当前位置:网站首页>[in depth learning] pytorch 1.12 was released, officially supporting Apple M1 chip GPU acceleration and repairing many bugs
[in depth learning] pytorch 1.12 was released, officially supporting Apple M1 chip GPU acceleration and repairing many bugs
2022-07-06 21:11:00 【Demeanor 78】

Almost Human reports
PyTorch 1.12 Official release , Friends who have not been updated can be updated .
distance PyTorch 1.11 Just a few months after launch ,PyTorch 1.12 came ! This version is provided by 1.11 Since version 3124 many times commits form , from 433 Contributors complete .1.12 The version has been significantly improved , And fixed a lot Bug.
With the release of the new version , The most talked about is probably PyTorch 1.12 Support for apple M1 chip .
As early as this year 5 month ,PyTorch Officials have announced their official support for M1 Version of Mac on GPU Accelerated PyTorch Machine learning model training . before ,Mac Upper PyTorch Training can only use CPU, But as the PyTorch 1.12 Release of version , Developers and researchers can take advantage of apple GPU Greatly speed up model training .
stay Mac Introduction of acceleration PyTorch Training
PyTorch GPU Training acceleration is using apple Metal Performance Shaders (MPS) Implemented as a back-end .MPS The back end extends PyTorch frame , Provided in Mac Scripts and functions for setting up and running operations on .MPS Use for each Metal GPU Series of unique features to fine tune the kernel capability to optimize computing performance . The new device maps machine learning computing diagrams and primitives to MPS Graph The framework and MPS The provided tuning kernel .
Each machine equipped with Apple's self-developed chip Mac All have a unified memory architecture , Give Way GPU You can directly access the complete memory storage .PyTorch Official expression , This makes Mac Become an excellent platform for machine learning , Enables users to train larger networks or batch sizes locally . This reduces the costs associated with cloud based development or for additional local resources GPU Computing power demand . The unified memory architecture also reduces data retrieval latency , Improved end-to-end performance .
You can see , And CPU Compared to baseline ,GPU Acceleration has doubled the training performance :
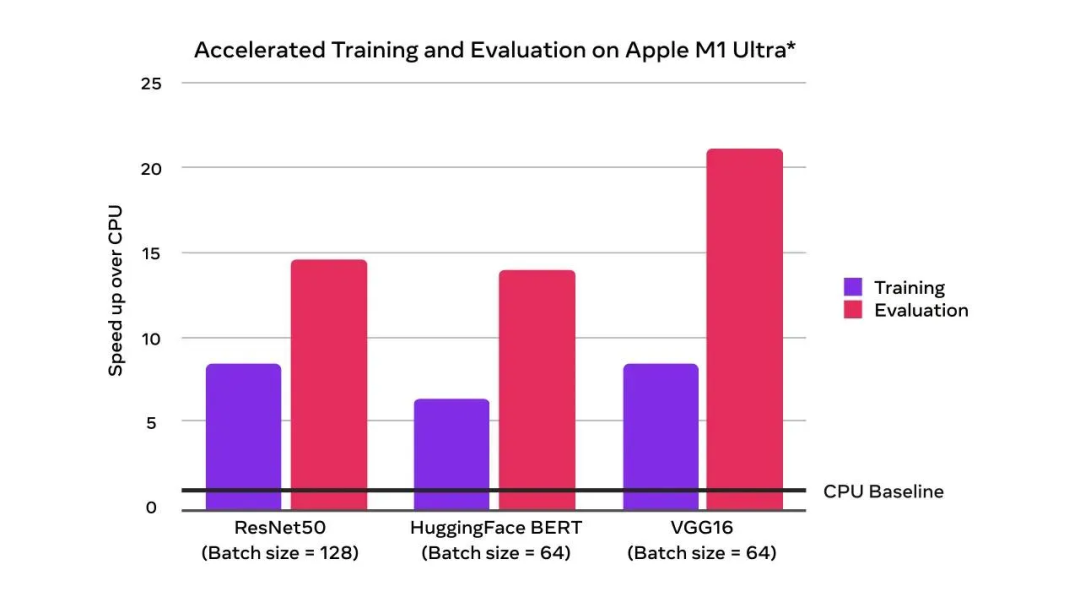
With GPU Blessing , Train and evaluate faster than CPU
The picture above shows apple in 2022 year 4 Monthly use is equipped with Apple M1 Ultra(20 nucleus CPU、64 nucleus GPU)128GB Memory ,2TB SSD Of Mac Studio Test results of the system . The test model is ResNet50(batch size = 128)、HuggingFace BERT(batch size = 64) and VGG16(batch size = 64). Performance testing is carried out using a specific computer system , Reflects Mac Studio General performance of .
PyTorch 1.12 Other new features
front end API:TorchArrow
PyTorch The official has released a new Beta Version for users to try :TorchArrow. This is a machine learning preprocessing library , Batch data processing . It has high performance , Both of them Pandas style , It also has easy to use API, To speed up user preprocessing workflow and development .
(Beta)PyTorch Medium Complex32 and Complex Convolutions
at present ,PyTorch Native support for plural 、 The plural autograd、 Complex number module and a large number of complex number operations ( Linear algebra and fast Fourier transform ). Include torchaudio and ESPNet In many libraries , Have used the plural , also PyTorch 1.12 Through complex convolution and experimental complex32 Data types further expand the complex function , This data type supports half precision FFT operation . because CUDA 11.3 There is... In the package bug, If the user wants to use the plural , Official recommended use CUDA 11.6 package .
(Beta)Forward-mode Automatic differentiation
Forward-mode AD It is allowed to calculate the directional derivative in the forward transfer ( Or equivalent Diya comparable vector product ).PyTorch 1.12 Significantly improved forward-mode AD Coverage of .
BetterTransformer
PyTorch Now support multiple CPU and GPU fastpath Realization (BetterTransformer), That is to say Transformer Encoder module , Include TransformerEncoder、TransformerEncoderLayer and MultiHeadAttention (MHA) The implementation of the . In the new version ,BetterTransformer In many common scenes, the speed is fast 2 times , It also depends on the model and input characteristics . The new version API Support with previous PyTorch Transformer API compatible , If the existing model meets fastpath Carry out the requirements , They will accelerate existing models , And read using the previous version PyTorch Training model .
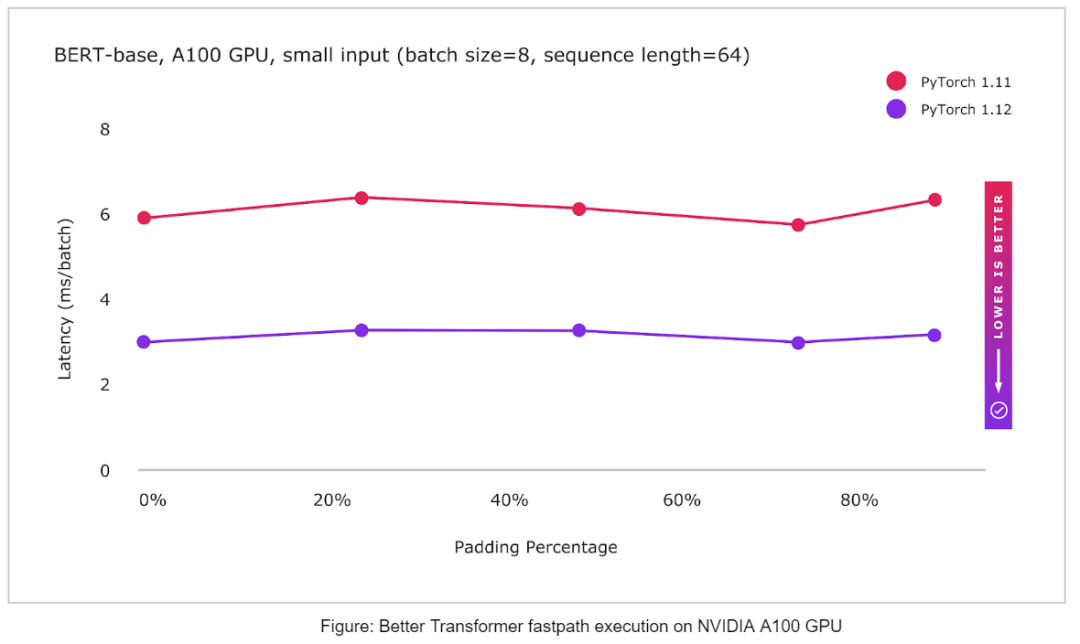
Besides , There are some updates in the new version :
modular : A new method of module calculation beta Feature is functionality API. This new functional_call() API It allows the user to fully control the parameters used in the module calculation ;
TorchData:DataPipe Improved communication with DataLoader The compatibility of .PyTorch Support is now based on AWSSDK Of DataPipes.DataLoader2 Has been introduced as a management DataPipes And others API A way to interact with the backend ;
nvFuser: nvFuser It's new 、 Faster default fuser, Used to compile to CUDA equipment ;
Matrix multiplication accuracy : By default ,float32 Matrix multiplication on data types will now work in full precision mode , This mode is slow , But it will produce more consistent results ;
Bfloat16: It provides faster calculation time for less precise data types , So in 1.12 Chinese vs Bfloat16 New improvements have been made to data types ;
FSDP API: As a prototype in 1.11 It's published in ,FSDP API stay 1.12 The beta version has been released , And added some improvements .
See more :https://pytorch.org/blog/pytorch-1.12-released/

Past highlights
It is suitable for beginners to download the route and materials of artificial intelligence ( Image & Text + video ) Introduction to machine learning series download Chinese University Courses 《 machine learning 》( Huang haiguang keynote speaker ) Print materials such as machine learning and in-depth learning notes 《 Statistical learning method 》 Code reproduction album machine learning communication qq Group 955171419, Please scan the code to join wechat group
边栏推荐
- No Yum source to install SPuG monitoring
- 038. (2.7) less anxiety
- Seven original sins of embedded development
- R语言可视化两个以上的分类(类别)变量之间的关系、使用vcd包中的Mosaic函数创建马赛克图( Mosaic plots)、分别可视化两个、三个、四个分类变量的关系的马赛克图
- 愛可可AI前沿推介(7.6)
- 【OpenCV 例程200篇】220.对图像进行马赛克处理
- Reviewer dis's whole research direction is not just reviewing my manuscript. What should I do?
- Mécanisme de fonctionnement et de mise à jour de [Widget Wechat]
- OSPF多区域配置
- Can novices speculate in stocks for 200 yuan? Is the securities account given by qiniu safe?
猜你喜欢
Redis insert data garbled solution

KDD 2022 | realize unified conversational recommendation through knowledge enhanced prompt learning

15 millions d'employés sont faciles à gérer et la base de données native du cloud gaussdb rend le Bureau des RH plus efficace

Hardware development notes (10): basic process of hardware development, making a USB to RS232 module (9): create ch340g/max232 package library sop-16 and associate principle primitive devices
【Redis设计与实现】第一部分 :Redis数据结构和对象 总结

Interviewer: what is the internal implementation of ordered collection in redis?

Aike AI frontier promotion (7.6)
![[sliding window] group B of the 9th Landbridge cup provincial tournament: log statistics](/img/2d/9a7e88fb774984d061538e3ad4a96b.png)
[sliding window] group B of the 9th Landbridge cup provincial tournament: log statistics

LLVM之父Chris Lattner:为什么我们要重建AI基础设施软件
基于STM32单片机设计的红外测温仪(带人脸检测)
随机推荐
R語言可視化兩個以上的分類(類別)變量之間的關系、使用vcd包中的Mosaic函數創建馬賽克圖( Mosaic plots)、分別可視化兩個、三個、四個分類變量的關系的馬賽克圖
[MySQL] basic use of cursor
El table table - get the row and column you click & the sort of El table and sort change, El table column and sort method & clear sort clearsort
Mécanisme de fonctionnement et de mise à jour de [Widget Wechat]
LLVM之父Chris Lattner:为什么我们要重建AI基础设施软件
请问sql group by 语句问题
SAP UI5 框架的 manifest.json
Le langage r visualise les relations entre plus de deux variables de classification (catégories), crée des plots Mosaiques en utilisant la fonction Mosaic dans le paquet VCD, et visualise les relation
js之遍历数组、字符串
全网最全的新型数据库、多维表格平台盘点 Notion、FlowUs、Airtable、SeaTable、维格表 Vika、飞书多维表格、黑帕云、织信 Informat、语雀
面试官:Redis中有序集合的内部实现方式是什么?
##无yum源安装spug监控
After working for 5 years, this experience is left when you reach P7. You have helped your friends get 10 offers
1500万员工轻松管理,云原生数据库GaussDB让HR办公更高效
【mysql】游标的基本使用
ICML 2022 | flowformer: task generic linear complexity transformer
Laravel笔记-自定义登录中新增登录5次失败锁账户功能(提高系统安全性)
OAI 5g nr+usrp b210 installation and construction
KDD 2022 | 通过知识增强的提示学习实现统一的对话式推荐
Reflection operation exercise