当前位置:网站首页>【深度学习】PyTorch 1.12发布,正式支持苹果M1芯片GPU加速,修复众多Bug
【深度学习】PyTorch 1.12发布,正式支持苹果M1芯片GPU加速,修复众多Bug
2022-07-06 12:51:00 【风度78】

机器之心报道
PyTorch 1.12 正式发布,还没有更新的小伙伴可以更新了。
距离 PyTorch 1.11 推出没几个月,PyTorch 1.12 就来了!此版本由 1.11 版本以来的 3124 多次 commits 组成,由 433 位贡献者完成。1.12 版本进行了重大改进,并修复了很多 Bug。
随着新版本的发布,大家讨论最多的可能就是 PyTorch 1.12 支持苹果 M1 芯片。
其实早在今年 5 月,PyTorch 官方就已经宣布正式支持在 M1 版本的 Mac 上进行 GPU 加速的 PyTorch 机器学习模型训练。此前,Mac 上的 PyTorch 训练仅能利用 CPU,但随着 PyTorch 1.12 版本的发布,开发和研究人员可以利用苹果 GPU 大幅度加快模型训练。
在 Mac 上引入加速 PyTorch 训练
PyTorch GPU 训练加速是使用苹果 Metal Performance Shaders (MPS) 作为后端来实现的。MPS 后端扩展了 PyTorch 框架,提供了在 Mac 上设置和运行操作的脚本和功能。MPS 使用针对每个 Metal GPU 系列的独特特性进行微调的内核能力来优化计算性能。新设备将机器学习计算图和原语映射到 MPS Graph 框架和 MPS 提供的调整内核上。
每台搭载苹果自研芯片的 Mac 都有着统一的内存架构,让 GPU 可以直接访问完整的内存存储。PyTorch 官方表示,这使得 Mac 成为机器学习的绝佳平台,让用户能够在本地训练更大的网络或批大小。这降低了与基于云算力的开发相关的成本或对额外的本地 GPU 算力需求。统一内存架构还减少了数据检索延迟,提高了端到端性能。
可以看到,与 CPU 基线相比,GPU 加速实现了成倍的训练性能提升:
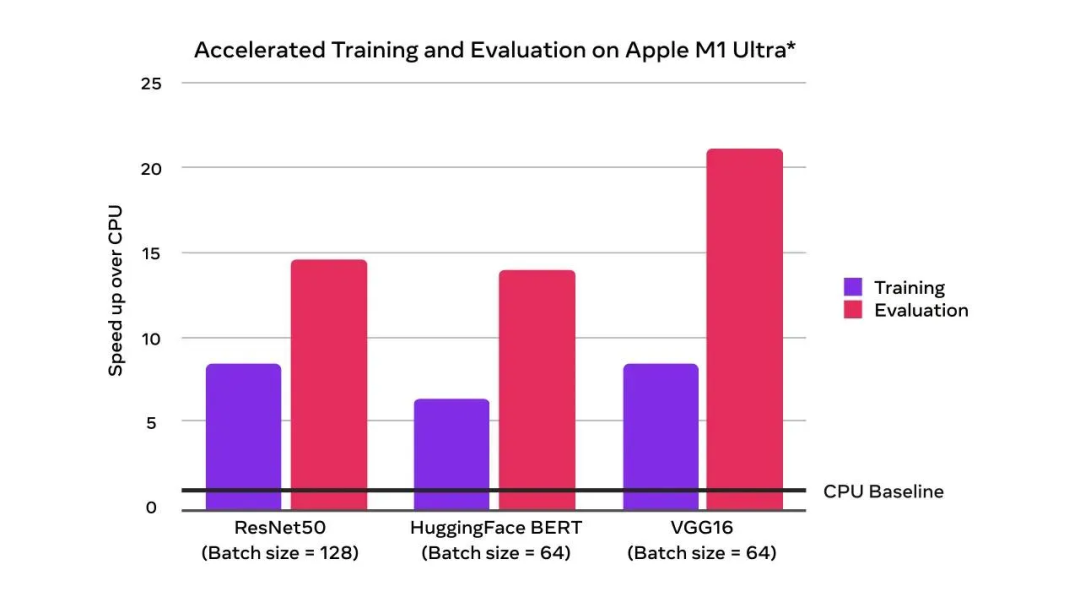
有了 GPU 的加持,训练和评估速度超过 CPU
上图是苹果于 2022 年 4 月使用配备 Apple M1 Ultra(20 核 CPU、64 核 GPU)128GB 内存,2TB SSD 的 Mac Studio 系统进行测试的结果。测试模型为 ResNet50(batch size = 128)、HuggingFace BERT(batch size = 64)和 VGG16(batch size = 64)。性能测试是使用特定的计算机系统进行的,反映了 Mac Studio 的大致性能。
PyTorch 1.12 其他新特性
前端 API:TorchArrow
PyTorch 官方已经发布了一个新的 Beta 版本供用户试用:TorchArrow。这是一个机器学习预处理库,可进行批量数据处理。它具有高性能,兼具 Pandas 风格,还具有易于使用的 API,以加快用户预处理工作流程和开发。
(Beta)PyTorch 中的 Complex32 和 Complex Convolutions
目前,PyTorch 原生支持复数、复数 autograd、复数模块和大量的复数运算(线性代数和快速傅里叶变换)。在包括 torchaudio 和 ESPNet 在内的许多库中,都已经使用了复数,并且 PyTorch 1.12 通过复数卷积和实验性 complex32 数据类型进一步扩展了复数功能,该数据类型支持半精度 FFT 操作。由于 CUDA 11.3 包中存在 bug,如果用户想要使用复数,官方建议使用 CUDA 11.6 包。
(Beta)Forward-mode 自动微分
Forward-mode AD 允许在前向传递中计算方向导数(或等效地雅可比向量积)。PyTorch 1.12 显着提高了 forward-mode AD 的覆盖范围。
BetterTransformer
PyTorch 现在支持多个 CPU 和 GPU fastpath 实现(BetterTransformer),也就是 Transformer 编码器模块,包括 TransformerEncoder、TransformerEncoderLayer 和 MultiHeadAttention (MHA) 的实现。在新的版本中,BetterTransformer 在许多常见场景中速度快 2 倍,这还要取决于模型和输入特征。新版本 API 支持与先前的 PyTorch Transformer API 兼容,如果现有模型满足 fastpath 执行要求,它们将加速现有模型,以及读取使用先前版本 PyTorch 训练的模型。
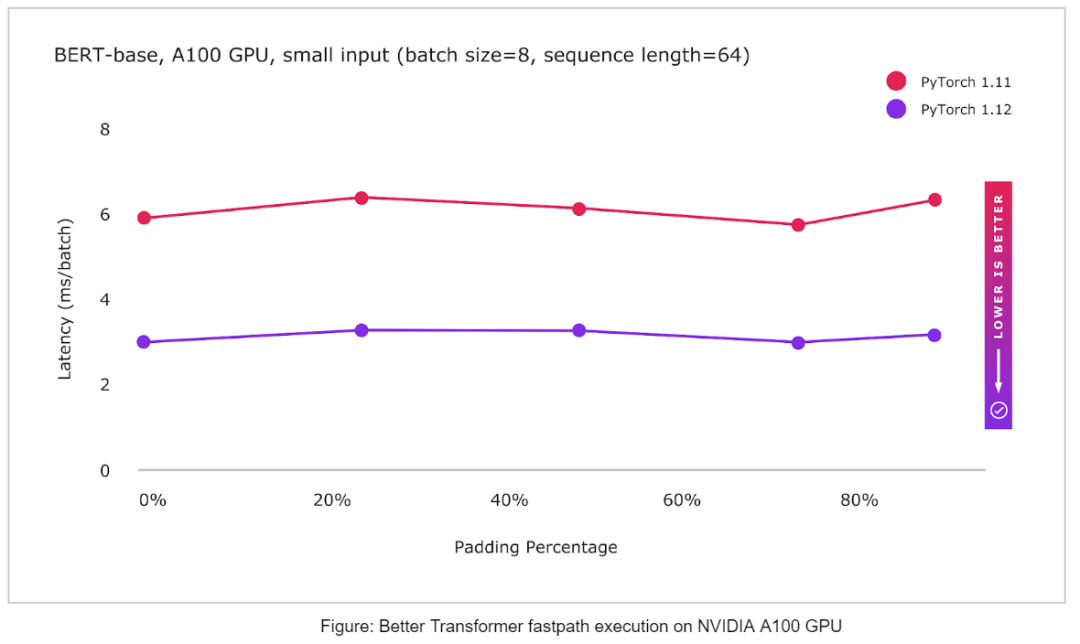
此外,新版本还有一些更新:
模块:模块计算的一个新 beta 特性是功能性 API。这个新的 functional_call() API 让用户可以完全控制模块计算中使用的参数;
TorchData:DataPipe 改进了与 DataLoader 的兼容性。PyTorch 现在支持基于 AWSSDK 的 DataPipes。DataLoader2 已被引入作为管理 DataPipes 与其他 API 和后端之间交互的一种方式;
nvFuser: nvFuser 是新的、更快的默认 fuser,用于编译到 CUDA 设备;
矩阵乘法精度:默认情况下,float32 数据类型上的矩阵乘法现在将在全精度模式下工作,这种模式速度较慢,但会产生更一致的结果;
Bfloat16:为不太精确的数据类型提供了更快的计算时间,因此在 1.12 中对 Bfloat16 数据类型进行了新的改进;
FSDP API:作为原型在 1.11 版中发布,FSDP API 在 1.12 版的发布中达到了测试版,并添加了一些改进。
更多内容请查看:https://pytorch.org/blog/pytorch-1.12-released/

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载中国大学慕课《机器学习》(黄海广主讲)机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码
边栏推荐
- 监控界的最强王者,没有之一!
- No Yum source to install SPuG monitoring
- 7、数据权限注解
- What is the problem with the SQL group by statement
- Math symbols in lists
- Value of APS application in food industry
- 过程化sql在定义变量上与c语言中的变量定义有什么区别
- What are RDB and AOF
- [diy] how to make a personalized radio
- [diy] self designed Microsoft makecode arcade, official open source software and hardware
猜你喜欢
Distributed ID

防火墙基础之外网服务器区部署和双机热备
OAI 5g nr+usrp b210 installation and construction

Variable star --- article module (1)
OAI 5G NR+USRP B210安装搭建
![[200 opencv routines] 220 Mosaic the image](/img/75/0293e10ad6de7ed86df4cacbd79b54.png)
[200 opencv routines] 220 Mosaic the image

2022 Guangdong Provincial Safety Officer C certificate third batch (full-time safety production management personnel) simulation examination and Guangdong Provincial Safety Officer C certificate third

OLED屏幕的使用
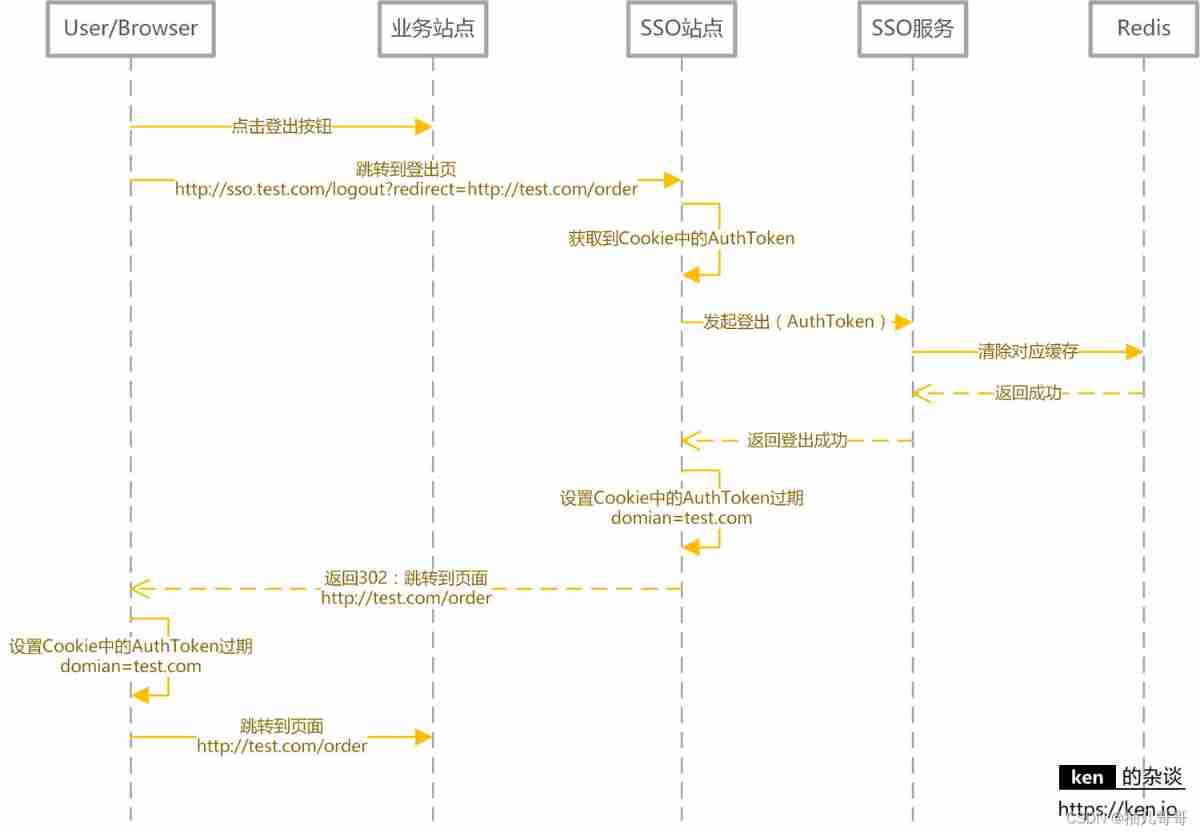
SSO single sign on
Value of APS application in food industry
随机推荐
APS taps home appliance industry into new growth points
Huawei device command
No Yum source to install SPuG monitoring
PHP online examination system version 4.0 source code computer + mobile terminal
[DSP] [Part 2] understand c6678 and create project
防火墙基础之外网服务器区部署和双机热备
OLED屏幕的使用
OAI 5G NR+USRP B210安装搭建
New database, multidimensional table platform inventory note, flowus, airtable, seatable, Vig table Vika, Feishu multidimensional table, heipayun, Zhixin information, YuQue
#yyds干货盘点#重新梳理箭头函数的this
use. Net analysis Net talent challenge participation
What is the problem with the SQL group by statement
Opencv learning example code 3.2.3 image binarization
Data Lake (VIII): Iceberg data storage format
(work record) March 11, 2020 to March 15, 2021
1_ Introduction to go language
PG basics -- Logical Structure Management (transaction)
I've seen many tutorials, but I still can't write a program well. How can I break it?
【微信小程序】运行机制和更新机制
Redis insert data garbled solution