当前位置:网站首页>Detailed explanation of knowledge map construction process steps
Detailed explanation of knowledge map construction process steps
2022-07-06 20:30:00 【Southern cities in late spring】
Overview of knowledge map construction process
1. knowledge
1.1 The main task of knowledge extraction
(1) Entity recognition and extraction
Mission : Identify seven types of text to be processed ( The person's name 、 Organization name 、 Place names 、 Time 、 date 、 Currency and percentage ) Named entity .
Two subtasks : Entity boundary identification and determination of entity type .
(2) Relationship extraction
Mission : Relationship extraction is to extract the semantic relationship between two or more entities from the text . It is one of the tasks in the field of information extraction .
(3) Attribute extraction
Mission : For a given entity, the attributes and attribute values of the entity are extracted from unstructured text to form structured data .
1.2 Entity extraction
Knowledge extraction includes three elements : Entity extraction ( Named entity recognition NER)、 Entity relation extraction (RE) and Attribute extraction . Among them, attribute extraction can use python Crawlers crawl Baidu Encyclopedia 、 Wikipedia and other websites , The operation is relatively simple , So named entity recognition (NER) And entity relationship extraction (RE) It is a very important part of knowledge extraction , Named entity recognition and relationship extraction are two independent tasks , The task of named entity recognition is to find entities with descriptive meaning in a sentence , Relationship extraction is to extract the relationship between two entities . Named entity recognition is the premise of relationship extraction , Relationship extraction is based on entity recognition .

1.2.1 Use CRF Complete named entity recognition
CRF(Conditional random field, Conditional random field ) It's a discriminant model (HMM It's a generative model ). It is the conditional probability distribution model of another set of output random variables given a set of input random variables , It is characterized by assuming that the output random variables form a Markov random field .
In general use BIO system : Label use “BIO” system , That is, the first word of the entity is B_, The remaining words are I_, Non entity words are uniformly marked as O. In most cases , The more complex the label system , The higher the accuracy .
Method : Use pycrfsuite and hanlp Completion is based on CRF Named entity recognition
1. Get corpus :nltk、 The People's Daily 、 Other publicly annotated corpus
2. The characteristic function : Defining characteristic functions , This is actually more like a template for defining characteristic functions , Because the real feature function will be generated according to this defined template , And generally, the number of characteristic functions generated is quite large , Then determine the weight corresponding to each characteristic function through training .
3. Training models : Then you can start creating Trainer Training , Turn each sentence of the corpus into a list of features and tags , And set it up Trainer Related parameters of , And add samples to Trainer Start training in . Finally, the model will be saved to model_path in .
4. forecast : establish Tagger And load the model , You can choose a sentence in the test set to label .
5. assessment : Finally, evaluate the overall effect of our model , Input all sentences in the test set into the trained model , Compare the predicted results with the tags corresponding to the sentences in the test set , Output various indicators .
1.2.2 be based on Bilstm+CRF Named entity recognition
BiLSTM It refers to two-way LSTM;CRF It refers to conditional random fields .
1. Data preprocessing : Word vector processing : According to dictionary and label dictionary , Turn text and labels into numbers respectively . The first line is text , The second line is the label .
2. model building : Two way LSTM Process the sequence , Splice the output results .
3. Model training and testing .
4. Model validation
1.2.3 Entity extraction based on keyword Technology
be based on TextRank Keyword extraction technology :
Algorithm principle : If a word appears after many words , Then it shows that this word is more important .
One TextRank A word followed by a word with high value , So the word TextRank The value will increase accordingly .
1.3 Entity relation extraction
There are semantic relationships between entities , When two entities appear in the same sentence , Context determines the semantic relationship between two entities .
A complete entity relationship includes two aspects : Relationship type and relationship parameters , The relationship type describes what the relationship is , Such as employment relationship 、 Generic relations, etc ; The parameters of the relationship are the entities in which the relationship occurs , Such as employees and companies in the employment relationship .
Entity relationship extraction can be regarded as a classification problem . Use with supervision ( Mark learning )、 Semi supervision ( Statistical analysis ) Or without supervision ( Clustering method ) And so on . Entity relationship extraction often focuses on the context within a sentence .
1.3.1 Open Chinese entity relation extraction based on dependency parsing
Hanlp participle HanLP It's a series of models and algorithms NLP tool kit , It's dominated by big search and fully open source , The goal is to popularize the application of natural language processing in the production environment .HanLP It has perfect functions 、 High performance 、 Clear architecture 、 The corpus is up to date 、 Customizable features .
Hanlp Features provided :
- Chinese word segmentation
- Part of speech tagging (pos)
- Named entity recognition (ner)
- Keywords extraction
- Automatic summarization
- Phrase extraction
- Pinyin conversion
- Simple and complex conversion
- dependency parsing
- word2vec
hanlp Two kinds of dependency parsing tools are provided , By default, the dependency parser based on neural network is adopted , The other is a dependency parser based on maximum entropy .
2 Knowledge storage
Knowledge map is a structured semantic knowledge base , Concepts used to describe the physical world in symbolic form and their relationships . The basic composition unit is 【 Entity -- Relationship -- Entity 】 Or is it 【 Entity -- attribute -- Property value 】 Wait for triples . Entities are linked by relationships , Form a network of knowledge structure .
2.1 Neo4j
Neo4j Is a high-performance ,NOSQL Graphic database , It stores structured data on the network instead of tables . It's an embedded 、 Disk based 、 With complete transaction characteristics Java Persistence engine , But it stores structured data on the network ( From a mathematical point of view, it's called graph ) Up instead of in the table .Neo4j It can also be seen as a high-performance graph engine , The engine has all the features of a mature database . Programmers work in an object-oriented 、 Flexible network structure, not strict 、 In a static table —— But they can enjoy full transactional features 、 All the benefits of an enterprise class database .
Neo4j It is an old-fashioned graph data representation . It's powerful , Good performance, too , A single node server can host hundreds of millions of nodes and relationships , Distributed cluster deployment can also be carried out when the performance of a single node is not enough .
Neo4j Have your own back-end storage , No need to rely on other database storage . Neo4j The pointer of each edge is stored in each node , Therefore, the time efficiency is quite high .
3 Knowledge processing
3.1 summary
The concept of knowledge processing :
Information extraction / After knowledge fusion “ The facts ” Carry out knowledge reasoning to expand and show knowledge 、 Get new knowledge .
The value of knowledge processing :
Through information extraction , We can extract entities from the original corpus 、 Knowledge elements such as relationship and attribute . And then through knowledge fusion , It can eliminate the ambiguity between entity referent and entity object , Get a basic set of facts to express . However , Fact itself is not equal to knowledge , To finally get structured 、 Network knowledge system , It also needs to go through the process of knowledge processing . Knowledge processing mainly includes three aspects : Ontology construction 、 Knowledge reasoning and quality assessment .
3.2 Ontology construction
What is noumenon ?
Definition : A concept derived from philosophy , Knowledge engineering scholars borrowed this concept , It is used to acquire domain knowledge when developing knowledge systems . Ontology is a collection of terms used to describe a domain , Its organizational structure is hierarchical . In short , Ontology is a data set used to describe a domain , It is the skeleton of knowledge base .
effect : obtain 、 Describe and represent knowledge in related fields , Provide a common understanding of knowledge in this field , Identify commonly recognized terms in the field , Provide domain specific concept definitions and relationships between concepts , Provide the activities in this field and the main theories and basic principles in this field , Achieve the effect of human-computer communication .
3.2.1 The construction method of ontology
3.2.1.1 IDEF-5 Method
IDEF The concept of is in 70 Proposed in the S , It is developed on the basis of structural analysis method . stay 1981 Published by the US Air Force in ICAM(integrated computer aided manufacturing) For the first time in the project, it is called “IDEF” Methods .IDEF yes ICAM Definition method Abbreviation , So far, it has developed into a series .IDEF5 yes KBSI(Knowledge Based Systems Inc.) Developed a set of methods for describing and acquiring enterprise ontology .IDEF5 Through the use of graphic language and detailed description language , Get the concept of objective existence 、 Properties and relationships , And formalize them into noumenon .
IDEF5 Create ontology 5 The first major step is :① Define the topic 、 Organize the team ;② collecting data ;③ Analyze the data ;④ Ontology preliminary development ;⑤ Ontology optimization and verification .
3.2.1.2 Skeletal Methodolody Skeleton method (Uschold Method )
Mike Uschold & Micheal Gruninger Skeleton method (Skeletal Methodology), also called Enterprise Law , Specifically used to create enterprise ontology (Enterprise ontology, It is the ontology of enterprise modeling process ).
3.2.1.3 Methontology Method
Mariano Fernandez & GOMEZ-PEREZ Waiting Methontology The method is from Spain Madrid Polytechnic University AI Proposed by the laboratory . This method is a combination of skeleton method and GOMEZ-PEREZ After the method , Proposed a more general ontology construction method . This ontology development method is closer to the software engineering development method . It distinguishes ontology development process and ontology life cycle , And use different technologies to support .
Methontology Law , Dedicated to creating chemical ontologies ( About the ontology of the periodic table of chemical elements ), This method has been adopted by the Artificial Intelligence Library of the University of Madrid Polytechnic . Its process includes :
(1) Management stage : The system planning at this stage includes the progress of the task 、 Resources needed 、 How to guarantee the quality .
(2) The development phase : It is divided into specifications 、 conceptualization 、 formalization 、 Implement and maintain five steps .
(3) Maintenance phase : Including knowledge acquisition 、 System integration 、 evaluation 、 documentation 、 Five steps of configuration management .
3.2.1.4 Seven steps
The seven step method developed by Stanford University School of Medicine , It is mainly used for the construction of domain ontology . The seven steps are : ① Determine the domain and scope of ontology ;② Examine the possibility of reusing existing ontologies ;③ List the important terms in ontology ;④ Define classes and hierarchy of classes ( There are some feasible ways to improve the hierarchy : From the top down 、 From low to high and comprehensive methods [7]);⑤ Define the properties of the class ;⑥ Defining the facets of an attribute ;⑦ Create examples
3.3 Knowledge reasoning
3.3.1 What is knowledge reasoning
The so-called reasoning is to obtain new knowledge or conclusions through various methods . Knowledge reasoning mainly uses the existing facts or corpus of the existing knowledge map , Use algorithmic tools , Infer the relationship between entities , Automatically generate new knowledge , Add missing facts , Improve the knowledge map .
3.3.2 Methods of knowledge reasoning
(1) Reasoning based on symbolic logic —— Ontological reasoning
(2) Based on table operations (Tableaux) And improved ⽅ Law : FaCT++、 Racer、 Pellet Hermit etc.
(3) be based on Datalog The conversion ⽅ Law as KAON、 RDFox etc.
(4) Based on production ⽣ The algorithm of the formula ( Such as rete): Jena 、 Sesame、 OWLIM etc.
(5) Reasoning based on graph structure and statistical rule mining
(6) Learning based on path ordering ⽅ Law (PRA, Path ranking Algorithm)
(7) Mining Based on association rules ⽅ Law (AMIE)
(8) Based on knowledge map to represent the relation reasoning of learning
Express entities and relationships as vectors
The existence of triples can be predicted by calculating between vectors instead of traversing and searching , Because the representation of vector already contains the original semantic information of entity , The calculation contains ⼀ Definite reasoning can ⼒.
May be ⽤ Link prediction , Multiple query based on path
(9) Method based on probability logic
Probability logic learning is sometimes called Relational Machine Learning (RML), Focus on the uncertainty and complexity of the relationship .
Usually use Bayesian networks or Markov networks
4 Knowledge fusion
4.1 Overview of knowledge fusion
Knowledge fusion ( Also known as body alignment 、 Ontology matching 、 Entity aligned ), That is to merge two knowledge maps ( noumenon ), The basic problem is to study how to integrate the description information about the same entity or concept from multiple sources . What needs to be confirmed is :
Equivalent instance : Entity matching , The left and right people are the same
Equivalence class / Subclass : Rock singers are a subclass of singers
Equivalent attribute / Sub properties : Being born on the date of birth is an equivalent attribute
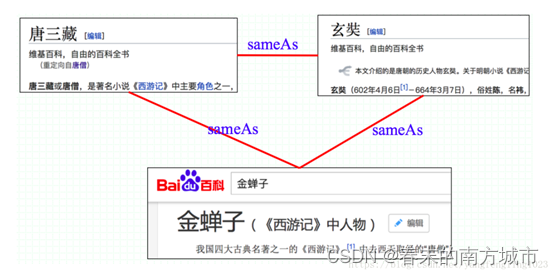

The main challenge :
The challenge of data quality : Such as vague naming , Data input error 、 Data loss 、 Inconsistent data format 、 Abbreviations, etc .
The challenge of data scale : Large amount of data ( Parallel computing )、 Variety of data 、 No longer match just by name 、 Multiple relationships 、 More links, etc .
Main task :
The construction of knowledge map often needs to integrate data from many different sources ( structured 、 Semi structured 、 Unstructured ) It is necessary to fuse descriptive information about the same entity or concept from multiple sources .
Unity of substance
Entity disambiguation Entity link
Knowledge merge
Entity link : Entity objects extracted from text , The operation of linking it to the corresponding correct entity object in the knowledge base . The basic idea is to first refer to items according to a given entity , Select a set of candidate entity objects from the knowledge base , Then the reference item is linked to the correct entity object by similarity calculation .
technological process :
1. Entity references are extracted from the text ;
2. Entity unification and entity disambiguation , Determine whether the entity with the same name in the knowledge base represents different meanings and whether there are other named entities with the same meaning in the knowledge base ;
3. After confirming the corresponding correct entity object in the knowledge base , Connect the entity reference necklace to the corresponding entity in the knowledge base .
4.2 Unity of substance ( Co refers to digestion )
Multi source heterogeneous data is in the process of integration , There is usually a phenomenon that a real world entity corresponds to multiple representations , The reason for this phenomenon may be : Spelling mistakes 、 Different naming rules 、 Name variants 、 Abbreviations, etc . This phenomenon will lead to a large amount of redundant data in the integrated data 、 Inconsistent data and other issues , Thus, the quality of integrated data is reduced , Then it affects the results of analysis and mining based on the integrated data . The problem of distinguishing whether multiple entity representations correspond to the same entity is entity unification .
Such as the phenomenon of duplicate names , Nanjing University of Aeronautics and Astronautics ( China Southern Airlines )
Entity co refers to resolution solutions :
4.2.1 Based on the method of mixing the two

4.2.2 Pattern matching
Pattern matching is mainly to find the mapping relationship between attributes in different associated data sources , It mainly solves the conflict between predicates in triples ; Another explanation : Solve the problem that different associated data sources adopt different identifiers for the same attribute , So as to realize the integration of heterogeneous data sources

4.2.3 Object conflict resolution
Object conflict resolution is to solve the problem of object inconsistency in multi-source related data .
4.3 Entity disambiguation
The essence of entity disambiguation is that a word has many possible meanings , That is, the meanings expressed in different contexts are different . Such as : My mobile phone is apple . I like apples .
4.3.1 Dictionary based word sense disambiguation
The early representative work of dictionary based word sense disambiguation method is Lesk On 1986 The job of . Given a word to be resolved and its context , The idea of this work is to calculate the coverage between the definition of each word meaning and the context in the semantic dictionary , Choose the word with the largest coverage as the correct word meaning of the word to be resolved in its context . However, the definition of word meaning in dictionaries is usually concise , This results in a coverage of 0, The disambiguation performance is not high .
4.3.2 Supervised word sense disambiguation
Supervised disambiguation method uses word meaning tagging corpus to establish disambiguation model , The research focuses on the representation of features . Common contextual features can be summarized into three types :
(1) Lexical features usually refer to the words and their parts of speech appearing in the upper and lower windows of the words to be resolved ;
(2) Syntactic features use the syntactic relationship characteristics of the word to be resolved in the context , Ru Dong - Guest Relations 、 With master or not / The object 、 Lord / Object chunk type 、 Lord / Object headword, etc ;
(3) Semantic features add semantic information on the basis of syntactic relations , As the Lord / The semantic category of the object headword , It can even be semantic role annotation class information .
4.3.3 Unsupervised and semi supervised word sense disambiguation
Although supervised disambiguation methods can achieve better disambiguation performance , But it needs a lot of manual tagging corpus , laborious . In order to overcome the need for large-scale corpus , Semi supervised or unsupervised methods require only a small amount or no manual annotation of the corpus . As a general rule , Although semi supervised or unsupervised methods do not require a lot of manual annotation data , But it depends on a large-scale unmarked corpus , And the result of syntactic analysis on the corpus .
4.4 Knowledge merge
Entity link refers to the data extracted by information extraction from semi-structured data and unstructured data .
More convenient data sources : Structured data , Such as external knowledge base and relational database . For the processing of this part of structured data , Is the content of knowledge merging . Generally speaking, there are two main types of knowledge consolidation : Merge external knowledge base and relational database .
4.4.1 Merge external knowledge base
(1) Data layer integration , Including references to entities 、 attribute 、 Relationship and category etc , The main problem is how to avoid conflicts between instances and relationships , Cause unnecessary redundancy .
(2) Integration of the pattern layer , Integrate the new ontology into the existing ontology library , There are generally four steps : Acquire knowledge -> Concept matching -> Entity matching -> Knowledge assessment .
4.4.2 Merge relational databases
In the process of building knowledge map , An important source of high-quality knowledge is the enterprise's or organization's own relational database . In order to integrate these structured historical data into the knowledge map , You can use a resource description framework (RDF) As a data model . Industry and academia call this data transformation process figuratively RDB2RDF, Its essence is to change the data of relational database into RDF Triple data for .( Tools :D2RQ).
4.5 Tool Research
1. Use jieba Complete entity unification
2. Use tf-idf Complete entity disambiguation
3. Use Falcon-AO Complete body alignment , yes RDF and OWL Expressed Web A practical choice for ontology matching .
4.Limes,Dedupe, Silk Realize entity matching
边栏推荐
- Special topic of rotor position estimation of permanent magnet synchronous motor -- fundamental wave model and rotor position angle
- 2022 refrigeration and air conditioning equipment installation and repair examination contents and new version of refrigeration and air conditioning equipment installation and repair examination quest
- Boder radius has four values, and boder radius exceeds four values
- JMeter server resource indicator monitoring (CPU, memory, etc.)
- 使用ssh连接被拒
- 8086 instruction code summary (table)
- 2022 Guangdong Provincial Safety Officer C certificate third batch (full-time safety production management personnel) simulation examination and Guangdong Provincial Safety Officer C certificate third
- [weekly pit] output triangle
- 【每周一坑】信息加密 +【解答】正整数分解质因数
- [weekly pit] information encryption + [answer] positive integer factorization prime factor
猜你喜欢
Tencent Android development interview, basic knowledge of Android Development
【计网】第三章 数据链路层(4)局域网、以太网、无线局域网、VLAN
02 基础入门-数据包拓展
Common doubts about the introduction of APS by enterprises

Deep learning classification network -- zfnet
I've seen many tutorials, but I still can't write a program well. How can I break it?
Continuous test (CT) practical experience sharing

“罚点球”小游戏
【每周一坑】计算100以内质数之和 +【解答】输出三角形
![[diy] how to make a personalized radio](/img/fc/a371322258131d1dc617ce18490baf.jpg)
[diy] how to make a personalized radio
随机推荐
Design your security architecture OKR
小孩子学什么编程?
In line elements are transformed into block level elements, and display transformation and implicit transformation
Crawler (14) - scrape redis distributed crawler (1) | detailed explanation
【计网】第三章 数据链路层(3)信道划分介质访问控制
【Yann LeCun点赞B站UP主使用Minecraft制作的红石神经网络】
js获取浏览器系统语言
Tencent byte Alibaba Xiaomi jd.com offer got a soft hand, and the teacher said it was great
How does kubernetes support stateful applications through statefulset? (07)
(work record) March 11, 2020 to March 15, 2021
电子游戏的核心原理
Tencent T2 Daniel explained in person and doubled his job hopping salary
Function optimization and arrow function of ES6
[DSP] [Part 2] understand c6678 and create project
永磁同步电机转子位置估算专题 —— 基波模型与转子位置角
[DSP] [Part 1] start DSP learning
Solution to the 38th weekly match of acwing
Use of OLED screen
5. Wireless in vivo nano network: top ten "feasible?" problem
Quel genre de programmation les enfants apprennent - ils?