当前位置:网站首页>Aike AI frontier promotion (7.6)
Aike AI frontier promotion (7.6)
2022-07-06 21:04:00 【Zhiyuan community】
LG - machine learning CV - Computer vision CL - Computing and language AS - Audio and voice RO - robot
Turn from love to a lovely life
Abstract : Neural network distribution drift performance prediction 、 Reasons for language models to enhance integration 、 Recommendation system with no distributed reliability guarantee 、 Unwrapping of random and cyclic effects in time-lapse photography sequences 、 Iterative refinement algorithm training based on implicit difference 、 A summary of the emerging interdisciplinary fields of biological robots 、 Through distributed optimization, the multi legged robot can climb freely and contact rich grasp and movement at the same time 、 Solid multi-functional quadruped free climbing robot 、 Label and text driven object radiation field
1、[LG] Agreement-on-the-Line: Predicting the Performance of Neural Networks under Distribution Shift
C Baek, Y Jiang, A Raghunathan, Z Kolter
[CMU]
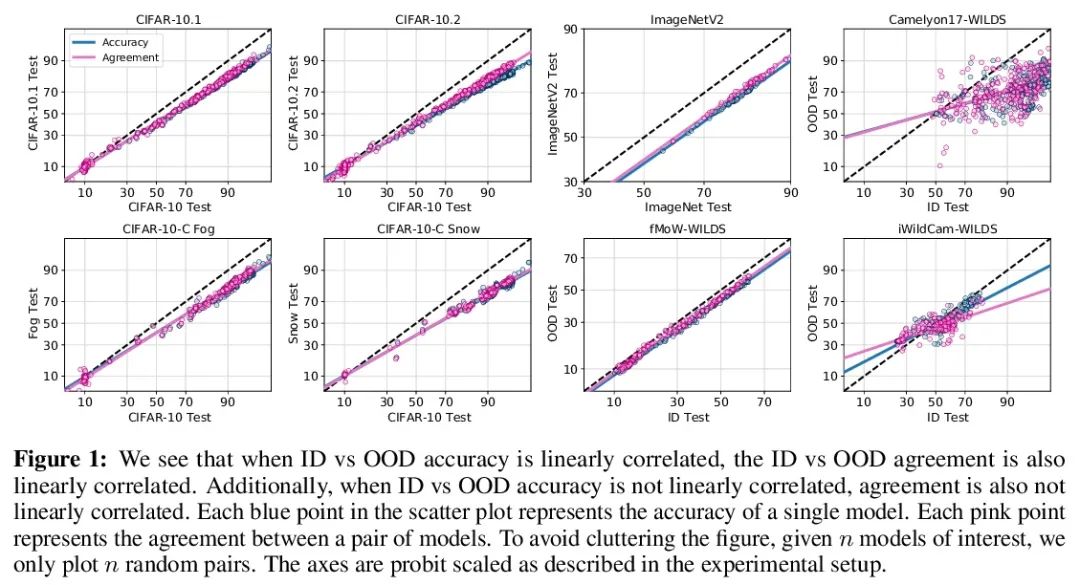
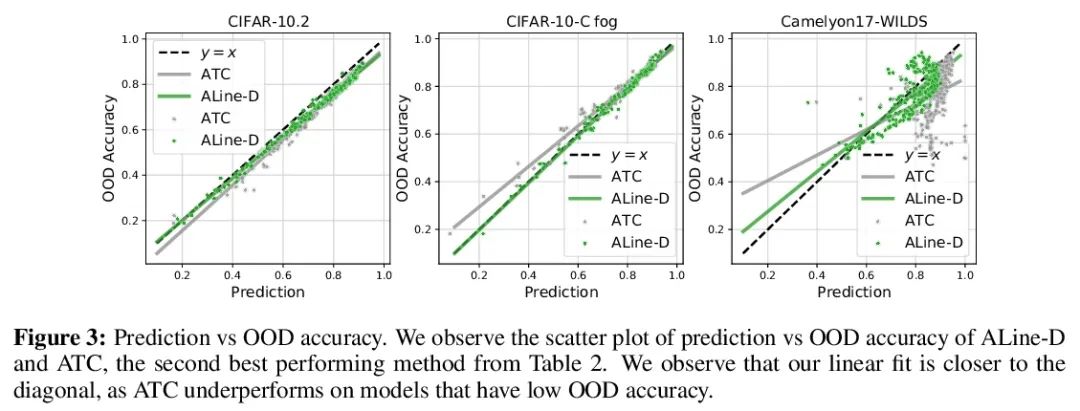
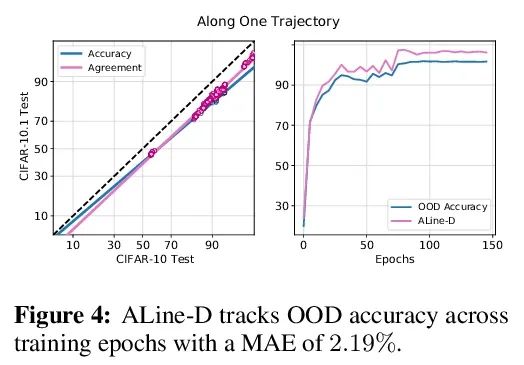
Agreement-on-the-Line: Neural network distribution drift performance prediction . lately ,Miller And so on , Within the distribution of a model (ID) The accuracy is in a few OOD Beyond the distribution on the benchmark (OOD) The accuracy has a strong linear correlation —— They call this phenomenon " Online accuracy (accuracy-on-the-line)". Although this is a useful tool for selecting models ( That is, it is most likely to show the best OOD The model has the highest ID The model of precision ), But this fact does not help to estimate the reality of the model OOD performance , Because there is no annotation OOD Verification set . This article shows a similar but surprising phenomenon , That is, the consistency between neural network classifier pairs is also established : No matter what accuracy-on-the-line Is it true , In this paper, we observe any two neural networks ( With potentially different architectures ) Between forecasts OOD Consistency is also related to their ID Consistency has a strong linear relationship . Besides , We observed that ,OOD vs ID The consistent slope and deviation of OOD vs ID Is closely related to the accuracy of . This kind of phenomenon , Call it online consistency (agreement-on-the-line), It has important practical significance : Without any annotation data , The classifier can be predicted OOD precision , because OOD Consistency can be estimated by unmarked data . The prediction algorithm is in agreement-on-the-line Established drift , And surprisingly , When the accuracy is not online , Are better than the previous methods . This phenomenon is also known as Deep neural network Provides new insights : And accuracy-on-the-line Different ,agreement-on-the-line It seems to be true only for neural network classifiers .
Recently, Miller et al. [56] showed that a model’s in-distribution (ID) accuracy has a strong linear correlation with its out-of-distribution (OOD) accuracy on several OOD benchmarks — a phenomenon they dubbed “accuracy-on-the-line”. While a useful tool for model selection (i.e., the model most likely to perform the best OOD is the one with highest ID accuracy), this fact does not help estimate the actual OOD performance of models without access to a labeled OOD validation set. In this paper, we show a similar but surprising phenomenon also holds for the agreement between pairs of neural network classifiers: whenever accuracyon-the-line holds, we observe that the OOD agreement between the predictions of any two pairs of neural networks (with potentially different architectures) also observes a strong linear correlation with their ID agreement. Furthermore, we observe that the slope and bias of OOD vs ID agreement closely matches that of OOD vs ID accuracy. This phenomenon, which we call agreement-on-the-line, has important practical applications: without any labeled data, we can predict the OOD accuracy of classifiers, since OOD agreement can be estimated with just unlabeled data. Our prediction algorithm outperforms previous methods both in shifts where agreement-on-the-line holds and, surprisingly, when accuracy is not on the line. This phenomenon also provides new insights into deep neural networks: unlike accuracy-on-the-line, agreement-on-the-line appears to only hold for neural network classifiers.
https://arxiv.org/abs/2206.13089


2、[CL] Rationale-Augmented Ensembles in Language Models
X Wang, J Wei, D Schuurmans, Q Le, E Chi, D Zhou
[Google Research]
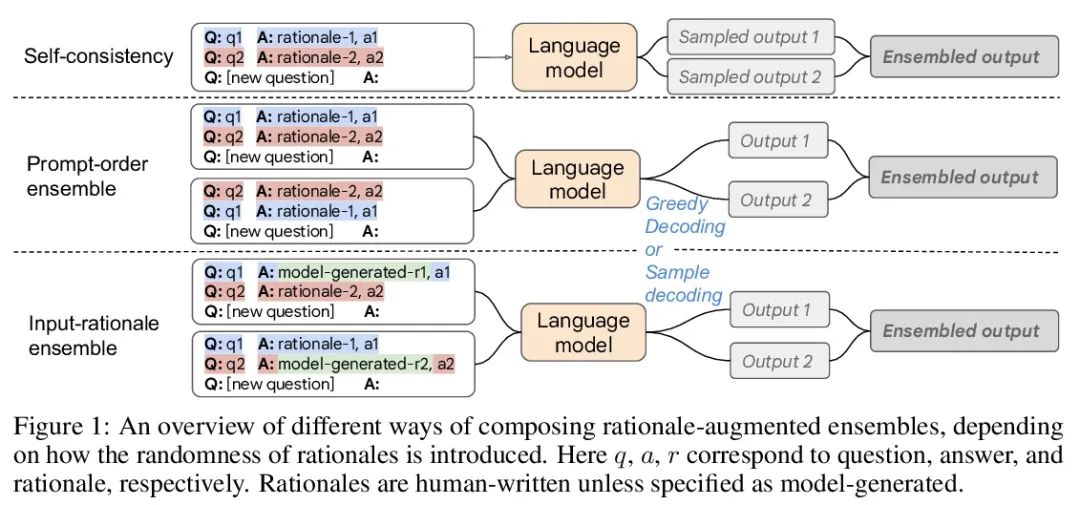
Reasons for language models to enhance integration . Recent research shows that , reason , Or step by step thinking chain , It can be used to improve the performance of multi-step reasoning tasks . This paper reconsiders the prompt method of rational enhancement , For less sample context learning , among ( Input → Output ) The prompt is extended to ( Input 、 reason → Output ) Tips . Tips for reason enhancement , It is proved that the existing methods that rely on manual prompt engineering are subject to the sub optimal reasons that may damage the performance . In order to reduce this brittleness , This paper proposes a unified reason to enhance the integration framework , The reason sampling in the output space is determined as the key part to improve the performance robustly . The framework is generic , It can be easily extended to common natural language processing tasks , Even those tasks that traditionally do not use intermediate steps , Such as Q & A 、 Word sense disambiguation and emotion analysis . And the existing prompt methods —— Including the standard prompt without reason and the thought chain prompt based on reason —— comparison , Reason enhanced integration can achieve more accurate and interpretable results , At the same time, the interpretability of the model prediction is improved through relevant reasons .
Recent research has shown that rationales, or step-by-step chains of thought, can be used to improve performance in multi-step reasoning tasks. We reconsider rationale-augmented prompting for few-shot in-context learning, where (input → output) prompts are expanded to (input, rationale → output) prompts. For rationale-augmented prompting we demonstrate how existing approaches, which rely on manual prompt engineering, are subject to sub-optimal rationales that may harm performance. To mitigate this brittleness, we propose a unified framework of rationale-augmented ensembles, where we identify rationale sampling in the output space as the key component to robustly improve performance. This framework is general and can easily be extended to common natural language processing tasks, even those that do not traditionally leverage intermediate steps, such as question answering, word sense disambiguation, and sentiment analysis. We demonstrate that rationale-augmented ensembles achieve more accurate and interpretable results than existing prompting approaches—including standard prompting without rationales and rationale-based chain-of-thought prompting—while simultaneously improving interpretability of model predictions through the associated rationales.
https://arxiv.org/abs/2207.00747



3、[IR] Recommendation Systems with Distribution-Free Reliability Guarantees
A N. Angelopoulos, K Krauth, S Bates, Y Wang, M I. Jordan
[UC Berkeley]
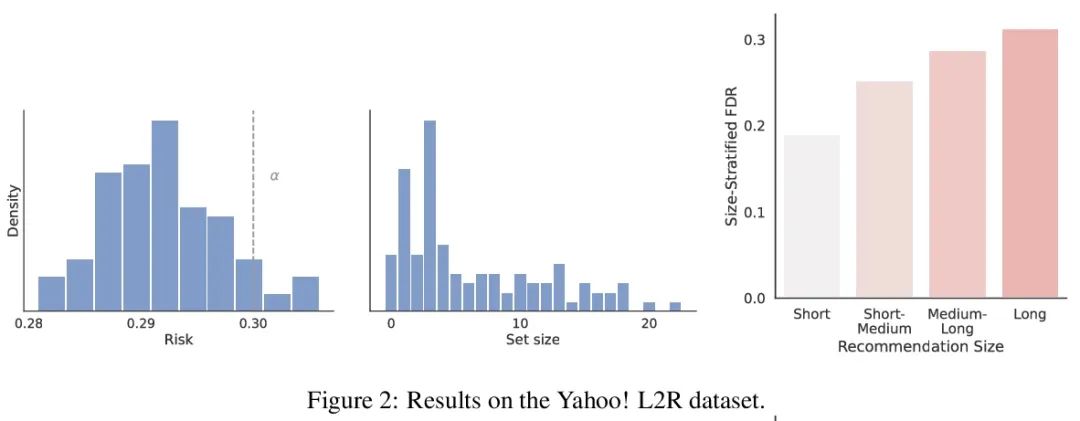
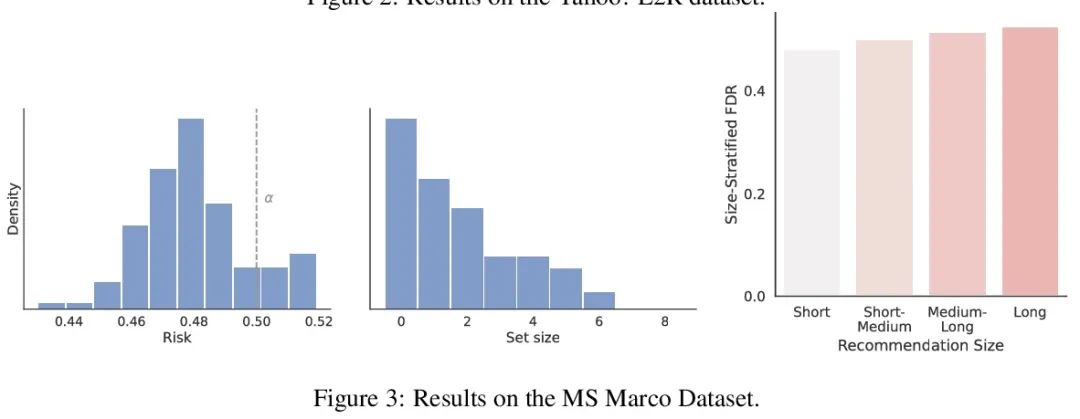
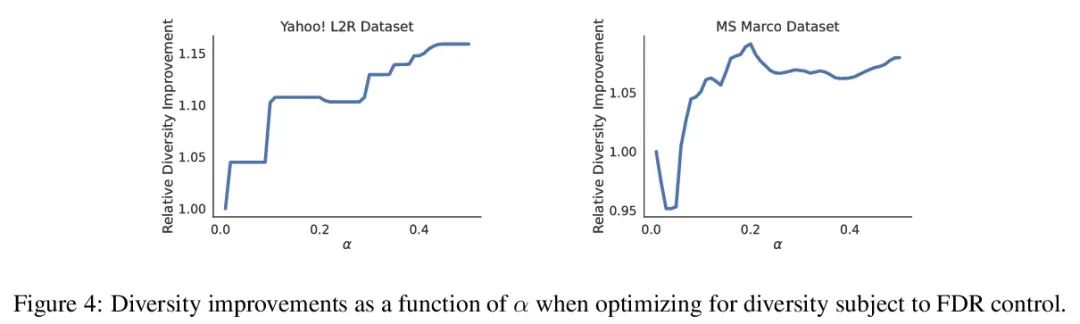
Recommendation system with no distributed reliability guarantee . When establishing a recommendation system , Always try to output a set of helpful items to users . Behind the system , A ranking model predicts which of the two candidate projects is better , These paired comparisons must be refined into user oriented output . However , A learned ranking model is never perfect , therefore , On the surface, its prediction cannot guarantee the reliability of user oriented output . Starting from a pre training ranking model , This article shows how to return a project set that strictly guarantees to contain most good projects . This program gives any ranking model a strict error detection rate (FDR) Finite sample control of , No matter what ( Unknown ) How is the data distributed . Besides , The proposed calibration algorithm makes the integration of multiple targets in the recommendation system simple and principled . As an example , This article shows how to specify FDR Optimize the diversity of recommendations under the control level , It avoids specifying special weights for diversity loss and accuracy loss . In the whole process , Focus on learning how to rank a group of possible recommendations , stay Yahoo! Learning to Rank and MSMarco The proposed method is evaluated on the dataset .
When building recommendation systems, we seek to output a helpful set of items to the user. Under the hood, a ranking model predicts which of two candidate items is better, and we must distill these pairwise comparisons into the user-facing output. However, a learned ranking model is never perfect, so taking its predictions at face value gives no guarantee that the user-facing output is reliable. Building from a pre-trained ranking model, we show how to return a set of items that is rigorously guaranteed to contain mostly good items. Our procedure endows any ranking model with rigorous finite-sample control of the false discovery rate (FDR), regardless of the (unknown) data distribution. Moreover, our calibration algorithm enables the easy and principled integration of multiple objectives in recommender systems. As an example, we show how to optimize for recommendation diversity subject to a user-specified level of FDR control, circumventing the need to specify ad hoc weights of a diversity loss against an accuracy loss. Throughout, we focus on the problem of learning to rank a set of possible recommendations, evaluating our methods on the Yahoo! Learning to Rank and MSMarco datasets.
https://arxiv.org/abs/2207.01609

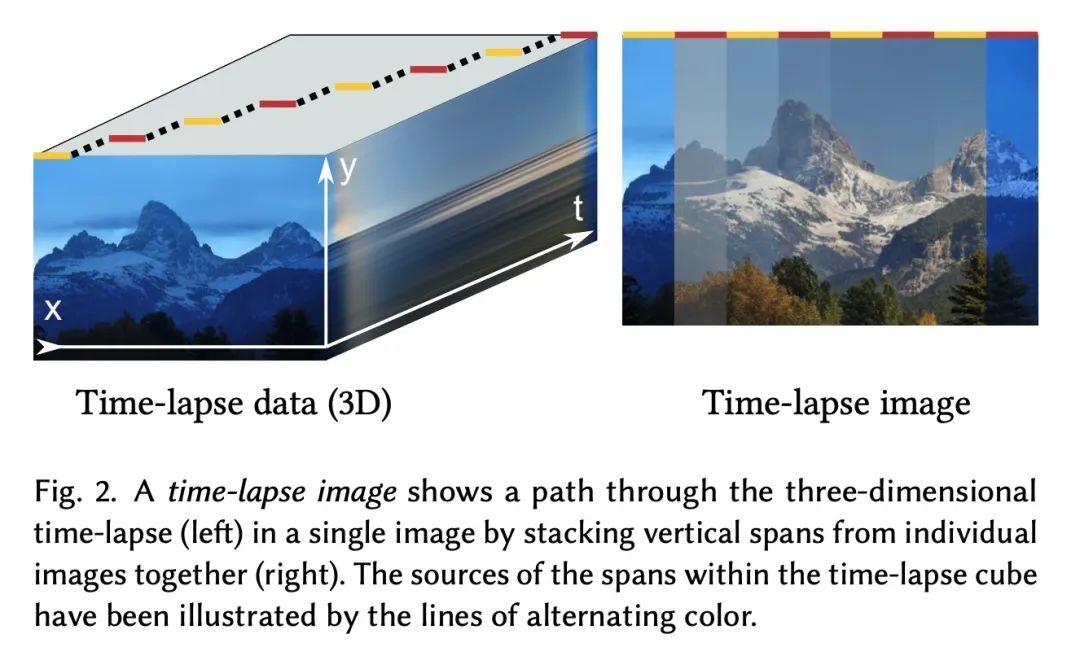
4、[CV] Disentangling Random and Cyclic Effects in Time-Lapse Sequences
E Härkönen, M Aittala, T Kynkäänniemi, S Laine, T Aila, J Lehtinen
[Aalto University & NVIDIA]
Unwrapping of random and cyclic effects in time-lapse photography sequences . Time lapse photography sequences provide visually convincing insight into dynamic processes , These processes are too slow , Unable to observe in real time . However , Due to random effects ( Like the weather ) And periodic effect ( Such as day and night cycle ) Influence , Playing back a long time-lapse photography sequence in the form of video often leads to disturbing flicker . In this paper, we propose the unwrapping problem of delay sequences , Allow the overall trend in the image 、 Periodic effects and random effects are individually controlled afterwards , And describes a data-driven generation model technology to achieve this goal . It can be achieved in a way that it is impossible to input images alone " Re render " Sequence . for example , It can stabilize a long sequence , In optional 、 Consistent weather , Pay attention to the growth of plants in multiple months . The proposed method is based on generating countermeasure Networks (GAN), Based on the time coordinates of the time-lapse photography sequence . Its structure and training program are designed in this way : Learn to use the Internet GAN To simulate random changes , Like the weather , And provide conditional time tags to the model by using Fourier features with specific frequencies , To distinguish between general trends and cyclical changes . Experiments show that , The proposed model is robust to the defects in the training data , It can correct some practical difficulties in capturing long delay sequences , Such as temporary shelter 、 Uneven frame spacing and frame missing .
Time-lapse image sequences offer visually compelling insights into dynamic processes that are too slow to observe in real time. However, playing a long time-lapse sequence back as a video often results in distracting flicker due to random effects, such as weather, as well as cyclic effects, such as the day-night cycle. We introduce the problem of disentangling time-lapse sequences in a way that allows separate, after-the-fact control of overall trends, cyclic effects, and random effects in the images, and describe a technique based on data-driven generative models that achieves this goal. This enables us to "re-render" the sequences in ways that would not be possible with the input images alone. For example, we can stabilize a long sequence to focus on plant growth over many months, under selectable, consistent weather. Our approach is based on Generative Adversarial Networks (GAN) that are conditioned with the time coordinate of the time-lapse sequence. Our architecture and training procedure are designed so that the networks learn to model random variations, such as weather, using the GAN's latent space, and to disentangle overall trends and cyclic variations by feeding the conditioning time label to the model using Fourier features with specific frequencies. We show that our models are robust to defects in the training data, enabling us to amend some of the practical difficulties in capturing long time-lapse sequences, such as temporary occlusions, uneven frame spacing, and missing frames.
https://arxiv.org/abs/2207.01413



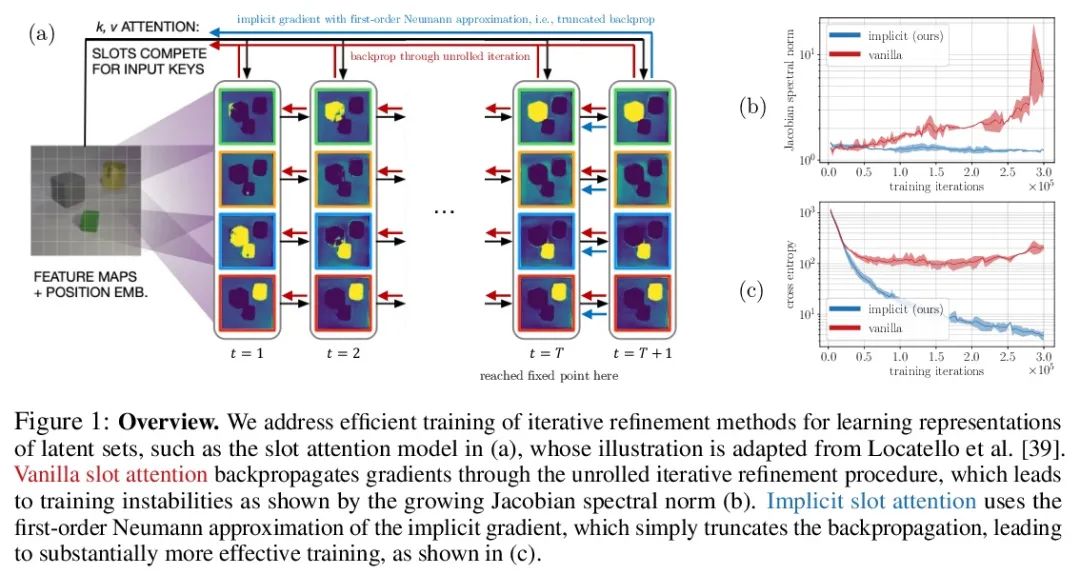
5、[LG] Object Representations as Fixed Points: Training Iterative Refinement Algorithms with Implicit Differentiation
M Chang, T L. Griffiths, S Levine
[UC Berkeley & Princeton University]
Fixed point objects represent : Iterative refinement algorithm training based on implicit difference . Iterative improvement —— Start with random guesses , Then iteratively improve the guess —— It is a useful paradigm to express learning , It provides a way to break the symmetry between equally reasonable interpretations of data . This feature enables this method to be applied to infer the representation of entity sets , Such as objects in physical scenes , In structure, it is similar to clustering algorithm in latent space . However , Most of the previous work is differential through loose refinement process , This can make optimization challenging . This paper observes that this method can become differentiable by implicit function theorem , And a method of implicit differentiation is developed , By decoupling forward and backward , Improve the stability and operability of training . This connection makes it possible to apply the progress of optimizing the hidden layer , Not only improved SLATE Optimization of the middle slot attention module —— A most advanced entity representation learning method —— And when the space and time complexity of back propagation remain unchanged , Just add a line of code to do it .
Iterative refinement – start with a random guess, then iteratively improve the guess – is a useful paradigm for representation learning because it offers a way to break symmetries among equally plausible explanations for the data. This property enables the application of such methods to infer representations of sets of entities, such as objects in physical scenes, structurally resembling clustering algorithms in latent space. However, most prior works differentiate through the unrolled refinement process, which can make optimization challenging. We observe that such methods can be made differentiable by means of the implicit function theorem, and develop an implicit differentiation approach that improves the stability and tractability of training by decoupling the forward and backward passes. This connection enables us to apply advances in optimizing implicit layers to not only improve the optimization of the slot attention module in SLATE, a state-of-the-art method for learning entity representations, but do so with constant space and time complexity in backpropagation and only one additional line of code.
https://arxiv.org/abs/2207.00787




Several other papers worthy of attention :
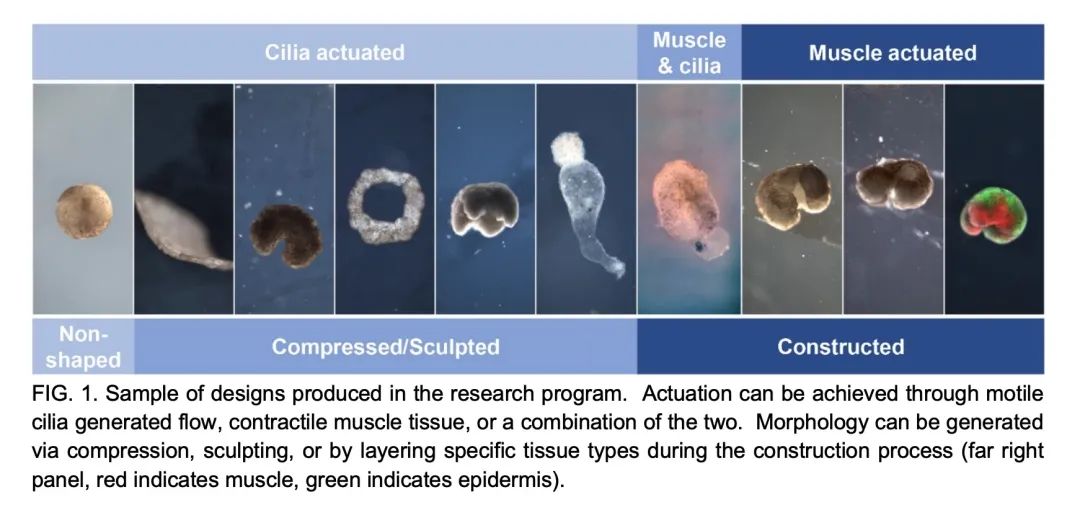
[RO] Biological Robots: Perspectives on an Emerging Interdisciplinary Field
Biological robots : Overview of emerging interdisciplinary fields
D. Blackiston, S. Kriegman, J. Bongard, M. Levin
[Tufts University & University of Vermont]
https://arxiv.org/abs/2207.00880


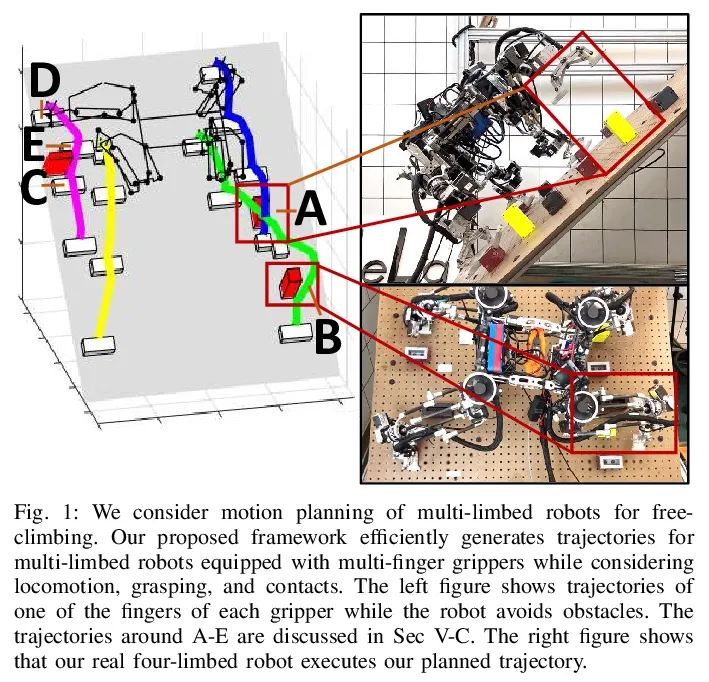
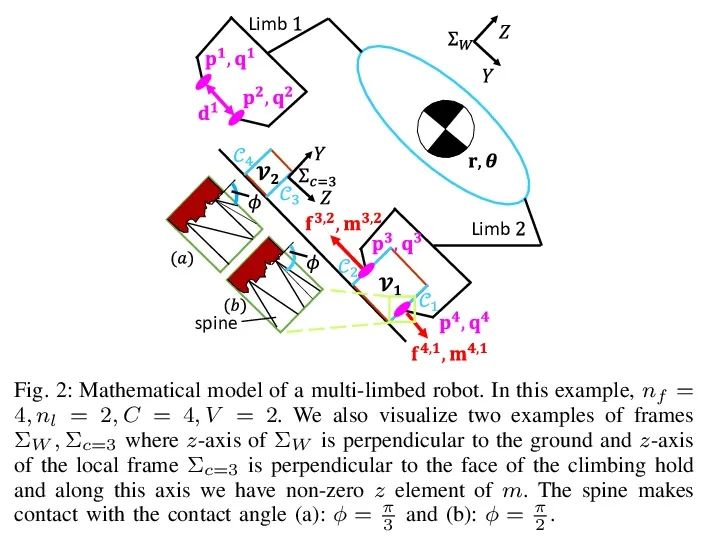
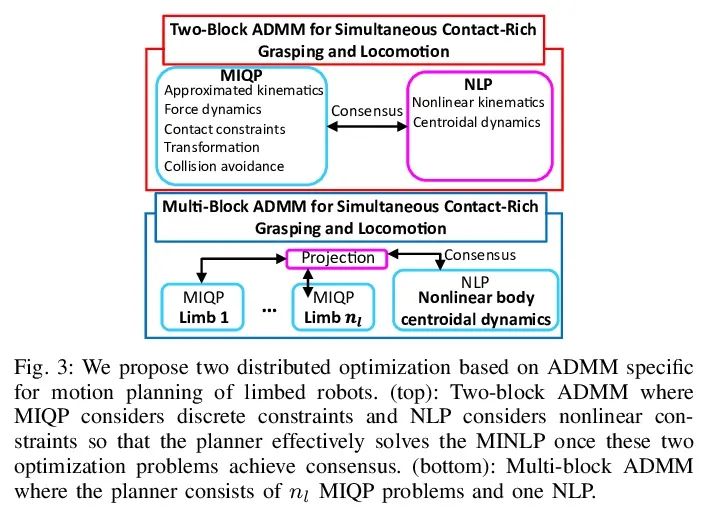
[RO] Simultaneous Contact-Rich Grasping and Locomotion via Distributed Optimization Enabling Free-Climbing for Multi-Limbed Robots
Through distributed optimization, the multi legged robot can climb freely and contact rich grasp and movement at the same time
Y Shirai, X Lin, A Schperberg, Y Tanaka...
[University of California, Los Angeles]
https://arxiv.org/abs/2207.01418

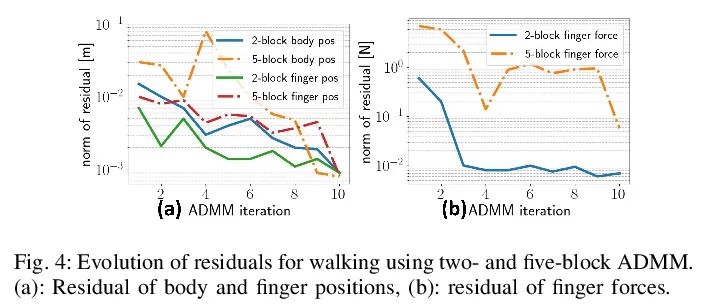
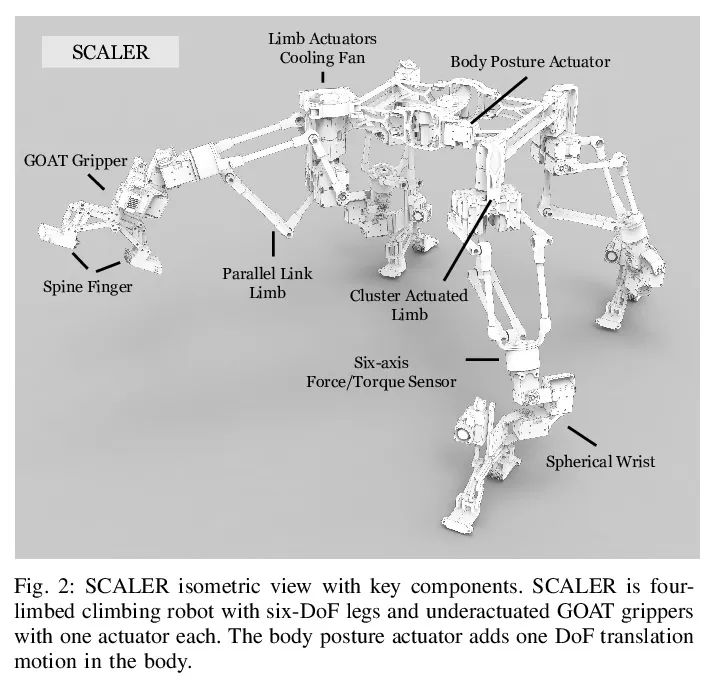
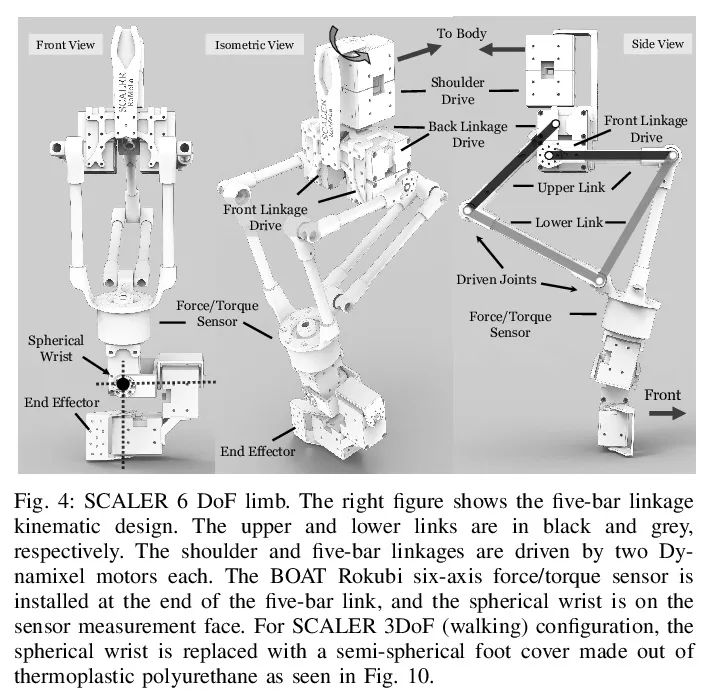
[RO] SCALER: A Tough Versatile Quadruped Free-Climber Robot
SCALER: Solid multi-functional quadruped free climbing robot
Y Tanaka, Y Shirai, X Lin, A Schperberg, H Kato, A Swerdlow, N Kumagai, D Hong
[University of California, Los Angeles]
https://arxiv.org/abs/2207.01180



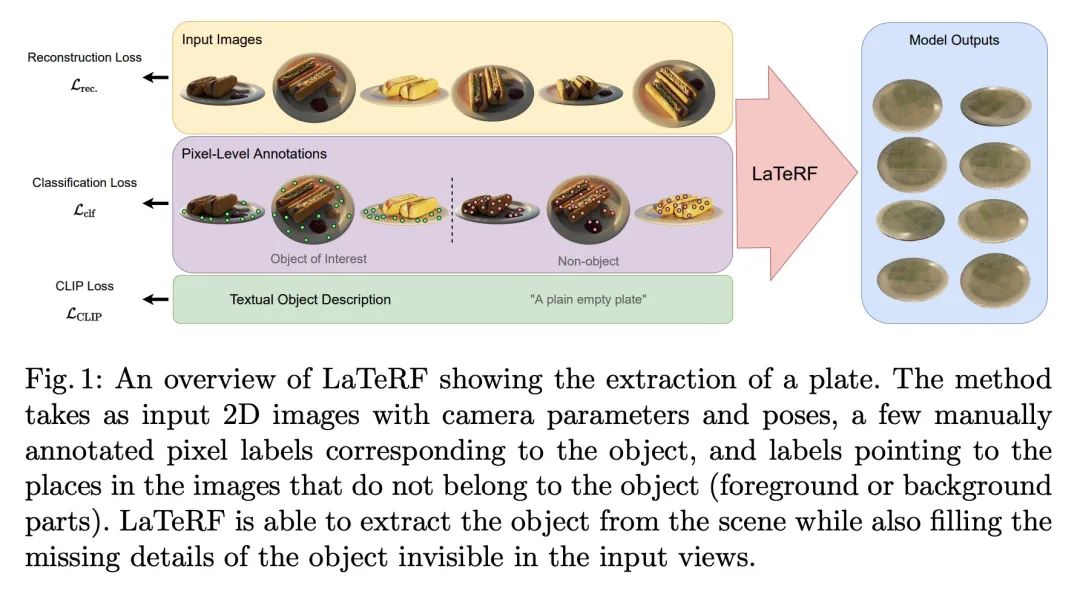
[CV] LaTeRF: Label and Text Driven Object Radiance Fields
LaTeRF: Label and text driven object radiation field
A Mirzaei, Y Kant, J Kelly, I Gilitschenski
[University of Toronto]
https://arxiv.org/abs/2207.01583



边栏推荐
- Distributed ID
- Summary of different configurations of PHP Xdebug 3 and xdebug2
- (work record) March 11, 2020 to March 15, 2021
- PHP online examination system version 4.0 source code computer + mobile terminal
- SAP Fiori应用索引大全工具和 SAP Fiori Tools 的使用介绍
- C # use Oracle stored procedure to obtain result set instance
- (工作记录)2020年3月11日至2021年3月15日
- 2022 nurse (primary) examination questions and new nurse (primary) examination questions
- [DSP] [Part 1] start DSP learning
- Mécanisme de fonctionnement et de mise à jour de [Widget Wechat]
猜你喜欢
![[diy] how to make a personalized radio](/img/fc/a371322258131d1dc617ce18490baf.jpg)
[diy] how to make a personalized radio

KDD 2022 | 通过知识增强的提示学习实现统一的对话式推荐
使用.Net分析.Net达人挑战赛参与情况

Entity alignment two of knowledge map

Variable star --- article module (1)
None of the strongest kings in the monitoring industry!
2017 8th Blue Bridge Cup group a provincial tournament

【OpenCV 例程200篇】220.对图像进行马赛克处理
Swagger UI教程 API 文档神器
Value of APS application in food industry
随机推荐
使用.Net驱动Jetson Nano的OLED显示屏
Hardware development notes (10): basic process of hardware development, making a USB to RS232 module (9): create ch340g/max232 package library sop-16 and associate principle primitive devices
面试官:Redis中有序集合的内部实现方式是什么?
2022 refrigeration and air conditioning equipment installation and repair examination contents and new version of refrigeration and air conditioning equipment installation and repair examination quest
过程化sql在定义变量上与c语言中的变量定义有什么区别
[200 opencv routines] 220 Mosaic the image
Mécanisme de fonctionnement et de mise à jour de [Widget Wechat]
2110 summary of knowledge points and common problems in redis class
Infrared thermometer based on STM32 single chip microcomputer (with face detection)
[DSP] [Part 1] start DSP learning
【OpenCV 例程200篇】220.对图像进行马赛克处理
2022 nurse (primary) examination questions and new nurse (primary) examination questions
Implementation of packaging video into MP4 format and storing it in TF Card
Value of APS application in food industry
What are RDB and AOF
【论文解读】用于白内障分级/分类的机器学习技术
Spiral square PTA
Intel 48 core new Xeon run point exposure: unexpected results against AMD zen3 in 3D cache
Core principles of video games
15 millions d'employés sont faciles à gérer et la base de données native du cloud gaussdb rend le Bureau des RH plus efficace