当前位置:网站首页>Entity alignment two of knowledge map
Entity alignment two of knowledge map
2022-07-06 20:31:00 【Southern cities in late spring】
Common processes and steps of knowledge fusion

1 Knowledge fusion
The relationship between information units after information extraction is flat , Lack of hierarchy and logicality , At the same time, there are a lot of redundant and even wrong information fragments . Knowledge fusion aims to solve how to fuse multi-source description information about the same entity or concept , Integrate knowledge from multiple knowledge bases , The process of forming a knowledge base . Common problems in knowledge fusion are data quality : The naming is vague , Data input error , Inconsistent data format , Abbreviation problem . In the process , The main key technologies include anaphora resolution 、 Entity disambiguation 、 Entity link .
1.1 Anaphora digestion
(1) Explicit pronoun resolution , It refers to the current anaphora and the words appearing in the context 、 A phrase or sentence ( Sentence group ) There is close semantic relevance , Anaphora depends on context semantics , It may refer to different entities in different language environments , It has asymmetry and non transitivity .
(2) Zero pronoun resolution , It is the process of restoring zero pronoun to refer to the antecedent linguistic unit , Sometimes it is also called ellipsis recovery .
(3) Co refers to digestion
It mainly refers to two nouns ( Including pronouns 、 noun phrase ) Point to the same reference in the real world . Multi source heterogeneous data is in the process of integration , There is usually a phenomenon that a real world entity corresponds to multiple representations , The reason for this phenomenon may be : Spelling mistakes 、 Different naming rules 、 Name variants 、 Abbreviations, etc . This phenomenon will lead to a large amount of redundant data in the integrated data 、 Inconsistent data and other issues , Thus, the quality of integrated data is reduced , Then it affects the results of analysis and mining based on the integrated data . The problem of distinguishing whether multiple entity representations correspond to the same entity is entity unification . Such as the phenomenon of duplicate names , Nanjing University of Aeronautics and Astronautics ( China Southern Airlines )
1.1.1 Solutions to anaphora resolution
(1) Based on the method of mixing the two

(2) Pattern matching
Pattern matching is mainly to find the mapping relationship between attributes in different associated data sources , It mainly solves the conflict between predicates in triples ; Another explanation : Solve the problem that different associated data sources adopt different identifiers for the same attribute , So as to realize the integration of heterogeneous data sources

(3) Object conflict resolution
Object conflict resolution is to solve the problem of object inconsistency in multi-source related data .
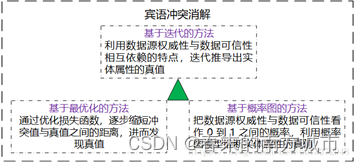
1.2 Entity disambiguation
The essence of entity disambiguation is that a word has many possible meanings , That is, the meanings expressed in different contexts are different . Such as : My mobile phone is apple . I like apples . According to the different fields of entity disambiguation task , Entity disambiguation system can be divided into :
Text type | Disambiguation method |
Structured text | The entity referent is represented as a structured text record , Such as list list 、 Knowledge base, etc ; Lack of context , It mainly relies on string comparison and entity relationship information to complete disambiguation ; |
Unstructured text | The entity referent is represented as an unstructured text ; There are a lot of contexts , It mainly uses the referential context and background knowledge to complete disambiguation . Common methods : Entity disambiguation based on clustering 、 Entity disambiguation based on entity link . |
1.2.1 Methods to solve entity disambiguation
(1) Dictionary based word sense disambiguation
The early representative work of dictionary based word sense disambiguation method is Lesk On 1986 The job of . Given a word to be resolved and its context , The idea of this work is to calculate the coverage between the definition of each word meaning and the context in the semantic dictionary , Choose the word with the largest coverage as the correct word meaning of the word to be resolved in its context . However, the definition of word meaning in dictionaries is usually concise , This results in a coverage of 0, The disambiguation performance is not high .
(2) Supervised word sense disambiguation
Supervised disambiguation method uses word meaning tagging corpus to establish disambiguation model , The research focuses on the representation of features . Common contextual features can be summarized into three types :
1. Lexical features usually refer to the words and their parts of speech appearing in the upper and lower windows of the words to be resolved ;
2. Syntactic features use the syntactic relationship characteristics of the word to be resolved in the context , Ru Dong - Guest Relations 、 With master or not / The object 、 Lord / Object chunk type 、 Lord / Object headword, etc ;
3. Semantic features add semantic information on the basis of syntactic relations , As the Lord / The semantic category of the object headword , It can even be semantic role annotation class information .
(3) Unsupervised and semi supervised word sense disambiguation
Although supervised disambiguation methods can achieve better disambiguation performance , But it needs a lot of manual tagging corpus , laborious . In order to overcome the need for large-scale corpus , Semi supervised or unsupervised methods require only a small amount or no manual annotation of the corpus . As a general rule , Although semi supervised or unsupervised methods do not require a lot of manual annotation data , But it depends on a large-scale unmarked corpus , And the result of syntactic analysis on the corpus .
1.3 Entity link (Entity Linking)
Entity link (entity linking) For unstructured data ( Text ) Or semi-structured data ( Such as the table ) Entity objects extracted from , The operation of linking it to the corresponding correct entity object in the knowledge base . Its basic idea is first according to the given entity reference , Select a set of candidate entity objects from the knowledge base , Then the reference item is linked to the correct entity object by similarity calculation , Through the scoring method, the entity with the highest referential item is regarded as the target entity .
The input of entity link includes two parts :
(1) Target entity knowledge base : Knowledge base usually includes : Entity table 、 Text description of the entity 、 Structured information of entities ( attribute / Attribute value pairs )、 Auxiliary information of the entity ( Entity category ); It also often provides additional structured semantic information ( Association between entities ).
(2) Entity references to be disambiguated and their context information .
1.3.1 Methods to realize entity linking
(1) Vector space model
Based on the co-occurrence information of features in the context of entity referent and target entity . Vector representation extracts effective feature representation , Effectively calculate the similarity between vectors .
(2) Theme consistency model
The degree of consistency between the candidate entity concept of the entity referent and other entity concepts in the context of the referent
(3) Collaborative entity link
The above only deals with the link problem of a single entity reference , The relationship between the target entities of all entity references in a single document is ignored . Collaborative linking of all entity references in the document helps to improve the performance of entity linking .
2 Common processes and steps of knowledge fusion
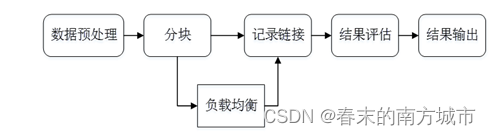
2.1 Data preprocessing
Data preprocessing stage , The quality of the original data will directly affect the final link result , Different data sets often describe the same entity in different ways , Normalizing these data is an important step to improve the accuracy of subsequent links . Commonly used data preprocessing are :
Grammar normalization :
Grammar matching : For example, telephone contact
Comprehensive attributes : Such as the expression of home address
Data normalization :
Remove spaces 、《》、“”、- Equisign
Topology error of input error class
Replace nicknames and abbreviations with official names
2.2 Block (Blocking)
From all entity pairs in a given knowledge base , Select potential matching record pairs as candidates , And reduce the size of candidates as much as possible . The reason for this is that there is too much data to connect one by one . The commonly used blocking methods are based on Hash Chunking of functions 、 Adjacent blocks, etc .
2.3 Load balancing
Load balancing (Load Balance) To ensure that the number of entities in all blocks is equal , So as to ensure the improvement of performance by blocking . The easiest way is to do it many times Map-Reduce operation .
2.4 Record Links
Suppose the records of two entities x and y, x and y In the i The value of each attribute is <script type = "math/tex" id="MathJax-Element-8">x_i, y_i</script>, Then record the connection through the following two steps :
Attribute similarity : The attribute similarity vector is obtained by synthesizing the similarity of a single attribute :
Entity similarity : The similarity of an entity is obtained according to the attribute similarity vector .
2.4.1 Calculation of attribute similarity
There are many ways to calculate attribute similarity , Commonly used are editing distance 、 Set similarity calculation 、 Vector based similarity calculation .
(1) Edit distance : Levenstein、 Wagner and Fisher、 Edit Distance with Afine Gaps
(2) Set similarity calculation : Jaccard coefficient , Dice
(3) Similarity calculation based on vector : Cosine Similarity degree 、TFIDF Similarity degree
2.4.2 Calculation of entity similarity
Use clustering methods such as hierarchical clustering , Correlation Clustering ,Canopy+k-means, Use aggregation methods such as weighted average , Make rules manually , Classifiers, etc , We can also use knowledge representation learning methods, such as joint knowledge embedding method .
(1) Aggregation based approach :
1) weighted mean : Weighted sum each component of the similarity score vector , Get the final entity similarity
2) Make rules manually : Set a threshold for each component of the similarity vector , If the threshold is exceeded, the two entities are connected
3) classifier : Use unsupervised / Semi supervised training generates training set classification
(2) Clustering based methods :
1) Hierarchical clustering : By calculating the similarity between different types of data points, the data at different levels are divided , Finally, a tree like clustering structure is formed .
2) Correlation Clustering : Find a clustering scheme with the least cost .
3)Canopy + K-means: No need to specify in advance K Values are clustered
(3) The method of learning based on knowledge representation
Map the entities and relationships in the knowledge map to low dimensional space vectors , Directly use mathematical expressions to calculate the similarity between entities . Such methods do not rely on any text information , What we get is the depth characteristics of the data . If joint knowledge is used to embed two KG The triples of are mixed together to train together , And treat the pre linked entity pair as having SameAS The triplet of relations , So for two KG Space to constrain , With parameter sharing and soft alignment TransE Realization
3. Knowledge fusion practice
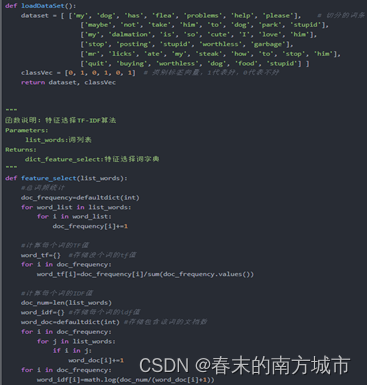
3.1TF-IDF(Term Frequency-inverse Document Frequency)
TF-IDF It is a statistical analysis method for keywords , Used to evaluate the importance of a word to a file set or corpus . The importance of a word is directly proportional to the number of times it appears in the article , It is inversely proportional to the number of times it appears in the corpus . This calculation method can effectively avoid the influence of common words on keywords , Improve the relevance between keywords and articles .

![]()
3.2 De duplicate entities and related information .
Data sets :example_input_with_true_ids.csv;example_messy_input.csv

The label is True Id, Characterized by :Sitename, Address, Zip, Phone.
As marked above Id No. gives relevant information . The first message corresponds to the above Id=0 The sample of .

Judge the selected features , Generate results after running :

In the prediction results , Duplicate data ID Forecast No. is the same .
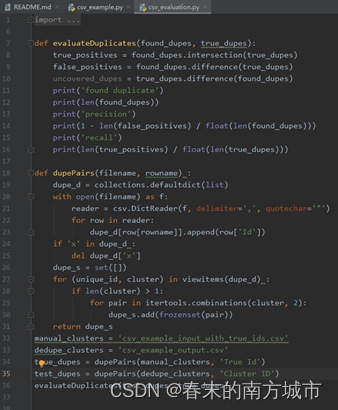
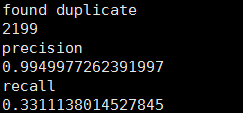
Model to predict : Calculate the accuracy and regression rate by calculating the number of intersection and difference sets between the predicted value and the real value . This example has 2199 Duplicate samples , Accuracy rate is 0.9949977%, The regression rate is 0.33.
3.3 Knowledge Links ( Connect two different data sets ),
use Cosine similarity measurement principle Compare text type fields .
requirement : Each of the two datasets to be connected should not contain duplicate datasets . Records from the first dataset can match only one record from the second dataset or do not match , That is, it either does not match or can only match one , So if there is duplicate data under a data set .
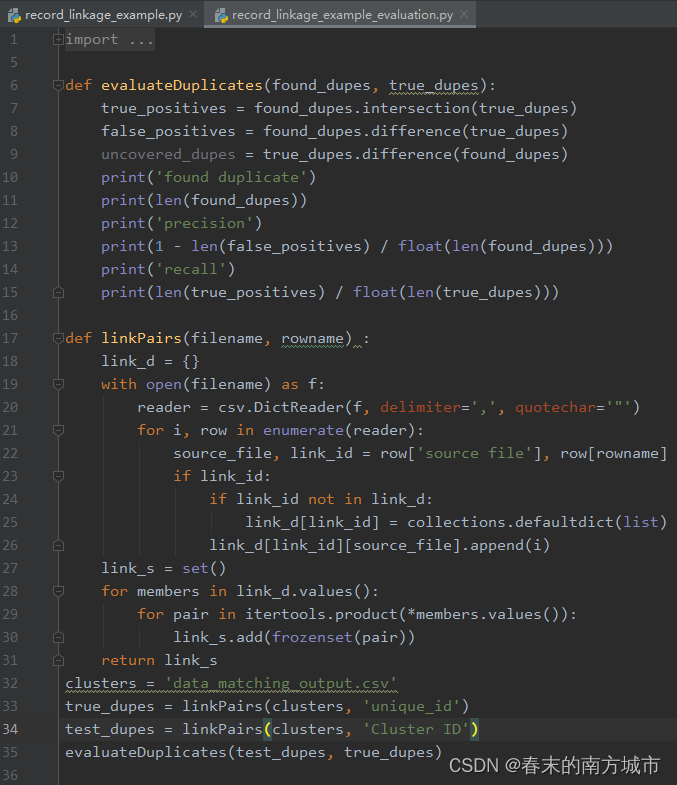
Data sets :AbtBuy_Abt.csv,AbtBuy_Buy.csv, Same format , Both contain four fields .unique_id, title, description, price. Unique_id The meaning is whether two samples are one sample , if Unique_id It's the same .


The function of the code is to judge whether this sample pair from two tables is the same identification . In the table Text Type data , This method uses cosine similarity measure to compare text type fields . This is a measure of the number of words shared by the two files . Because the overlap of rare words is more important than that of ordinary words , So this method can be more useful . You can also learn weights according to the corpus in different scenes .
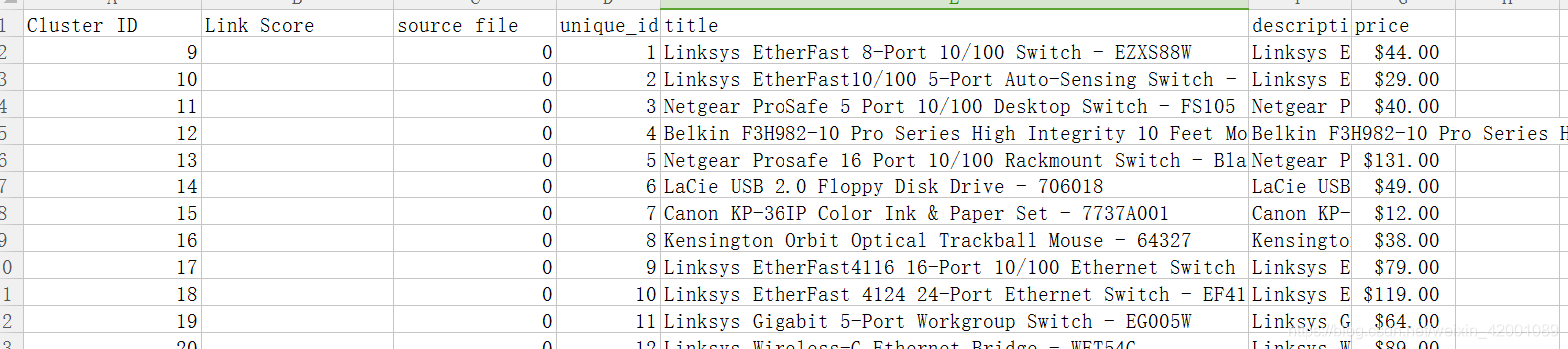
The final prediction result :
Cluster ID: Whether it belongs to the same knowledge
source file: The source of the dataset , If it comes from the first csv by 0, Otherwise 1.
unique_id: Is the original csv Medium unique_id
Model evaluation :
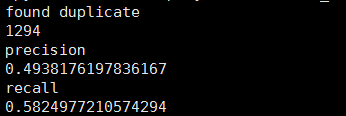
Indicates that there are 1294 Samples belong to the same identification .
3.4 disambiguate
person_id : It means human id
Lat Lng: The address of the inventor ( Longitude and latitude )
Coauthor: Co-author.
Name: Inventor's name
Class: On the patent assigned to the inventor 4 digit ipc Technical code

if person_id Of leuven_id The same means the same kind

result :( After disambiguation )

3.5 be based on Silk Knowledge fusion
Silk Is an open source framework for integrating heterogeneous data sources . The programming language is Python. A special Silk-LSL Language for specific processing . Provides a graphical user interface Silk Workbench, Users can easily record links .Silk The overall framework of is shown in the figure below :
Silk install , Implementation introduction
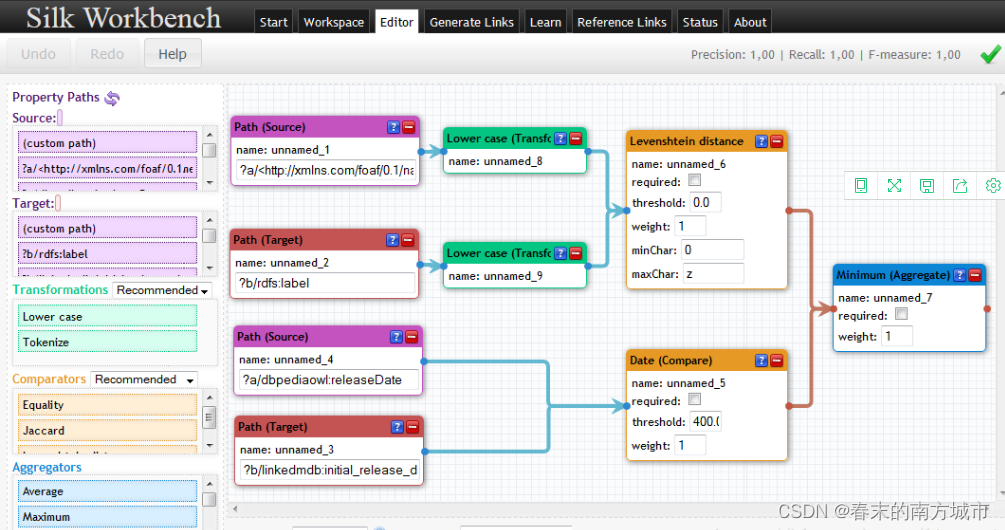
Workbench Guide users to complete the process of creating links , To link two data sources . It provides the following components : work area (workspace) browser : Allow users to browse items in the workspace . Link tasks can be loaded from the project and returned later . Link rule editor (Linkage Rule Editor): A graphic editor , Make it easy for users to create and edit link rules . The widget will display the current link specification in the tree view , You can also use drag and drop to edit . assessment (Evaluation): Allow users to execute current link rules . These links will be displayed when they are generated instantly . The generated link reference link set does not specify its correctness , Users can confirm or reject its correctness . Users can request a detailed summary of how to compose the similarity score of a particular link .
3.6 Use Dedupe Package implements entity matching
dedupe It's a python package , It plays an important role in the field of knowledge fusion ! It is mainly used for entity matching .dedupe Is a fuzzy matching, record deduplication and entity-resolution Of python library . It's based on active learing Methods , The user only needs to mark the small amount of data it selects in the calculation process , Can effectively train a compound blocking Methods and record Calculation method of similarity between , And complete the matching through clustering .dedupe Support a variety of flexible data types and user-defined types .
Knowledge fusion -Dedupe Introduction link
dedupe The paper :http://www.cs.utexas.edu/~ml/papers/marlin-dissertation-06.pdf
dedupe Source code :https://github.com/dedupeio/dedupe
dedupe demo: GitHub - dedupeio/dedupe-examples: Examples for using the dedupe library
dedupe Chinese website :dedupe: Knowledge Links python library - Tools - Open knowledge map
dedupe Official website :Dedupe 2.0.11 — dedupe 2.0.11 documentation
dedupe API explain :Library Documentation — dedupe 2.0.11 documentation
3.7 Real example practice
3.7.1 De duplicate entities and related information .
Data sets :example_input_with_true_ids.csv;example_messy_input.csv
The label is True Id, Characterized by :Sitename, Address, Zip, Phone.
As marked above Id No. gives relevant information .
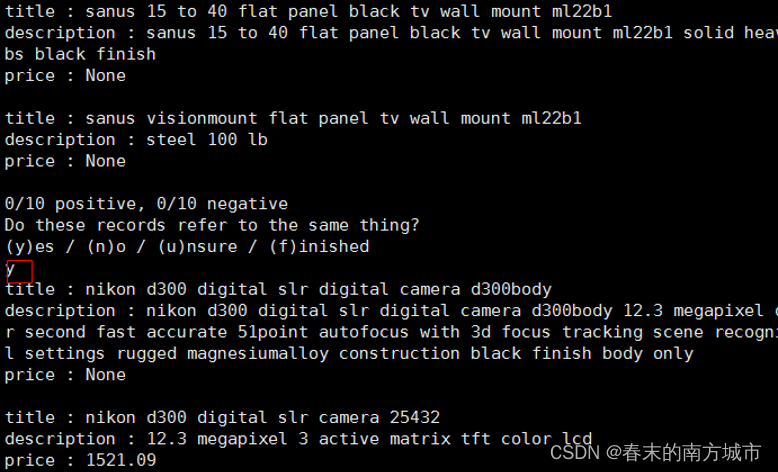
In operation , Print out the samples that cannot be judged and let the manual judge ,3 The result is y( It's repetition ),n( Not repeat ),u( Not sure ).

In the prediction results , Duplicate data ID Forecast No. is the same .
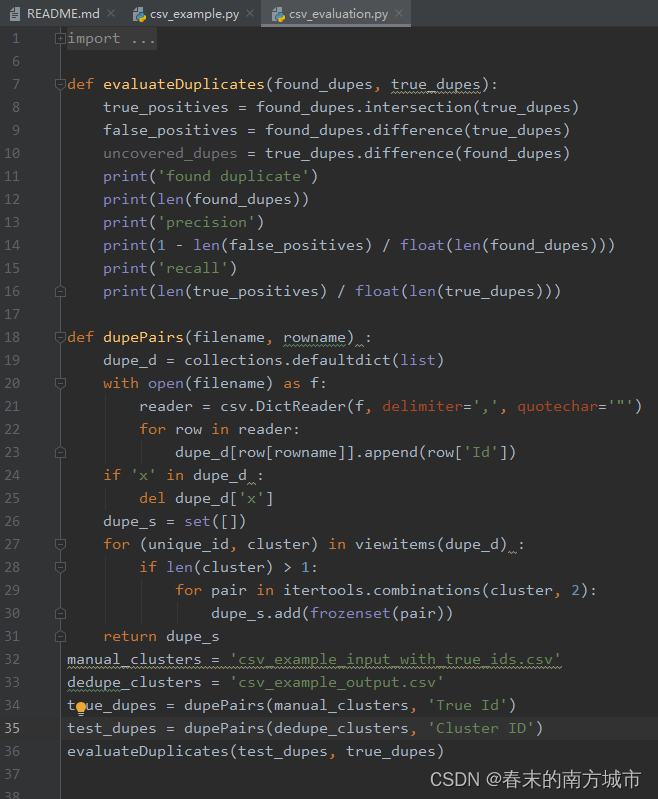
Model to predict : Calculate the accuracy and regression rate by calculating the number of intersection and difference sets between the predicted value and the real value . This example has 2199 Duplicate samples , Accuracy rate is 0.9949977%, The regression rate is 0.33.
3.7.2 Knowledge Links
Connect two different data sets , Use cosine similarity measure to compare text type fields , Cosine similarity measurement principle
requirement : Each of the two datasets to be connected should not contain duplicate datasets . Records from the first dataset can match only one record from the second dataset or do not match , That is, it either does not match or can only match one , So if there is duplicate data under a data set .
Data sets :AbtBuy_Abt.csv,AbtBuy_Buy.csv, Same format , Both contain four fields .unique_id, title, description, price.

The function of the code is to judge whether this sample pair from two tables is the same identification .
The final prediction result :
Cluster ID: Whether it belongs to the same knowledge
source file: The source of the dataset , If it comes from the first csv by 0, Otherwise 1.
unique_id: Is the original csv Medium unique_id
Model evaluation :
Indicates that there are 1294 Samples belong to the same identification .
3.7.3 disambiguate
person_id : It means human id
Lat Lng: The address of the inventor ( Longitude and latitude )
Coauthor: Co-author.
Name: Inventor's name
Class: On the patent assigned to the inventor 4 digit ipc Technical code
if person_id and leuven_id The same means the same kind
result :( After disambiguation )
summary : be based on dedupe Related examples of , Essentially, it is to remove repetition , Compare samples through various data types , Calculate similarity , Then cluster , To gather duplicate data into the same category , Achieve the goal of weight removal .
边栏推荐
- 2022 refrigeration and air conditioning equipment installation and repair examination contents and new version of refrigeration and air conditioning equipment installation and repair examination quest
- Review questions of anatomy and physiology · VIII blood system
- Why do novices often fail to answer questions in the programming community, and even get ridiculed?
- BUUCTF---Reverse---easyre
- [network planning] Chapter 3 data link layer (3) channel division medium access control
- [weekly pit] information encryption + [answer] positive integer factorization prime factor
- PowerPivot - DAX (first time)
- 报错分析~csdn反弹shell报错
- In line elements are transformed into block level elements, and display transformation and implicit transformation
- Number of schemes from the upper left corner to the lower right corner of the chessboard (2)
猜你喜欢

棋盘左上角到右下角方案数(2)

Introduction of Xia Zhigang
Jupyter launch didn't respond after Anaconda was installed & the web page was opened and ran without execution
Tencent architects first, 2022 Android interview written examination summary

数字三角形模型 AcWing 1018. 最低通行费
Special topic of rotor position estimation of permanent magnet synchronous motor -- fundamental wave model and rotor position angle

Comment faire une radio personnalisée
Common doubts about the introduction of APS by enterprises

【每周一坑】正整数分解质因数 +【解答】计算100以内质数之和
5. Wireless in vivo nano network: top ten "feasible?" problem
随机推荐
深度学习分类网络 -- ZFNet
Cesium Click to draw a circle (dynamically draw a circle)
Value of APS application in food industry
rt-thread i2c 使用教程
Basic knowledge of lists
Appx code signing Guide
Groovy basic syntax collation
JS get browser system language
2022 Guangdong Provincial Safety Officer C certificate third batch (full-time safety production management personnel) simulation examination and Guangdong Provincial Safety Officer C certificate third
I've seen many tutorials, but I still can't write a program well. How can I break it?
Special topic of rotor position estimation of permanent magnet synchronous motor -- Summary of position estimation of fundamental wave model
SSO single sign on
Web security - payload
Detailed introduction of distributed pressure measurement system VIII: basic introduction of akka actor model
In line elements are transformed into block level elements, and display transformation and implicit transformation
Core principles of video games
【每周一坑】计算100以内质数之和 +【解答】输出三角形
Anaconda安装后Jupyter launch 没反应&网页打开运行没执行
(工作记录)2020年3月11日至2021年3月15日
Initial experience of addresssanitizer Technology