当前位置:网站首页>缓存更新策略概览(Caching Strategies Overview)
缓存更新策略概览(Caching Strategies Overview)
2022-07-06 12:56:00 【abka】
缓存是一种用于更快数据检索的数据存储技术。从某种意义上说,它比从其主存储(如数据库)获取数据更快。为了实现这一点,我们通常缓存频繁请求或计算的数据。现在,让我们仔细看看可能需要考虑的不同缓存策略。请记住,每个应用程序的需求都是不同的,您应该据此选择缓存策略。
Cache-Aside Strategy (缓存侧缓存策略、旁路缓存 策略)
Cache-Aside Strategy(缓存侧缓存策略、旁路缓存 策略)是使用最广泛的缓存策略之一。该策略背后的主要思想是,仅当应用程序请求对象时,才将对象存储在缓存中。





Cache-Aside(缓存侧缓存策略、旁路缓存)的基本流程如下:
- 应用程序收到要获取某些数据的请求。
- 应用程序检查缓存中是否存在数据:
- 如果是(也称为缓存命中),则从缓存中获取。
- 如果不是(缓存未命中),则调用数据存储(例如数据库)以检索数据并将其存储在缓存中。
- 应用程序返回请求的数据。
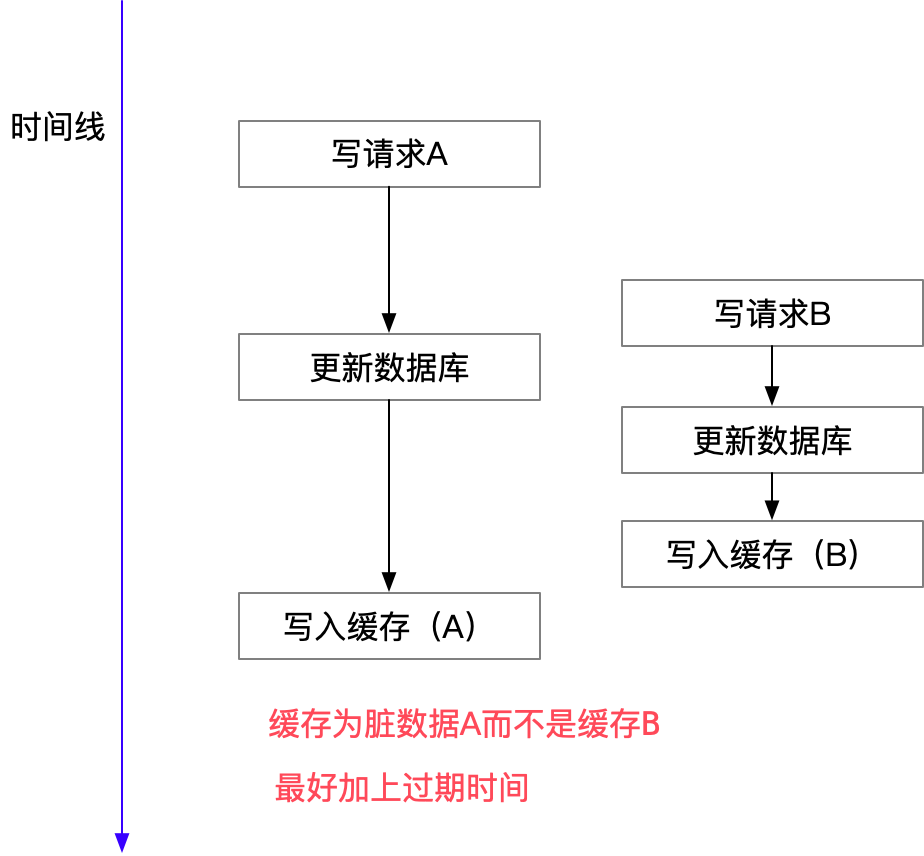
这是标准的design pattern,包括Facebook的论文《Scaling Memcache at Facebook》也使用了这个策略。为什么不是写完数据库后更新缓存?你可以看一下Quora上的这个问答《Why does Facebook use delete to remove the key-value pair in Memcached instead of updating the Memcached during write request to the backend?》,主要是怕两个并发的写操作导致脏数据。
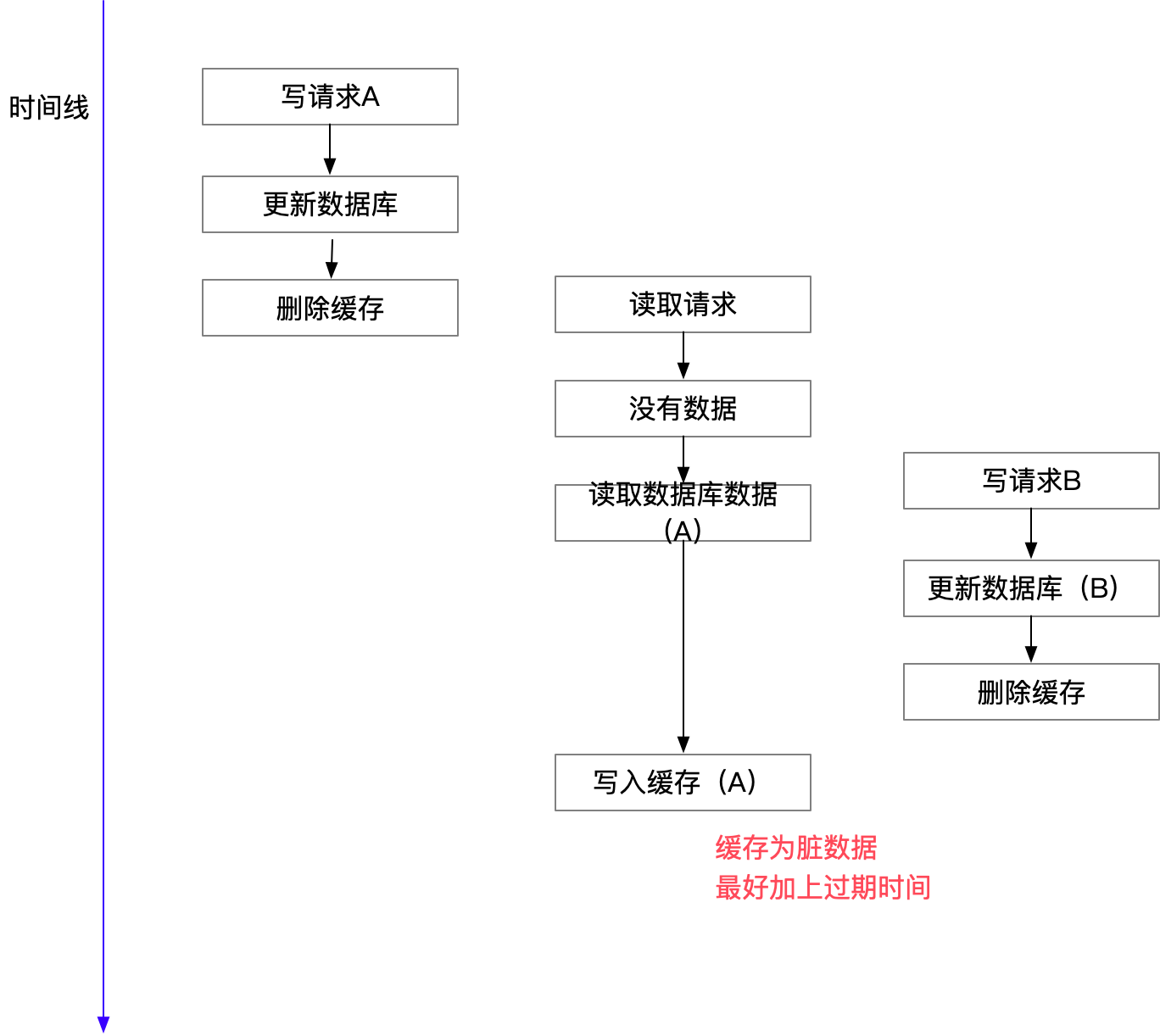
两个并发的写操作导致脏数据 Just imagine what if two concurrent updates of the same data element occur? You might have different values of the same data item in DB and in memcached. Which is bad. There is a certain number of ways to avoid or to decrease probability of this. Here is the couple of them: 1. A single transaction coordinator 2. Many transaction coordinators, with an elected master via Paxos or Raft consensus algorithm 3. Deletion of elements from memcached on DB updates I assume that they chose the way #3 because "a single" means a single point of failure, and Paxos/Raft is not easy to implement plus it sacrifices availability for the benefit of consistency. -- 并发更新数据库的情况下: 可能会将过期数据写入缓存,导致业务读取脏数据。所以直接删除最靠谱。 Why does Facebook use delete to remove the key-value pair in Cache instead of updating the Cache? https://blog.csdn.net/qfzhangwei/article/details/118379546那么,是不是Cache Aside这个就不会有并发问题了?不是的,比如,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
Cache-Aside Strategy 可能的问题 但,这个case理论上会出现,不过,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。(不过计算机科学中常见的常识就是的小概率事件一定会发生,因为计算机会反复重复很多次)
所以,这也就是Quora上的那个答案里说的,要么通过2PC或是Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率,而Facebook使用了这个降低概率的玩法,因为2PC太慢,而Paxos太复杂。当然,最好还是为缓存设置上过期时间。
用例,优点和缺点
缓存侧缓存通常是通用的,最适合读取繁重的工作负载。Memcached和Redis被广泛使用。使用缓存侧的系统对缓存故障具有弹性。如果缓存集群出现故障,系统仍然可以直接访问数据库进行操作。(虽然,如果缓存在峰值负载期间下降,它并没有多大帮助。响应时间可能会变得很糟糕,在最坏的情况下,数据库可能会停止工作。)
另一个好处是缓存中的数据模型可以不同于数据库中的数据模型。例如,作为多个查询的结果生成的响应可以针对某个请求 id 进行存储。
使用cache-aside时,最常见的写入策略是直接将数据写入数据库。发生这种情况时,缓存可能会与数据库不一致。为了解决这个问题,开发人员通常使用生存时间 (TTL) 并继续提供陈旧数据,直到 TTL 过期。如果必须保证数据的新鲜度,开发人员要么使缓存条目无效,要么使用适当的写入策略,我们稍后将探讨。
Read-Through Caching Strategy (通读缓存策略,读穿透缓存策略)
Read-Through Caching Strategy (通读缓存策略,读穿透缓存策略)是一种类似于Cache-Aside Strategy(旁路缓存 策略)的缓存方法。不同之处在于应用程序不协调从哪里读取数据(缓存或数据存储)。相反,它总是通过缓存读取数据。在这种情况下,缓存是决定从哪里获取数据的那个。当我们将其与缓存侧策略进行比较时,这是一个很大的优势,因为它使应用程序的代码更加干净


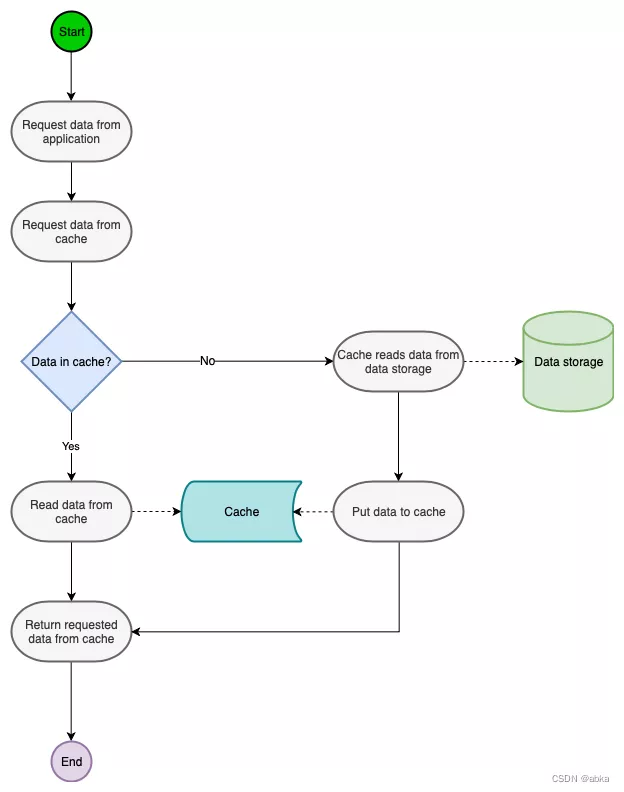

Read-Through, Write-Through, Write-Behind Caching and Refresh-Ahead
用例,优点和缺点
虽然 read-through 和 cache-aside 非常相似,但至少有两个关键区别:
- 在缓存侧,应用程序负责从数据库中获取数据并填充缓存。在通读中,此逻辑通常由库或独立缓存提供程序支持。
- 与 cache-aside 不同,read-through cache 中的数据模型不能与数据库的数据模型不同。
当多次请求相同的数据时,通读缓存最适合读取繁重的工作负载。例如,一个新闻故事。缺点是当第一次请求数据时,总是会导致缓存未命中,并招致将数据加载到缓存中的额外惩罚。开发人员通过手动发出查询来“加热”或“预热”缓存来处理这个问题。就像cache-aside一样,缓存和数据库之间的数据也有可能不一致,解决办法在于写策略,我们接下来会看到。
Write-Through Caching Strategy(直写式缓存策略,写穿透缓存策略)
在这个策略中,所有的写操作都经过缓存。每次写入时,缓存也会将数据存储在底层数据存储中。这两个操作都发生在一个事务中。因此,只有两个写入都成功,一切才会成功。它确实会在写入时产生一些额外的延迟,但至少它极大地改善了数据不一致问题,因为缓存中的数据和数据存储是相同的。但是请注意要通过缓存写入哪些数据,以免最终导致缓存中存在实际上从未或很少读取的数据负载。这可能会导致不必要的内存使用。更糟糕的是,一些有用的数据可能会被不那么有用的数据从缓存中清除。
从积极的方面来说,因为应用程序只与缓存对话,所以它的代码更加干净和简单。如果您需要在代码中的多个位置复制逻辑,这一点尤其明显。




当使用Write-Through Caching Strategy(直写式缓存策略,写穿透缓存策略)时,也可以通过缓存进行读取,因为读取操作很快。
Write-Through Caching Strategy(写穿透缓存策略)最适合以下应用程序:
- 需要经常读取相同的数据。
- 不要容忍缓存和数据存储(“旧数据”)之间的数据丢失和不一致。
可以使用Write-Through Caching Strategy(直写式缓存策略,写穿透缓存策略)的系统的一个潜在示例是银行系统。
用例,优点和缺点
就其本身而言,直写式缓存似乎没有太大作用,实际上,它们会引入额外的写入延迟,因为数据先写入缓存,然后再写入主数据库。但是当与通读缓存配对时,我们可以获得通读的所有好处,并且我们还可以获得数据一致性保证,使我们免于使用缓存失效技术。
DynamoDB Accelerator (DAX)是读取/写入缓存的一个很好的例子。它与 DynamoDB 和您的应用程序内联。可以通过 DAX 对 DynamoDB 进行读取和写入。(旁注:如果您计划使用 DAX,请确保您熟悉它的数据一致性模型以及它如何与 DynamoDB 相互作用。)
Write-Behind Caching Strategy(后写缓存策略)



Read-Through, Write-Through, Write-Behind Caching and Refresh-Ahead
Write-behind 缓存策略类似于 write-through 缓存,应用程序仅与缓存进行通信,并且只有一个外观来写入数据。与直写模式的区别在于数据首先写入缓存。然后,一段时间后(或通过其他触发器),数据也被写入底层数据源。现在这是这个策略的关键部分——这些操作是异步发生的。
数据源写入可以通过多种方式完成。一种选择是“收集”所有写入,然后在某个时间点(例如,当数据库负载较低时)对数据源进行批量写入。另一种方法是将写入合并成更小的批次。缓存收集例如五个写入操作,然后对数据源进行批量写入。
对缓存和数据源进行异步写入有助于大大减少延迟。除此之外,它还有助于卸载数据源。但在不太积极的方面,它增加了缓存和数据源之间的数据不一致。这导致了一个额外的问题。如果有人在数据尚未写入数据源的情况下直接从数据源获取数据,则可能导致获取过期数据。
为了解决数据不一致问题,系统可以将 write-behind 策略与 read-through 策略相结合。这样,始终要从缓存中读取最新数据。
当我们将其与直写策略进行比较时,它更适合具有较大写入量的系统,这些系统可以容忍一些数据不一致。
Write Behind 又叫 Write Back(写回)。一些了解Linux操作系统内核的同学对write back应该非常熟悉,这不就是Linux文件系统的Page Cache的算法吗?是的,你看基础这玩意全都是相通的。所以,基础很重要,我已经不是一次说过基础很重要这事了。
Write Back套路,一句说就是,在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是让数据的I/O操作飞快无比(因为直接操作内存嘛 ),因为异步,write backg还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。
但是,其带来的问题是,数据不是强一致性的,而且可能会丢失(我们知道Unix/Linux非正常关机会导致数据丢失,就是因为这个事)。在软件设计上,我们基本上不可能做出一个没有缺陷的设计,就像算法设计中的时间换空间,空间换时间一个道理,有时候,强一致性和高性能,高可用和高性性是有冲突的。软件设计从来都是取舍Trade-Off。
另外,Write Back实现逻辑比较复杂,因为他需要track有哪数据是被更新了的,需要刷到持久层上。操作系统的write back会在仅当这个cache需要失效的时候,才会被真正持久起来,比如,内存不够了,或是进程退出了等情况,这又叫lazy write。
在wikipedia上有一张write back的流程图,基本逻辑如下:

用例,优点和缺点
回写缓存提高了写入性能,适用于写入繁重的工作负载。与通读结合使用时,它适用于混合工作负载,其中最近更新和访问的数据始终在缓存中可用。
它对数据库故障具有弹性,并且可以容忍一些数据库停机时间。如果支持批处理或合并,它可以减少对数据库的整体写入,从而减少负载并降低成本,如果数据库提供商按请求数量收费,例如 DynamoDB。请记住,DAX 是直写的,因此如果您的应用程序写入繁重,您不会看到任何成本降低。(当我第一次听说 DAX 时,这是我的第一个问题 - DynamoDB 可能非常昂贵,但该死的亚马逊。)
一些开发人员将 Redis 用于缓存和回写,以更好地吸收峰值负载期间的峰值。主要缺点是如果缓存失败,数据可能会永久丢失。
大多数关系数据库存储引擎(即 InnoDB)在其内部默认启用了回写缓存。查询首先写入内存并最终刷新到磁盘。
Write around

数据直接写入数据库,只有读取的数据才能进入缓存。
用例,优点和缺点
write-around 可以与 read-through 结合使用,并在数据写入一次而读取频率较低或从不读取的情况下提供良好的性能。例如,实时日志或聊天室消息。同样,此模式也可以与cache-aside(缓存侧)结合使用。
Write-Around其实本身并不会用到缓存,而是会直接写入到数据库中。
Cache-Aside为什么要配合Write-Around而不能和Write-Through一起使用呢?
因为Write-Through会先更新缓存,而如果这时刚好有另外一个线程将数据库中旧的数据读取出来将缓存中新的数据覆盖,就会造成数据错误,而使用Write-Around就不会出现这个问题。
Write-Around在某些场景下与Read-Through搭配使用也很有用,对于某些只需要写一次并且读多次的情况,比如聊天信息的写入和获取。
结论
在这篇博文中,我们介绍了五种不同的缓存策略:cache-aside, read-trough, Write-Around、write-through and write-behind。要使用一个,您需要考虑系统的特性。此外,在实际使用场景中,您最有可能将策略组合在一起使用。
如果选错了怎么办?与您的目标或访问模式不匹配的一种?您可能会引入额外的延迟,或者至少看不到全部好处。例如,如果您在实际上应该使用write-around/read-through(写入的数据访问频率较低)时选择write-through/read-through ,那么您的缓存中就会有无用的垃圾。可以说,如果缓存足够大,它可能没问题。但是在许多现实世界的高吞吐量系统中,当内存永远不够大并且服务器成本成为问题时,正确的策略很重要。
一致性问题
直写中的客户端/网络故障
下图是直写模式。T1 尝试更新 X,同时 T2 读取 X。如果 T1 在第 2 步崩溃或网络中断怎么办?T2 将始终在第 3 步看到陈旧数据,直到缓存过期。这符合顺序一致性模型,取决于您的实际用例,如果缓存过期时间足够短,延迟可能不是大问题。

在这种情况下,真正的问题是缓存驱逐。如果缓存逐出是基于LRU并且数据被频繁读取,缓存-数据库不一致时间窗口会很大,甚至无限大,这意味着T2永远不会看到新的值,这不满足任何客户端视图之间的一致性模型并且会在您的应用程序中导致严重的问题。为避免这种情况,请根据第一次缓存密钥时的时间戳强制设置一个固定的过期时间(例如,Caffeine 中的 expireAfterWrite)。
通读并发
假设我们不使用分布式锁来协调 T1 和 T2,X 还不存在于缓存中。下图显示了 T1 和 T2 都遇到了缓存未命中。在第 3 步之后,如果在 T1 中发生 JVM full GC 之类的事情,则对数据库的更新将被延迟。同时,T2 更新缓存并将 X 写入最新的值 2,最终 T1 从 GC 中恢复并将其陈旧值 1 写入缓存。如果 T2 再次读取 X,它会看到一个旧值并且可能会混淆。不满足顺序一致性和线性一致性。

使用分布式锁可以解决这个问题,但是太贵了。一个简单的解决方案是通过 CAS 防止 T1 在步骤 7 写入过时数据。大多数现代缓存系统都支持 CAS 写入(例如 Redis Lua),我们可以使用带有版本的 CAS 写入来确保这样的写入顺序(在 Redis 中使用 Lua 实现):
# Arguments
#KEYS[1]: the key
#ARGV[1]: old version
#ARGV[2]: new version
#ARGV[3]: new value
#ARGV[4]: TTL in seconds
# You can test in redis-cli:
eval "local v = redis.call('GET', KEYS[1]); if (v) then local version, value = v:match(\"([^:]+):([^:]+)\"); if (version ~= ARGV[1]) then return 1; end end redis.call('SET', KEYS[1], ARGV[2] .. ':' .. ARGV[3], 'EX', tonumber(ARGV[4])); return 0;" 1 key1 0 1 value1 1000使用 CAS,在第 7 步 T1 将失败,并且 T1 能够再次查询缓存以获取最新的 X。
一个非常特殊的情况是,如果 T1 暂停很长时间,足够长以至于在第 6 步写入的 X 的值过期,在这种情况下,T1 仍然能够将过时的数据写入缓存,但这种情况极少发生,因为 T1 已经暂停很长时间,也许 15 分钟,这不太可能发生。所以,这只是理论上的一种可能性。如果要解决这个问题,请考虑在写入缓存时使用时间戳,如果太旧,缓存系统可以拒绝写入。例如,过期设置为 5 分钟,如果写入的时间戳超过 5 分钟,则拒绝并报告错误,以便客户端可以意识到这一点并重试。但是,任何基于时间戳的解决方案都容易受到时钟漂移的影响,您必须进行正确的 NTP 设置。
直写并发
假设我们不使用分布式锁来协调 T1 和 T2,T1 和 T2 都尝试更新 X。

在第 2 步之后,理想情况下,T1 应该将缓存更新为 1,但如果在 T1 中发生类似 JVM 完全 GC 的情况,同时 T2 更新缓存并将 X 写入最新值 2,那么 T1 会将其陈旧值 1 写入 X缓存。这类似于前面提到的并发问题,但这种情况发生的可能性更大,它不需要两个并发的缓存未命中,这种情况很少见。
要在没有分布式锁的情况下解决此类问题,您可以使用 write-invalidate 模式和 read-through 模式。在第 4/5 步,我们只是使缓存键无效,下一次读取应该重新创建缓存数据。这样,T1/T2 在下一次读取时都会将 X 视为 2,如果另一个 T3 在第 4 步和第 5 步之间读取 X,它会看到缓存未命中并尝试从数据库加载缓存,并将 X 视为 2 . 现在我们达到了线性化一致性级别。缺点很明显,在先写后读的场景中,您会看到命中率较低。
您还可以使用带有版本检查的 CAS 写入来确保顺序,正如我们在上一节中演示的那样。每次更新数据库时都取回版本(可以通过Oracle序列,在MySQL中模拟序列,分布式增量键,锁定行以检索结果),然后仅在传入请求的版本为时更新缓存高于缓存中的版本以防止步骤 5 发生。除非 T1 暂停很长时间并且 X 过期(这种情况很少见),否则它应该在大多数情况下都可以工作。这个解决方案有点复杂,只有在你真正需要的时候才使用它。
写无效中的并发
为了解决直写问题,我们可以使用 write-invalidate 模式。如果我们在 write-through 的时序图中将“update X to ...”改为“invalidate cache”,看起来是这样的:

然后任何后续读取都将看到缓存未命中并使用最新值重新填充缓存。但是,这只是解决了两个写客户端之间的一些数据竞争场景,它没有解决读客户端和写客户端之间没有锁的数据竞争问题,它只是尽力而为的最终一致性,而不是顺序一致性。我将在下一节中解释原因。在此之前,让我们看看 Facebook 是如何通过锁(租约)来解决这个问题的。
Facebook 在 2013 年发表了一篇论文,解释了 Write-Invalidate 模式是如何与“lease”一起使用的,“lease”实际上是一个锁。来自Facebook 3.2.1的 Scaling Memcache 。
直观地说,memcached 实例向客户端提供租约,以便在客户端遇到缓存未命中时将数据设置回缓存中。租约是绑定到客户端最初请求的特定密钥的 64 位令牌。客户端在缓存中设置值时提供租用令牌。使用租约令牌,memcached 可以验证并确定是否应存储数据,从而仲裁并发写入。如果 memcached 由于收到对该项目的删除请求而使租用令牌无效,则验证可能会失败。租约以类似于 load-link/storeconditional 操作的方式防止陈旧集 [20]。
论文没有说明发生错误时如何退租,如果承租人崩溃并未能退租怎么办?最有可能使用超时解决方案来破坏租约以防出错。但很明显,这个超时会增加负面情况下的延迟。我相信带有版本控制而不锁定的 CAS 是比他更好的解决方案。现在让我们看看为什么在没有锁的情况下很难实现顺序一致性,当两个客户端通过写入无效和通读同时读取和写入时。
具有写入无效和通读的并发性
在上一节中,我们讨论了 write-invalidate 如何解决由 write-through 引起的问题。但是 write-invalidate 在与 read-through 一起使用时也存在问题,这是在许多系统中使用的非常常见的模式。假设我们不使用分布式锁来协调 T1 和 T2,T1 都尝试读取 X,T2 尝试更新 X。

如果 T1 超载并且由于某种原因速度很慢,则可以推迟第 5 步并将过时的值写入缓存。
CAS 写入解决方案不适用于 write-invalidate 模式,因为一旦在第 4 步删除了缓存的密钥,您就没有什么可与 CAS 进行比较的了。
有些人使用类似write-deferred-invalidate 的解决方案,即异步安排 500ms 后的失效,并在第 3 步后立即返回。想法是我们希望我们可以预测 T1 的延迟程度,并在第 5 步后进行失效。

当您拥有只读从数据库集群时,此解决方案还有助于隐藏数据库主/从延迟。如果 T1 更新主数据库,T2 从从数据库实例读取,由于复制延迟,T2 将看不到 T1 所做的最新更改,因此 T2 可以填充陈旧缓存,幸运的是陈旧缓存将在 500 毫秒后被 T1 删除.
但是这种解决方案也有很多缺点。首先,在更新缓存中的现有值的情况下,新值总是以 500 毫秒的延迟被删除,这会损害缓存命中率。此外,这个解决方案取决于延迟的正确设置,这通常是无法预测的,因为它会随着负载、硬件变化等而变化。我不推荐write-deferred-invalidate,因为预测延迟只是一种赌博。
因此,CAS 可能是解决此类问题的唯一方法。
其他解决方案
双重删除
这种模式是一种直写变体,起源于一些工程师希望先使缓存无效,然后再写入数据库。这是一个三步解决方案:1)使缓存无效。2) 写入数据库 3) 安排延迟缓存失效。我不明白他们为什么要在写入数据库之前使缓存无效,这只会导致更多的不一致。并且三步解决方案非常昂贵。实际上,这和上一节我们刚刚谈到的write-deferred-invalidate解决方案非常相似,我不建议这样做。
MySQL binlog 到缓存
这是阿里巴巴工程师的解决方案。他们有一个监听器来接收 MySQL binlog 并在 Redis 或其他类型的缓存中填充缓存数据。这样您就不再需要在应用程序代码中编写缓存,缓存由侦听器自动填充。而且你有从数据库实例滞后,所以你不需要延迟缓存失效。该解决方案满足顺序一致性模型。听起来很酷,但是这个解决方案不能处理细粒度的缓存,如果你只想缓存 1% 的数据(你有 100 个表,只需要缓存一个表),你仍然需要处理 100% 的 binlog并删除 99% 的日志条目。而且您可能会看到更高的延迟,因为您必须处理异步复制和解析 binlog。如果您有多个数据库甚至多个数据中心,您必须已经拥有数据库复制,在这种情况下,此解决方案可能是实现顺序一致性的最简单方法。注意,使用binlog复制数据库和缓存的时候,一定要先处理数据库再缓存,如果写数据库失败,就停止写缓存,如果一直写到volatile缓存,缓存过期后,你的应用程序可能会看到幻像数据消失,您只能获得最终一致性。如果你可以从 binlog 和本地应用程序中更新每个数据中心的缓存,那是非常复杂的,超出了本文的范围。有关这方面的更多详细信息,请阅读 facebook 论文中的“跨区域:一致性”一章,了解如何使用“远程标记”来缓解不一致。此解决方案可能是实现顺序一致性的最简单方法。注意,使用binlog复制数据库和缓存的时候,一定要先处理数据库再缓存,如果写数据库失败,就停止写缓存,如果一直写到volatile缓存,缓存过期后,你的应用程序可能会看到幻像数据消失,您只能获得最终一致性。如果你可以从 binlog 和本地应用程序中更新每个数据中心的缓存,那是非常复杂的,超出了本文的范围。有关这方面的更多详细信息,请阅读 facebook 论文中的“跨区域:一致性”一章,了解如何使用“远程标记”来缓解不一致。此解决方案可能是实现顺序一致性的最简单方法。注意,使用binlog复制数据库和缓存的时候,一定要先处理数据库再缓存,如果写数据库失败,就停止写缓存,如果一直写到volatile缓存,缓存过期后,你的应用程序可能会看到幻像数据消失,您只能获得最终一致性。如果你可以从 binlog 和本地应用程序中更新每个数据中心的缓存,那是非常复杂的,超出了本文的范围。有关这方面的更多详细信息,请阅读 facebook 论文中的“跨区域:一致性”一章,了解如何使用“远程标记”来缓解不一致。您必须始终处理数据库然后缓存,如果您无法写入数据库,您应该停止写入缓存,如果您继续写入易失性缓存,缓存到期后,您的应用程序可能会看到幻像数据消失,您只能获取最终的一致性。如果你可以从 binlog 和本地应用程序中更新每个数据中心的缓存,那是非常复杂的,超出了本文的范围。有关这方面的更多详细信息,请阅读 facebook 论文中的“跨区域:一致性”一章,了解如何使用“远程标记”来缓解不一致。您必须始终处理数据库然后缓存,如果您无法写入数据库,您应该停止写入缓存,如果您继续写入易失性缓存,缓存到期后,您的应用程序可能会看到幻像数据消失,您只能获取最终的一致性。如果你可以从 binlog 和本地应用程序中更新每个数据中心的缓存,那是非常复杂的,超出了本文的范围。有关这方面的更多详细信息,请阅读 facebook 论文中的“跨区域:一致性”一章,了解如何使用“远程标记”来缓解不一致。如果你可以从 binlog 和本地应用程序中更新每个数据中心的缓存,那是非常复杂的,超出了本文的范围。有关这方面的更多详细信息,请阅读 facebook 论文中的“跨区域:一致性”一章,了解如何使用“远程标记”来缓解不一致。如果你可以从 binlog 和本地应用程序中更新每个数据中心的缓存,那是非常复杂的,超出了本文的范围。有关这方面的更多详细信息,请阅读 facebook 论文中的“跨区域:一致性”一章,了解如何使用“远程标记”来缓解不一致。
缓存失败
如果缓存更新失败,通读不会引入任何问题,除了增加数据库负载。如果缓存更新因 write-through 或 write-invalidate 而失败,您将无法看到最新值,直到另一个成功的写入或缓存过期。当您将所有这些缓存模式组合在一起工作时,事情就会变得复杂。
结论
考虑到各种错误和故障,通常不可能使用分布式缓存和数据库系统实现线性一致性模型。每个缓存模式都有其局限性,在某些情况下您无法获得顺序一致性,或者有时您会在缓存和数据库之间获得意外延迟。对于我在本文中展示的所有解决方案,您总是会遇到高并发的极端情况。因此,对此没有灵丹妙药,在选择解决方案之前了解限制并定义您的一致性要求。如果您希望具有容错性的线性一致性一致性,则最好根本不使用缓存。
缓存模式
写读
直写:同步写入数据库然后缓存。这是安全的,因为它首先写入数据库,但它比 Write-Behind 慢。与 write-invalidate 相比,它为 write-then-read 场景提供了更好的性能。
后写(或回写):先写入缓存,然后异步写入数据库。这对于写入来说非常快,如果将同一键上的多次写入合并到对数据库的一次写入中,则速度会更快。但是数据库长期与缓存不一致,如果数据还没刷到数据库,进程就崩溃了,可能会丢失数据。RAID 卡就是这种模式的一个很好的例子,为了避免数据丢失,您通常需要 RAID 卡上的电池备份单元将数据保存在缓存中但尚未登陆磁盘。
写入无效:类似于直写,先写入数据库,然后使缓存无效。这简化了在并发更新的情况下处理缓存和数据库之间的一致性。您不需要复杂的同步,权衡是命中率较低,因为您总是使缓存无效,并且下一次读取将始终未命中。
提前刷新:从数据库中预测热点数据并自动刷新缓存,从不阻塞读取,最适合小型只读数据集,例如邮政编码列表缓存,您可以定期刷新整个缓存,因为它很小并且是只读的。如果您可以准确预测最需要阅读的键,您还可以在此模式中预热这些键。最后,如果数据在您的系统之外更新并且您的系统无法收到通知,您可能必须使用此模式。
Read Through:当读取未命中时,从数据库中加载它并将其保存到缓存中。这种模式的主要问题是,有时您需要预热缓存(使用提前刷新模式),如果您的网站上正好在黑色星期五上午 9:00 有热销产品,冷缓存可能会导致很多该产品的待处理请求。
在大多数情况下,我们使用 read-through 和 write-through/write-behind/write-invalidate。Refresh-ahead 可以单独使用,也可以作为预测和预热读取以进行通读的优化。
责任并且根据应用程序的职责范围有两种实现模式。
Cache-through:(或look-through,或inline-cache)缓存层是一个库或服务委托写入数据库,您的应用程序只与缓存层对话。缓存层可以在后台处理数据库,并确保一致性和故障转移。例如,很多数据库都内置了缓存,一切都经过缓存然后磁盘,客户端应用程序不知道缓存和磁盘之间的一致性,这是一个很好的缓存通过示例。另一个例子是 Spring 应用程序中的抽象缓存层,从调用者的角度来看,该层也是一个缓存穿透模式。(参见 Spring 缓存框架中的 @Cacheable 和 @CachePut 注解)。
Cache-aside:(或look-aside)您的应用程序保持缓存一致性,这意味着您的应用程序代码更复杂,但这提供了更大的灵活性。例如,开发人员可以防止某些数据被缓存,或者通过检查数据内容动态设置 TTL,对一些一致性要求高的查询绕过缓存,缓存复合对象而不是缓存原始数据库记录。尽管有这些好处,但权衡是更多的编码,因为它们不能在缓存框架下自动发生。而且像cache-through一样保持缓存的一致性也很困难,例如,由于所有查询都经过数据库的内置缓存,因此缓存一致性更容易实现。
从调用者的角度来看,cache-through 和 cache-aside 模式是有区别的。无论您采用哪种模式,您总是必须处理在分布式系统中很难且经常被忽略的并发性和一致性。由于它必须以 cache-aside 或 cache-through 模式来解决,并且实现实际上是相同的,所以我将在本文中以 cache-aside 模式讨论这个主题。
参考:
Caching Strategies Overview - Cats In Code
https://www.usenix.org/system/files/conference/nsdi13/nsdi13-final170_update.pdf
https://en.wikipedia.org/wiki/Cache_replacement_policies
Read-Through, Write-Through, Write-Behind Caching and Refresh-Ahead
Caching Strategies and How to Choose the Right One | CodeAhoy
Cache Strategies 缓存策略_Bryan要加油的博客-CSDN博客
Cache Consistency with Database
边栏推荐
- The use method of string is startwith () - start with XX, endswith () - end with XX, trim () - delete spaces at both ends
- R語言可視化兩個以上的分類(類別)變量之間的關系、使用vcd包中的Mosaic函數創建馬賽克圖( Mosaic plots)、分別可視化兩個、三個、四個分類變量的關系的馬賽克圖
- Word bag model and TF-IDF
- 审稿人dis整个研究方向已经不仅仅是在审我的稿子了怎么办?
- Why do job hopping take more than promotion?
- How do I remove duplicates from the list- How to remove duplicates from a list?
- JS get array subscript through array content
- @PathVariable
- Mtcnn face detection
- El table table - get the row and column you click & the sort of El table and sort change, El table column and sort method & clear sort clearsort
猜你喜欢

Laravel notes - add the function of locking accounts after 5 login failures in user-defined login (improve system security)

愛可可AI前沿推介(7.6)
SAP UI5 框架的 manifest.json

ICML 2022 | flowformer: task generic linear complexity transformer
OAI 5g nr+usrp b210 installation and construction

Performance test process and plan
![[redis design and implementation] part I: summary of redis data structure and objects](/img/2e/b147aa1e23757519a5d049c88113fe.png)
[redis design and implementation] part I: summary of redis data structure and objects
Reinforcement learning - learning notes 5 | alphago
20220211 failure - maximum amount of data supported by mongodb

3D face reconstruction: from basic knowledge to recognition / reconstruction methods!
随机推荐
Regular expression collection
Swagger UI教程 API 文档神器
Reinforcement learning - learning notes 5 | alphago
【力扣刷题】一维动态规划记录(53零钱兑换、300最长递增子序列、53最大子数组和)
966 minimum path sum
The difference between break and continue in the for loop -- break completely end the loop & continue terminate this loop
字符串的使用方法之startwith()-以XX开头、endsWith()-以XX结尾、trim()-删除两端空格
'class file has wrong version 52.0, should be 50.0' - class file has wrong version 52.0, should be 50.0
Pat 1078 hashing (25 points) ⼆ times ⽅ exploration method
2017 8th Blue Bridge Cup group a provincial tournament
Thinking about agile development
Forward maximum matching method
[redis design and implementation] part I: summary of redis data structure and objects
ICML 2022 | flowformer: task generic linear complexity transformer
KDD 2022 | 通过知识增强的提示学习实现统一的对话式推荐
Swagger UI tutorial API document artifact
In JS, string and array are converted to each other (II) -- the method of converting array into string
R語言可視化兩個以上的分類(類別)變量之間的關系、使用vcd包中的Mosaic函數創建馬賽克圖( Mosaic plots)、分別可視化兩個、三個、四個分類變量的關系的馬賽克圖
In JS, string and array are converted to each other (I) -- the method of converting string into array
Nodejs教程之让我们用 typescript 创建你的第一个 expressjs 应用程序