当前位置:网站首页>Vit paper details
Vit paper details
2022-07-06 21:41:00 【Murmur and smile】
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
Billbill Explain :https://www.bilibili.com/video/BV1GB4y1X72R/?spm_id_from=333.788&vd_source=d2733c762a7b4f17d4f010131fbf1834
1.Introduction
Self attention based architecture , In especial Transformers(Vaswani wait forsomeone ,2017 year ), It has become natural language processing (NLP) The preferred model for . The main method is pre training on a large text corpus , Then fine tune on smaller task specific data sets (Devlin wait forsomeone ,2019). because Transformers Computational efficiency and scalability , Training has more than 100B Unprecedented models of parameters are possible (Brown wait forsomeone ,2020;Lepikhin wait forsomeone ,2020). As models and data sets grow , There is still no sign of saturation performance .
But in the field of computer vision , Convolution still dominates the address . suffer NLP Successful inspiration , Multiple work attempts will be similar to CNN Architecture and self-attention Combine . Some of them completely replace convolution , Although the latter model is theoretically valid , But due to the use of a special attention model , Has not been effectively extended on modern hardware , classical ResNet Still preferred .
suffer NLP Medium Transformer The inspiration of scaling success , Try to put the standard Transformer Apply directly to images , And minimize modifications . therefore , We split the image into pathch, And provide these patch Linearity of embedding As Transformer The input of .Image patch How to deal with it and NLP In the application token(word) identical ( How many words are there in a sentence , How many are there in a picture Patch). We train image classification models in a supervised way (nlp Learning with no supervision ).
When there is no strong regularization Transformer In medium-sized datasets ImageNet When you're training on , The accuracy is larger than that of downlight ResNet A few percentage points lower . This is because Transformer Lack some CNN Inherent induction bias, For example, translation without deformation and locality , Therefore, it cannot be well summarized in the case of insufficient data sets .
however , If the model is in a larger dataset (14M-300M Images ) Training , Things will change . We found that large-scale training is better than inductive bias .
2.Related Work
Self-attention Simply applying it to an image requires each pixel to focus on every other pixel . Due to the secondary cost of the number of pixels , It cannot be extended to the actual input size . because , In order to apply in the context of image processing Transformer, Query pixels in local areas of application self-attention, On the whole self-attention Use scalable approximations ( Sparse attention ), To apply to images . Another way to expand attention is to apply it to blocks of different sizes (Weissenborn wait forsomeone ,2019 year ), In extreme cases, apply only along a single axis ( The horizontal axis 、 The vertical axis )(Ho wait forsomeone ,2019 year ;Wang wait forsomeone ,2020a). Many of these specialized attention architectures show promising results in computer vision tasks , But it requires complex engineering to be effectively implemented on the hardware accelerator .
What is most relevant to us is Cordonnier The model of people . (2020), It extracts from the input image a size of 2x2 Of patch, And apply full self attention at the top . This model is similar to ViT Very similar , But our work further proves that large-scale pre training makes vanilla Transformer It can be done with ( Even better than ) State-of-the-art CNN competition . Besides ,Cordonnier wait forsomeone . (2020) Use 2 2 Small block size of pixels , This makes the model only suitable for small resolution images , And we also deal with medium resolution images .
Another recent related model is image GPT (iGPT) (Chen et al., 2020a), It will reduce the image resolution and color space Transformers Apply to image pixels . The model is trained in an unsupervised way as a generative model , The generated representation can then be fine tuned or linearly probed to improve classification performance , stay ImageNet Implemented on 72% Maximum accuracy of .
3.Method
The design is in the model , We try to follow the original Transformer (Vaswani et al., 2017). One advantage of this deliberately simple setup is extensibility NLP Transformer The architecture and its efficient implementation can be used almost out of the box .
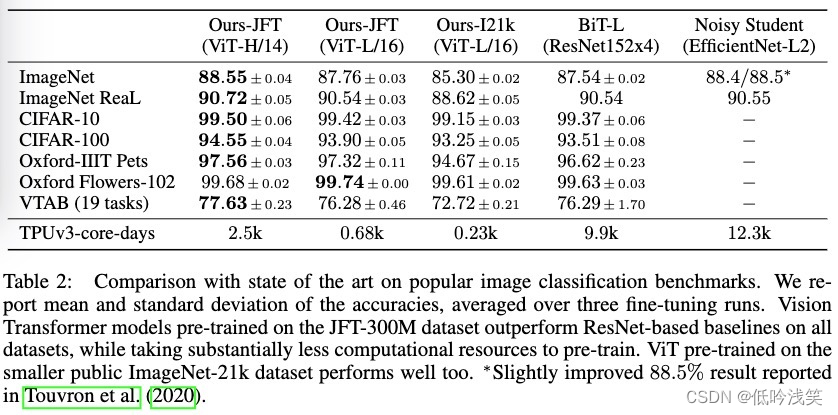
chart 1: Model overview . We divide the image into fixed size blocks , Linear embedding of each block , Add location embed , And feed the generated vector sequence to the standard Transformer Encoder . To perform classification , We use to add extra learnable “ Classification marks ” Standard method of . Transformer The illustration of the encoder was Vaswani And so on . (2017)
step : chart ---> Divided into several patch---> take patch Through the linear projection layer ----> add to Position Embedding---->Transformer Encoder-->MLP Head--->class
Let's say 224x224x3 The input of , Explain the diagram .
Input X: 224x224x3 Every patch Size : 16x16 patch The number of N = 224^2/16^2 = 196 Every patch To 1D Embedding:16x16x3=768
Linear projection layer E: 768x768 ( Dimension in the article D) For input : 196x768 token: 1x768
Through the linear projection layer : [196x768] x [178x768] = [196,768] ( Matrix multiplication )
Add one cls token, This thing can be from other 196 individual embedding Learning classification features :torch.cat([196,768],[1,768]) ==> [197,768]
Add location code :[197, 768] + [197, 768] ==> [197,768], Sum up (2017 Year of Transformer prove + and concat The effect is the same ).
Multi-head attention. long position ,e.g., 12 Head ,768/12 = 64, Each head is 197x64, After splicing is 197x768.
MLP: General dimension enlargement , Quadruple magnification 197x3012. Later, we will expand and shrink the dimension , Retract 197x768.
Layer norm: The difference in BN, On all the samples , Yes CHW Perform the normalization operation .
3.1 Vision Transformer
The standard Transformer receive 1D token As input . In order to deal with 2D Images , take Into a series of flat 2D patch , among .H and W Is the height and width ,C It's a channel ,P Every patch The resolution of the . It's every image patch Count , Can be used as Transformer Valid input sequence length of .Transformer Use a constant potential vector size in all its layers D, So we will patch Flatten and map to... Using a trainable linear projection D dimension ( Equation 1). We call the output of this projection patch embedding.
And BERT Of [class] token similar , We are embedding Sequence (Z00= xclass) Add learnable embedding, Its presence Transformer Encoder (Z0L ) The state at the output is used as an image representation y ( equation 4). During pre training and fine tuning , Category headers are attached to Z0L . The classification header consists of MLP Realization , There is a hidden layer during pre training , Fine tuning is achieved by a single linear layer .
Position embedding Be added to patch embedding To retain location information . We use standard learnable 1D position embedding, Because we didn't observe the use of more advanced 2D Significant performance improvement due to location aware embedding ( appendix D.4). Generated embedding vectors The vector sequence is used as the input of the encoder .
Transformer Encoder (Vaswani wait forsomeone ,2017) From the attention of the Bulls (MSA, See appendix A) and MLP block ( equation 2、3) Composed of alternating layers . Apply... Before each block Layernorm (LN), Apply residual join after each block (Wang et al., 2019; Baevski & Auli, 2019).
MLP Contains two with GELU Nonlinear layers .
Perceptual bias . And CNN comparison ,Vision Transformer The image feature induction deviation is much less . stay CNN in , Locality , The two-dimensional domain structure and translational deformability are added to each layer of the whole model . stay ViT in , Only MLP Layers are local and translation invariant , The self attention layer is global , And when fine-tuning, adjust the image of different resolutions position embedding. besides , Initialization position embedding Do not carry relevant patch Of 2D Location information , And you have to learn from scratch patch All spatial relationships between .
Hybrid Architecture. Hybrid architecture . As an alternative to the original image block , The input sequence can be CNN The characteristic diagram of (LeCun wait forsomeone ,1989). In this hybrid model ,patch embedding Projection E( equation 1) Apply to from CNN Patches extracted from feature maps . As a special case ,patch Can have 1x1 Space size of , This means that the input sequence is simply flattened and projected onto the spatial dimension of the feature map Transformer Dimension to get . Add category input embedding and location embedding as described above .
3.2 Fine-tuning and higher resolution
Usually , We pre train on large data sets ViT, And fine tune to ( smaller ) Downstream tasks . So , We removed the pre trained prediction header and attached a zero initialization DxK Feedforward layer , among K Is the number of downstream classes . Compared with pre training , Fine tuning at a higher resolution is usually beneficial (Touvron wait forsomeone ,2019;Kolesnikov wait forsomeone ,2020). When providing higher resolution images , We keep patch size identical , This results in a larger effective sequence length . Vision Transformer Can handle any sequence length ( Until the memory limit ), however , The location embedding of pre training may no longer make sense . therefore , We embed the pre trained positions according to their positions in the original image 2D interpolation . Please note that , This resolution adjustment and patch extraction will be related to the image 2D The inductive deviation of the structure is manually injected into the unique point of the visual converter .
4.Experience
Compared with other methods ,ViT Better performance , And have less training time .
The gray part indicates ResNet What can be achieved , On small data ,VIT The effect of is worse than ResNet, On big data sets ,VIT be better than ResNet.
The picture shows Transformer、ResNet、Hybrid Three models , Performance is increasing FLOPs Increase and improve . There is no bottleneck yet .
For the same FLOPs Model of ,Transformer And hybrid models are better than ResNet.
The hybrid model can improve the pure Transformer, But it has no advantage over larger models .
4.5 Inspection Vision Transformer
Vision Transformer The first layer of will be flattened patch Linear projection to low dimensional space . chart 7( Left ) Shows learning embedding fiters The main components of . These components are similar to reasonable basis functions , For each patch Low dimensional representation of inner fine structure .
After projection , Embed and add learning location to patch In the expression of . chart 7( in ) Show that the model is learned in position embedding The distance in the image is encoded in the similarity of , That is, closer blocks tend to have more similar location embedding . further , The row and column structure appears ; The same line / The patches in the column have similar embedding . Last , For larger meshes , Sometimes sinusoidal structures appear ( appendix D). Position embedding learning representation 2D Image topology explains why handmade 2D Perceptual embedding variants do not produce improvements ( appendix D.4, because Transformer Has gone from 1D The adjacent feature representation is learned in the position coding of )
Self-attention allow ViT Integrate the information of the whole image , Even at the lowest level . Our research network makes use of this ability to a great extent . say concretely , We calculate the average distance of information integration in image space according to the attention weight ( chart 7, Right ). such “ Pay attention to the distance ” Be similar to CNN The size of the receptive field in . Some heads participating in the low-level network have also observed the global information , This shows that the model does use the ability to globally integrate information . The attention distance of other attention heads at the lower level is always very small . This highly localized attention is Transformer Previously applied ResNet Less obvious in the mixed model ( chart 7, Right ), This suggests that it may have a relationship with CNN Similar functions of early convolution in . Besides , The attention distance increases with the increase of network depth . On a global scale , We find that the model focuses on image regions related to Classification Semantics .
5.Conclusion
We have explored Transformer Direct application in image recognition . Unlike previous work using self attention in computer vision , Except for the beginning patch Outside the extraction step , We will not introduce image specific inductive bias into the architecture . contrary , We interpret the image as a series patch, And pass NLP Standards used in Transformer The encoder processes it . This simple but scalable strategy works surprisingly well when combined with pre training of large data sets . therefore ,Vision Transformer It matches or exceeds the existing technology on many image classification data sets , At the same time, the cost of pre training is relatively low .
边栏推荐
- Fzu 1686 dragon mystery repeated coverage
- Redistemplate common collection instructions opsforset (V)
- 中国白酒的5场大战
- One line by line explanation of the source code of anchor free series network yolox (a total of ten articles, you can change the network at will after reading it, if you won't complain to me)
- [Digital IC manual tearing code] Verilog automatic beverage machine | topic | principle | design | simulation
- npm run dev启动项目报错 document is not defined
- VIM basic configuration and frequently used commands
- Why does MySQL index fail? When do I use indexes?
- Quick access to video links at station B
- This year, Jianzhi Tencent
猜你喜欢
![[Digital IC manual tearing code] Verilog automatic beverage machine | topic | principle | design | simulation](/img/75/c0656c4890795bd65874b4f2b16462.jpg)
[Digital IC manual tearing code] Verilog automatic beverage machine | topic | principle | design | simulation
039. (2.8) thoughts in the ward
![[interpretation of the paper] machine learning technology for Cataract Classification / classification](/img/0c/b76e59f092c1b534736132faa76de5.png)
[interpretation of the paper] machine learning technology for Cataract Classification / classification

【力扣刷题】一维动态规划记录(53零钱兑换、300最长递增子序列、53最大子数组和)
[Li Kou brushing questions] one dimensional dynamic planning record (53 change exchanges, 300 longest increasing subsequence, 53 largest subarray and)

Microsoft technology empowerment position - February course Preview

中国白酒的5场大战

KDD 2022 | realize unified conversational recommendation through knowledge enhanced prompt learning

Efficiency tool +wps check box shows the solution to the sun problem

袁小林:安全不只是标准,更是沃尔沃不变的信仰和追求
随机推荐
分糖果
Z function (extended KMP)
Five wars of Chinese Baijiu
Forward maximum matching method
guava:Collections. The collection created by unmodifiablexxx is not immutable
for循环中break与continue的区别——break-完全结束循环 & continue-终止本次循环
Start the embedded room: system startup with limited resources
[sliding window] group B of the 9th Landbridge cup provincial tournament: log statistics
It's not my boast. You haven't used this fairy idea plug-in!
In JS, string and array are converted to each other (I) -- the method of converting string into array
Enhance network security of kubernetes with cilium
R语言做文本挖掘 Part4文本分类
50个常用的Numpy函数解释,参数和使用示例
npm run dev启动项目报错 document is not defined
Nodejs教程之Expressjs一篇文章快速入门
el-table表格——sortable排序 & 出现小数、%时排序错乱
PostgreSQL 修改数据库用户的密码
VIM basic configuration and frequently used commands
MySQL - transaction details
字符串的使用方法之startwith()-以XX开头、endsWith()-以XX结尾、trim()-删除两端空格