Caching is a data storage technology for faster data retrieval . In a sense , It's better than storing from its master ( Such as a database ) Get data faster . To achieve this , We usually cache data that is frequently requested or calculated . Now? , Let's take a closer look at the different caching strategies that may need to be considered . please remember , The requirements of each application are different , You should choose a caching strategy based on this .
Cache-Aside Strategy( Cache side cache policy 、 Bypass cache Strategy ) Is one of the most widely used caching strategies . The main idea behind this strategy is , Only when an application requests an object , To store objects in the cache .
Cache-Aside Strategy
Cache-Aside( Cache side cache policy 、 Bypass cache ) The basic process is as follows :
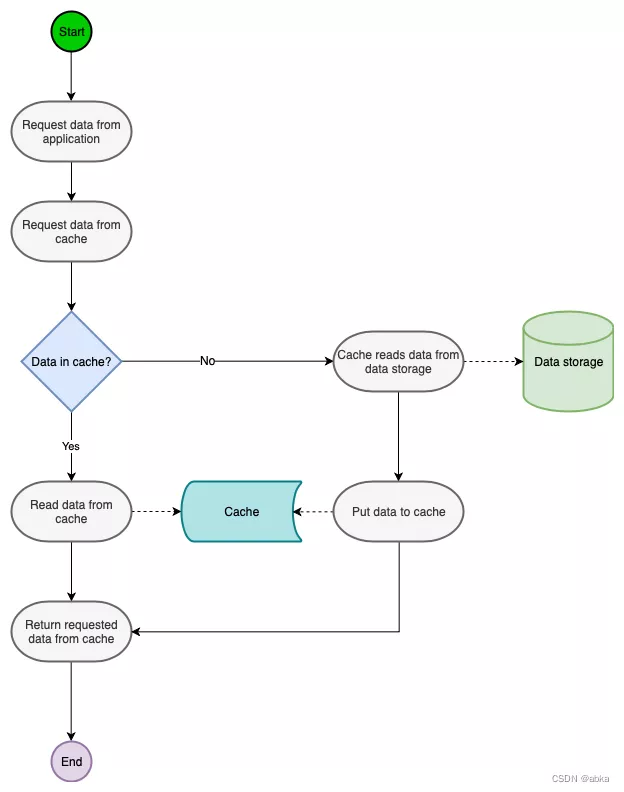
The application receives a request to get some data .
The application checks whether there is data in the cache :
If it is ( Also known as cache hits ), Get... From the cache .
If not ( Cache miss ), Then call the data store ( Like databases ) To retrieve data and store it in the cache .
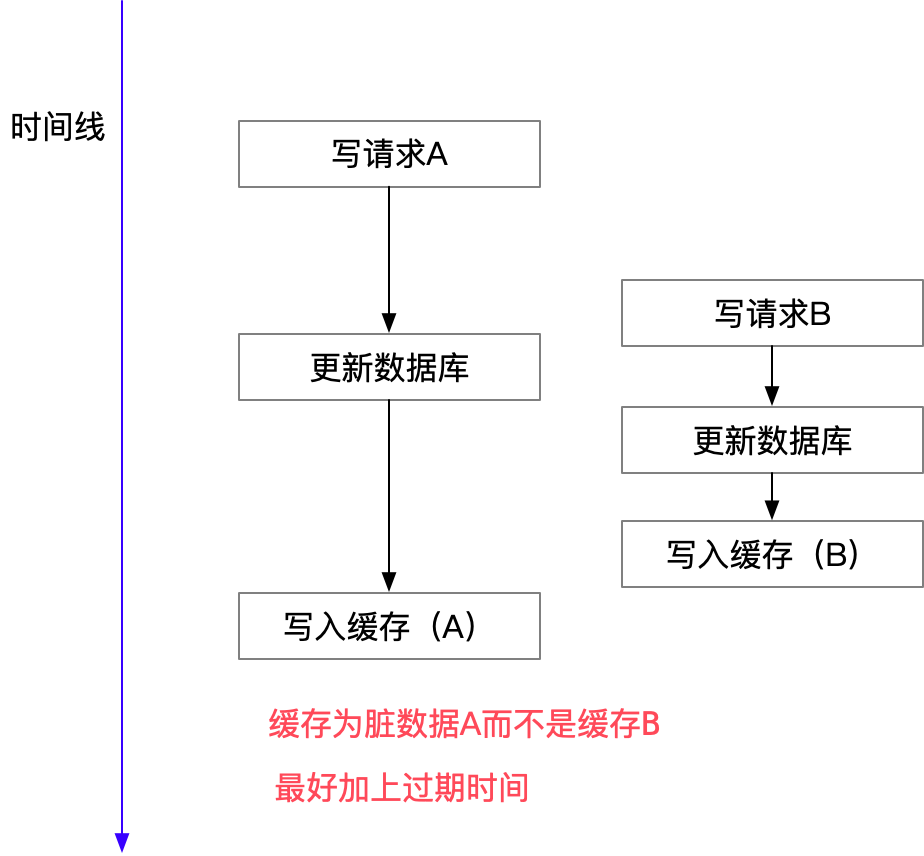
Two concurrent write operations result in dirty data
Just imagine what if two concurrent updates of the same data element occur? You might have different values of the same data item in DB and in memcached. Which is bad. There is a certain number of ways to avoid or to decrease probability of this. Here is the couple of them:
1. A single transaction coordinator
2. Many transaction coordinators, with an elected master via Paxos or Raft consensus algorithm
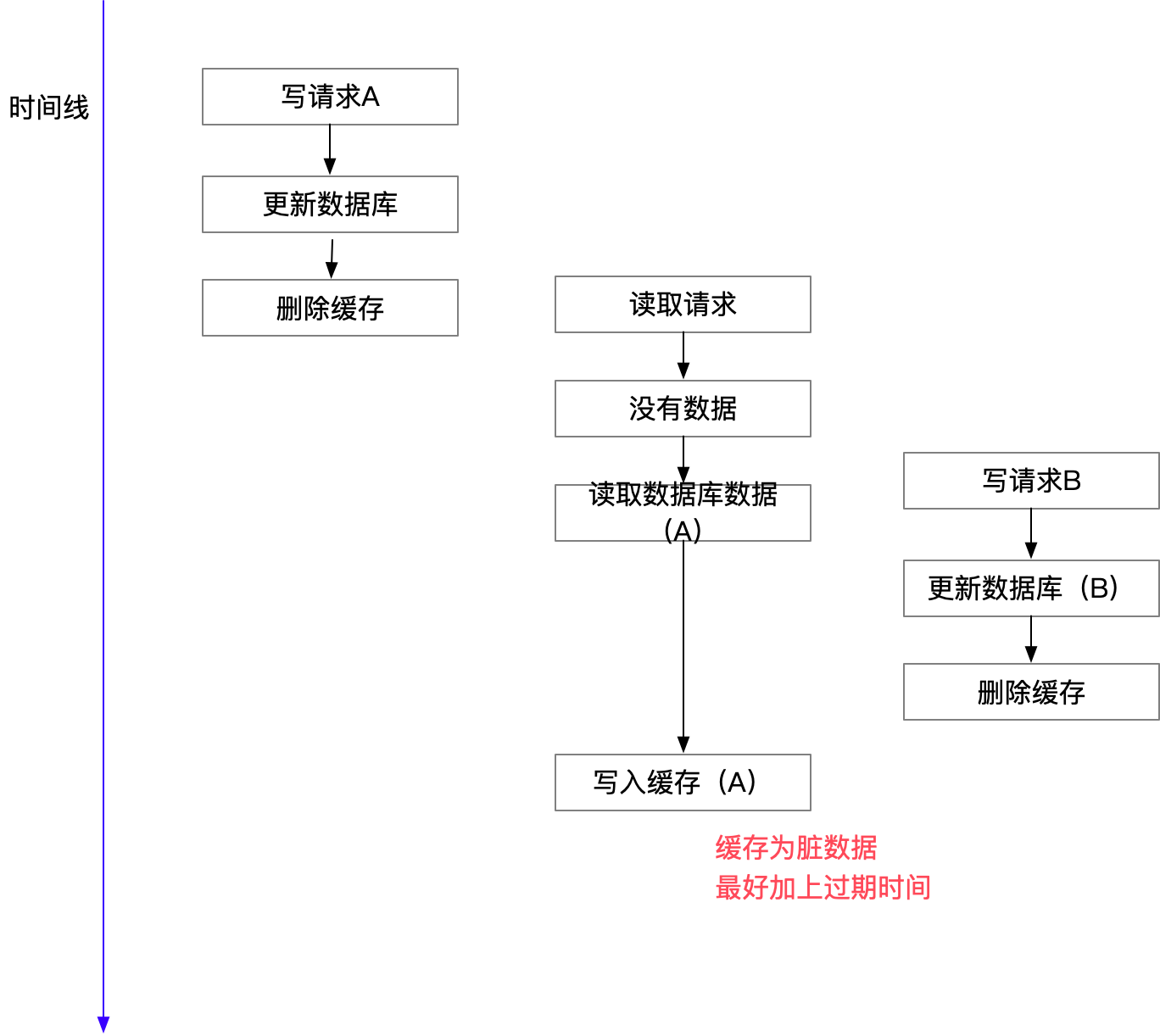
3. Deletion of elements from memcached on DB updates
I assume that they chose the way #3 because "a single" means a single point of failure, and Paxos/Raft is not easy to implement plus it sacrifices availability for the benefit of consistency.
-- When updating the database concurrently : Expired data may be written to the cache , Cause the business to read dirty data . So deleting it directly is the most reliable .
Why does Facebook use delete to remove the key-value pair in Cache instead of updating the Cache?
https://blog.csdn.net/qfzhangwei/article/details/118379546
that , Is it right? Cache Aside There won't be any concurrency problem ? No, it isn't , such as , One is read operation , But the cache was not hit , Then go to the database and get the data , Here comes a write operation , After writing the database , Invalidate the cache , then , The previous read operation put the old data in , therefore , Can cause dirty data .
Cache-Aside Strategy Possible problems
but , This case In theory, there will be , however , In fact, the probability of occurrence may be very low , Because this condition requires cache invalidation to occur while reading the cache , And there is a write operation concurrently . In fact, database writes are much slower than reads , And a lock table , The read operation must enter the database operation before the write operation , And update the cache later than the write operation , The probability that all of these things are true is pretty small .( But the common sense in computer science is that small probability events will happen , Because the computer will repeat many times )
therefore , This is the same. Quora The answer on is , Either through 2PC or Paxos Agreement guarantees consistency , Or desperately reduce the probability of dirty data in concurrency , and Facebook Using this method of reducing probability , because 2PC Too slow , and Paxos Too complicated . Of course , It's better to set the expiration time for the cache .
Use cases , pros and cons
Cache side caching is usually generic , Best fit Read heavy workloads .Memcached and Redis Widely used . Use the system on the cache side Resilient to cache failures . If the cache cluster fails , The system can still directly access the database for operation .( although , If the cache drops during peak load , It doesn't help much . Response times can get bad , In the worst case , The database may stop working .)
Another advantage is that the data model in the cache can be different from the data model in the database . for example , The response generated as the result of multiple queries can be specific to a request id For storage .
Use cache-aside when , The most common write strategy is to write data directly to the database . When this happens , The cache may be inconsistent with the database . To solve this problem , Developers often use time to live (TTL) And continue to provide old data , until TTL Be overdue . If you have to keep the data fresh , Developers either Invalidate cache entries , Or use the appropriate write strategy , We will discuss later .
Read-Through Caching Strategy ( Read through cache strategy , Read through cache policy )
Read-Through Caching Strategy ( Read through cache strategy , Read through cache policy ) It's something like Cache-Aside Strategy( Bypass cache Strategy ) The cache method of . The difference is that the application does not coordinate where to read data ( Cache or data storage ). contrary , It always reads data through the cache . under these circumstances , Cache is the one that decides where to get data . When we compare it with the cache side strategy , This is a big advantage , Because it makes the application code cleaner
Read-Through Caching Strategy Read Through Caching
although read-through and cache-aside Very similar , But there are at least two key differences :
On the cache side , The application is responsible for fetching data from the database and populating the cache . In reading through , This logic is usually supported by libraries or independent cache providers .
And cache-aside Different ,read-through cache The data model in cannot be different from that of the database .
When the same data is requested more than once , Read through caching is best Read heavy workloads . for example , A news story . The disadvantage is when data is first requested , Always causes cache misses , And incur additional penalties for loading data into the cache . Developers manually issue queries to “ heating ” or “ preheating ” Caching to deal with this . It's like cache-aside equally , The data between the cache and the database may also be inconsistent , The solution lies in writing strategies , We're going to see .
Write-Through Caching Strategy( Write through caching strategy , Write through cache policy )
In this strategy , All writes are cached . Every time you write , Caching also stores data in the underlying data store . Both operations occur in one transaction . therefore , Only two writes succeeded , Everything will succeed . It does cause some extra delay when writing , But at least it has greatly improved the problem of data inconsistency , Because the data in the cache and the data storage are the same . But please note what data to write through the cache , So as not to eventually lead to data loads that are actually never or rarely read in the cache . This may lead to unnecessary memory usage . What's worse is , Some useful data may be cleared from the cache by less useful data .
On the positive side , Because the application only talks to the cache , So its code is cleaner and simpler . If you need to copy logic in multiple places in your code , This is especially true .
When using Write-Through Caching Strategy( Write through caching strategy , Write through cache policy ) when , You can also read from the cache , Because the read operation is fast .
Write-Through Caching Strategy( Write through cache policy ) Best for the following applications :
You need to read the same data often .
Don't tolerate caching and data storage (“ Old data ”) Data loss and inconsistency between .
have access to Write-Through Caching Strategy( Write through caching strategy , Write through cache policy ) A potential example of a system of is the banking system .
Use cases , pros and cons
In terms of itself , Write through caching doesn't seem to work much , actually , They introduce additional write latency , Because the data is written to the cache first , Then write it into the main database . But when paired with read through cache , We can get all the benefits of reading through , And we can also obtain data consistency guarantee , Avoid using cache invalidation Technology .
DynamoDB Accelerator (DAX) Is read / A good example of write caching . It is associated with DynamoDB Inline with your application . Can pass DAX Yes DynamoDB Read and write .( sidenote : If you plan to use DAX, Please make sure you are familiar with Its data consistency model And how it works with DynamoDB Interaction .)
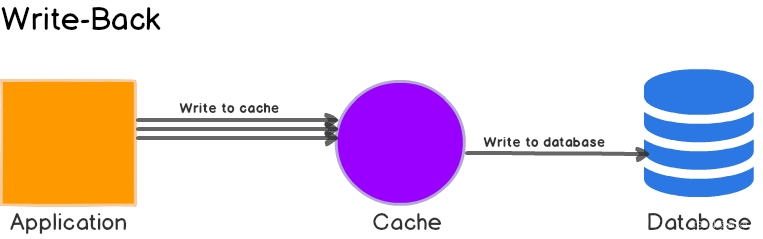
Write-Behind Caching Strategy( Post write cache policy )
Write-behind The caching strategy is similar to write-through cache , The application communicates only with the cache , And there is only one appearance to write data . The difference from the write through mode is that the data is first written to the cache . then , After a while ( Or through other triggers ), Data is also written to the underlying data source . Now this is a key part of this strategy —— These operations occur asynchronously .
Data source writing can be done in many ways . One option is “ collect ” All writes , And then at some point in time ( for example , When the database load is low ) Batch write to the data source . Another way is to merge writes into smaller batches . Cache collection, such as five write operations , Then batch write the data source .
Asynchronous writes to the cache and data source help greatly reduce latency . besides , It also helps unload data sources . But on the less positive side , It increases the data inconsistency between cache and data source . This leads to an additional problem . If someone gets data directly from the data source when the data has not been written to the data source , It may result in getting expired data .
In order to solve the problem of data inconsistency , The system can write-behind Strategy and read-through Combination of strategies . such , Always read the latest data from the cache .
When we compare it with the write through strategy , It is more suitable for systems with larger input , These systems can tolerate some data inconsistencies .
Write Behind Also called Write Back( Write back to ). Some understanding Linux Schoolmate pairs of operating system kernel write back Should be very familiar , Isn't that what Linux File system Page Cache The algorithm of ? Yes , You see, the basic things are all interlinked . therefore , Foundation is very important , It's not the first time I've said that foundation matters .
Write Back tricks , In a word, it is , When updating data , Update cache only , Do not update database , And our cache will asynchronously batch update the database . The advantage of this design is to make the data I/O Fast operation ( Because of direct memory operation ), Because asynchronous ,write backg You can also merge multiple operations on the same data , So the performance improvement is considerable .
however , The problem with it is , Data is not strongly consistent , And it could be lost ( We know Unix/Linux Abnormal shutdown will cause data loss , That's why ). In software design , It's basically impossible for us to make a flawless design , Like time for space in algorithm design , Space for time , occasionally , Strong consistency and high performance , There is a conflict between high availability and high sex . Software design is always a choice Trade-Off.
in addition ,Write Back Complex implementation logic , Because he needs track What data has been updated , It needs to be brushed on the persistence layer . Operating system write back Only if cache When failure is needed , Will be really lasting , such as , Not enough memory , Or the process exits, etc , This is also called lazy write.
stay wikipedia There's a picture on it write back Flow chart of , The basic logic is as follows :
Use cases , pros and cons
Write back caching improves write performance , Apply to Write heavy The workload . When used in conjunction with read through , It is suitable for mixed workloads , The recently updated and accessed data is always available in the cache .
It is resilient to database failures , And some database downtime can be tolerated . If batch or merge is supported , It can reduce the overall write to the database , Thus reducing the load and cost reduction , If the database provider charges by the requested quantity , for example DynamoDB. please remember ,DAX It's written directly , So if your application writes heavily , You won't see any cost reductions .( When I first heard of DAX when , This is my first question - DynamoDB It can be very expensive , But damn Amazon .)
Some developers will Redis For caching and write back , To better absorb the peak during peak load . The main disadvantage is if the cache fails , Data may be lost permanently .
Most relational database storage engines ( namely InnoDB) Write back caching is enabled internally by default . Queries are first written to memory and finally flushed to disk .
Write around
Data is written directly to the database , Only read data can enter the cache .
Use cases , pros and cons
write-around It can be done with read-through Use a combination of , And provide good performance when the data is written once and the reading frequency is low or never read . for example , Real time logs or chat messages . Again , This mode can also be used with cache-aside( Cache side ) Use a combination of .
Write-Around In fact, it doesn't use caching itself , It's written directly to the database .
Cache-Aside Why cooperate with Write-Around But not with Write-Through Use it together ?
because Write-Through The cache will be updated first , If there is another thread reading the old data in the database, the new data in the cache will be covered , It will cause data errors , While using Write-Around That's not going to happen .
Write-Around In some situations with Read-Through It's also useful to use with , For some cases that only need to be written once and read many times , For example, writing and obtaining chat information .
Conclusion
In this post , We introduced five different caching strategies :cache-aside, read-trough, Write-Around、write-through and write-behind. Use a , You need to consider the characteristics of the system . Besides , In actual use scenarios , You are most likely to combine strategies .
What if I choose the wrong one ? One that does not match your goal or access pattern ? You may introduce additional delays , Or at least not All the benefits . for example , If you should actually use write-around/read-through( The written data access frequency is low ) Time selection write-through/read-through , Then there will be useless garbage in your cache . so to speak , If the cache is large enough , It may be OK . But in many real-world high-throughput systems , When memory is never large enough and server cost becomes a problem , The right strategy is important .
Consistency issues
Write through client / Network failure
The following figure shows the write through mode .T1 Try to update X, meanwhile T2 Read X. If T1 In the 2 How to deal with step crash or network interruption ?T2 Will always be in the first 3 Step to see old data , Until the cache expires . This is consistent with the sequential consistency model , It depends on your actual use case , If the cache expiration time is short enough , Delay may not be a big problem .
under these circumstances , The real problem is cache eviction . If cache eviction is based on LRU And the data is read frequently , cache - The database inconsistency time window will be large , Even infinite , It means T2 Never see new values , This does not satisfy any consistency model between client views and can cause serious problems in your application . To avoid this situation , Please force a fixed expiration time according to the timestamp when the key is cached for the first time ( for example ,Caffeine Medium expireAfterWrite).
Read through concurrently
Suppose we don't use distributed locks to coordinate T1 and T2,X It doesn't exist in the cache yet . The image below shows T1 and T2 All encountered cache misses . In the 3 After step , If in T1 Occur in the JVM full GC Things like that , The update of the database will be delayed . meanwhile ,T2 Update the cache and put X Write the latest value 2, Final T1 from GC And restore it to its old value 1 Write cache . If T2 Read again X, It will see an old value and may be confused . Does not meet the order consistency and linear consistency .
Using distributed locks can solve this problem , But it's too expensive . A simple solution is through CAS prevent T1 Steps in 7 Write obsolete data . Most modern caching systems support CAS write in ( for example Redis Lua), We can use with version CAS Write to ensure such a writing order ( stay Redis Use in Lua Realization ):
# Arguments
#KEYS[1]: the key
#ARGV[1]: old version
#ARGV[2]: new version
#ARGV[3]: new value
#ARGV[4]: TTL in seconds
# You can test in redis-cli:
eval "local v = redis.call('GET', KEYS[1]); if (v) then local version, value = v:match(\"([^:]+):([^:]+)\"); if (version ~= ARGV[1]) then return 1; end end redis.call('SET', KEYS[1], ARGV[2] .. ':' .. ARGV[3], 'EX', tonumber(ARGV[4])); return 0;" 1 key1 0 1 value1 1000
Use CAS, In the 7 Step T1 Will fail , also T1 You can query the cache again to get the latest X.
A very special case is , If T1 Pause for a long time , Long enough to be in the first 6 Step written X The value of is out of date , under these circumstances ,T1 You can still write stale data to the cache , But this rarely happens , because T1 It has been suspended for a long time , Maybe 15 minute , This is unlikely to happen . therefore , This is only a theoretical possibility . If we want to solve this problem , Consider using a timestamp when writing to the cache , If it's too old , The cache system can reject writes . for example , Expiration is set to 5 minute , If the timestamp written exceeds 5 minute , Reject and report an error , So that the client can realize this and try again . however , Any timestamp based solution is vulnerable to clock drift , You must do the right NTP Set up .
Write through concurrency
Suppose we don't use distributed locks to coordinate T1 and T2,T1 and T2 Try to update X.
In the 2 After step , Ideally ,T1 The cache should be updated to 1, But if T1 Something similar happens in JVM Completely GC The situation of , meanwhile T2 Update the cache and put X Write the latest value 2, that T1 Its obsolete value 1 write in X cache . This is similar to the concurrency problem mentioned earlier , But this is more likely to happen , It does not require two concurrent cache misses , This is a rare case .
To solve such problems without distributed locks , You can use write-invalidate Patterns and read-through Pattern . In the 4/5 Step , We just invalidate the cache key , The next read should recreate the cached data . such ,T1/T2 In the next reading, it will X As 2, If the other T3 In the 4 And the first step 5 Read between steps X, It will see cache misses and try to load the cache from the database , And will X As 2 . Now we have reached the linearization consistency level . The disadvantages are obvious , In the scene of writing before reading , You will see a low hit rate .
You can also use CAS Write to ensure order , As we demonstrated in the previous section . Retrieve the version every time you update the database ( Can pass Oracle Sequence , stay MySQL Medium analog sequence , Distributed incremental key , Lock rows to retrieve results ), Then update the cache only when the version of the incoming request is higher than the version in the cache to prevent step 5 happen . Unless T1 Pause for a long time and X Be overdue ( This is a rare case ), Otherwise, it should work in most cases . This solution is a little complicated , Use it only when you really need it .
Concurrency in write invalidation
To solve the direct writing problem , We can use write-invalidate Pattern . If we were write-through In the sequence diagram of “update X to ...” Change it to “invalidate cache”, It looks like this :
Then any subsequent reads will see cache misses and refill the cache with the latest values . however , This only solves some data competition scenarios between two write clients , It does not solve the data competition between the read client and the write client without locks , It's just the ultimate consistency of best effort , Not sequential consistency . I will explain the reason in the next section . Before that , Let's see Facebook How to pass the lock ( lease ) To solve this problem .
Facebook stay 2013 Published a paper in , Explained Write-Invalidate How patterns relate to “lease” Used together ,“lease” It's actually a lock . come from Facebook 3.2.1 Of Scaling Memcache .
Intuitively speaking ,memcached Instances provide leases to clients , In order to set the data back into the cache when the client encounters a cache miss . The lease is bound to a specific key originally requested by the client 64 Bit token . The client provides the rental token when setting the value in the cache . Use lease token ,memcached You can verify and determine whether data should be stored , Thus arbitrate concurrent writes . If memcached The rental token is invalid due to the receipt of a delete request for the item , Then the verification may fail . The lease is similar to load-link/storeconditional The way of operation prevents stale sets [20].
The paper does not explain how to cancel the lease when an error occurs , What if the lessee collapses and fails to return the lease ? It is most likely to use a timeout solution to break the lease in case of errors . But it's clear , This timeout will increase the delay in negative situations . I believe in version control without locking CAS Is a better solution than him . Now let's see why it's difficult to achieve sequence consistency without locks , When two clients read and write simultaneously through write invalidation and read through .
It has the concurrency of invalid writing and read through
In the last section , We talked about write-invalidate How to solve the problem caused by write-through The problems caused . however write-invalidate With the read-through There are also problems when used together , This is a very common pattern used in many systems . Suppose we don't use distributed locks to coordinate T1 and T2,T1 Try to read X,T2 Try to update X.
If T1 Overloaded and slow for some reason , You can postpone the 5 Step and write the obsolete value to the cache .
CAS The write solution is not applicable to write-invalidate Pattern , Because once in the first 4 Step deletes the cached key , You have nothing to do with CAS For comparison .
Some people use similar write-deferred-invalidate Of Solution , That is, asynchronous scheduling 500ms Failure after , And in the first place 3 Return immediately after step . The idea is that we hope we can predict T1 The degree of delay , And in the first place 5 Fail after step .
When you have a read-only slave database cluster , This solution also helps hide the database master / From delay . If T1 Update master database ,T2 Read from the database instance , Due to replication delay ,T2 You won't see T1 The latest changes made , therefore T2 Can fill stale cache , Fortunately, the stale cache will be in 500 After milliseconds, it is T1 Delete .
But this solution also has many disadvantages . First , In the case of updating existing values in the cache , New values always start with 500 The millisecond delay is deleted , This will damage the cache hit rate . Besides , This solution depends on the correct setting of the delay , This is usually unpredictable , Because it will follow the load 、 Hardware changes, etc . I don't recommend write-deferred-invalidate, Because prediction delay is just a gamble .
therefore ,CAS May be the only way to solve such problems .
Other solutions
Double delete
This mode is a direct writing variant , It originated from some engineers who wanted to invalidate the cache first , And then write it to the database . This is a three-step solution :1) Invalidate cache .2) Write to database 3) Schedule deferred cache invalidation . I don't understand why they invalidate the cache before writing to the database , This will only lead to more inconsistencies . And the three-step solution is very expensive . actually , This is the same as what we just talked about in the previous section write-deferred-invalidate The solution is very similar , I don't recommend it .
MySQL binlog To cache
This is the solution of Alibaba engineers . They have a listener to receive MySQL binlog And in Redis Or other types of cache to fill cache data . This way, you no longer need to write a cache in your application code , The cache is automatically populated by listeners . And you have lag from database instances , So you don't need to delay cache invalidation . The solution satisfies the sequential consistency model . It sounds cool , But this solution cannot handle fine-grained caching , If you just want to cache 1% The data of ( Do you have 100 Tables , Just cache a table ), You still need to deal with 100% Of binlog And delete 99% Log entries for . And you may see higher delays , Because you have to deal with asynchronous replication and parsing binlog. If you have multiple databases or even multiple data centers , You must already have database replication , under these circumstances , This solution is probably the easiest way to achieve sequence consistency . Be careful , Use binlog When copying databases and caches , Be sure to process the database before caching , If writing to the database fails , Stop writing cache , If I keep writing volatile cache , After the cache expires , Your application may see the phantom data disappear , You can only get final consistency . If you can start from binlog And update the cache of each data center in the local application , That's very complicated , Beyond the scope of this article . More details about this , Please read facebook In the paper “ Across the region : Uniformity ” chapter , Learn how to use “ Remote tagging ” To mitigate inconsistencies . This solution is probably the easiest way to achieve sequence consistency . Be careful , Use binlog When copying databases and caches , Be sure to process the database before caching , If writing to the database fails , Stop writing cache , If I keep writing volatile cache , After the cache expires , Your application may see the phantom data disappear , You can only get final consistency . If you can start from binlog And update the cache of each data center in the local application , That's very complicated , Beyond the scope of this article . More details about this , Please read facebook In the paper “ Across the region : Uniformity ” chapter , Learn how to use “ Remote tagging ” To mitigate inconsistencies . This solution is probably the easiest way to achieve sequence consistency . Be careful , Use binlog When copying databases and caches , Be sure to process the database before caching , If writing to the database fails , Stop writing cache , If I keep writing volatile cache , After the cache expires , Your application may see the phantom data disappear , You can only get final consistency . If you can start from binlog And update the cache of each data center in the local application , That's very complicated , Beyond the scope of this article . More details about this , Please read facebook In the paper “ Across the region : Uniformity ” chapter , Learn how to use “ Remote tagging ” To mitigate inconsistencies . You must always process the database and then cache , If you cannot write to the database , You should stop writing to the cache , If you continue to write to the volatile cache , After the cache expires , Your application may see the phantom data disappear , You can only get the final consistency . If you can start from binlog And update the cache of each data center in the local application , That's very complicated , Beyond the scope of this article . More details about this , Please read facebook In the paper “ Across the region : Uniformity ” chapter , Learn how to use “ Remote tagging ” To mitigate inconsistencies . You must always process the database and then cache , If you cannot write to the database , You should stop writing to the cache , If you continue to write to the volatile cache , After the cache expires , Your application may see the phantom data disappear , You can only get the final consistency . If you can start from binlog And update the cache of each data center in the local application , That's very complicated , Beyond the scope of this article . More details about this , Please read facebook In the paper “ Across the region : Uniformity ” chapter , Learn how to use “ Remote tagging ” To mitigate inconsistencies . If you can start from binlog And update the cache of each data center in the local application , That's very complicated , Beyond the scope of this article . More details about this , Please read facebook In the paper “ Across the region : Uniformity ” chapter , Learn how to use “ Remote tagging ” To mitigate inconsistencies . If you can start from binlog And update the cache of each data center in the local application , That's very complicated , Beyond the scope of this article . More details about this , Please read facebook In the paper “ Across the region : Uniformity ” chapter , Learn how to use “ Remote tagging ” To mitigate inconsistencies .
Cache failed
If the cache update fails , Reading through will not introduce any problems , In addition to increasing database load . If the cache is updated because write-through or write-invalidate Failure , You will not see the latest value , Until another successful write or cache expires . When you combine all these caching patterns together , Things get complicated .
Conclusion
Considering all kinds of errors and faults , It is usually impossible to implement a linear consistency model using distributed caching and database systems . Each caching mode has its limitations , In some cases, you cannot achieve sequence consistency , Or sometimes you get unexpected delays between the cache and the database . For all the solutions I have shown in this article , You will always encounter extreme cases of high concurrency . therefore , There is no panacea for this , Understand the limitations and define your consistency requirements before choosing a solution . If you want linear consistency consistency with fault tolerance , It's best not to use caching at all .
Cache mode Write to read
Write directly : Write to the database synchronously and cache . It's safe , Because it writes to the database first , But it is better than Write-Behind slow . And write-invalidate comparison , It's for write-then-read Scenarios provide better performance .
Post write ( Or write back ): Write to cache first , Then write to the database asynchronously . This is very fast for writing , If multiple writes on the same key are merged into one write to the database , Then the speed will be faster . But the database is inconsistent with the cache for a long time , If the data has not been swiped to the database , The process crashed , Data may be lost .RAID Card is a good example of this pattern , To avoid data loss , You usually need RAID The battery backup unit on the card saves the data in the cache but has not logged into the disk .
Invalid write : Similar to direct writing , Write to the database first , Then invalidate the cache . This simplifies the processing of consistency between the cache and the database in the case of concurrent updates . You don't need complex synchronization , The tradeoff is low hit rate , Because you always invalidate the cache , And the next read will always miss .
Refresh in advance : Predict hot data from the database and automatically refresh the cache , Never block reads , Best for small read-only datasets , For example, postal code list cache , You can refresh the entire cache periodically , Because it is small and read-only . If you can accurately predict the key you need to read most , You can also warm up these keys in this mode . Last , If the data is updated outside your system and your system cannot receive notification , You may have to use this mode .
Read Through: When the read misses , Load it from the database and save it to the cache . The main problem with this model is , Sometimes you need to warm up the cache ( Use early refresh mode ), If your website happens to be on Black Friday morning 9:00 There are popular products , Cold caching may cause many pending requests for this product .
in the majority of cases , We use read-through and write-through/write-behind/write-invalidate.Refresh-ahead Can be used alone , It can also be used as prediction and preheating reading for optimization of read through .
responsibility
And there are two implementation modes according to the scope of responsibility of the application .
Cache-through:( or look-through, or inline-cache) The cache layer is a library or service delegate that writes to the database , Your application only talks to the cache layer . The cache layer can process the database in the background , And ensure consistency and failover . for example , Many databases have built-in caches , Everything is cached and then the disk , Client applications do not know the consistency between cache and disk , This is a good example of cache passing . Another example is Spring Abstract cache layer in application , From the perspective of the caller , This layer is also a cache penetration mode .( See Spring In the cache framework @Cacheable and @CachePut annotation ).
Cache-aside:( or look-aside) Your application maintains cache consistency , This means that your application code is more complex , But this provides more flexibility . for example , Developers can prevent some data from being cached , Or check the dynamic setting of data content TTL, Bypass the cache for queries that require high consistency , Cache composite objects instead of original database records . Despite these benefits , But the tradeoff is more coding , Because they cannot happen automatically under the caching framework . And like cache-through It is also difficult to maintain cache consistency , for example , Because all queries go through the built-in cache of the database , Therefore, cache consistency is easier to achieve .
From the perspective of the caller ,cache-through and cache-aside Patterns are different . No matter which mode you use , You always have to deal with concurrency and consistency, which are difficult and often overlooked in distributed systems . Because it must be in cache-aside or cache-through Pattern to solve , And the implementation is actually the same , So I will use cache-aside Patterns discuss this topic .



























![[200 opencv routines] 220 Mosaic the image](/img/75/0293e10ad6de7ed86df4cacbd79b54.png)