当前位置:网站首页>[DSP] [Part 1] start DSP learning
[DSP] [Part 1] start DSP learning
2022-07-06 20:27:00 【Kshine2017】
2022 year 6 month 14 Japan
1. Deployment development environment
A little . Work needs ,TMS320C6678.
Learn from today DSP Knowledge .
How to install the deployment environment will be added later .
1.1 Components

1.1.1 SDK
MCSDK(CCSv5,CCSv6)+Path( All English path , No Chinese , No spaces )
After installation , Need a patch .Pocessor SDK (CCSv6)
1.1.2 Components
- XDCTools
- SYS/BIOS
- NDK
- UIA
- XDAIS
- Framework Components
1.1.3 Algorithm library
- DSPLIB
- MATHLIB
- IMGLIB
- VLIB
1.2 Integrated development environment
- Code Composer Studio (CCSv5,CCSv6)
1.3 other
1.3.1 compiler
CGT 7.4.x ,CGT 8.1.x
1.3.2 code / Decoding algorithm library
video
HEVC[H265], High compression efficiency , Large amount of computation .
H264 BP/MP/HP
MPEG4
JPEG
JPEG2000voice
G711
G722/G722…1/G722.2
G726
G728
OPUSMedicine related
Telecommunications related
1.4 setup script
1.4.1 download CCS Mirror image
- Official website , Search for CCS, Download the relevant version .
https://www.ti.com.cn/tool/cn/download/CCSTUDIO
1.4.2 install CCS Mirror image
- If during installation , Tips VC++ Runtime installation failed , You can install it first VC++2008 as well as VC++2012 Runtime [32 position ], And then install it CCSv5.
1.4.3 Install Fonts
- It is recommended to install equal width fonts , The width is the same in both Chinese and English .
- Download constant width fonts , Put it in Windows Of font In the folder
- stay CCS Code settings in the software , Font settings . Font size recommendations 12 Number , Script selection chinese GB2312.
1.4.4 Modify the theme
- install eclipse Theme plugin ,Eclipse Marketplace, to update , Search for theme,
- Choose a dark theme , Eye protection .
1.4.5 The menu displays Chinese
- install eclipse Language Translation , According to Chinese .
1.5 Install software components
Download address of embedded software products :https://software-dl.ti.com/dsps/dsps_public_sw/sdo_sb/targetcontent/index.html
Older software :https://software-dl.ti.com/dsps/dsps_public_sw/sdo_sb/targetcontent/legacy.html
1.5.1 TI-RTOS
https://www.ti.com.cn/tool/zh-cn/TI-RTOS-MCU?keyMatch=&tisearch=search-everything&usecase=software#downloads
https://software-dl.ti.com/dsps/dsps_public_sw/sdo_sb/targetcontent/tirtos/index.html
1.5.2 SYS/BIOS
https://www.ti.com.cn/tool/cn/SYSBIOS?keyMatch=SYS%20BIOS%20DOWNLOAD
https://software-dl.ti.com/dsps/dsps_public_sw/sdo_sb/targetcontent/bios/index.html
https://software-dl.ti.com/dsps/dsps_public_sw/sdo_sb/targetcontent/bios/sysbios/index.html
1.5.3 The Internet NDK
https://www.ti.com.cn/tool/zh-cn/NDKTCPIP?keyMatch=&tisearch=search-everything&usecase=software
https://software-dl.ti.com/dsps/dsps_public_sw/sdo_sb/targetcontent/ndk/index.html
1.5.4 UIA
https://software-dl.ti.com/dsps/dsps_public_sw/sdo_sb/targetcontent/uia/index.html
1.5.5 IPC
https://software-dl.ti.com/dsps/dsps_public_sw/sdo_sb/targetcontent/ipc/index.html
- Communication between multiple cores , Communication between multiple chips .
- It is no longer updated
1.5.6 Multimedia Framework Products
Codec Engine Management resources , frame
https://software-dl.ti.com/dsps/dsps_public_sw/sdo_sb/targetcontent/ce/index.htmlFramework components Provide abstract interface
https://software-dl.ti.com/dsps/dsps_public_sw/sdo_sb/targetcontent/fc/index.htmlXDAIS,XDM Algorithm
https://software-dl.ti.com/dsps/dsps_public_sw/sdo_sb/targetcontent/xdais/index.html
1.5.7 XDCtools Real time software components
https://software-dl.ti.com/dsps/dsps_public_sw/sdo_sb/targetcontent/rtsc/index.html
1.5.8 CGT compiler
https://www.ti.com/tool/TI-CGT
https://software-dl.ti.com/codegen/non-esd/downloads/download_archive.htm
1.6 Software library
1.6.1 MATHLIB
https://www.ti.com.cn/tool/cn/MATHLIB?keyMatch=MATHLIB#downloads
1.6.2 IQMath
- C64x+ IQMath library - Virtual floating point engine
https://www.ti.com.cn/tool/zh-cn/SPRC542?keyMatch=&tisearch=search-everything&usecase=partmatches
1.6.3 FastRTS
- Optimization of basic mathematical operations .
1.6.4 DSPLIB
- Digital signal processing , Handle floating point
1.6.5 IMGLIB
- The image processing ,DCT Transformation , Discrete cosine transform
- Image analysis , Histogram
1.6.6 VLB
- Higher level image processing
1.6.7 VICP
- signal processing
1.6.8 VoLIB
- Sound processing library
1.6.9 FaxLIB
- Fax , codec
1.6.10 AER/AEC
- codec
1.6.11 Codecs
- codec
- voice , video , Image coding
1.7 Software development package
- MCSDK Multi core software development suite ( Older )
- MCSDK-VIDEODEMO
- PROCESSOR-SDK-C667X
2. Basic knowledge of
B Learn video on the Internet : Wang Jun, Beihang Electronic Information Engineering College 《DSP Architecture 》
2.1 Instruction cycle
Von Neumann structure .
1 Instruction cycles = 1 One or more machine cycles .
1 Machine cycles = 6 State cycles = 12 Clock cycles .6 section (s)12 pat (p).
1 State cycles = 2 Clock cycles .
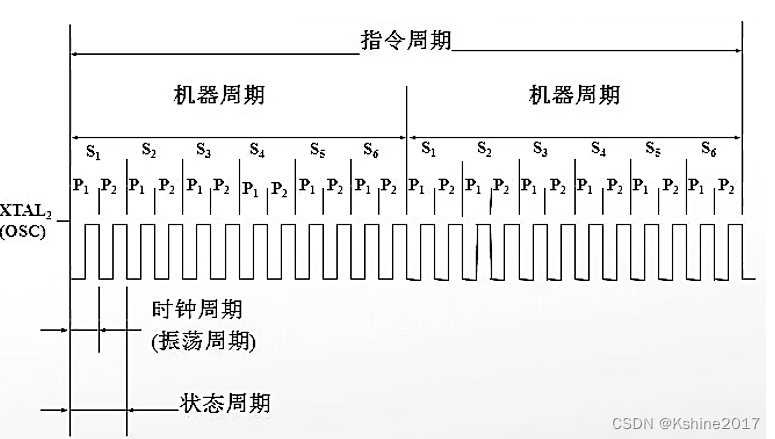
1 The execution of instruction cycles : Take command , decoding , perform ,( Write back to ).
Take command : From the data register MDR, Through the bus , Read to instruction register IR in .
decoding : Instruction decoder ID. Register the instruction IR Translate the instructions in .
perform : Execute instruction decoder ID The instructions given .stay s1p1 and s4p1 When the falling edge , , respectively, Read the instruction once ( Read one byte at a time ).
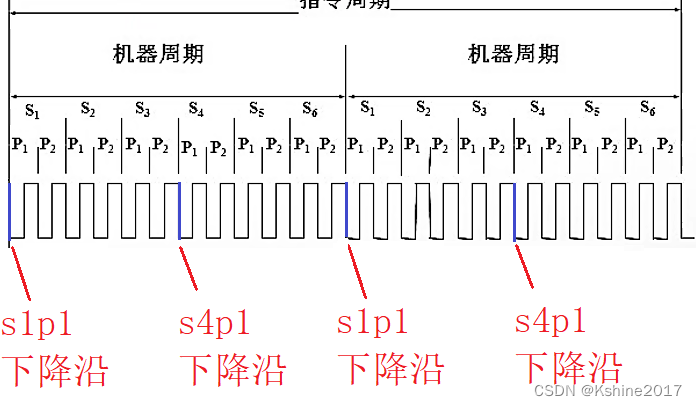
Different instructions , The length of instructions is different , The execution cycle of instructions is also different . There is a single byte and a single cycle , Double byte single cycle , Single byte double cycle , Double byte double cycle , Double byte three cycles ......
2.2 Executive performance
When the dominant frequency is the same ,CPI The smaller it is , The better the performance .
clock frequency : reaction DSP implementation technique , Production process
CPI: reaction DSP Instruction set structure ,DSP Architecture .
IC: reaction DSP Instruction set structure and Compilation Technology , And programming level .

Instruction cycle , It refers to the time required to execute an instruction . Usually, the ns In units of .
MAC Time , The time of a multiplication and a wig . Most of the DSP Multiplication and addition can be completed once in an instruction cycle .
FFT execution time , To measure DSP An indicator of the computing power of a chip .
MIPS: namely M+IPS. Execute millions of instructions per second .
MFLOPS, Perform millions of floating-point operations per second .
in application ,tdsp The time must be less than the sampling time ts,
2.2 Assembly line
- PipeLine.
- Using assembly line , take CPI=12(24) drop to CPI=1.
2.2.1 The type of pipeline
(1) According to the number of functions
Single function pipeline , Only one function can be completed .
Multifunctional pipeline , Can complete different functions .
(2) According to the connection mode between segments at the same time
Static pipeline , At the same time , Each segment is connected according to one function .
Dynamic pipeline , At the same time , Each segment can be connected according to different functions .
(3) According to the level of the assembly line in the photo
Intraslice , Command pipeline DLX, Computing pipeline ( In core assembly line , Inter core assembly line ).
Between films , Multi chip parallel processor .
Machine room , Multiprocessor parallel processing , Task flow .
(4) Divide according to the data representation
(5) Divide according to whether there is a feedback loop
2.2.2 Command pipeline DLX(RISC framework )
- The architecture of the processor , Take command , decoding , perform , Visiting and depositing , Write back to .
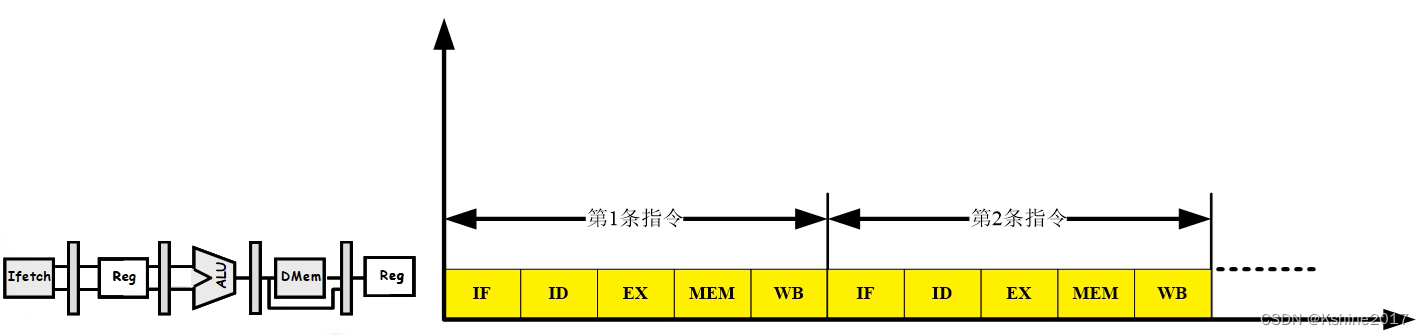
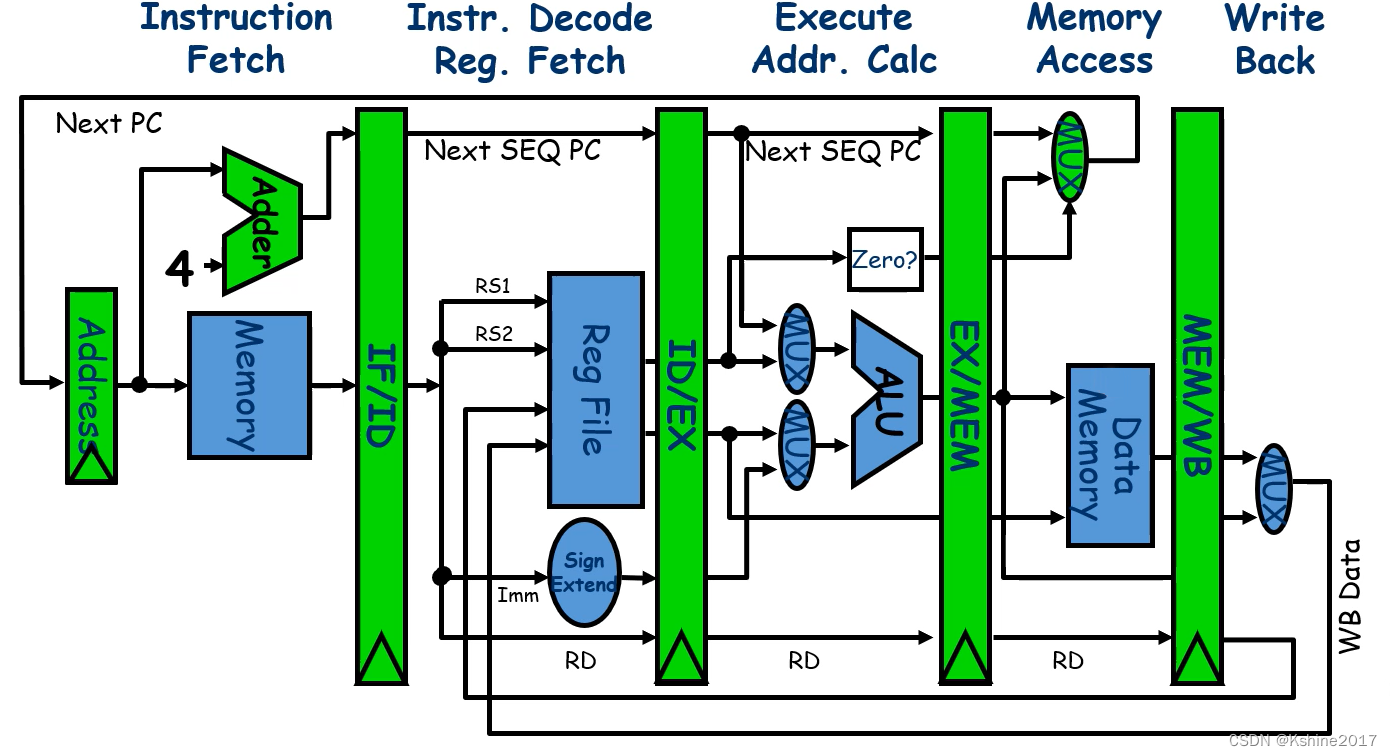
2.2.3 Instruction pipeline competition
(1) Structural competition , Hardware resources cannot meet the instruction pipeline execution .
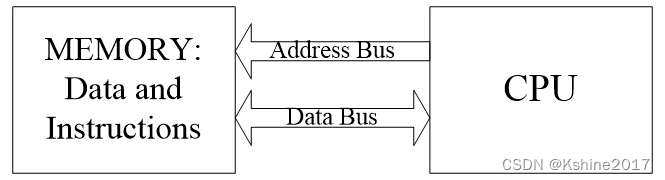
- Von Neumann structure There is only one bus , Used for data and instruction transmission .
- When both parts of the pipeline need to access memory , There will be competition . As shown in the figure below , When the first instruction is transmitted to the fourth link , The first link and the fourth link compete for the bus .
- The solution is , Move the command backward , And it must be moved to a position different from the fourth link and the first link . It's inefficient .
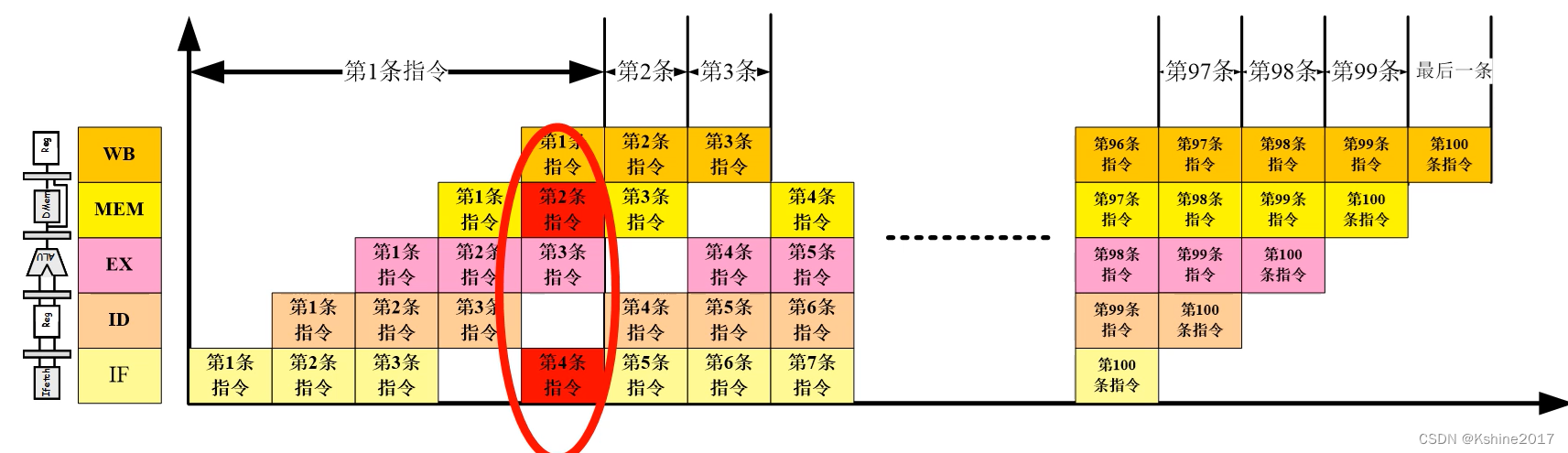
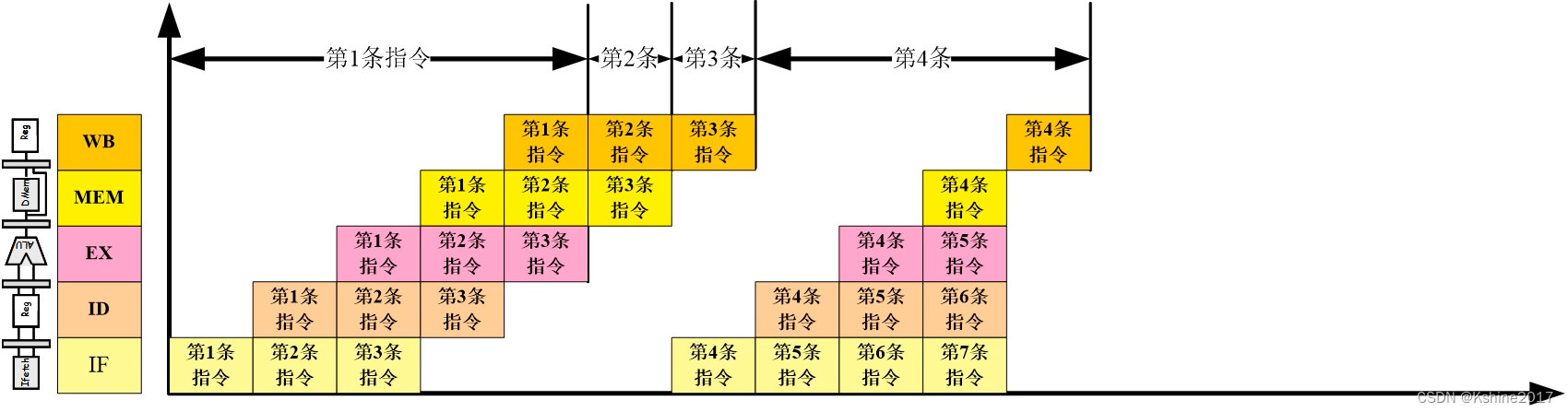
- Another solution , Another structure , Harvard structure . Add a bus , Data and instructions are stored separately , To avoid conflict .

(2) Data competition , When the previous instruction result cannot be output in time .
Rely on compilers and programming methods to solve .
Write before they are read Same register , There will be competition . If the method of moving back and waiting is adopted , It's going to be inefficient .
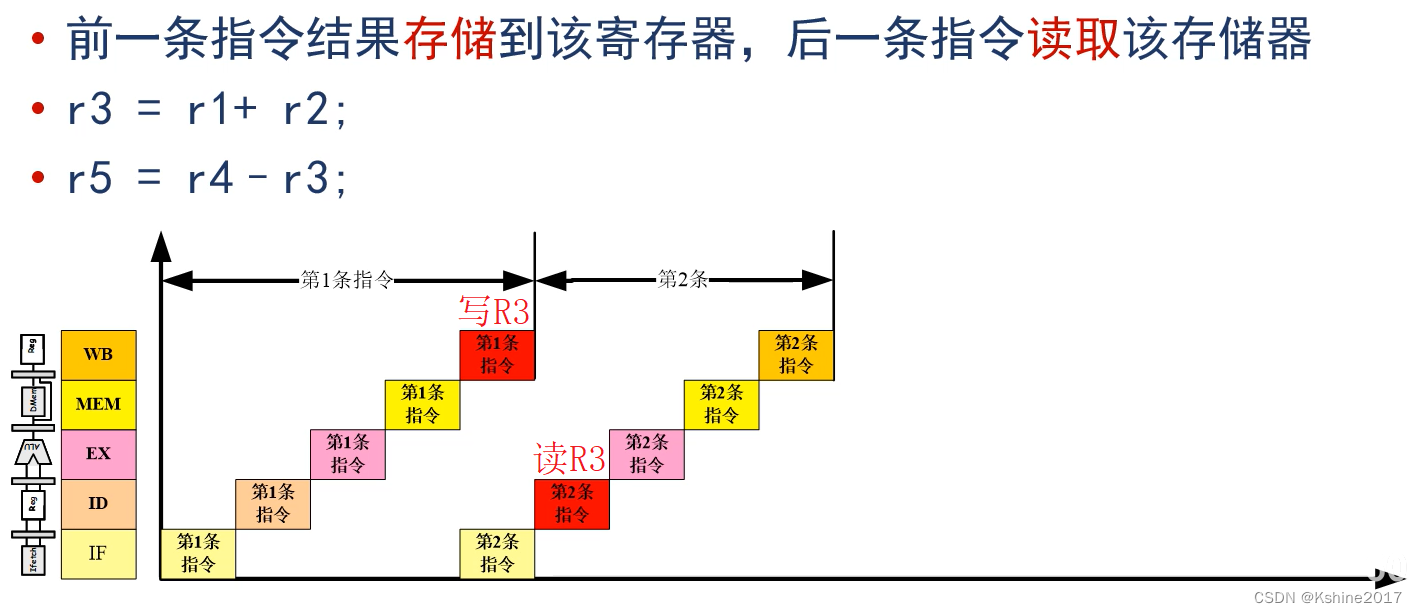
Change to First learns to write Same register , There will be no competition .
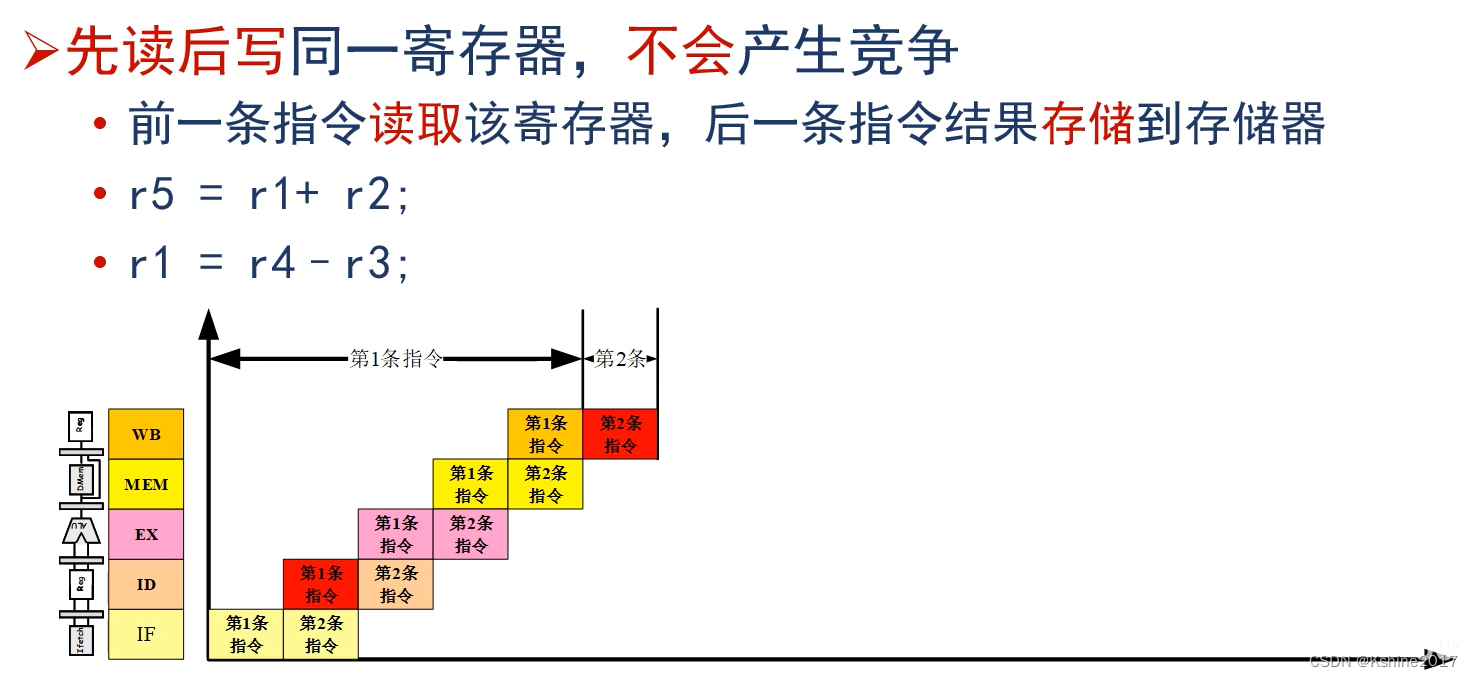
Read continuously perhaps Write in succession Same register , There will be no competition .
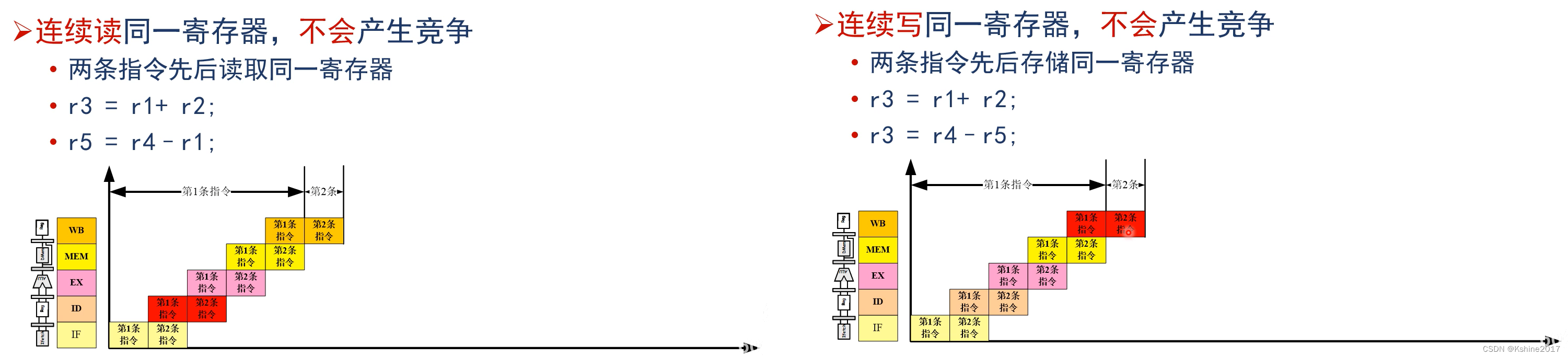
Eliminate data competition , Try to avoid operating on the same register ; Moving forward does not produce competitive instructions ( Insert other instructions in the middle ).
Compiler choice :
The clock of the pipeline is correct ,
The data result of the pipeline is correct
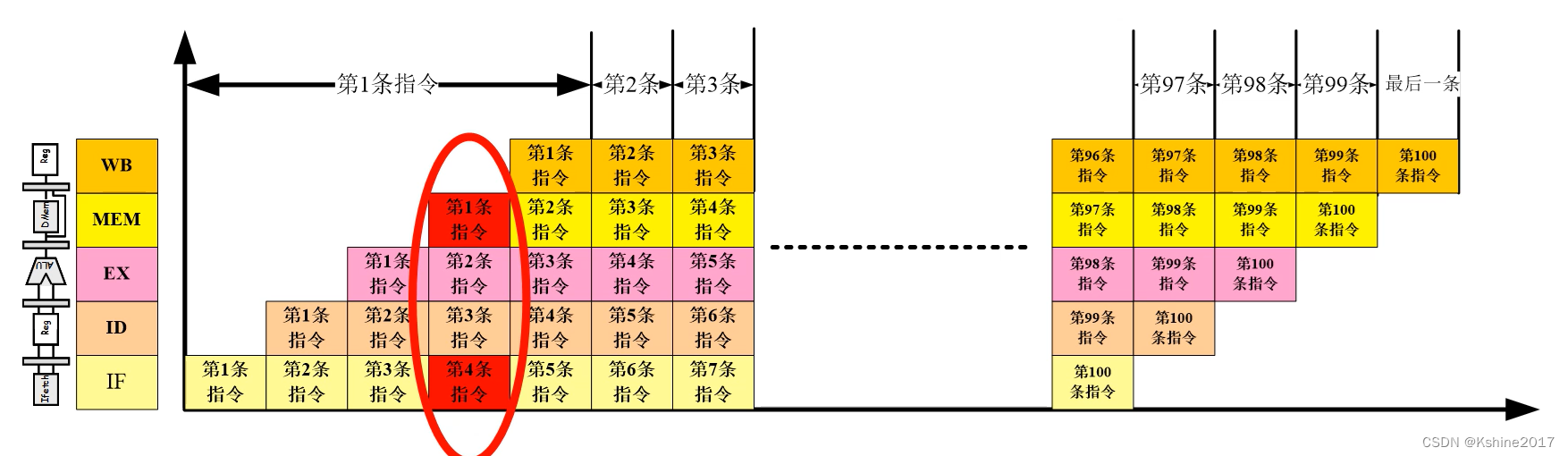
(3) Control competition , Jump and other changes PC Value instruction pre read does not match the actual .
- Instructions 5 Used to judge the jump direction , One is to continue executing instructions 6, One is jump back instruction 1.
- If a jump back instruction appears 1 The situation of , Others under the assembly line 678 The part of the instruction that has been loaded needs to be cleared , Then there will be a gap in the middle , The assembly line is disconnected .
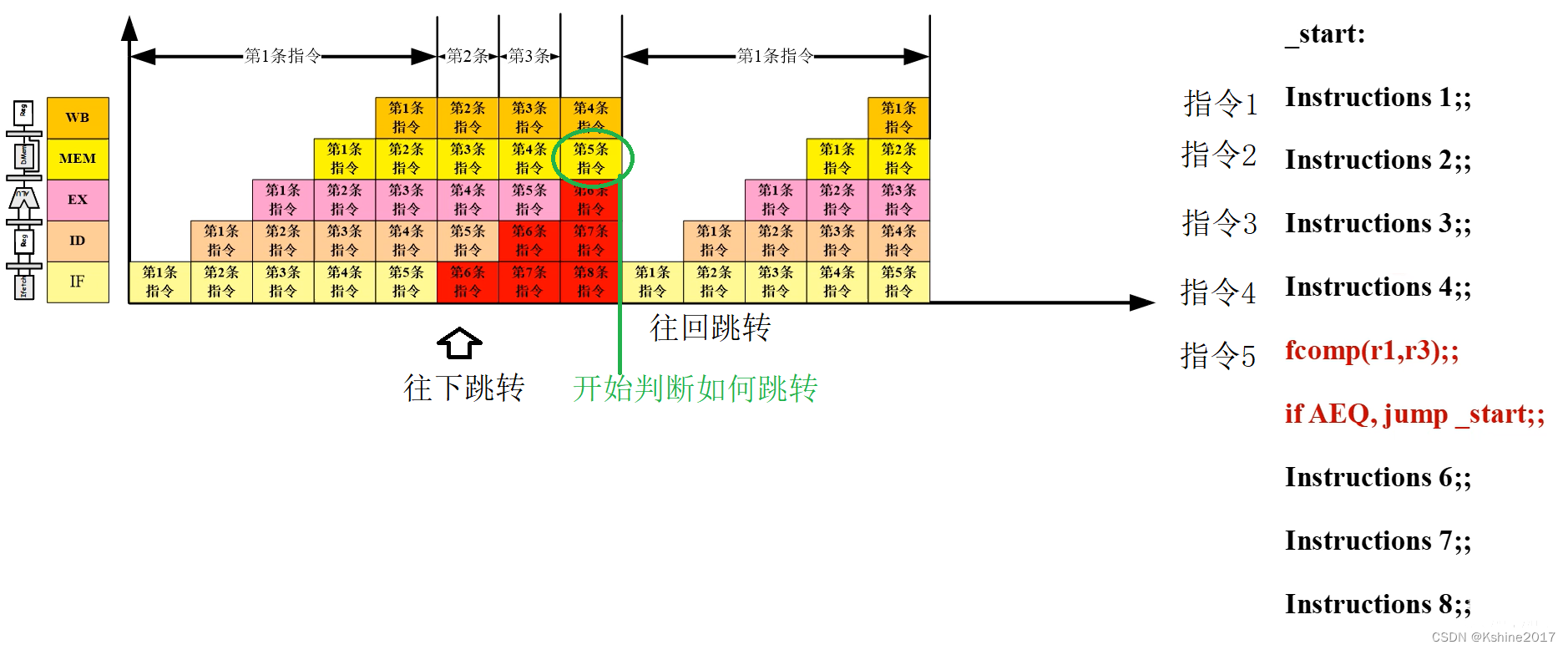
- Method 1 : Branch prediction , Load instructions with high execution probability .
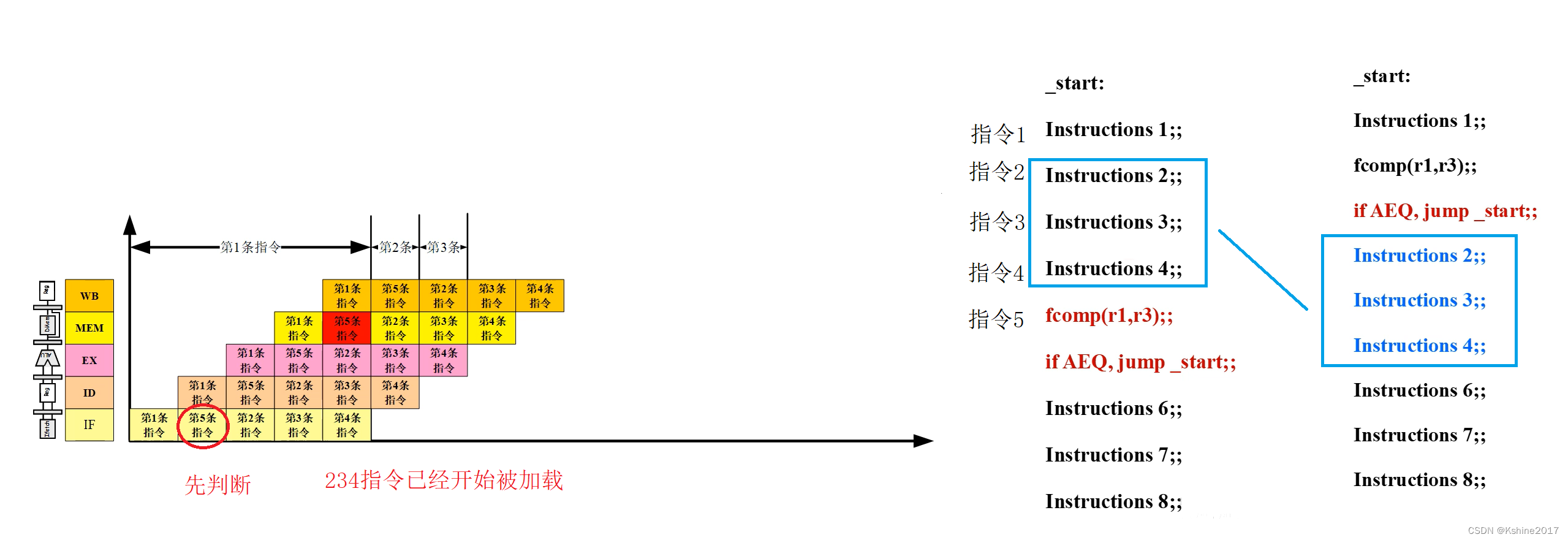
- Method 2 : The jump command moves forward . As shown in the figure below , Except for instructions 1 And instructions 6 Outside ,234 It must be implemented .
2.3 bring CPI Further down
Video link 《DSP Architecture 》
- It is known that , Assembly line makes CPI=12 or 24 drop to CPI=1. This section describes how to make CPI<1.
- Traditional assembly line CPI = 1.
- Complete multiple instructions in one clock CPI<1.
2.3.1 Super pipeline
- CPI=1, The main frequency is increased .
- Refine the flow , Increase the main frequency , Space for time .
- Pentium4 Galloping 4 On the processor , application 20 Class assembly line .
- 《 Baidu Encyclopedia 》 Super pipelined processors are relative to benchmark processors , commonly cpu The pipeline of is basic instruction prefetching , decoding , Execute and write back result level 4 . Super pipeline (superpiplined) It refers to a certain type CPU The internal assembly line exceeds the usual 5~6 Step above , for example Pentium pro The assembly line is as long as 14 Step . The steps of pipeline design ( level ) More , The faster it completes an instruction , Therefore, it can adapt to work with higher dominant frequency CPU.
2.3.2 Very long instruction words (VLIW,very long instruction word)
- Complete multiple instructions in one clock CPI<1
- A very long instruction set ,8x32bit = 256bits. Multiple assembly lines are combined .
- TI The company's C6000 Start using after series VLIW technology .
- Program compile time , According to parallelism , Combine into multi operation super long instruction words . There will be many 32 Bit null instruction , After compiling the program , The larger , Program storage efficiency is not high .
- VLIW Each segment corresponds to a different operation unit .D,D,M,M,L,L,S,S.
(1) Each clock cycle starts one VLIW Instructions .
(2) Each section controls an operation unit .
(3) compile , When programming , Solve the competition problem , The control hardware is relatively simple .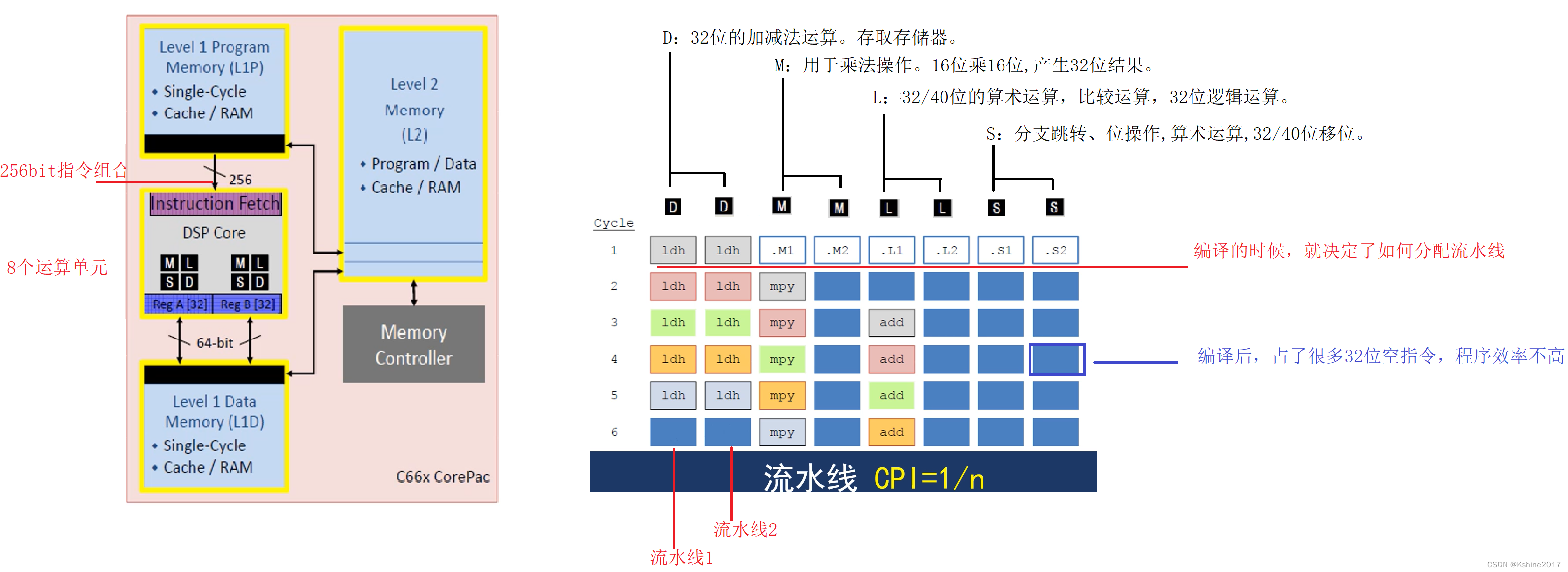
2.3.3 Superscalar (super scalar)
- And VLIW The structure is similar to .
- Execution time , According to resources , Data competition , Decide whether a unit executes .
- On the basis of ultra long instruction set, the storage efficiency of the program is improved .
2.4 DSP Software optimization technology
- The essence of software optimization : How to use DSP Hardware resources in .
- We need to know what hardware resources there are .
2.4.1 understand DSP Hardware resources
sketch
- With TI The company's TMS320C6678 For example .
- L1 Memory (L1P Program ,L1D data ),L2 Memory .
Functional units
- There are two register groups A and B, Each register group has 4 A functional unit MLSD.
(1)M,multiplier Multiplier .
(2)L,ALU Logical unit .
(3)S,Data Data unit .
(4)D,Control Control and jump unit .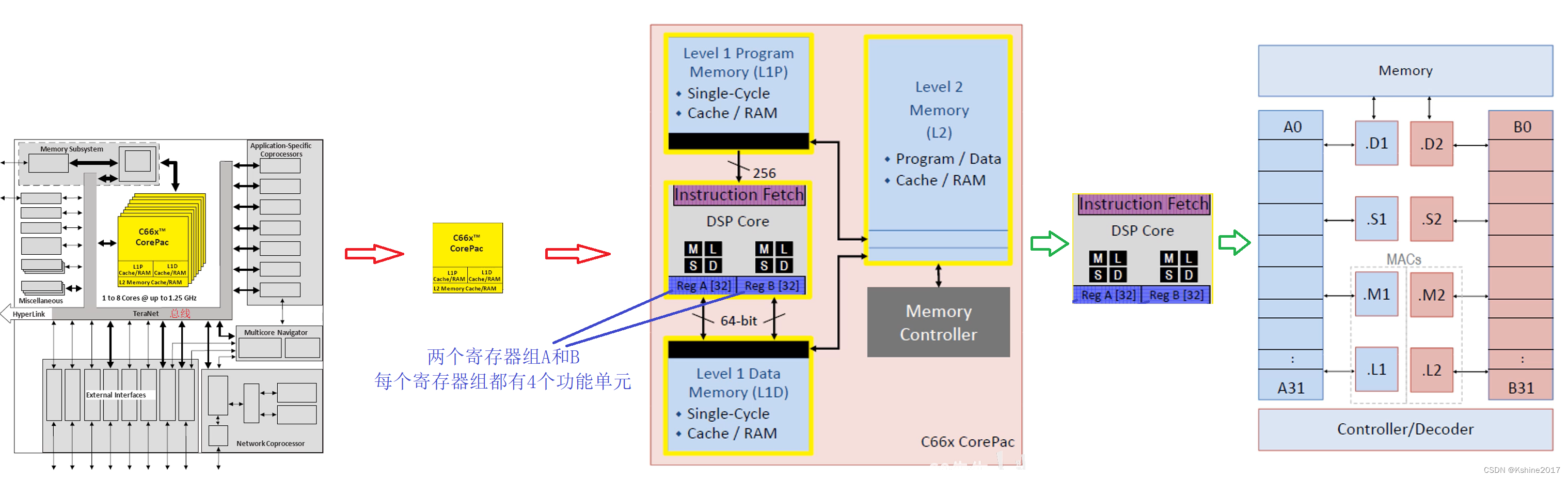
Swap paths
A Side and B Side exchange data .
Internal bus
Command pipeline
Three instructions , When there is no assembly line , Serial execution , need 9 Clock cycles . Adopt assembly line , It only needs 5 Clock cycles .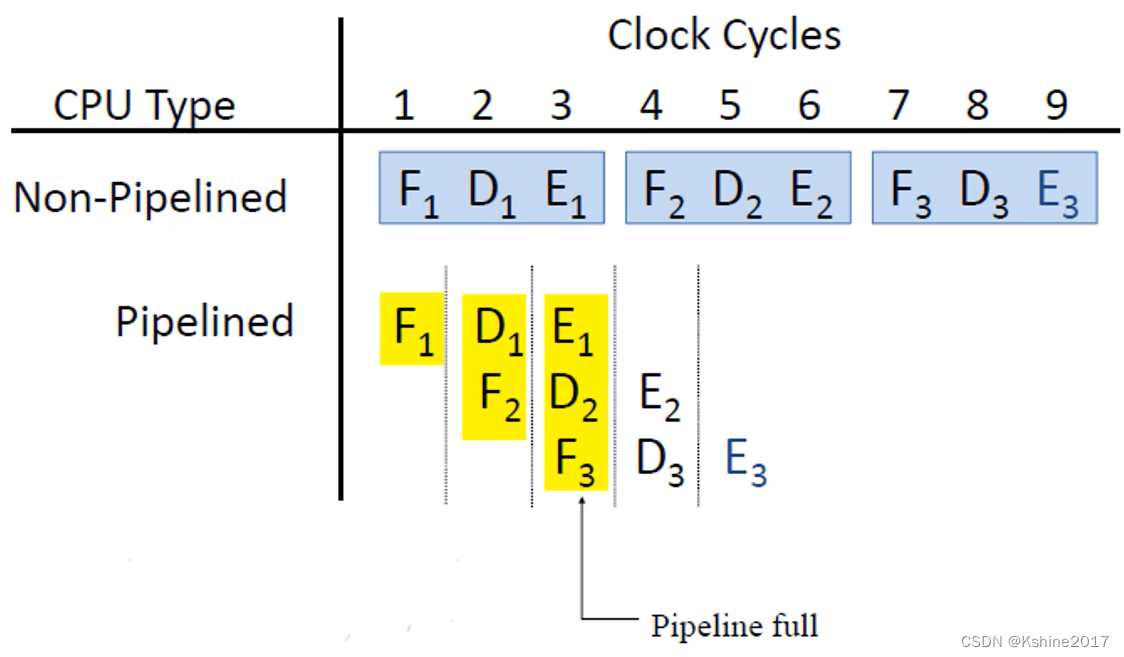
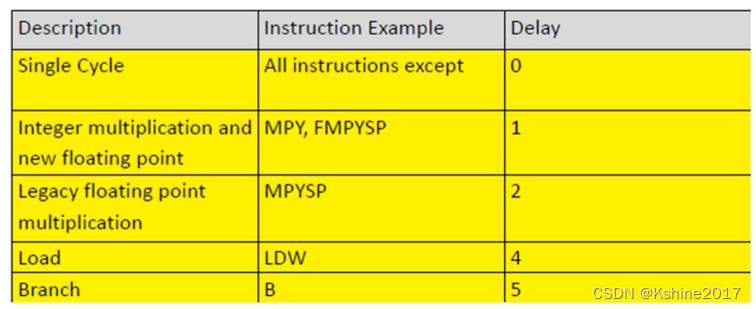
Instruction delay
- Most instructions can get results immediately .
- Multiplication , Delay 1 pat .
- Floating point multiplication , Delay 2 pat .
- Data loading , You need to give an address first , The memory only returns one data , Need to delay 4 pat .
- Jump , You need to clear the pre stored instructions , Need to delay 5 pat .
2.4.2 DSP Software optimization
- The purpose of software optimization : Running speed and code size .
- Optimization programming requirements : Familiar with processor architecture , Familiar with programming language (C, assembly , Linear assembly ).
- Learn about code generation tools ( compiler , Assembler , The linker )
- C6X Optimize C compiler , Use ANSI C Source code , It can achieve manual optimization 80%. Need to understand various optimization levels .
Assembly optimization means
(1) Instruction parallelism .
(2) fill NOP Instructions .
(3) Loop unrolling .( eliminate sub,b Instruction overhead ).
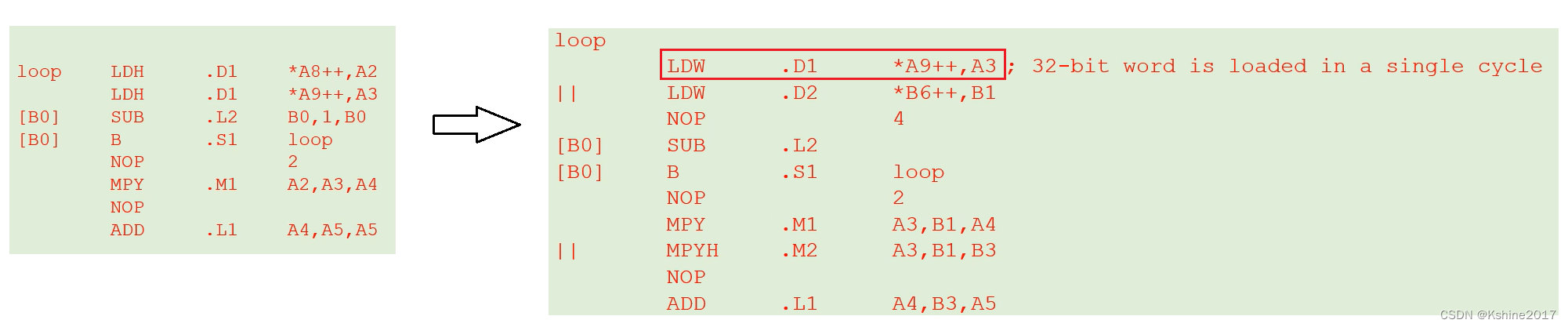
(4) Word or double word access .
2.4.3 Refer to the optimization case

- Instructions for loading data , It can be executed in parallel .
- eliminate sub+b Jump time waiting .

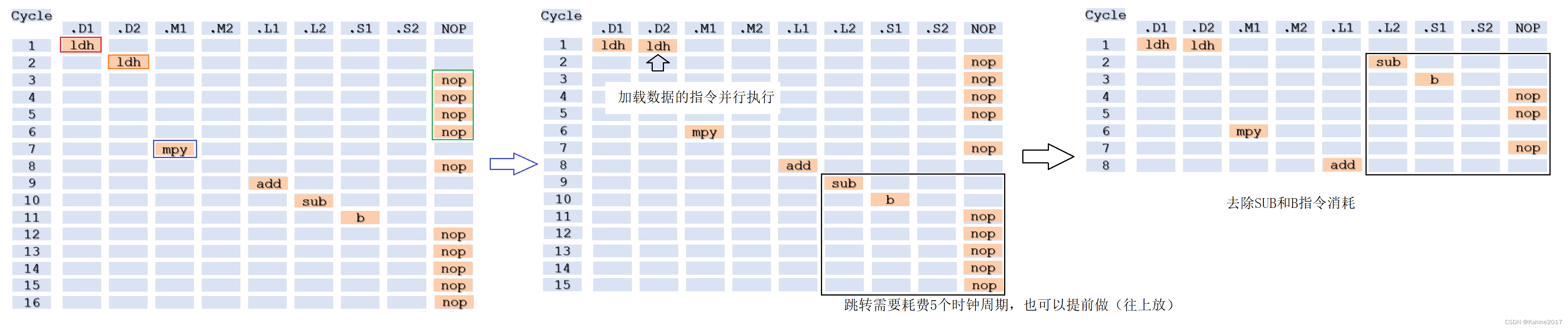
- Loop unrolling , Eliminate the overhead of jump instructions .
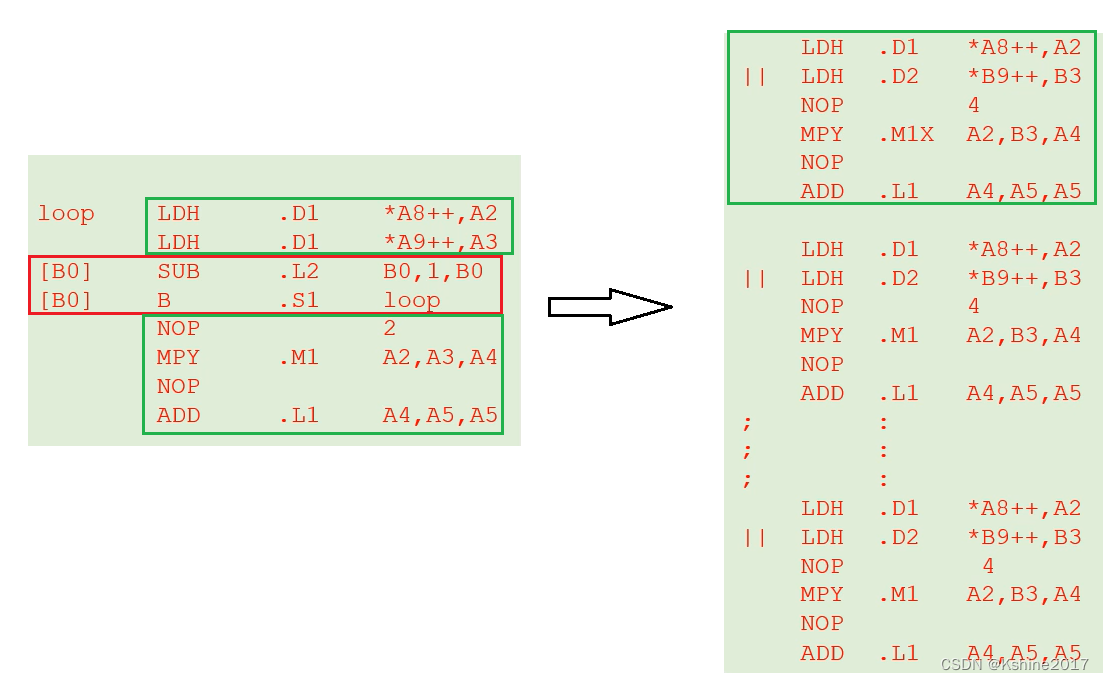
- Use word or doubleword access
2.4.4 Software pipelining
B Stop video 《DSP Software optimization 》
1. C Language implementation algorithm
2. C6x Linear assembly of
- No delay Nop
- No instruction parallel
- There is no need to consider functional units and registers

3. Design diagrams
- In the process of getting the code , Dependency , Data path , Guide us in allocating resources .
- Draw algorithm nodes and paths
- Write instruction cycles consumption
- Assign functional units to nodes
- Divide nodes into A,B All functional units on both sides
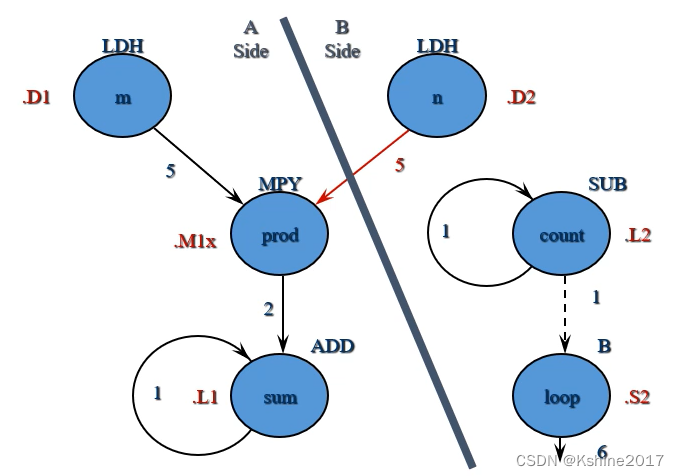
4. Allocation register
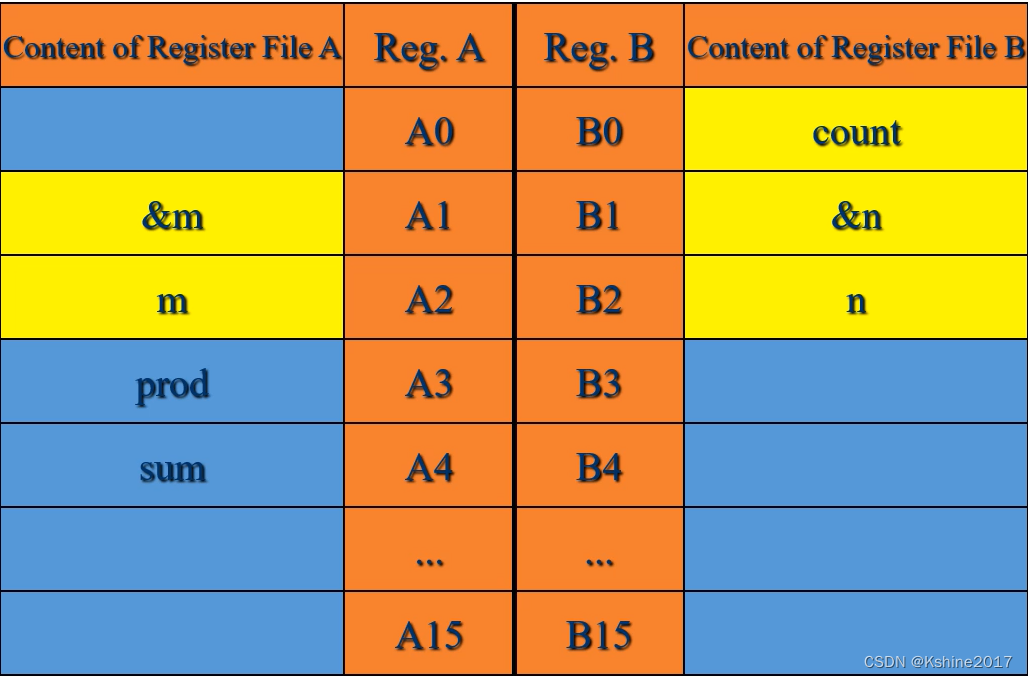
5. Create a process table
- front 7 Clock cycles , In the process of establishing a cycle .
- The first 8 A clock cycle begins , It's a circular body .
- The figure does not show the , The process of cycle ending processing .
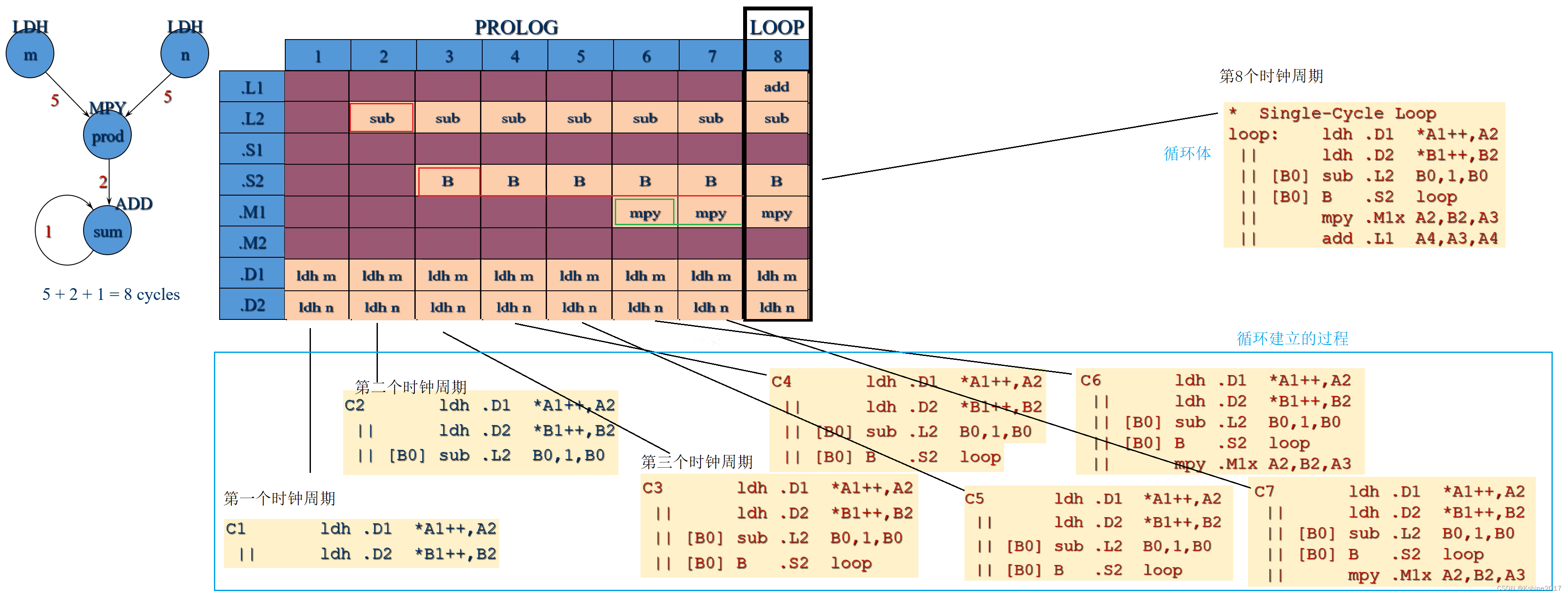
6. transformation C6x Code
Prolog, Cycle building
Loop, loop
Epilog, Cycle ending , The known loop body includes loading two data , Multiplication , Add . Cycle closure and cycle establish correspondence and complementarity .
additional load
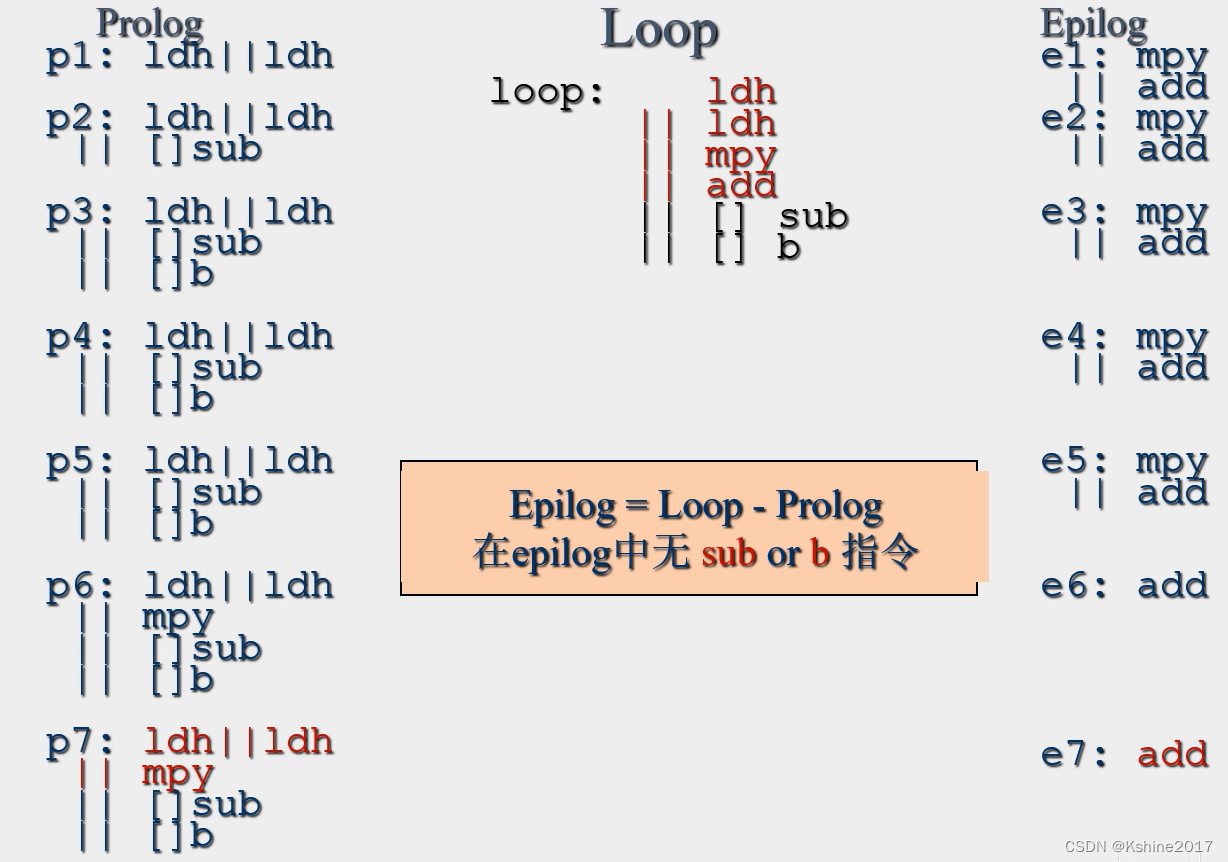
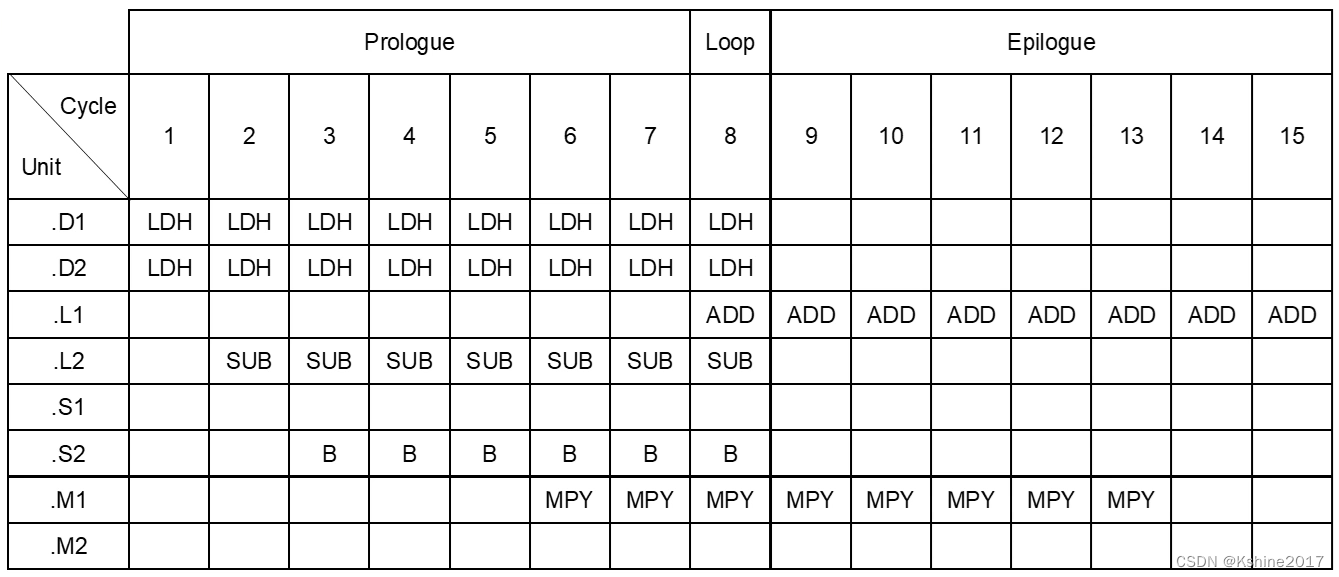
Complete schedule , Including cycle closure , Here's the picture .
Loop Only, During the cycle , Realize the closing work .
Remove all instructions except jump instructions .
Clear the input register , Accumulator and intermediate product .
Adjust the subtraction quantity .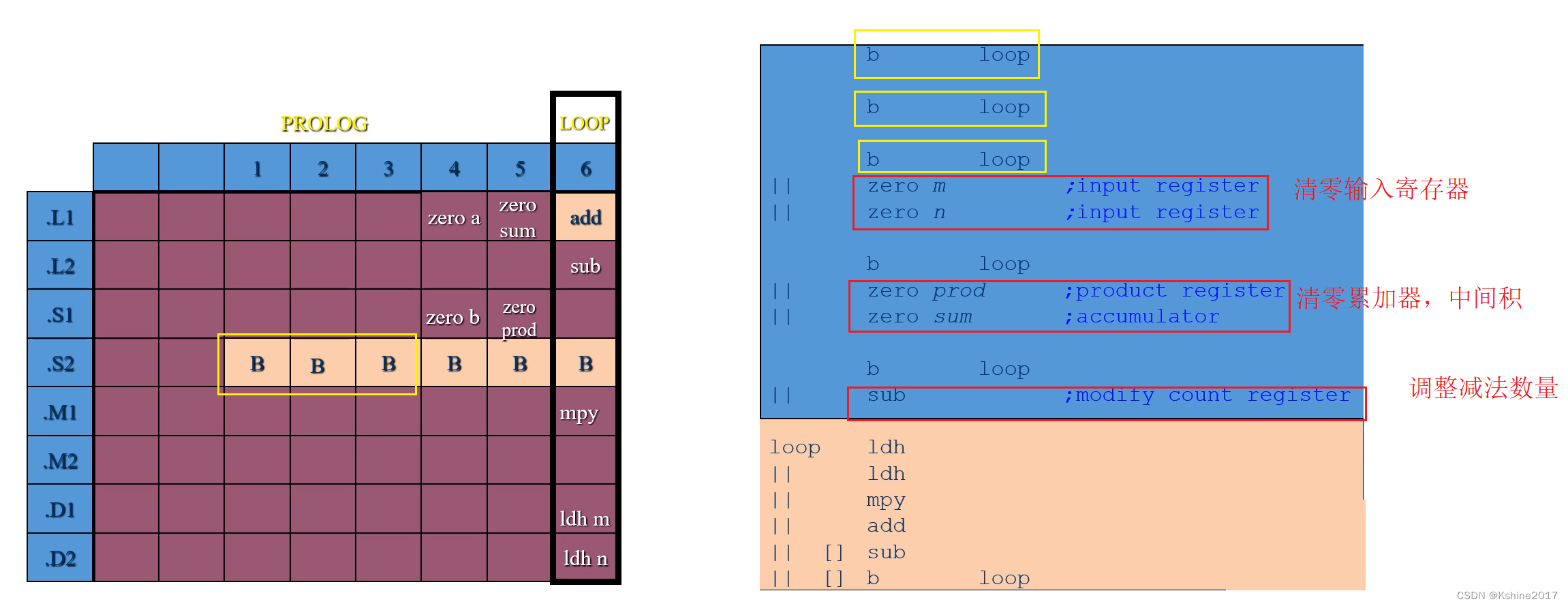
2.4.5 C Code optimization
Intrinsics Inline Technology .
(1) Direct threshold C6000 Special inline functions corresponding to assembly instructions , No function call expenses .
(2) Use C Variable name ( It's not a register ), And C Environment compatible .
(3) Don't add C Programming workload .
(4) Code efficiency is the same as assembly .C Code :( Code efficiency is low )
y=a*b;
- Use Intrinsics Of C Code :
y = _mpy(a,b);
- Embedded assembly :( Easy to destroy C Environmental Science )
asm("MPY A0,A1,A2");
- Assembly code :( There's a lot of programming )
MPY A0,A1,A2 ;a,b,y
3. other
边栏推荐
- How to select several hard coded SQL rows- How to select several hardcoded SQL rows?
- 【计网】第三章 数据链路层(3)信道划分介质访问控制
- 【每周一坑】信息加密 +【解答】正整数分解质因数
- Unity writes a timer tool to start timing from the whole point. The format is: 00:00:00
- 案例 ①|主机安全建设:3个层级,11大能力的最佳实践
- 永磁同步电机转子位置估算专题 —— 基波模型与转子位置角
- Review questions of anatomy and physiology · VIII blood system
- Rhcsa Road
- 微信小程序常用集合
- Implementation of packaging video into MP4 format and storing it in TF Card
猜你喜欢
rt-thread i2c 使用教程
Quel genre de programmation les enfants apprennent - ils?
APS taps home appliance industry into new growth points
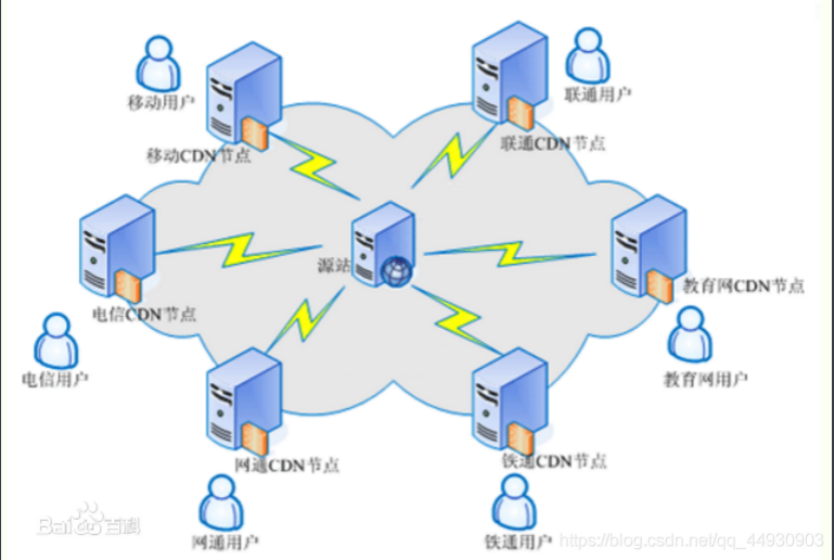
![[network planning] Chapter 3 data link layer (3) channel division medium access control](/img/df/dd84508dfa2449c31d72c808c50dc0.png)
[network planning] Chapter 3 data link layer (3) channel division medium access control
Common doubts about the introduction of APS by enterprises
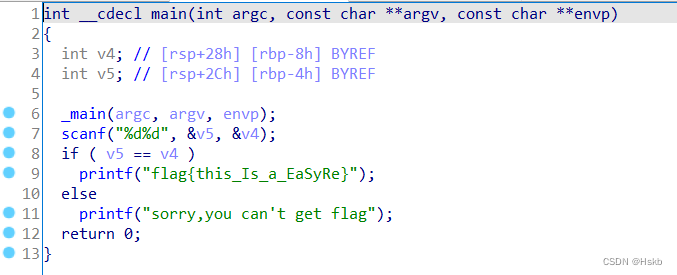
BUUCTF---Reverse---easyre
Tencent byte and other big companies interview real questions summary, Netease architects in-depth explanation of Android Development
01 basic introduction - concept nouns
Tencent T4 architect, Android interview Foundation
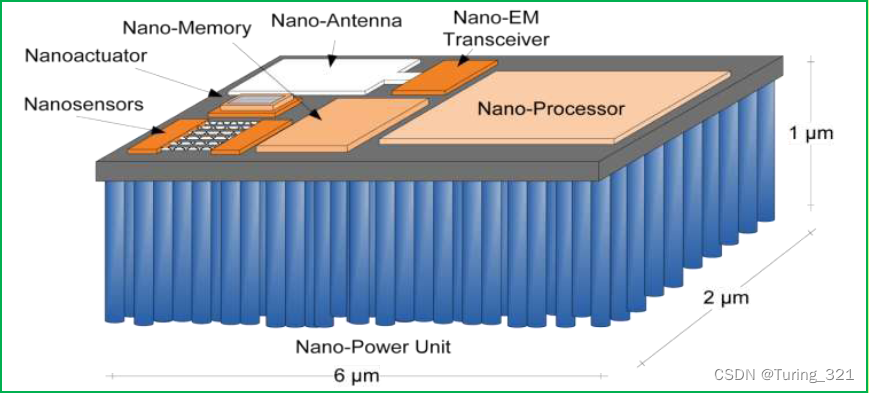
5. 無線體內納米網:十大“可行嗎?”問題
随机推荐
Special topic of rotor position estimation of permanent magnet synchronous motor -- fundamental wave model and rotor position angle
Groovy基础语法整理
Continuous test (CT) practical experience sharing
String length limit?
[network planning] Chapter 3 data link layer (3) channel division medium access control
【GET-4】
HMS Core 机器学习服务打造同传翻译新“声”态,AI让国际交流更顺畅
案例 ①|主机安全建设:3个层级,11大能力的最佳实践
Qinglong panel white screen one key repair
【DSP】【第二篇】了解C6678和创建工程
5. 無線體內納米網:十大“可行嗎?”問題
I've seen many tutorials, but I still can't write a program well. How can I break it?
Leetcode question 283 Move zero
[network planning] Chapter 3 data link layer (4) LAN, Ethernet, WLAN, VLAN
[weekly pit] positive integer factorization prime factor + [solution] calculate the sum of prime numbers within 100
SQL injection 2
PowerPivot - DAX (first time)
[DSP] [Part 2] understand c6678 and create project
Maximum likelihood estimation and cross entropy loss
Zoom with unity mouse wheel: zoom the camera closer or farther