当前位置:网站首页>Word bag model and TF-IDF
Word bag model and TF-IDF
2022-07-06 21:01:00 【wx5d786476cd8b2】
from sklearn.feature_extraction.text import CountVectorizer,TfidfTransformer
import os
import re
import jieba.posseg as pseg
# Load thesaurus
'''stop_words_path = './stop_words/'
stopwords1 = [line.rstrip() for line in open(os.path.join(stop_words_path, ' Chinese Thesaurus .txt'), 'r',encoding='utf-8')]
stopwords2 = [line.rstrip() for line in open(os.path.join(stop_words_path, ' Stoppage vocabulary of Harbin Institute of Technology .txt'), 'r',encoding='utf-8')]
stopwords3 = [line.rstrip() for line in
open(os.path.join(stop_words_path, ' The Machine Intelligence Laboratory of Sichuan University stopped using thesaurus .txt'), 'r', encoding='utf-8')]
stopwords = stopwords1 + stopwords2 + stopwords3
'''
def proc_text(raw_line):
"""
Processing text data
Return the word segmentation result
"""
# 1. Use regular expressions to remove non Chinese characters
filter_pattern = re.compile('[^\u4E00-\u9FD5]+')
chinese_only = filter_pattern.sub('', raw_line)
# 2. Stuttering participle + Part of speech tagging
word_list = pseg.cut(chinese_only)
# 3. Remove stop words , Keep meaningful parts of speech
# Verb , Adjective , adverb
used_flags = ['v', 'a', 'ad']
meaninful_words = []
for word, flag in word_list:
if flag in used_flags:
meaninful_words.append(word)
return ' '.join(meaninful_words)
count_vectorizer = CountVectorizer()
transformer=TfidfTransformer()
print(count_vectorizer)
ch_text1 = ' Very disappointed , The script is completely perfunctory , The main plot didn't break through, you can understand , But all the characters lack motivation , Between good and evil 、 There is no spark inside the women's Federation . unity - split - Although the three-stage style of unity is old-fashioned, it can also make use of the accumulated image charm to make sense , But the script is very superficial 、 Plane . The scheduling on the scene is chaotic and rigid , Full screen of armor aesthetic fatigue . Only a smile can be regarded as unsatisfactory .'
ch_text2 = ' 2015 The most disappointing work of the year . Think everything is covered , In fact, it's like painting a snake to make it superfluous ; Think the theme is profound , In fact, the old tune is repeated ; Think that through the old and bring forth the new , In fact, it is unbearable ; I thought the scene was very high, But in fact high Lack of strength . gas ! The last episode was completely uninteresting , The laughter point of this episode is obviously deliberately guilty . There is no episode in the whole film, which gives me a time of tension , Too weak. , Like aochuang .'
ch_text3 = ' 《 Iron Man 2》 Seduce iron man ,《 Women's Federation 1》 Seduce eagle eyes ,《 American team 2》 Seduce Captain America , stay 《 Women's Federation 2》 Finally …… Confessed to the Hulk , The black widow told us what loyalty is with practical actions ; And in order to treat infertility, even combat weapons have become two pregnancy test rods ( Firmly believe that kuaiyin is not dead , I have to come back later )'
ch_text4 = ' Although from beginning to end , But it's really boring .'
ch_text5 = ' The plot is not as interesting as the first episode , It all depends on dense laughter to refresh . The direct consequence of too many monks and too few girls is that every widowed sister has to change her teammates to fall in love , It's harder than fighting , Sincerely beg to let go ~~~( At the end, the egg thought it was rocky , As a result, I bah !)'
ch_texts = [ch_text1, ch_text2, ch_text3, ch_text4, ch_text5]
corpus = [proc_text(ch_text) for ch_text in ch_texts]
print(corpus)
tfidf=transformer.fit_transform(count_vectorizer.fit_transform(corpus))
word = count_vectorizer.get_feature_names()
print(tfidf)
print(tfidf.toarray())
for i in range(len(tfidf.toarray())):# Print... For each type of text tf-idf Word weight , first for Traverse all text , the second for Facilitate the weight of words in a certain type of text
print (u"------- Here is the output of ",i,u" A text like word tf-idf The weight ------")
for j in range(len(word)):
print(word[j],tfidf.toarray()[i][j])
new_text = ' The plot is chaotic , I'm so disappointed '
new_pro_text = proc_text(new_text)
print(new_pro_text)
print(transformer.fit_transform(count_vectorizer.transform([new_pro_text])).toarray())
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
边栏推荐
- User defined current limiting annotation
- PG basics -- Logical Structure Management (transaction)
- Swagger UI教程 API 文档神器
- (work record) March 11, 2020 to March 15, 2021
- 强化学习-学习笔记5 | AlphaGo
- None of the strongest kings in the monitoring industry!
- 7. Data permission annotation
- 【OpenCV 例程200篇】220.对图像进行马赛克处理
- [DIY]如何制作一款个性的收音机
- Application layer of tcp/ip protocol cluster
猜你喜欢
Build your own application based on Google's open source tensorflow object detection API video object recognition system (IV)

(work record) March 11, 2020 to March 15, 2021
基于STM32单片机设计的红外测温仪(带人脸检测)

使用.Net驱动Jetson Nano的OLED显示屏
Common doubts about the introduction of APS by enterprises

What key progress has been made in deep learning in 2021?
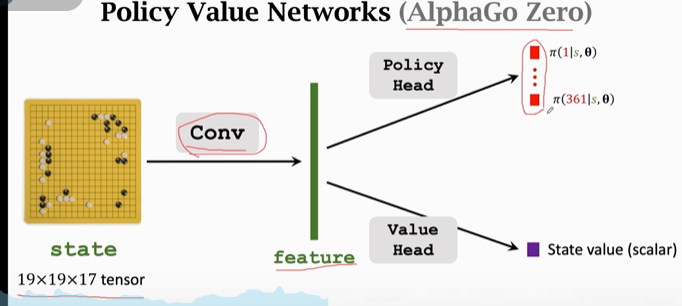
强化学习-学习笔记5 | AlphaGo
use. Net drives the OLED display of Jetson nano
OAI 5g nr+usrp b210 installation and construction
None of the strongest kings in the monitoring industry!
随机推荐
[DIY]如何制作一款個性的收音機
R language visualizes the relationship between more than two classification (category) variables, uses mosaic function in VCD package to create mosaic plots, and visualizes the relationship between tw
Minimum cut edge set of undirected graph
OAI 5g nr+usrp b210 installation and construction
The most comprehensive new database in the whole network, multidimensional table platform inventory note, flowus, airtable, seatable, Vig table Vika, flying Book Multidimensional table, heipayun, Zhix
Mtcnn face detection
[weekly pit] information encryption + [answer] positive integer factorization prime factor
Comment faire une radio personnalisée
2022 refrigeration and air conditioning equipment installation and repair examination contents and new version of refrigeration and air conditioning equipment installation and repair examination quest
全网最全的新型数据库、多维表格平台盘点 Notion、FlowUs、Airtable、SeaTable、维格表 Vika、飞书多维表格、黑帕云、织信 Informat、语雀
强化学习-学习笔记5 | AlphaGo
15 millions d'employés sont faciles à gérer et la base de données native du cloud gaussdb rend le Bureau des RH plus efficace
2022 Guangdong Provincial Safety Officer C certificate third batch (full-time safety production management personnel) simulation examination and Guangdong Provincial Safety Officer C certificate third
自定义限流注解
It's almost the new year, and my heart is lazy
Spiral square PTA
什么是RDB和AOF
Leetcode hot topic Hot 100 day 32: "minimum coverage substring"
2110 summary of knowledge points and common problems in redis class
15million employees are easy to manage, and the cloud native database gaussdb makes HR office more efficient