当前位置:网站首页>Aiko ai Frontier promotion (7.6)
Aiko ai Frontier promotion (7.6)
2022-07-06 21:03:00 【Communauté des sages】
LG - Apprentissage automatique CV - Vision par ordinateur CL - Calcul et langue AS - Audio et voix RO - Robot
De l'amour à la belle vie
Résumé:Prédiction de la performance de dérive distribuée du réseau neuronal、Justification du Modèle linguistique intégration accrue、Système recommandé avec une garantie de fiabilité non distribuée、Déballage des effets aléatoires et cycliques des séquences photographiques retardées、Formation à l'algorithme itératif d'amincissement basé sur la différence implicite、Aperçu des nouveaux domaines interdisciplinaires de la robotique biologique、Grâce à l'optimisation distribuée, le robot Multi - membres peut grimper librement tout en touchant la capture et le mouvement riches、Robot d'escalade quadripode robuste et polyvalent、Étiquettes et champs de rayonnement d'objets textuels
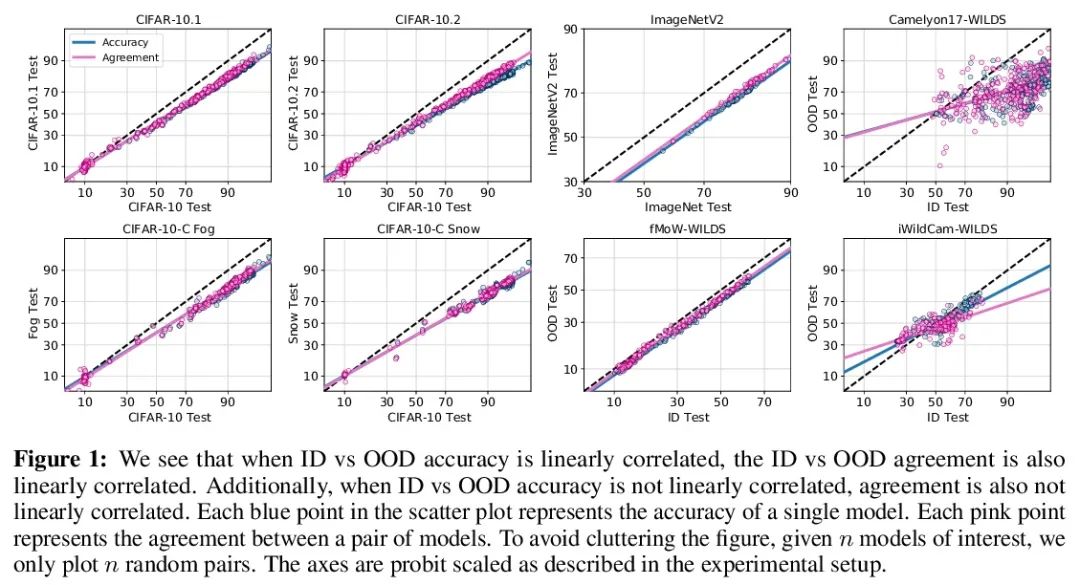
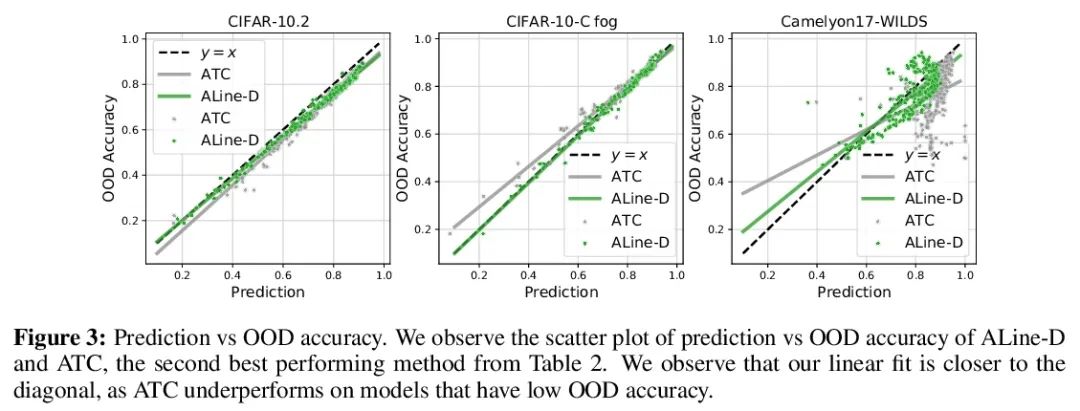
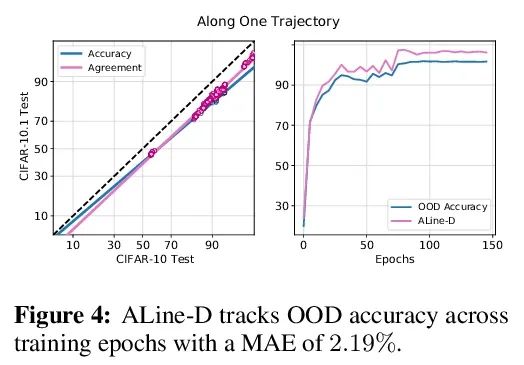
1、[LG] Agreement-on-the-Line: Predicting the Performance of Neural Networks under Distribution Shift
C Baek, Y Jiang, A Raghunathan, Z Kolter
[CMU]
Agreement-on-the-Line:Prédiction de la performance de dérive distribuée du réseau neuronal.Récemment,MillerEt al.,Dans la distribution d'un modèle(ID)La précision est comparable à celle de plusieursOODEn dehors de la distribution sur la base de référence(OOD)La précision a une forte corrélation linéaire——Ils appellent ce phénomène"Précision en ligne(accuracy-on-the-line)".Bien qu'il s'agisse d'un outil utile pour choisir un modèle( C'est - à - dire qu'il est le plus susceptible de montrer le meilleur OOD Le modèle de IDModèle de précision), Mais ce fait n'aide pas à estimer la réalité du modèle OODPerformance, Parce qu'aucune annotation n'a été obtenue OODEnsemble de validation. Cet article montre un phénomène similaire mais surprenant , C'est - à - dire que la cohérence entre les paires de classificateurs de réseaux neuronaux est également établie. :Peu importe.accuracy-on-the-lineOui Non, Deux réseaux neuronaux arbitraires ont été observés ( Avec des architectures potentiellement différentes ) Interprévisionnel OOD La cohérence avec leurs ID La cohérence est fortement linéaire .En outre,Nous avons observé,OOD vs ID La pente et l'écart constants par rapport à OOD vs ID La précision de .Ce phénomène, Appelez ça la cohérence en ligne (agreement-on-the-line), A une importance pratique importante : En l'absence de données dimensionnelles , On peut prédire le classificateur OODPrécision,Parce queOOD La cohérence peut être estimée à l'aide de données non marquées . L'algorithme de prédiction est agreement-on-the-line Dérive établie , Et étonnamment , Si la précision n'est pas en ligne , Est supérieur à la méthode précédente . Ce phénomène est également Réseau neuronal profond Offre de nouvelles perspectives :Avecaccuracy-on-the-lineC'est différent.,agreement-on-the-line Ça ne semble fonctionner que pour les classificateurs de réseaux neuronaux .
Recently, Miller et al. [56] showed that a model’s in-distribution (ID) accuracy has a strong linear correlation with its out-of-distribution (OOD) accuracy on several OOD benchmarks — a phenomenon they dubbed “accuracy-on-the-line”. While a useful tool for model selection (i.e., the model most likely to perform the best OOD is the one with highest ID accuracy), this fact does not help estimate the actual OOD performance of models without access to a labeled OOD validation set. In this paper, we show a similar but surprising phenomenon also holds for the agreement between pairs of neural network classifiers: whenever accuracyon-the-line holds, we observe that the OOD agreement between the predictions of any two pairs of neural networks (with potentially different architectures) also observes a strong linear correlation with their ID agreement. Furthermore, we observe that the slope and bias of OOD vs ID agreement closely matches that of OOD vs ID accuracy. This phenomenon, which we call agreement-on-the-line, has important practical applications: without any labeled data, we can predict the OOD accuracy of classifiers, since OOD agreement can be estimated with just unlabeled data. Our prediction algorithm outperforms previous methods both in shifts where agreement-on-the-line holds and, surprisingly, when accuracy is not on the line. This phenomenon also provides new insights into deep neural networks: unlike accuracy-on-the-line, agreement-on-the-line appears to only hold for neural network classifiers.
https://arxiv.org/abs/2206.13089


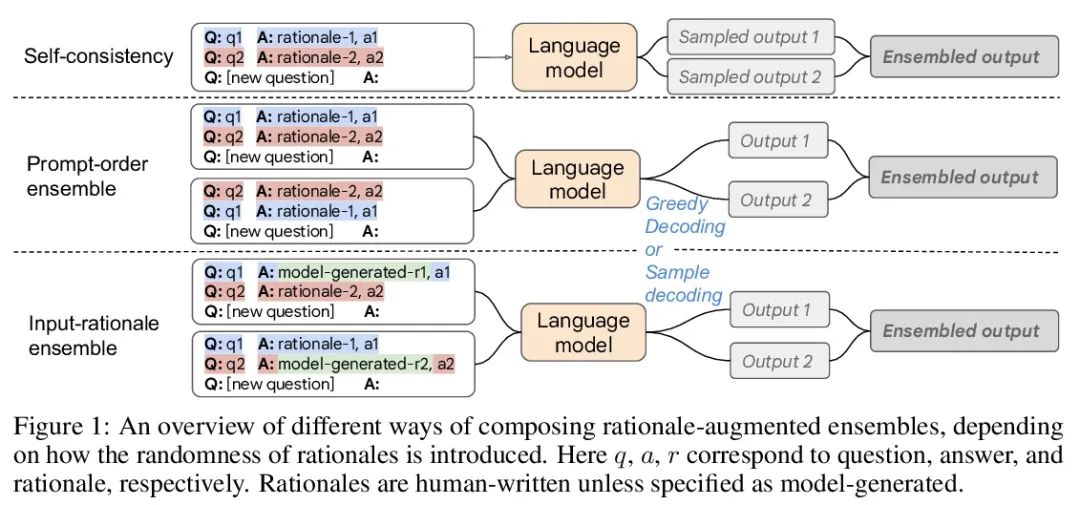
2、[CL] Rationale-Augmented Ensembles in Language Models
X Wang, J Wei, D Schuurmans, Q Le, E Chi, D Zhou
[Google Research]
Justification du Modèle linguistique intégration accrue.Des études récentes ont montré que,Justification, Ou une chaîne de pensée étape par étape , Peut être utilisé pour améliorer la performance des tâches de raisonnement en plusieurs étapes . Dans cet article, nous examinons à nouveau la façon de suggérer l'amélioration rationnelle , Pour l'apprentissage contextuel de petits échantillons ,Parmi eux(Entrée→Produits) L'invite est étendue à (Entrée、Justification→Produits)Conseils. Conseils pour l'amélioration de la raison , Il est prouvé que les méthodes existantes, qui reposent sur l'ingénierie manuelle, sont soumises à des raisons sous - optimales qui peuvent nuire au rendement. . Pour atténuer cette fragilité , Cet article présente un cadre d'intégration amélioré fondé sur une justification unifiée , Identifier l'échantillonnage des motifs dans l'espace de sortie comme un élément clé d'une amélioration robuste du rendement . Le cadre est générique , Peut être facilement étendu aux tâches communes de traitement du langage naturel , Même les tâches qui n'utilisent pas traditionnellement les étapes intermédiaires ,Comme Q & A、 Désambiguation sémantique et analyse émotionnelle . Avec les méthodes de pointe existantes —— Comprend des conseils standard non justifiés et des conseils de chaîne de pensée fondés sur des motifs ——Comparé à, Justification une meilleure intégration permet d'obtenir des résultats plus précis et plus interprétables , Entre - temps, l'interprétation des prévisions du modèle est améliorée par des raisons connexes. .
Recent research has shown that rationales, or step-by-step chains of thought, can be used to improve performance in multi-step reasoning tasks. We reconsider rationale-augmented prompting for few-shot in-context learning, where (input → output) prompts are expanded to (input, rationale → output) prompts. For rationale-augmented prompting we demonstrate how existing approaches, which rely on manual prompt engineering, are subject to sub-optimal rationales that may harm performance. To mitigate this brittleness, we propose a unified framework of rationale-augmented ensembles, where we identify rationale sampling in the output space as the key component to robustly improve performance. This framework is general and can easily be extended to common natural language processing tasks, even those that do not traditionally leverage intermediate steps, such as question answering, word sense disambiguation, and sentiment analysis. We demonstrate that rationale-augmented ensembles achieve more accurate and interpretable results than existing prompting approaches—including standard prompting without rationales and rationale-based chain-of-thought prompting—while simultaneously improving interpretability of model predictions through the associated rationales.
https://arxiv.org/abs/2207.00747



3、[IR] Recommendation Systems with Distribution-Free Reliability Guarantees
A N. Angelopoulos, K Krauth, S Bates, Y Wang, M I. Jordan
[UC Berkeley]
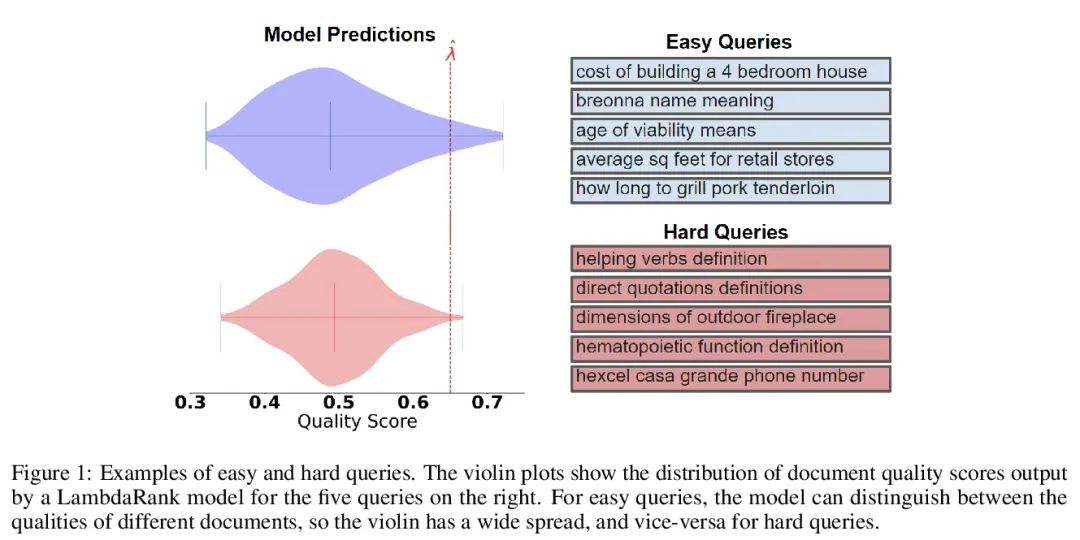
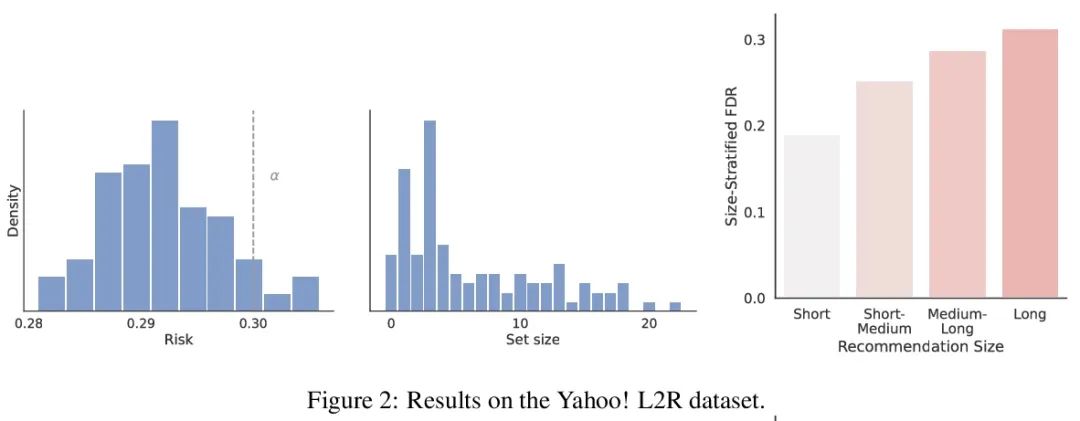
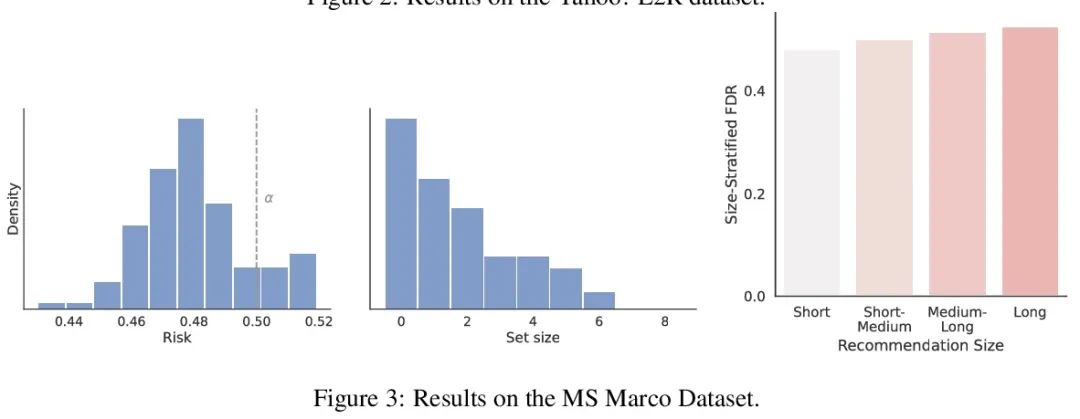
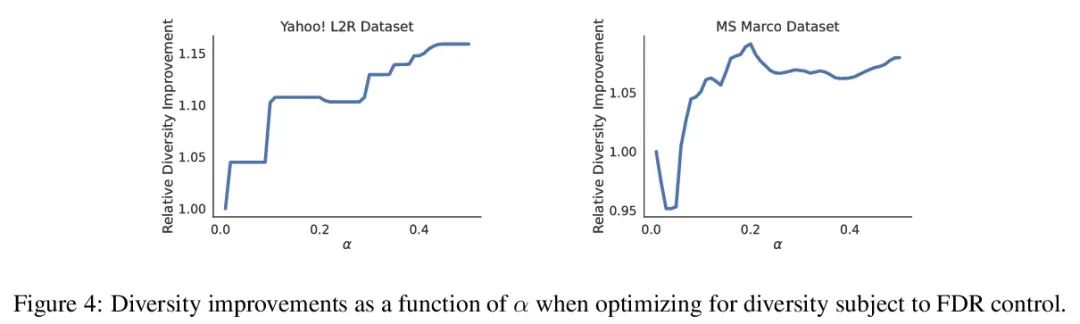
Système recommandé avec une garantie de fiabilité non distribuée. Lors de la mise en place du système recommandé , Toujours essayer d'exporter un ensemble d'éléments utiles à l'utilisateur . Derrière le système , Un modèle de classement prédit lequel des deux candidats est le meilleur , Ces comparaisons par paires doivent être affinées en résultats orientés vers l'utilisateur. .Et pourtant, Un modèle de classement appris n'est jamais parfait ,Donc,, Sa prédiction ne garantit pas à première vue la fiabilité de la sortie orientée vers l'utilisateur . À partir d'un modèle de classement pré - formé , Cet article montre comment retourner une collection d'articles qui sont strictement garantis de contenir la plupart des bons articles . Ce programme donne à tout modèle de classement un taux strict de détection des erreurs (FDR) Contrôle limité des échantillons pour ,Peu importe.(Inconnu) Comment les données sont - elles réparties .En outre, L'algorithme d'étalonnage proposé simplifie l'intégration de plusieurs cibles dans le système de recommandation. .Par exemple, Cet article montre comment faire pour FDR Optimiser la diversité recommandée au niveau du contrôle , Poids spécial pour éviter la perte de diversité spécifiée et la perte de précision .Tout au long du processus, Se concentrer sur l'apprentissage des questions de classement d'un ensemble de recommandations possibles ,InYahoo! Learning to RankEtMSMarco La méthodologie proposée a été évaluée sur l'ensemble de données .
When building recommendation systems, we seek to output a helpful set of items to the user. Under the hood, a ranking model predicts which of two candidate items is better, and we must distill these pairwise comparisons into the user-facing output. However, a learned ranking model is never perfect, so taking its predictions at face value gives no guarantee that the user-facing output is reliable. Building from a pre-trained ranking model, we show how to return a set of items that is rigorously guaranteed to contain mostly good items. Our procedure endows any ranking model with rigorous finite-sample control of the false discovery rate (FDR), regardless of the (unknown) data distribution. Moreover, our calibration algorithm enables the easy and principled integration of multiple objectives in recommender systems. As an example, we show how to optimize for recommendation diversity subject to a user-specified level of FDR control, circumventing the need to specify ad hoc weights of a diversity loss against an accuracy loss. Throughout, we focus on the problem of learning to rank a set of possible recommendations, evaluating our methods on the Yahoo! Learning to Rank and MSMarco datasets.
https://arxiv.org/abs/2207.01609

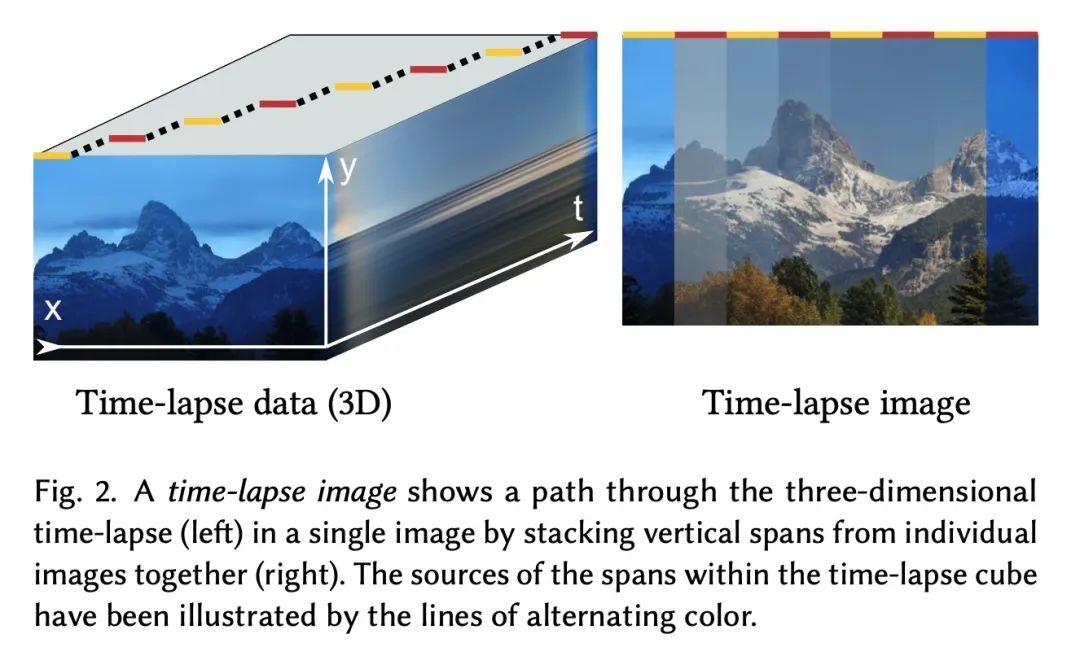
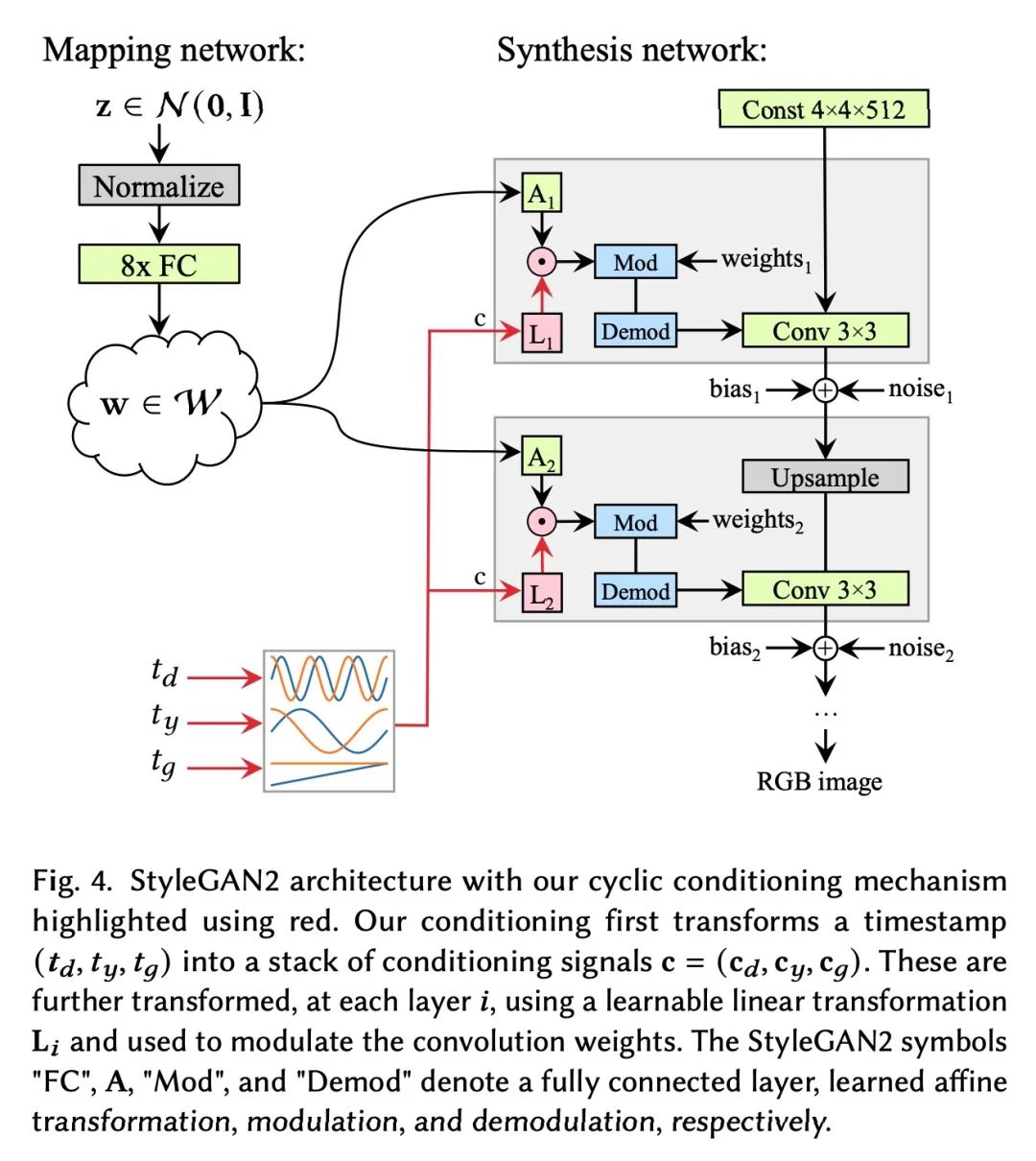
4、[CV] Disentangling Random and Cyclic Effects in Time-Lapse Sequences
E Härkönen, M Aittala, T Kynkäänniemi, S Laine, T Aila, J Lehtinen
[Aalto University & NVIDIA]
Déballage des effets aléatoires et cycliques des séquences photographiques retardées. Les séquences photographiques retardées fournissent un aperçu visuellement convaincant des processus dynamiques , Ces processus sont trop lents , Impossible d'observer en temps réel .Et pourtant, En raison d'effets aléatoires (Comme le temps) Et les effets périodiques ( Comme un cycle de jour et de nuit )Impact de, La lecture d'une longue séquence photographique retardée sous forme vidéo entraîne souvent un clignotement perturbateur. . Dans cet article, nous présentons le problème du déballage des séquences retardées , Permet une tendance globale dans l'image 、 Les effets périodiques et aléatoires font l'objet d'un contrôle post érieur distinct , Et décrit une technique de génération de modèles basée sur les données pour atteindre cet objectif . D'une manière qui n'est pas possible avec une seule image d'entrée "Rendu"Séquence.Par exemple, Peut stabiliser une longue séquence , En option 、 Par temps constant , Attention à la croissance des plantes sur plusieurs mois . La méthode proposée est basée sur la création d'un réseau de contre - mesures (GAN), En fonction des coordonnées temporelles des séquences photographiques retardées . Sa structure et son programme de formation sont conçus de cette façon : Le réseau apprend à utiliser GAN Pour simuler des changements aléatoires ,Comme le temps, Et en utilisant des caractéristiques de Fourier avec des fréquences spécifiques pour fournir des étiquettes de temps conditionnelles au modèle , Pour distinguer les tendances générales des variations cycliques .Les expériences montrent que, Le modèle proposé est robuste aux défauts des données de formation , Quelques difficultés pratiques pour saisir les séquences à long délai , Comme l'occlusion temporaire 、 Espacement inégal des cadres et absence de cadres .
Time-lapse image sequences offer visually compelling insights into dynamic processes that are too slow to observe in real time. However, playing a long time-lapse sequence back as a video often results in distracting flicker due to random effects, such as weather, as well as cyclic effects, such as the day-night cycle. We introduce the problem of disentangling time-lapse sequences in a way that allows separate, after-the-fact control of overall trends, cyclic effects, and random effects in the images, and describe a technique based on data-driven generative models that achieves this goal. This enables us to "re-render" the sequences in ways that would not be possible with the input images alone. For example, we can stabilize a long sequence to focus on plant growth over many months, under selectable, consistent weather. Our approach is based on Generative Adversarial Networks (GAN) that are conditioned with the time coordinate of the time-lapse sequence. Our architecture and training procedure are designed so that the networks learn to model random variations, such as weather, using the GAN's latent space, and to disentangle overall trends and cyclic variations by feeding the conditioning time label to the model using Fourier features with specific frequencies. We show that our models are robust to defects in the training data, enabling us to amend some of the practical difficulties in capturing long time-lapse sequences, such as temporary occlusions, uneven frame spacing, and missing frames.
https://arxiv.org/abs/2207.01413



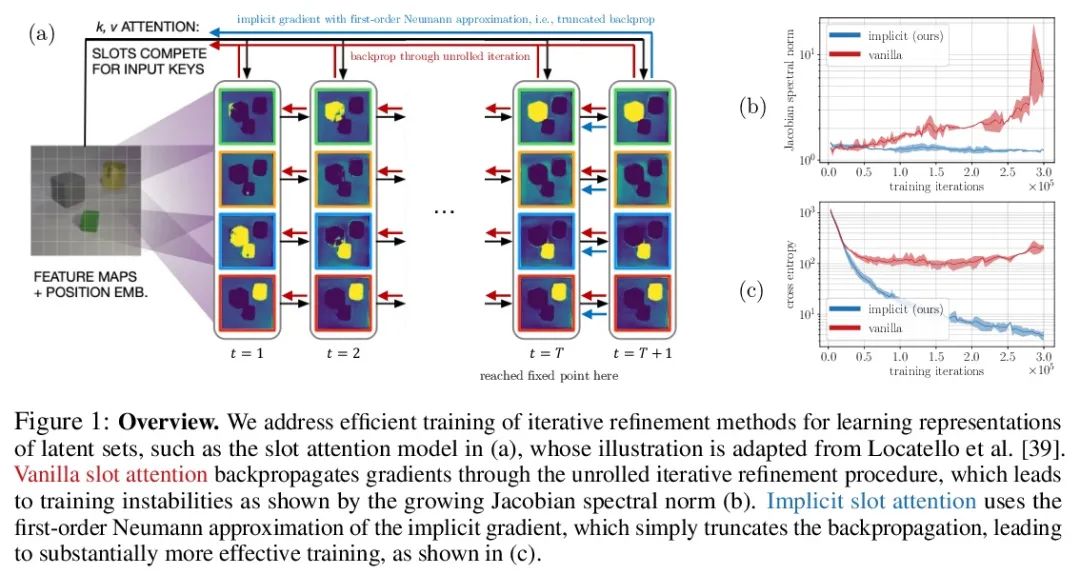
5、[LG] Object Representations as Fixed Points: Training Iterative Refinement Algorithms with Implicit Differentiation
M Chang, T L. Griffiths, S Levine
[UC Berkeley & Princeton University]
L'objet point représente :Formation à l'algorithme itératif d'amincissement basé sur la différence implicite.Amélioration itérative—— En commençant par des suppositions aléatoires , Et ensuite itérer pour améliorer la conjecture —— Est une représentation utile du paradigme d'apprentissage , Fournit un moyen de briser la symétrie entre les interprétations tout aussi raisonnables des données . Cette propriété permet d'appliquer la méthode pour déduire la représentation des ensembles d'entités , Comme un objet dans une scène Physique , Structure similaire à l'algorithme de regroupement dans l'espace sous - Marin .Et pourtant, La plupart des travaux antérieurs ont consisté à différencier par un processus de raffinement lâche , Cela peut rendre l'optimisation difficile . Dans cet article, nous observons que la méthode peut être différenciée par le théorème de la fonction implicite , Et a développé une méthode de différenciation implicite , En découplant l'avant et l'arrière , Améliorer la stabilité et l'opérabilité de l'entraînement . Ce lien permet d'appliquer les progrès de l'optimisation des couches cachées , Non seulement ça s'est amélioré SLATE Optimisation du module d'attention du canal moyen —— Une méthode d'apprentissage de pointe pour la représentation des entités —— Et avec la même complexité spatiale et temporelle de Rétropropagation, , .Il suffit d'ajouter une ligne de code pour .
Iterative refinement – start with a random guess, then iteratively improve the guess – is a useful paradigm for representation learning because it offers a way to break symmetries among equally plausible explanations for the data. This property enables the application of such methods to infer representations of sets of entities, such as objects in physical scenes, structurally resembling clustering algorithms in latent space. However, most prior works differentiate through the unrolled refinement process, which can make optimization challenging. We observe that such methods can be made differentiable by means of the implicit function theorem, and develop an implicit differentiation approach that improves the stability and tractability of training by decoupling the forward and backward passes. This connection enables us to apply advances in optimizing implicit layers to not only improve the optimization of the slot attention module in SLATE, a state-of-the-art method for learning entity representations, but do so with constant space and time complexity in backpropagation and only one additional line of code.
https://arxiv.org/abs/2207.00787




Plusieurs autres documents intéressants:
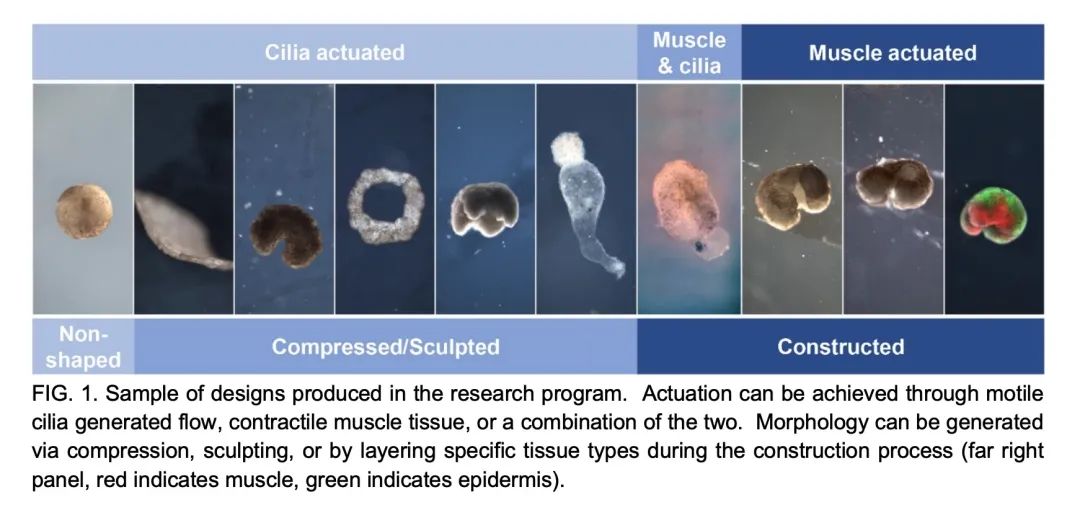
[RO] Biological Robots: Perspectives on an Emerging Interdisciplinary Field
Robot biologique : Aperçu des nouveaux domaines interdisciplinaires
D. Blackiston, S. Kriegman, J. Bongard, M. Levin
[Tufts University & University of Vermont]
https://arxiv.org/abs/2207.00880


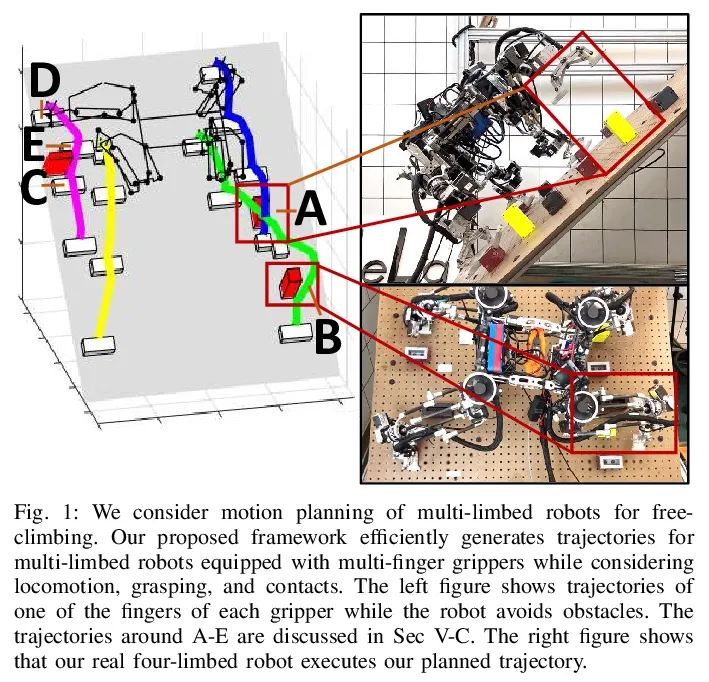
[RO] Simultaneous Contact-Rich Grasping and Locomotion via Distributed Optimization Enabling Free-Climbing for Multi-Limbed Robots
Grâce à l'optimisation distribuée, le robot Multi - membres peut grimper librement tout en touchant la capture et le mouvement riches
Y Shirai, X Lin, A Schperberg, Y Tanaka...
[University of California, Los Angeles]
https://arxiv.org/abs/2207.01418

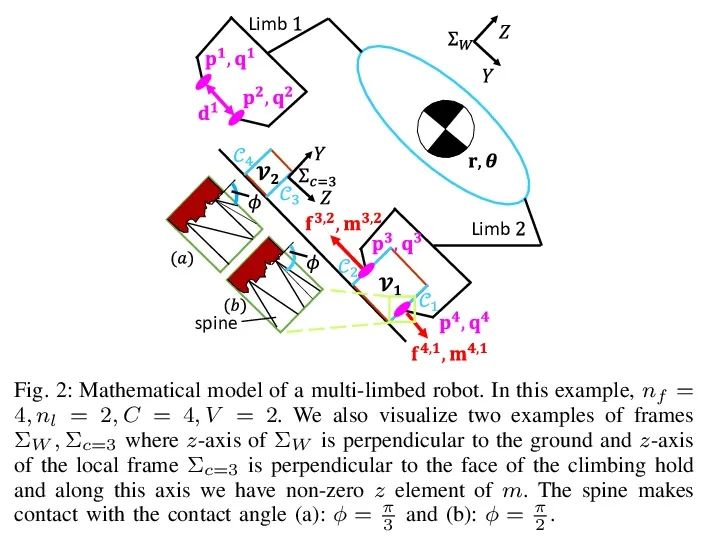
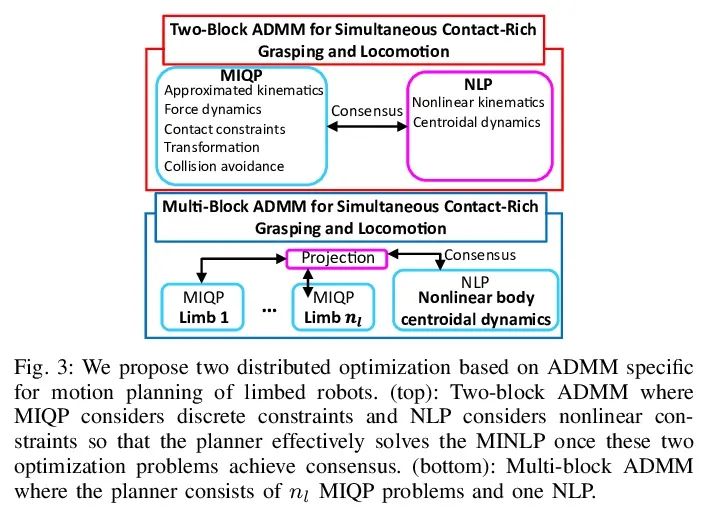
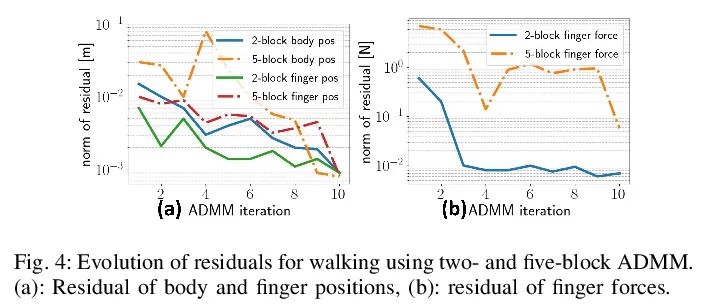
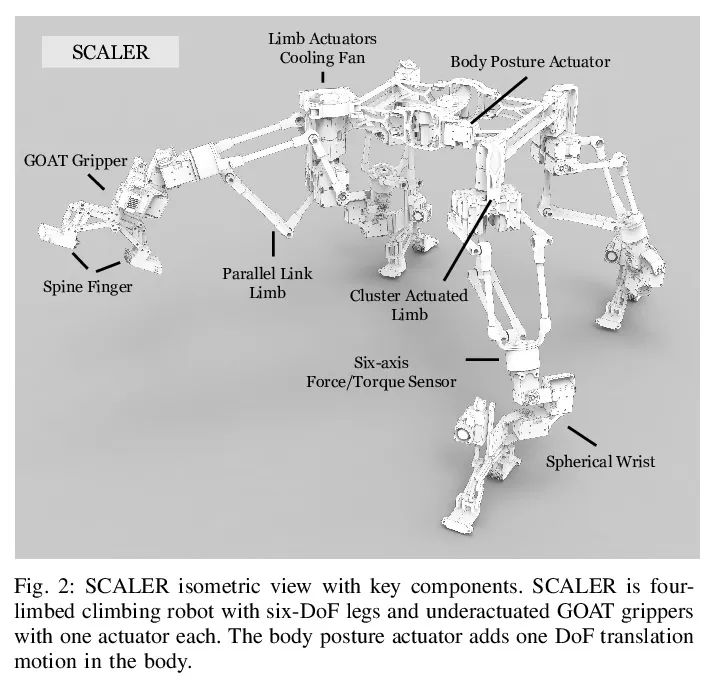
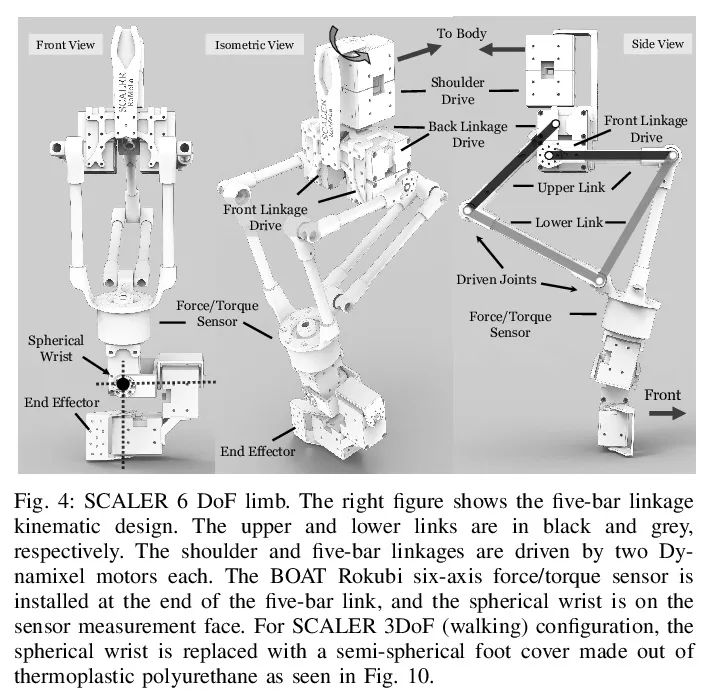
[RO] SCALER: A Tough Versatile Quadruped Free-Climber Robot
SCALER:Robot d'escalade quadripode robuste et polyvalent
Y Tanaka, Y Shirai, X Lin, A Schperberg, H Kato, A Swerdlow, N Kumagai, D Hong
[University of California, Los Angeles]
https://arxiv.org/abs/2207.01180



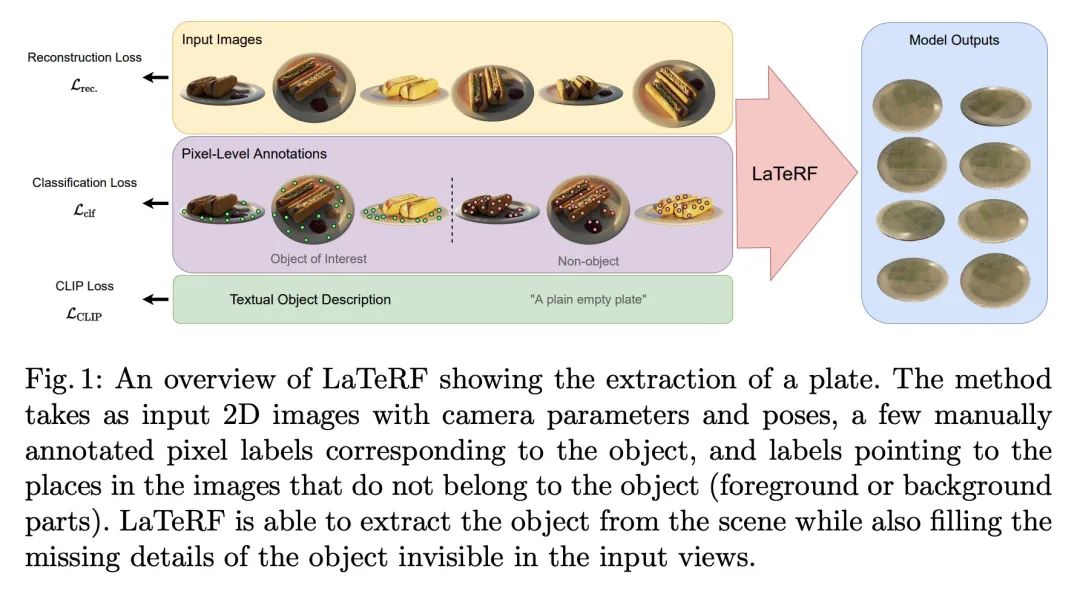
[CV] LaTeRF: Label and Text Driven Object Radiance Fields
LaTeRF:Étiquettes et champs de rayonnement d'objets textuels
A Mirzaei, Y Kant, J Kelly, I Gilitschenski
[University of Toronto]
https://arxiv.org/abs/2207.01583



边栏推荐
- Spiral square PTA
- 每个程序员必须掌握的常用英语词汇(建议收藏)
- OneNote 深度评测:使用资源、插件、模版
- Use of OLED screen
- Laravel notes - add the function of locking accounts after 5 login failures in user-defined login (improve system security)
- Common doubts about the introduction of APS by enterprises
- c#使用oracle存储过程获取结果集实例
- 2017 8th Blue Bridge Cup group a provincial tournament
- [weekly pit] calculate the sum of primes within 100 + [answer] output triangle
- 拼多多败诉,砍价始终差0.9%一案宣判;微信内测同一手机号可注册两个账号功能;2022年度菲尔兹奖公布|极客头条
猜你喜欢
Infrared thermometer based on STM32 single chip microcomputer (with face detection)
![[DIY]如何制作一款個性的收音機](/img/fc/a371322258131d1dc617ce18490baf.jpg)
[DIY]如何制作一款個性的收音機
请问sql group by 语句问题
![[DIY]自己设计微软MakeCode街机,官方开源软硬件](/img/a3/999c1d38491870c46f380c824ee8e7.png)
[DIY]自己设计微软MakeCode街机,官方开源软硬件

知识图谱之实体对齐二
Pycharm remote execution
![Mécanisme de fonctionnement et de mise à jour de [Widget Wechat]](/img/cf/58a62a7134ff5e9f8d2f91aa24c7ac.png)
Mécanisme de fonctionnement et de mise à jour de [Widget Wechat]
Activiti global process monitors activitieventlistener to monitor different types of events, which is very convenient without configuring task monitoring in acitivit
1_ Introduction to go language
Opencv learning example code 3.2.3 image binarization
随机推荐
Dynamically switch data sources
快过年了,心也懒了
Tips for web development: skillfully use ThreadLocal to avoid layer by layer value transmission
PG基础篇--逻辑结构管理(事务)
Recyclerview GridLayout bisects the middle blank area
c#使用oracle存储过程获取结果集实例
Xcode6 error: "no matching provisioning profiles found for application"
OSPF多区域配置
Opencv learning example code 3.2.3 image binarization
R language visualizes the relationship between more than two classification (category) variables, uses mosaic function in VCD package to create mosaic plots, and visualizes the relationship between tw
Application layer of tcp/ip protocol cluster
User defined current limiting annotation
过程化sql在定义变量上与c语言中的变量定义有什么区别
全网最全的知识库管理工具综合评测和推荐:FlowUs、Baklib、简道云、ONES Wiki 、PingCode、Seed、MeBox、亿方云、智米云、搜阅云、天翎
1500萬員工輕松管理,雲原生數據庫GaussDB讓HR辦公更高效
Reviewer dis's whole research direction is not just reviewing my manuscript. What should I do?
C language games - minesweeping
Reinforcement learning - learning notes 5 | alphago
2022 Guangdong Provincial Safety Officer C certificate third batch (full-time safety production management personnel) simulation examination and Guangdong Provincial Safety Officer C certificate third
Intel 48 core new Xeon run point exposure: unexpected results against AMD zen3 in 3D cache