing id}.
Here is a brief introduction to a few tree id Related content , Suppose a request comes from A->B->C->D after 4 Applications ,A It's the portal app , Then there will be :
1、 There will be a total 4 individual Tree Object instances from 4 An app is delivered to Kafka, When calling across applications, you need to pass treeId, parentTreeId, rootTreeId Three parameters ;
2、A Applied treeId It's all nodes rootTreeId;
3、B Applied parentTreeId yes A Of treeId, Empathy C Of parentTreeId yes B Applied treeId;
4、 When calling across applications , For instance from A call B When , To know A What's the next node for , So in A In advance for B Generate treeId,B Upon receipt of the request , If you find that A Has been generated for it treeId, Use the treeId.
It should be easy for you to know , These are through tree id, We want to achieve trace The function of .
The introduction is over. tree The content of , Let's briefly discuss the application integration solution .
Integration is nothing more than two technologies , One is through javaagent The way , In the startup script , Add the corresponding agent, The advantage of this approach is that developers have no perception , It can be done at the operation and maintenance level , Of course, if developers want to do some buried points manually , You may need to provide another simple client jar Package to developers , To bridge to agent in . The other is to provide a jar package , It's up to the developer to introduce this dependency .
The two schemes have their own advantages and disadvantages ,Pinpoint and Skywalking It uses javaagent programme ,Zipkin、Jaeger、Cat The second solution is used ,Dog Also use the second method of manually adding dependencies .
Generally speaking , do Traces Choose to use javaagent The plan is easy , Because this kind of system agent We've done all the burying we need , There's no need for app developers to perceive .
Last , Let me give you a brief introduction to Heartbeat The content of , This part is actually the simplest , But you can make a lot of colorful charts , It can realize boss oriented programming .
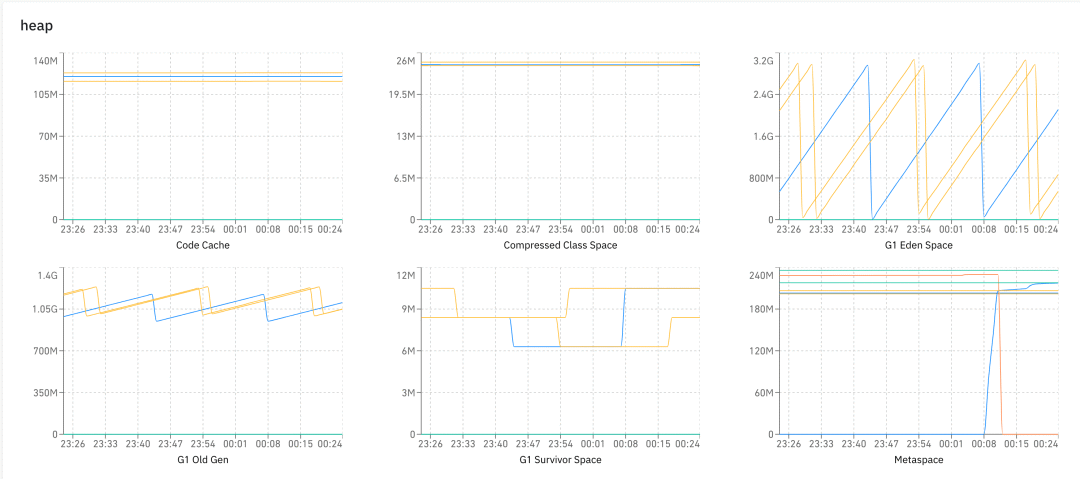
We introduced Message There are two subclasses Event and Transaction, Here we add another subclass Heartbeat, Used to report heartbeat data .
We mainly collect thread、os、gc、heap、client Operation of the ( How many tree, data size , Number of send failures ) etc. , It also provides api Let developers customize data for reporting .Dog client Will open a background thread , It runs every minute Heartbeat Collection procedure , Report data .
More details . The core structure is a Map<String, Double>,key Be similar to “os.systemLoadAverage”, “thread.count” etc. , Prefix os,thread,gc And so on are actually used to classify on the page , The suffix is the name of the line chart displayed .
About clients , That's all , In fact, in the actual coding process , There are still some details to deal with , For example, what to do if a tree is too big , Such as no rootTransaction How to deal with the situation ( The developer just calls Dog.logEvent(...)), For example, the inner nested transaction There is no call finish How to deal with it and so on .
Dog server Design
The figure below illustrates server The overall design of , It is worth noting that , We are very restrained in using threads here , There is only 3 Four worker threads .
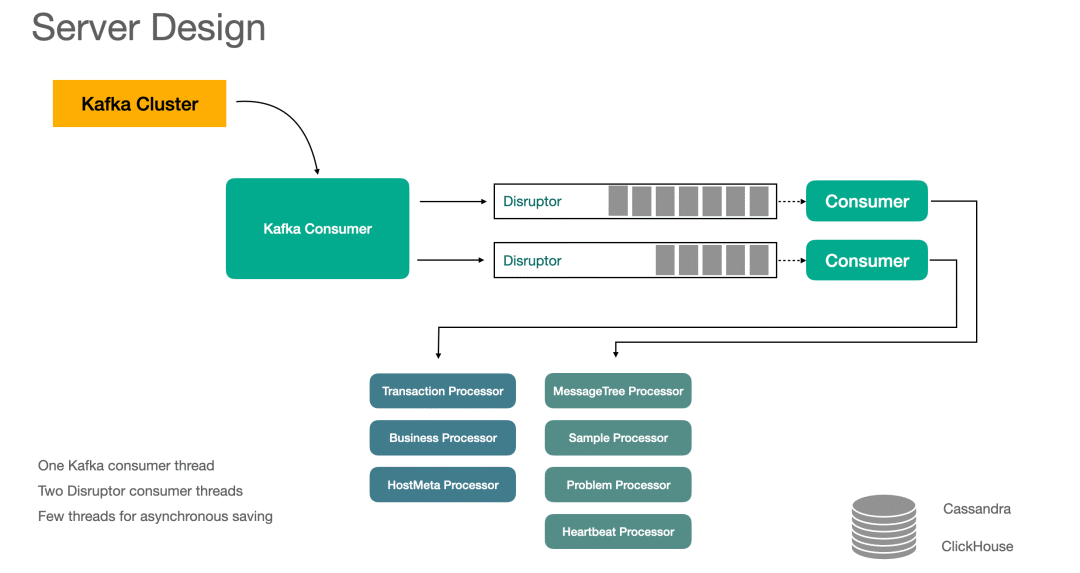
First of all Kafka Consumer Threads , It's responsible for mass consumption of messages , from kafka The consumption in the cluster is one by one Tree Example , Next, think about what to do with it .
ad locum , We need to make the tree structure message to pave nicely , We call this step deflate, And do some pretreatment , Form the following structure :
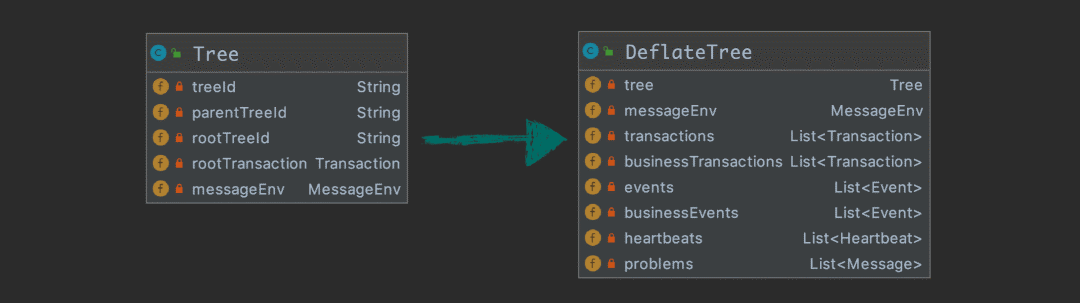
Next , We will DeflateTree To two separate Disruptor In the example , We put Disruptor Designed as single thread production and single thread consumption , It's mainly about performance . Consumption thread is based on DeflateTree Use the bound Processor To deal with , such as DeflateTree in List<Message> problmes Not empty , At the same time, I bound ProblemProcessor, Then you need to call ProblemProcessor To deal with it .
The popular science time :Disruptor Is a high-performance queue , Performance ratio JDK Medium BlockingQueue It is better to
Here we use 2 individual Disruptor example , Of course, you can also consider using more examples , So each consumer thread is bound to processor Even less . Let's put Processor Bound to Disruptor For instance , The reason is simple , For performance , We want everyone to processor Only a single thread uses it , Single thread operation can reduce the cost of thread switching , Can make full use of the system cache , And in design processor When , Don't worry about concurrent reading and writing .
Here we need to consider the load balancing situation , There are some processor It's more expensive CPU And memory resources , It must be distributed reasonably , We can't divide the most stressful tasks into one thread .
The core processing logic is all in each processor in , They're in charge of data calculation . Next , I put all the processor What we need to do is to introduce , After all, you can see the developers here , It should really be right APM I'm more interested in data processing .
Transaction processor
transaction processor It's where the system is most stressed , It's responsible for reporting statistics , although Message Yes Transaction and Event Two main subclasses , But in a real tree , Most of the nodes are transaction Data of type .
The picture below is transaction processor A major internal data structure , The outermost layer is a time , We take minutes to organize , We end up in persistence , It's also stored in minutes . Second floor HostKey Which application and which ip Data from , The third layer is type、name、status The combination of . innermost Statistics It's our data statistics module .

In addition, we can see , How much memory does this structure consume , In fact, it mainly depends on our type、name、status That's the combination of ReportKey Will there be a lot of , That's when we talked about client management , To avoid dimension explosion .
The outermost structure represents the minute representation of time , Our report is based on statistics per minute , And then persist to ClickHouse in , But when our users look at the data , Not every minute , So we need to do data aggregation , Here's how two pieces of data are aggregated , When there's a lot of data , They all merge in the same way .

If you think about it, you'll find , There is nothing wrong with the calculation of the previous data , however P90, P95 and P99 Is the calculation a bit deceiving ? In fact, there is no solution to this problem , We can only think of an appropriate data calculation rule , And then let's think about the rules of computation , Maybe the calculated value is almost usable .
There's another detail , We need to let the data in memory provide the latest 30 Minute Statistics ,30 More than minutes from DB Read . And then do the above merge operation .
Discuss : Whether we can discard part of real-time , We persist every minute , All the data we read is from DB To the , Is this feasible ?
no way , Because our data is from kafka Consumption comes from , It has a certain lag in itself , If we persist one minute's data at the beginning of one minute , Maybe I will receive the message of the previous time later , This situation can't be dealt with .
For example, we need to count the last hour , Then there will be 30 Minutes of data are obtained from various machines , Yes 30 Minutes of data from DB get , And then merge .
It's worth mentioning here , stay transaction In the report ,count、failCount、min、max、avg It's easier to calculate , however P90、P95、P99 Actually, it's not very easy to calculate , We need an array structure , To record the time of all events in this minute , Then calculate , We use it here Apache DataSketches, It's very easy to use , I will not expand here , Interested students can have a look at it by themselves .
Come here , You can think about it ClickHouse The amount of data .app_name、ip、type、name、status Different combinations of , One data per minute .
Sample Processor
sample processor consumption deflate tree Medium List<Transaction> transactions and List<Event> events The data of .
We also sample in minutes , Eventually every minute , For each type、name、status Different combinations of , The largest collection 5 A success 、5 A failure 、5 It's a slow process .
relatively speaking , This one is very simple , Its core structure is shown in the figure below :

combination Sample It's easier to understand the function of :
Problem Processor
Doing it deflate When , all success=false Of Message, Will be put in List<Message> problmes in , For error statistics .
Problem The internal data structure is shown in the figure below :

Let's take a look at this picture , In fact, I know what to do , I won't go on and on . among samples We save every minute 5 individual treeId.
By the way, I'll show you Problem The view of :
About persistence , We saved it ClickHouse in , among sample Concatenate a string with commas ,problem_data Here's the list :
event_date, event_time, app_name, ip, type, name, status, count, sampleHeartbeat processor
Heartbeat Handle List<Heartbeat> heartbeats The data of , Digression , Under normal circumstances , There is only one in a tree Heartbeat example .
I also mentioned it briefly , We Heartbeat The core data structure used to show charts in is a Map<String, Double> .
Collected key-value The data is shown below :
{
"os.systemLoadAverage": 1.5,
"os.committedVirtualMemory": 1234562342,
"os.openFileDescriptorCount": 800,
"thread.count": 600,
"thread.httpThreadsCount": 250,
"gc.ZGC Count": 234,
"gc.ZGC Time(ms)": 123435,
"heap.ZHeap": 4051233219,
"heap.Metaspace": 280123212
}The prefix is classification , The suffix is the name of the graph . The client collects data every minute for reporting , And then you can do a lot of maps , For example, the figure below shows heap All kinds of graphs under classification :
Heartbeat processor The thing to do is very simple , It's data storage ,Dog UI The data on is directly from ClickHouse Reads the .
heartbeat_data Here's the list :
event_date, event_time, timestamp, app_name, ip, name, valueMessageTree Processor
We've mentioned this many times before Sample The function of , These sampled data help us recover the scene , So we can go through trace View to track the chain of calls .
To do this above trace View , We need all the upstream and downstream tree The data of , For example, the picture above is 3 individual tree Instance data .
We said before in the introduction of the client , These are a few tree adopt parent treeId and root treeId To organize .
To do this view , The challenge for us is , We need to keep the full amount of data .
You can think about it , Why save the full amount of data , We keep it directly sample That's all right ?
Here we use Cassandra The ability of ,Cassandra In this way kv In the scene , It has very good performance , And its operation and maintenance costs are very low .
We use treeId A primary key , Plus data Just one column , It is the whole tree Instance data of , The data type is blob, We'll do it first gzip Compress , And then throw it to Cassandra.
Business Processor
When we introduced the client, we said , Every Message You can carry Business Data, But it's only when the application developer manually buries the point , When we find business data , We'll do another thing , That is to store this data in ClickHouse in , For business analysis .
We don't really know what scenarios app developers will use it in , Because everyone is responsible for different projects , So we can only make a general data model .
Looking back at this picture ,BusinessData We have defined the more general userId and bizId, We think they might be things that are used in every business scenario .userId Not to mention ,bizId You can do it to record orders id, Payment note id etc. .
And then we offered 3 individual String Column of type ext1、ext2、ext3 And two numeric Columns extVal1 and extVal2, They can be used to express your business related parameters .
Our treatment is also very simple , Save the data to ClickHouse Medium will do , There are mainly these columns in the table :
event_data, event_time, user, biz_id, timestamp, type, name, status, app_name、ip、success、ext1、ext2、ext3、ext_val1、ext_val2These data are very important to us Dog I don't know about the system , Because you don't know what our business is ,type、name、status It's defined by the developers themselves ,ext1, ext2, ext3 What do they mean , We all don't know , We're only responsible for storing and querying .
These business data are very useful , Based on these data , We can do a lot of data reports . Because this article is about APM Of , Therefore, this part will not be repeated .
other
ClickHouse Need to write in bulk , Otherwise, it will not hold up , Generally one batch At least 10000 Row data .
We are Kafka This layer controls , One app_name + ip The data of , It's the same thing dog-server consumption , Of course, it's not to say that by multiple dog-server There will be problems with consumption , But this way ClickHouse There will be more data .
There's another key point , We talked about each of them processor Is accessed by a single thread , But there's a problem , That's from Dog UI What can I do with the request on ? I've come up with a solution here , That is to put the request in a Queue in , from Kafka Consumer That thread to consume , It's going to throw the mission at two Disruptor in . For example, the request is transaction Report request , One of them Disruptor Consumers will find that this is what they want to do , I'm going to carry out this mission .
Summary
If you know Cat Words , You can see Dog In many places and Cat There are similarities , Or just say ” copy “ It's OK , We've considered using it directly before Cat Or in Cat On the basis of the second development . But I'm through Cat After the source code , I gave up the idea , Think carefully , It's just a reference Cat Data model of , And then we write our own set of APM It's not that hard , So with our project .
Writing needs , In many places, I avoid the heavy and take the light , Because this is not a source code analysis article , There's no need to go into details , It is mainly to give readers a panorama , Through my description, readers can think about what they need to deal with , What code needs to be written , Then when I make it clear .
Recent hot article recommends :
1.1,000+ Avenue Java Arrangement of interview questions and answers (2022 The latest version )
2. Explode !Java Xie Cheng is coming ...
3.Spring Boot 2.x course , It's too complete !
4. Don't write about the explosion on the screen , Try decorator mode , This is the elegant way !!
5.《Java Development Manual ( Song Mountain version )》 The latest release , Download it quickly !
I think it's good , Don't forget to like it + Forward !
边栏推荐
- C language games - minesweeping
- Force deduction brush question - 98 Validate binary search tree
- 快过年了,心也懒了
- Logic is a good thing
- Common doubts about the introduction of APS by enterprises
- 逻辑是个好东西
- 7. Data permission annotation
- Simple continuous viewing PTA
- [wechat applet] operation mechanism and update mechanism
- use. Net analysis Net talent challenge participation
猜你喜欢

Application layer of tcp/ip protocol cluster
Distributed ID
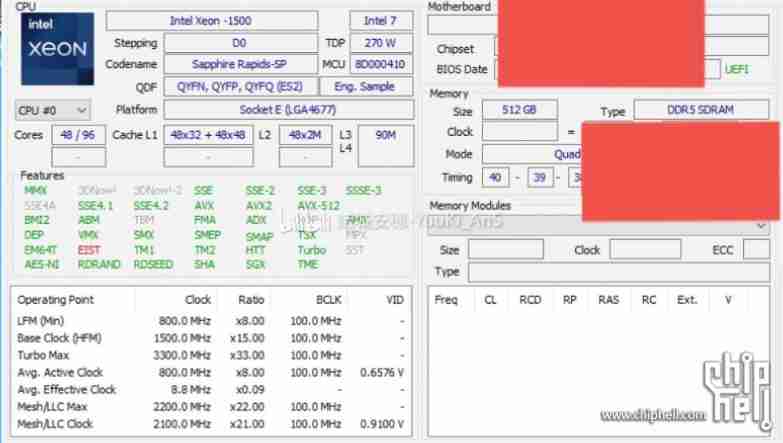
Intel 48 core new Xeon run point exposure: unexpected results against AMD zen3 in 3D cache
![[asp.net core] set the format of Web API response data -- formatfilter feature](/img/6b/e3d513f63b244f9f32555d3b3bec8c.jpg)
[asp.net core] set the format of Web API response data -- formatfilter feature
看过很多教程,却依然写不好一个程序,怎么破?
OAI 5g nr+usrp b210 installation and construction

(work record) March 11, 2020 to March 15, 2021
Comprehensive evaluation and recommendation of the most comprehensive knowledge base management tools in the whole network: flowus, baklib, jiandaoyun, ones wiki, pingcode, seed, mebox, Yifang cloud,
![[DSP] [Part 2] understand c6678 and create project](/img/06/54b1cf1f5b3308fffb4f84dcf7db9b.png)
[DSP] [Part 2] understand c6678 and create project
![[weekly pit] calculate the sum of primes within 100 + [answer] output triangle](/img/d8/a367c26b51d9dbaf53bf4fe2a13917.png)
[weekly pit] calculate the sum of primes within 100 + [answer] output triangle
随机推荐
Spark SQL chasing Wife Series (initial understanding)
[asp.net core] set the format of Web API response data -- formatfilter feature
[weekly pit] calculate the sum of primes within 100 + [answer] output triangle
(工作记录)2020年3月11日至2021年3月15日
C language games - minesweeping
B-jiege's tree (pressed tree DP)
Intel 48 core new Xeon run point exposure: unexpected results against AMD zen3 in 3D cache
Common doubts about the introduction of APS by enterprises
解剖生理学复习题·VIII血液系统
Rhcsa Road
How to upgrade high value-added links in the textile and clothing industry? APS to help
2022 refrigeration and air conditioning equipment installation and repair examination contents and new version of refrigeration and air conditioning equipment installation and repair examination quest
【DSP】【第一篇】开始DSP学习
C language games - three chess
[weekly pit] positive integer factorization prime factor + [solution] calculate the sum of prime numbers within 100
使用.Net驱动Jetson Nano的OLED显示屏
Force deduction brush question - 98 Validate binary search tree
[DIY]如何制作一款个性的收音机
Redis insert data garbled solution
基于STM32单片机设计的红外测温仪(带人脸检测)